盘点15个优质爬虫开源项目,yyds!


1、EasySpider
开源地址:https://github.com/NaiboWang/EasySpider
EasySpider 是一款无代码爬虫项目,采用可视化操作界面,无需编写任何代码,只需通过鼠标点击和拖拽,就能完成爬虫任务的设计。
支持多种数据格式的输出,如 CSV、JSON、Excel 等,方便后续的数据分析和处理。
这个项目超级好用,star 已经2万+,非常受欢迎。
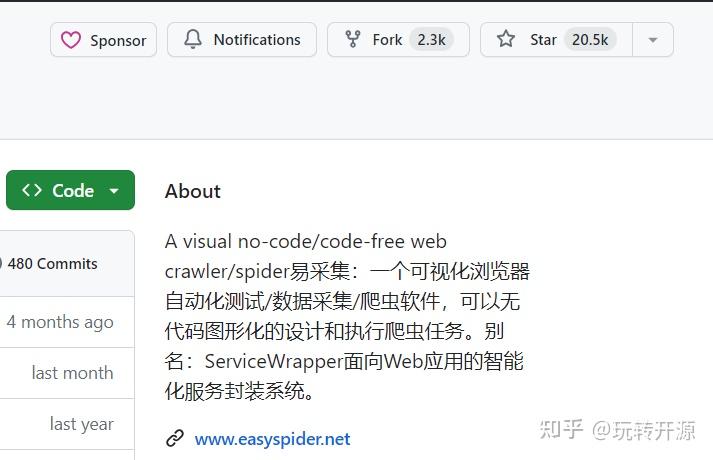
功能特性:
- 开源免费无广告:代码开源,所有功能免费(商用除外),无弹窗和广告。
- 跨平台支持:支持 Windows、MacOS 和 Linux 系统。
- 快速便捷:2-5 分钟设计爬虫任务,支持并行多开,保证采集速度。
- 安全可靠:无需注册,所有任务和数据本地保存,不经过第三方服务器。
- 灵活扩展:可添加浏览器插件、执行 JavaScript 指令、调用系统外部程序。
- 命令行执行:支持命令行方式执行任务,可嵌入到其他程序中。
- 元素截图和 OCR 识别:支持元素截图、OCR 识别和图片下载。
- 定时执行任务:可定时执行任务,成为贴心生活小助手。

2、学习 Solidity
开源地址:https://github.com/AmazingAng/WTF-Solidity
Solidity是一种高级编程语言,专门用于开发以太坊智能合约。它是基于 JavaScript 编写的,并使用类似于 C 语言的语法。
Solidity 被设计成可以在以太坊虚拟机(EVM)上运行,可以让开发人员在以太坊区块链上创建可执行的智能合约。
开发者 @AmazingAng 重新学习 Solidity,写了这个“WTF Solidity极简入门”,现在已经更新了 80 讲。

3、awesome-spider
开源地址:https://github.com/facert/awesome-spider
收集各种爬虫的爬虫合集,按照首字母 A~Z 分类。不多说,给你们截点内容看看:


4、spider-flow(9k+ star)
开源地址:https://github.com/ssssssss-team/spider-flow
