利用爬虫技术能做到哪些很酷很有趣很有用的事情?
链接:https://www.zhihu.com/question/27621722/answer/73919752478
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Clipsheet是一款完全开源的Chrome爬虫插件, 通过易用的交互界面以所见即所得的方式, 快速的从页面中采集到你想要的表格,且可以通过简单配置将采集工作自动化。
[Github]: https://github.com/dream-num/univer-clipsheet
[官方网站]: Univer | ClipSheet
[Chrome商店]: Chrome插件商店-Clipsheet
如何安装 Clipsheet ?
可以直接访问上面的 Chrome商店链接安装,如果无法访问外网,可以通过该下载链接https://xakbyahbro.feishu.cn/docx/YU2BdTIqYo4rtIxZxLOctWvxnCh,下载插件的压缩包安装。
[插件压缩包安装教程]:Docs
快速开始
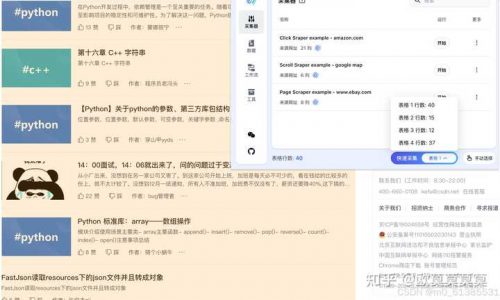
安装插件成功后,以CSDN的文章列表页https://blog.csdn.net/?spm=1001.2101.3001.4477作为展示, 可以看到Clipsheet插件已经在该网页中自动检测到 4 个表格,此时插件内 快速采集 的按钮也是高亮的, 直接点击按钮就可以通过插件采集到我们的第一个表格
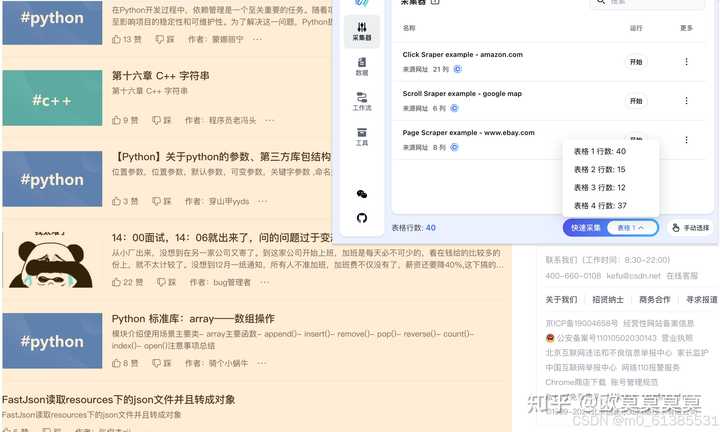
1、点击快速采集后,这时我们能看到右上角有个面板,并高亮选中了当前表格,点击确认按钮
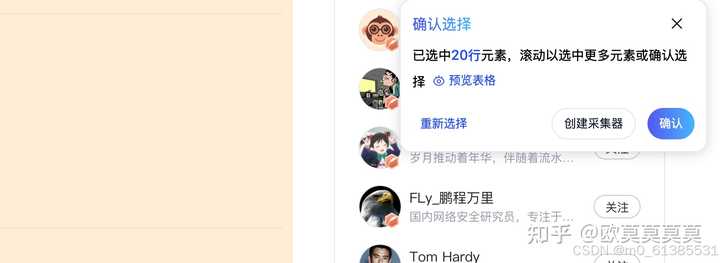
2、这里能看到表格已经提示采集成功,我们点击查看表格

3、此时弹出了一个表格弹窗,能看到已经成功采集到了第一个表格,我们同时也支持将表格导出成csv,能看到左下角就有个按钮能支持支持导出csv
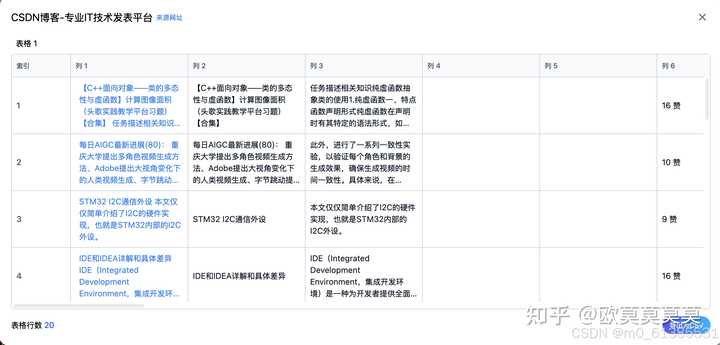
4、至此我们就简单完成了如何用univer-clipsheet从网页中采集表格,当然,现在的整个流程都需要我们自己手动去完成,但这在你快速需要采集当前网页一个表格数据时也非常有用。
