python爬虫学习笔记——xpath

xpath
1.xpath简介
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
2.xpath安装
pip install lxml3.常用的基本规则

举例子
//title[@lang='eng'] # 选取所有名称为title,且属性lang等于eng的节点4.实例引入
from lxml import etree # 导入模块
data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(data) #生成一个xpath对象
print(html) #<Element html at 0x26ae8c0>
res = etree.tostring(html) # # 可修正html代码,上面的代码里的最后一个li标签没有闭合,这个可以自动闭合
print(res) # 输入结果是<class 'bytes'>类型可以用decode()方法转换成str类型5.实例
from lxml import etree
data = """
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div>
</body></html>
"""
html = etree.HTML(data)
# 1.获取所有页面标签
res = html.xpath('//*') # 获取所有标签对象
res = html.xpath('//*') # 列表类型
"""
<class 'list'> [<Element html at 0x26b6200>, <Element body at 0x275e600>, <Element div at 0x275e680>, <Element ul at 0x275e580>, <Element li at 0x275e6c0>, <Element a at 0x275e740>, <Element li at 0x275e780>, <Element a at 0x275e7c0>, <Element li at 0x275e800>, <Element a at 0x275e700>, <Element li at 0x275e840>, <Element a at 0x275e880>, <Element li at 0x275e8c0>, <Element a at 0x275e900>]
"""
# 2.获取所有的li标签
res = html.xpath('//li') # 获取所有的li标签(结果是列表类型)
print(type(res),res)
print(res[0]) #获取列表里的一个li标签
"""
<class 'list'> [<Element li at 0x276e6c0>, <Element li at 0x276e740>, <Element li at 0x276e640>, <Element li at 0x276e780>, <Element li at 0x276e7c0>]
<Element li at 0x276e6c0>
"""
# 3.获取li标签的子节点a标签
res = html.xpath('//li/a') # //li用于获取所有li标签,追加\a则是获取所有li标签的直接子节点a
print(type(res),res)
"""
<class 'list'> [<Element a at 0x275e680>, <Element a at 0x275e700>, <Element a at 0x275e600>, <Element a at 0x275e740>, <Element a at 0x275e780>]
"""
# 4.//和/的区别
"""
//获取子孙节点
/获取直接子节点
"""
res = html.xpath('//ul/a')
print(type(res),res)
"""
ul下没有直接子节点a,所有获取为空
<class 'list'> []
"""
res = html.xpath('//ul//a')
print(type(res),res)
"""
获取子孙节点,可以获取li标签下的a标签
<class 'list'> [<Element a at 0x2590b80>, <Element a at 0x276e800>, <Element a at 0x276e780>, <Element a at 0x276e700>, <Element a at 0x276e840>]
"""
# 5.父节点
"""
.当前节点
..父节点
"""
# 获取href属性是link4.html的节点,然后获取其父节点的属性
res = html.xpath('//a[@href="link4.html"]/../@class')
print(type(res),res)
"""
<class 'list'> ['item-1']
"""
# 也可通过parent::来获取,用parent::代替..即可
# 6.属性匹配
"""
用@符号进行属性的过滤
"""
res = html.xpath('//li[@class="item-0"]') # 获取class值为item-0的li标签
print(type(res),res)
"""
<class 'list'> [<Element li at 0x274e640>, <Element li at 0x274e540>]
"""
# 7.文本获取
"""
text()方法
"""
res = html.xpath('//li[@class="item-0"]//text()') # 获取最全面的文本,但可能会存在特殊字符
print(type(res),res)
"""
<class 'list'> ['first item', 'fifth item', '\n ']
"""
res = html.xpath('//li[@class="item-0"]/a/text()') # 获取文本内容
print(type(res),res)
"""
<class 'list'> ['first item', 'fifth item']
"""
# 8.属性获取
"""
通过@获取
"""
res = html.xpath('//li/a/@href') # 获取li节点下a节点的href属性
print(type(res),res)
"""
<class 'list'> ['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
"""
# 9.属性多值匹配
"""
当一个属性有多个值的时候可以用contains()函数匹配
contains()
第一个参数出入属性名称
第二个参数传入属性其中一个值
只要包含就可以完成匹配
如contains("@class","li")
"""
# 10.多属性匹配
'''
如果需要多个属性确认一个节点的话,需要用到多值匹配
and
'''
from lxml import etree
data = """
<li class="li li-first" name="item"><a href="link.html">first item</a></li>
"""
html = etree.HTML(data)
res = html.xpath('//li[contains(@class,"li") and @name="item"]/a/text()')
print(res)
"""
['first item']
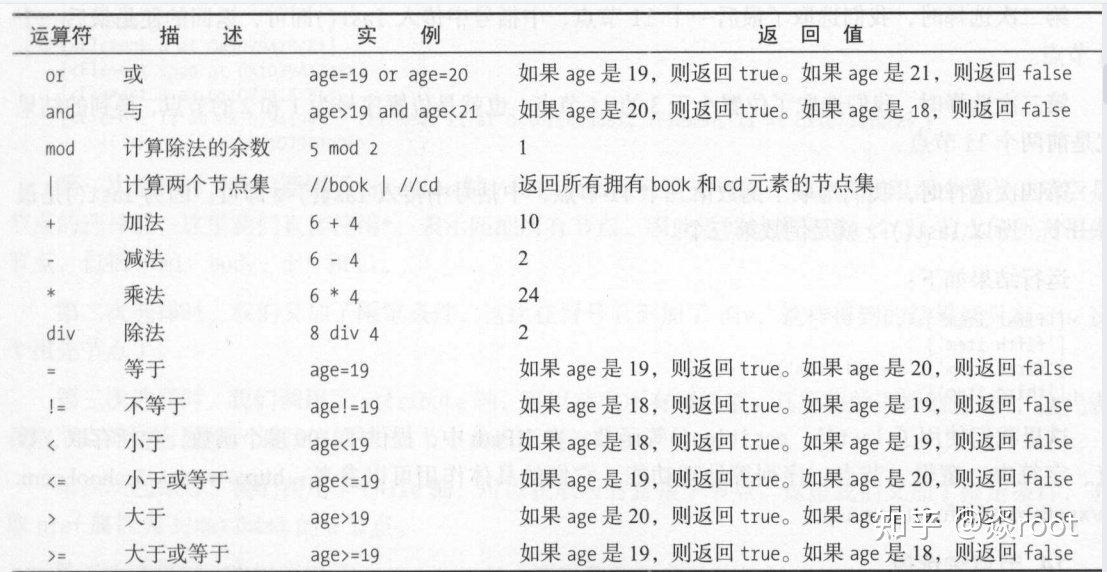
上面的and是运算符
"""
# 10.按序选择
"""
如果需要选中某个节点可以用中括号方法选择
"""
from lxml import etree
data = """
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth2 item</a>
</li></ul>
</div>
</body></html>
"""
html = etree.HTML(data)
res = html.xpath('//li[1]/a/text()') # 获取第一个li标签(这里和代码不同序号是1开头不是0)
print(res) # ['first item']
res2 = html.xpath('//li[last()]/a/text()') # 选取最后一个li节点(last()最后一个)
print(res2) # ['fifth2 item']
res3 = html.xpath('//li[position()<3]/a/text()') # 选取位置小于3的li节点(也就是1和2)
print(res3)
res4 = html.xpath('//li[last()-2]/a/text()') # 选取倒数第三个节点
print(res4)更多用法参考
https://www.w3school.com.cn/xpath/index.asp xpath教程
https://lxml.de/ lxml官网