智能高效的在线爬虫,平台以流程图的方式定义爬虫,是一个高度灵活可配置的爬虫平台。最强的是,无需写代码就可以快速完成一个简单的爬虫。
5、媒体平台爬虫
开源地址:https://github.com/NanmiCoder/MediaCrawler
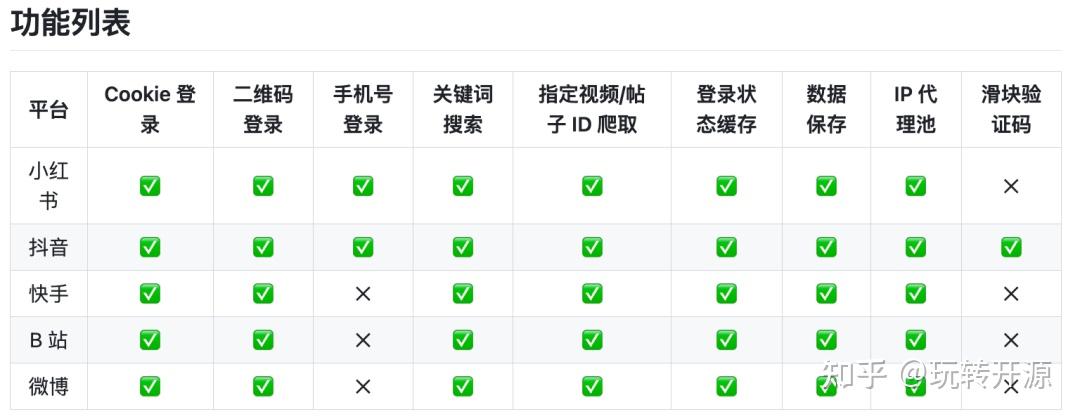
MediaCrawler 由开发者 NanmiCoder 创建和维护。该项目是一个开源的媒体内容爬虫工具集,专注于从多个流行的社交媒体和内容平台上抓取数据,特别是针对小红书笔记、抖音视频、快手视频、B站视频和微博帖子的评论信息。
多平台支持:包括但不限于小红书、抖音、快手、B站和微博。评论抓取:该项目主要关注于抓取用户的评论信息,这对于市场研究、舆论监控和数据分析等方面非常有用。
6、GPT 爬虫
开源地址:https://github.com/BuilderIO/gpt-crawler
这个开源项目名为 GPT Crawler,可以爬取网站内容来生成知识文件。
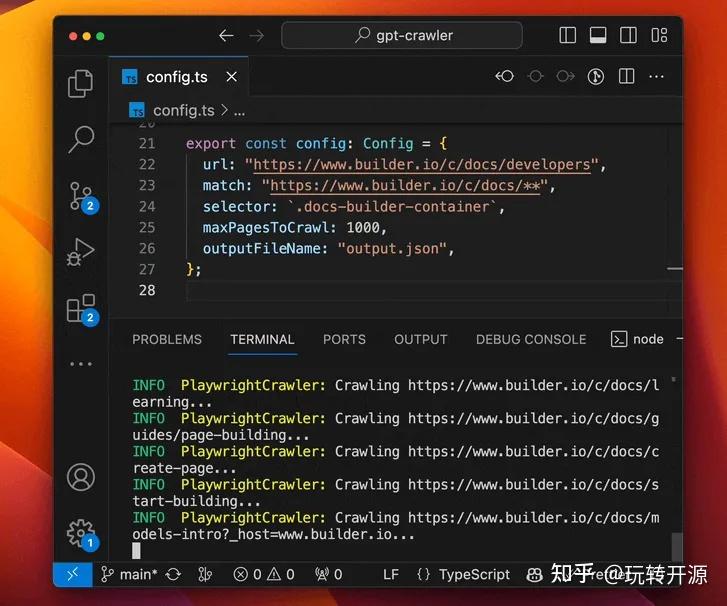
项目展示了如何使用爬虫从指定 URL(例如 http://Builder.io 的文档)进行爬取,配置爬虫参数,比如 URL,选择器,最大爬取页面数等参数。运行后就能爬取该知识网站的内容,输出 Json 文件。
7、FireCrawl
开源地址:https://github.com/mendableai/firecrawl
它能够抓取任何网站的所有可访问子页面,而且无需站点地图,并将这些内容转换为干净的Markdown格式。FireCrawl 与传统的网页爬虫工具不同,即使网站使用JavaScript动态生成其内容,FireCrawl 也能有效地抓取这些内容。
FireCrawl 还提供了一个易于使用的API,使开发者能够通过简单的API调用实现内容的爬取和转换。
抓取任何网站并将其转换为 LLM-ready markdown,按 Mendable.ai 构建。
该存储库目前处于开发的早期阶段。我们正在将自定义模块合并到这个单声道存储库中。主要目标是通过利用干净的数据来提高响应的LLM准确性。它还没有准备好完全自托管 – 我们正在努力。