高级功能教程:
仅通过所见即所得的方式从网页中采集表格可能是不够的,univer-clipsheet提供各种高级功能以便我们将采集这一过程自动化,在这个章节我们会介绍clipsheet的部份高级功能,让你更好的优化自己的采集流程,如果使用上还有任何问题,欢迎及时联系我们反馈
采集器讲解-执行操作
使用采集器可以将你的重复的采集动作自动化
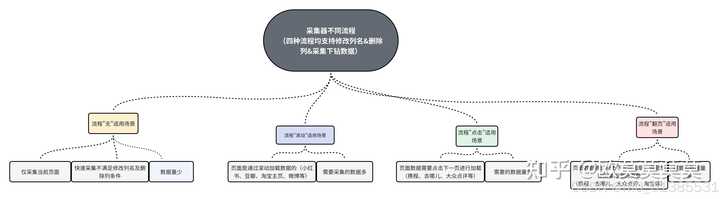
操作步骤:
1、先打开要采集的网站,并点击右上角的小插件
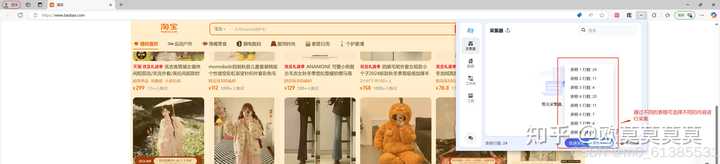
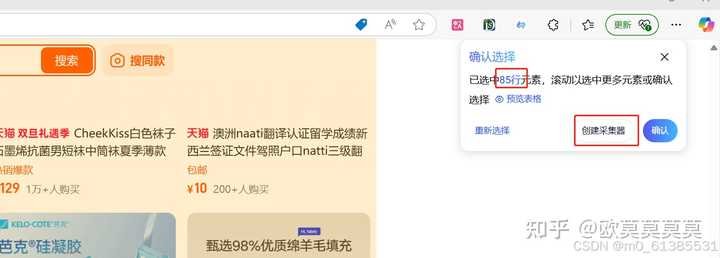
2、通过滚动页面,可以获取更多元素哦,查看右上角的×行元素知道大概的采集行数
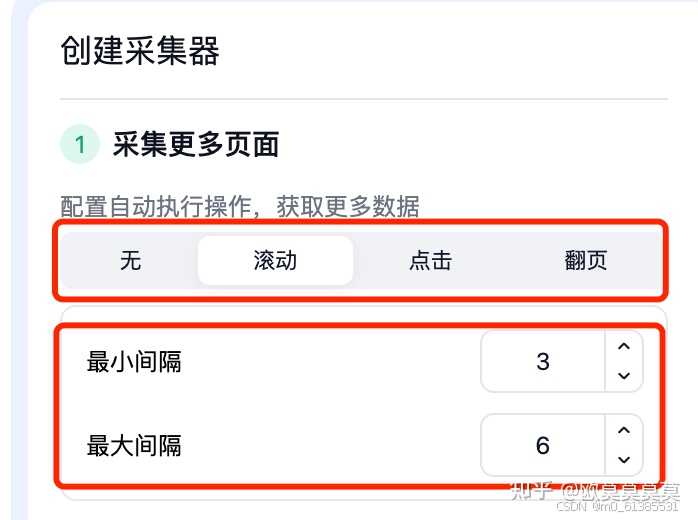
3、根据不同网页加载数据的方式在采集器内设置对应的操作
- 数据量较大时建议将间隔时间设置的稍微长一些
4、想要采集标题对应的内容时可以设置下钻,选择想要的内容区域