8、CefSharp .NET爬虫开源项目
开源地址:https://github.com/cefsharp/CefSharp
CefSharp是一个基于Chromium Embedded Framework(CEF)的.NET开源项目。
可以让开发人员非常方便使用C#与浏览器交互,可以操作Html、Css、执行JavaScript代码等方式来处理页面的内容。
支持多线程,方便开发人员创建多个浏览器对象,并可以通过设定CookieContainer和UserAgent来模拟不同用户的操作,提升网页数据采集和速度。
项目优点
1、控件:支持WPF和WinForms web浏览器控件;
2、强大的JS交互能力:支持与JavaScript的双向交互能力,方便Web端与客户端进行数据交互;
3、多线程抓取:支持多线程操作,提升效率;
4、丰富的API:提供了非常丰富的API,使得开发人员非常方便控制和操作Web浏览器;
5、社区:社区非常活跃,案例和资料非常多,方便开发人员进行交流和解决问题。
使用示例
1、加载网页
ChromiumWebBrowser browser = new ChromiumWebBrowser();
browser.Load("https://www.xxx.com");
2、执行Js脚本
browser.ExecuteScriptAsync("document.getElementById('login-button').click();");
3、获取页面Html
public partial class Form1 : Form
{
ChromiumWebBrowser browser;
public Form1()
{
InitializeComponent();
}
private void Form1_Load(object sender, EventArgs e)
{
browser = new ChromiumWebBrowser();
browser.Dock = DockStyle.Fill;
Controls.Add(browser);
browser.FrameLoadEnd += Browser_FrameLoadEnd;
browser.Load("http://www.baidu.com");
}
private void Browser_FrameLoadEnd(object? sender, FrameLoadEndEventArgs e)
{
var task = e.Frame.GetSourceAsync();//HTML源文件作为字符串返回
task.ContinueWith(t =>
{
if (!t.IsFaulted)
{
string resultStr = t.Result;
}
});
}
}
9、DotnetSpider
开源地址:https://github.com/dotnetcore/DotnetSpider
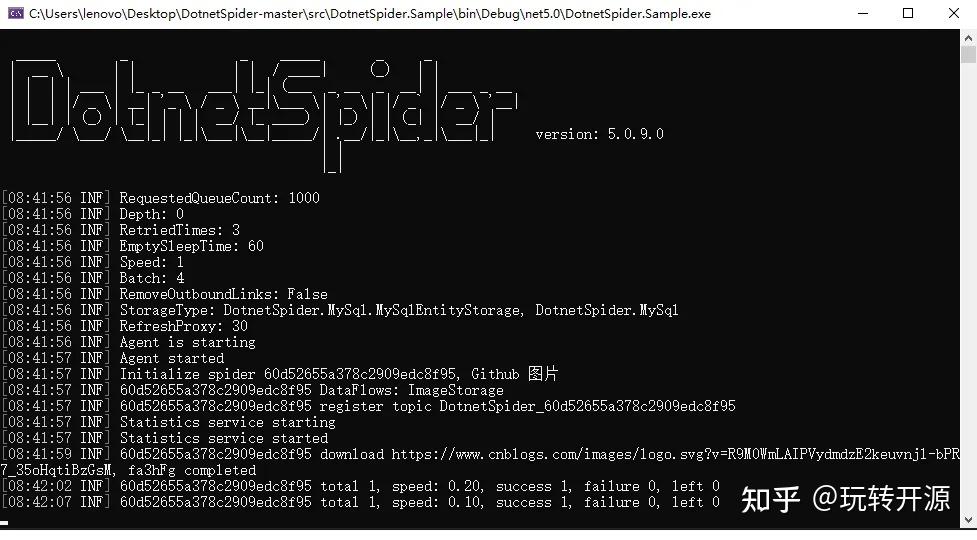
DotnetSpider 是C#.NET开发的轻量、灵活、高性能、跨平台的分布式网络爬虫框架。可以帮助 .NET 工程师快速的完成爬虫的开发。
整个爬虫设计是纯异步的,利用消息队列进行各个组件的解耦,若是只需要单机爬虫则不需要做任何额外的配置,默认使用了一个内存型的消息队列。
10、InfoSpider
开源地址:https://github.com/kangvcar/InfoSpider
INFO-SPIDER 是一个集众多数据源于一身的爬虫工具箱,旨在安全快捷的帮助用户拿回自己的数据,工具代码开源,流程透明。并提供数据分析功能,基于用户数据生成图表文件,使得用户更直观、深入了解自己的信息。目前支持数据源包括GitHub、QQ邮箱、网易邮箱、阿里邮箱、新浪邮箱、Hotmail邮箱、Outlook邮箱、京东、淘宝、支付宝、中国移动、中国联通、中国电信、知乎、哔哩哔哩、网易云音乐、QQ好友、QQ群、生成朋友圈相册、浏览器浏览历史、12306、博客园、CSDN博客、开源中国博客、简书。

功能特点:
- 安全可靠:本项目为开源项目,代码简洁,所有源码可见,本地运行,安全可靠。
- 使用简单:提供 GUI 界面,只需点击所需获取的数据源并根据提示操作即可。
- 结构清晰:本项目的所有数据源相互独立,可移植性高,所有爬虫脚本在项目的 Spiders 文件下。
- 数据源丰富:本项目目前支持多达24+个数据源,持续更新。