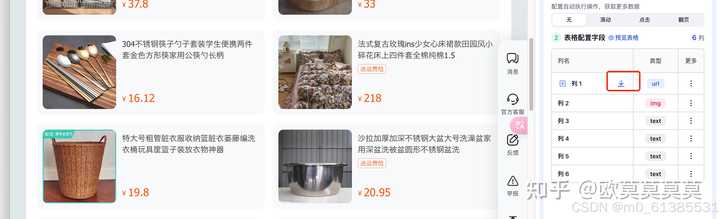
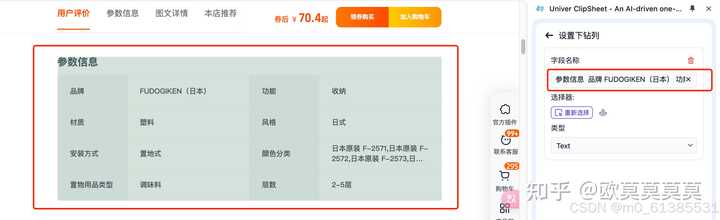
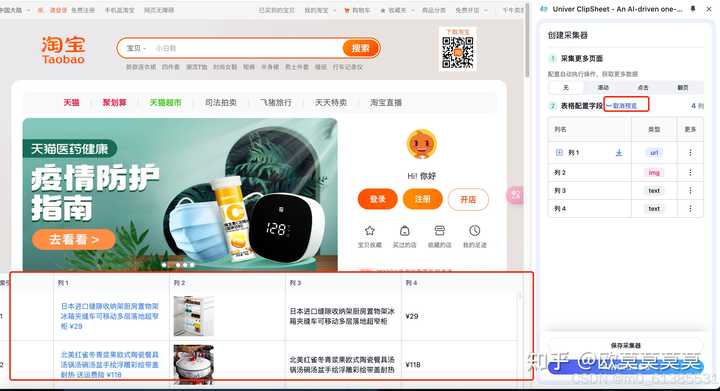
5、可以通过查看预览页自定义调整列
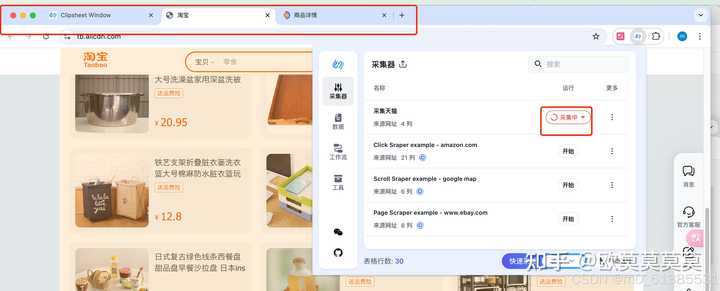
6、运行采集器时会打开一个新的页面,可以通过该页面确定采集的进度
7、采集完成后通过侧边栏 – 数据查看文档并导出
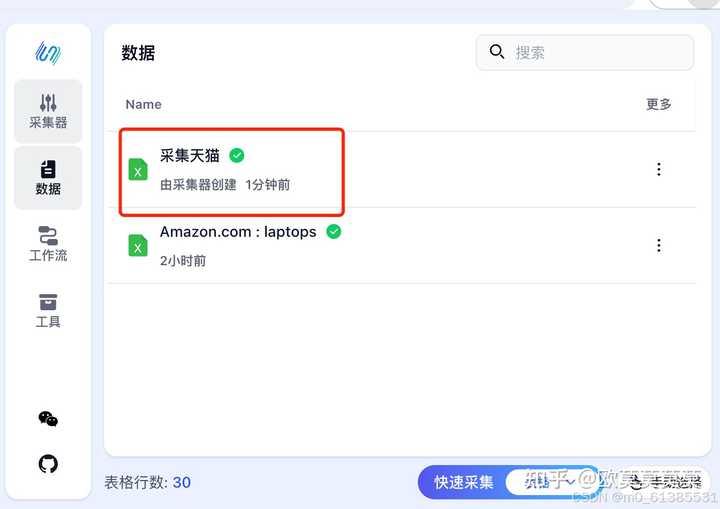

工作流讲解:定时采集&定时更新采集
操作步骤:
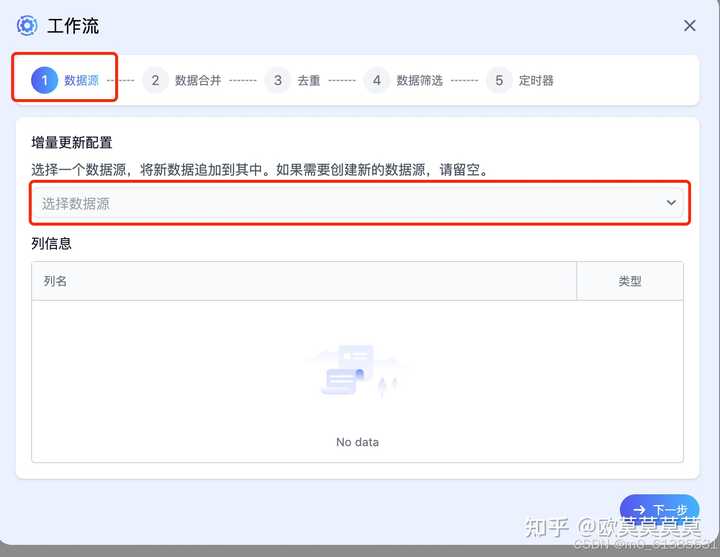
1、新增工作流,会展示选择数据源选项
- 选择数据源时,会往对应的表格内新增数据
- 未选择数据源时,会自动采集生成一个文档
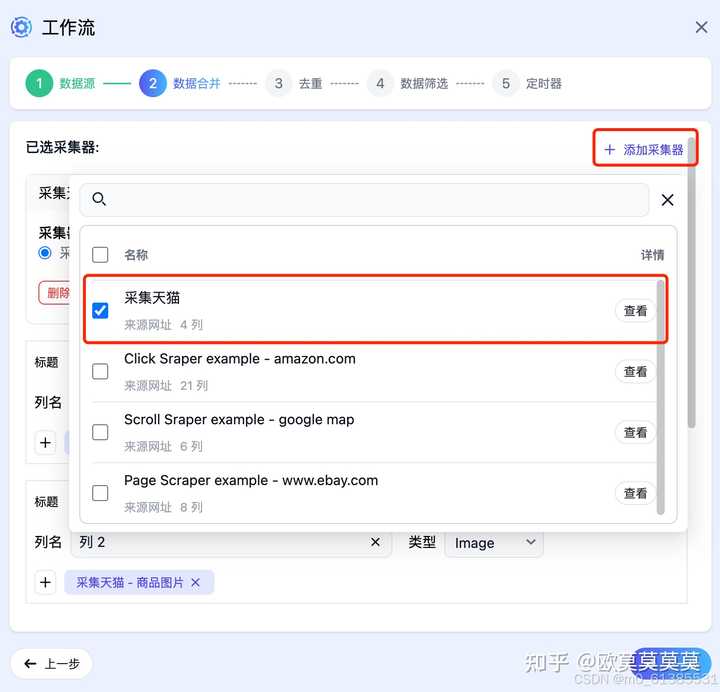
2、在数据合并页面绑定要运行的采集器(教程见采集器讲解) ,自定义调整列后点击下一步