- 数据格式统一:爬取的所有数据都将存储为json格式,方便后期数据分析。
- 个人数据丰富:本项目将尽可能多地为你爬取个人数据,后期数据处理可根据需要删减。
- 数据分析:本项目提供个人数据的可视化分析,目前仅部分支持。
- 文档丰富:本项目包含完整全面的使用说明文档和视频教程
11、Colly:Go 实现的比较有名的一款爬虫框架
开源地址: http://github.com/gocolly/colly
colly官网地址:http://go-colly.org/
colly 是 Go 实现的比较有名的一款爬虫框架,而且 Go 在高并发和分布式场景的优势也正是爬虫技术所需要的。它的主要特点是轻量、快速,设计非常优雅,并且分布式的支持也非常简单,易于扩展。
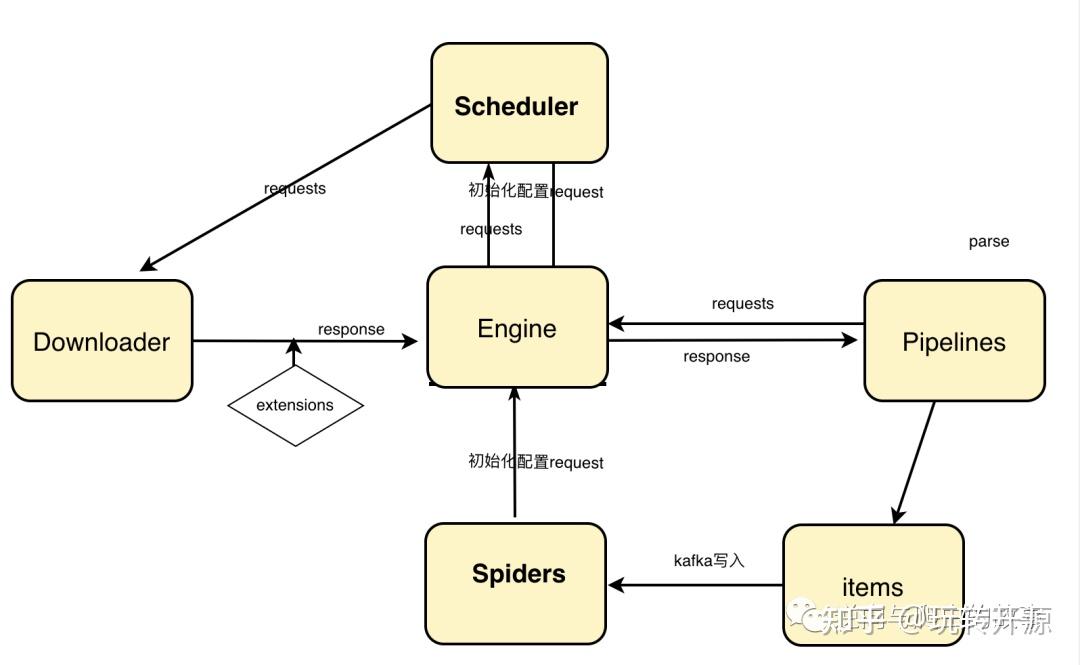
框架简介:基于colly框架及net/http进行封装,实现的一款可配置分布式爬虫架构。使用者只需要配置解析、并发数、入库topic、请求方式、请求url等参数即可,其他代码类似于scrapy,不需要单独编写。
框架优势:实现了重试机制,各个功能可插拔,自定义解析模块、结构体模块等,抽象了调度模块,大大减少代码冗余,快速提高开发能力;其中对于feed流并发的爬虫也能够生效,不止基于深度优先爬虫;也可以用于广度优先。
12、B 站自动任务工具
开源地址:https://github.com/RayWangQvQ/BiliBiliToolPro
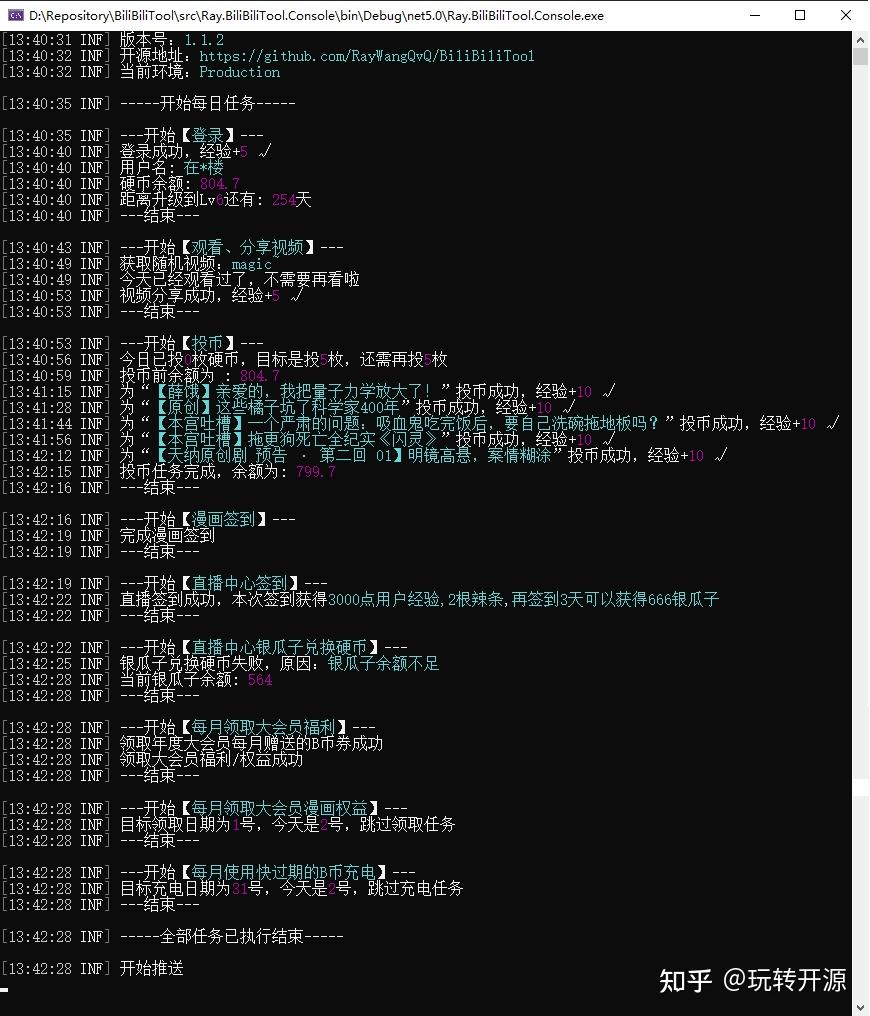
BiliBiliTool 是一个自动化工具,它可以帮助你每天获取经验、每日签到、批量取关等等。详细功能如下:

你可以通过多种方式部署 B站自动化工具,比如:Dorcker、本地运行、Chart部署、腾讯云函数SCF。
13、WechatSogou:微信公众号爬虫
开源地址:https://github.com/Chyroc/WechatSogou
基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。
14、高性能异步抖音爬取工具
开源地址:https://github.com/Evil0ctal/Douyin_TikTok_Download_API
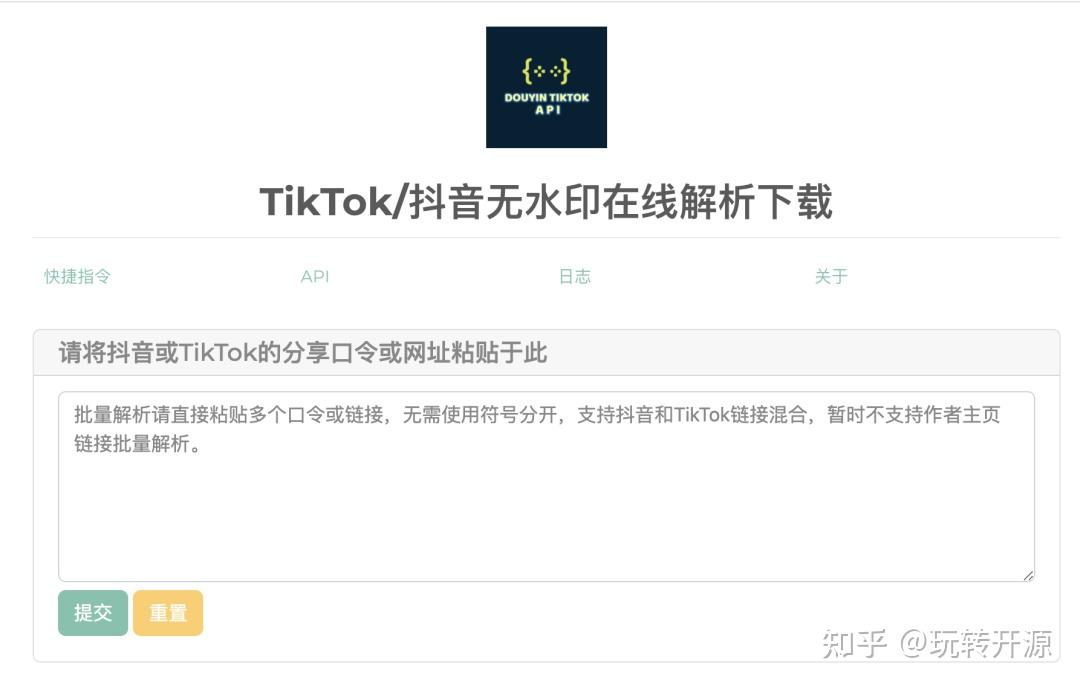
Douyin_TikTok_Download_API 是一个易于使用的高性能异步 API,用于下载 TikTok 内容。它基于 PyWebIO、FastAPI 和 AIOHTTP, 支持 API 调用,支持在线批量解析和下载。可以通过 Web 界面在线批量解析和下载无水印视频或图片。
15、awesome-python-login-model
开源地址:https://github.com/Kr1s77/awesome-python-login-model

Awesome Python Login Model 是一个以Markdown格式编写的文档,包含了各种Python登录模版的代码示例,包括但不限于:
基于Cookie的登录
OAuth2.0认证
JWT(JSON Web Token)身份验证
SMS验证码登录
邮件验证登录等
每个示例都详细解释了其工作原理和使用方法,并且大部分都有可运行的代码片段,方便开发者直接测试和应用到自己的项目中。
技术分析:
该项目的技术亮点在于它展示了如何利用Python的标准库和一些流行第三方库来处理登录认证问题。例如:
HTTP请求 – 使用requests库进行API调用或模拟登录。
数据加密 – hashlib 和 cryptography 库用于密码哈希和加解密操作。
Web Tokens – PyJWT 库用于生成和验证JWT。
OAuth2 – oauthlib 和 requests-oauthlib 提供OAuth2协议的支持。
每个模版都按照最佳实践进行了设计,确保了安全性并遵循了相关规范。
应用场景:
无论你是初学者还是经验丰富的开发者,这个项目都能为你提供实用的价值:
学习和研究 – 对于想要了解不同登录机制的开发者来说,这是一个极好的起点,可以深入了解各种认证方法的细节。
快速原型 – 如果你在短时间内需要搭建一个登录系统,你可以直接复制这里的代码片段,根据需求进行修改。
代码审查 – 在团队中,它可以作为代码质量标准的一个参考,确保你的登录模块符合行业最佳实践。
最后
如有帮助,点赞支持一下!
如有更多的爬虫开源项目,欢迎在评论中指出。