- 可以绑定多个采集器,数据会统一汇总的到表格内
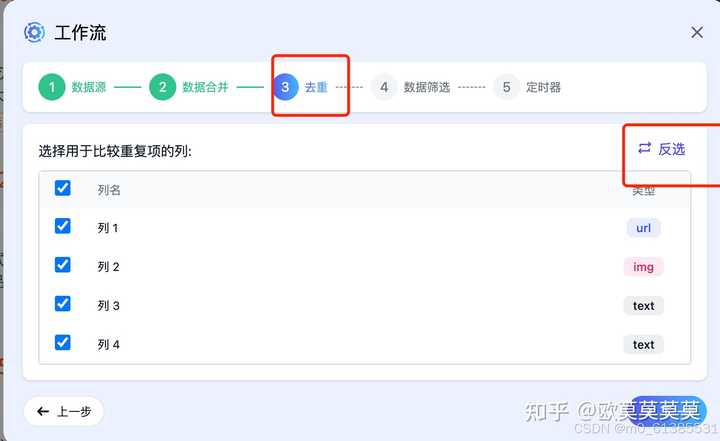
3、默认去重(比较所有的列),如不需要去重可以点击反选取消
4、在数据筛选页面可以设置过滤规则,采集想要的关键词数据等
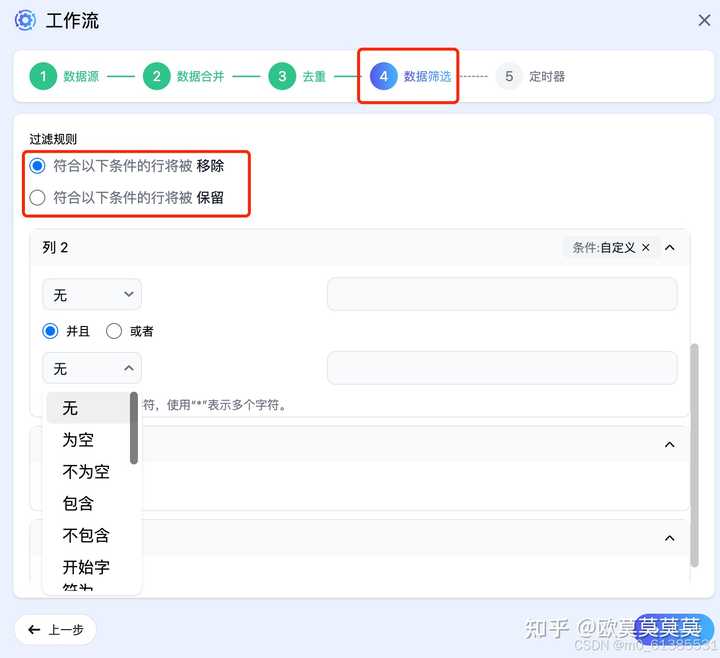
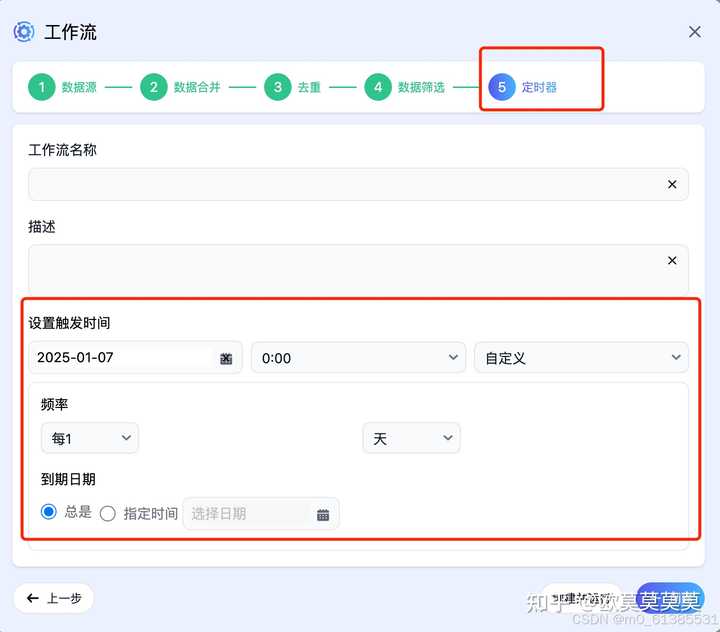
5、上面都设置完成后,我们就可以设置定时并保存运行啦
- 到时间点后会自动采集数据,在侧边栏的数据内可查看数据并导出
看完想要开开发自己的爬虫插件?我教你!
开发插件的内容较多,我单独开了新的文章去更新这部分内容,请通过以下文章阅读https://zhuanlan.zhihu.com/p/16971078935?utm_psn=1860075259723669504
联系我们
Clipsheet插件使用中有任何问题或者优化建议,欢迎通过github来提交issue上报问题,或通过以下方式来联系我们
[Discord] https://discord.gg/rbZcJPm4un