Dify-0009-应用模版-助手-股票新闻情感分析


0、背景
从本篇开始,研究一下 Dify 应用模板 ~
按照官方分类包括:助手、智能体 Agent、人力资源、编程、工作流、写作。
(1)本系列文章
1、股票新闻情感分析
(0)从应用模板创建
(1)整体流程
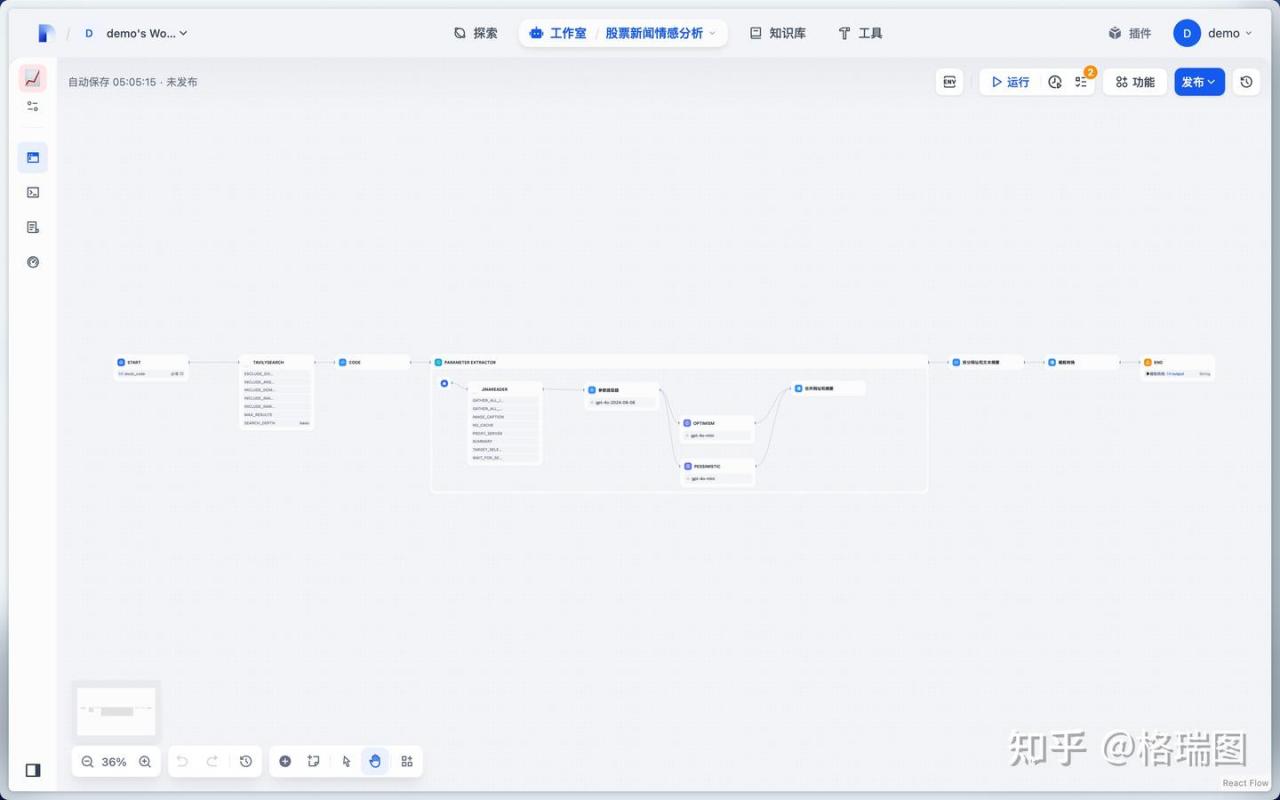
(2)开始节点
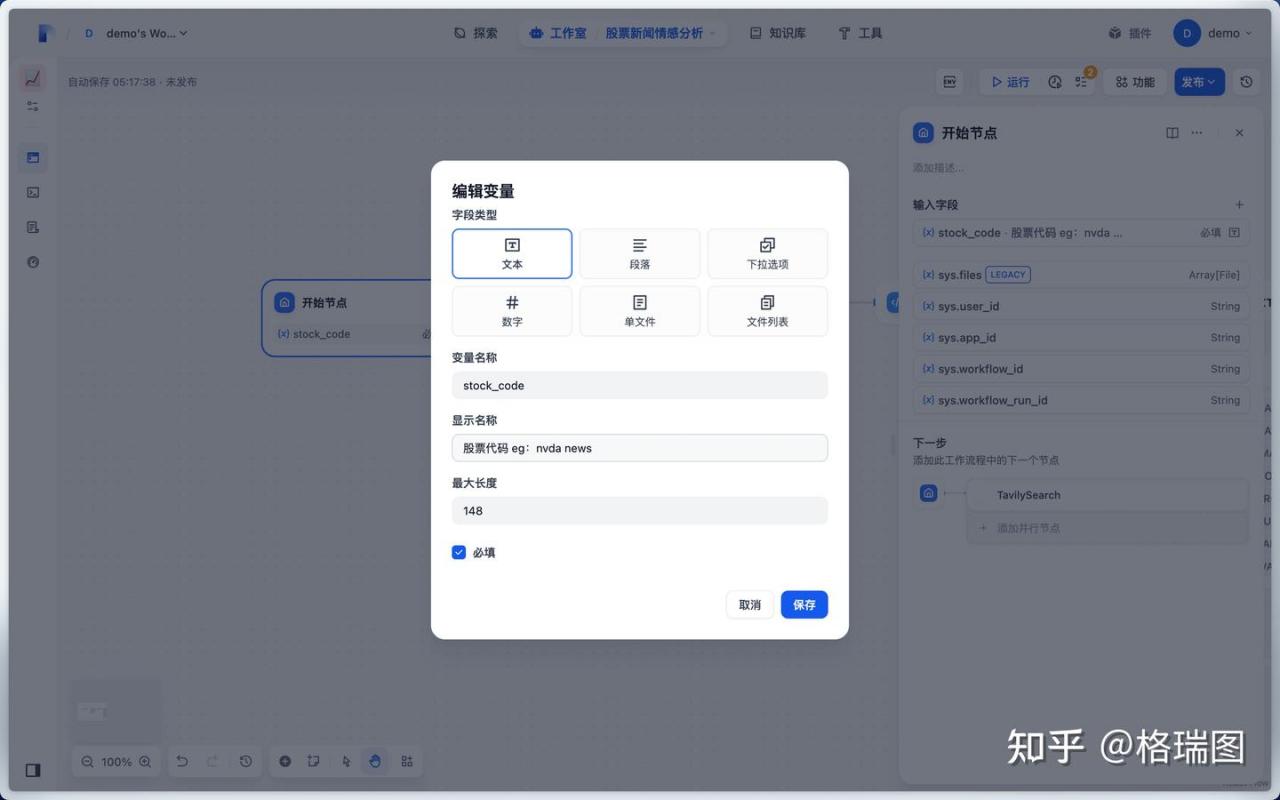
(3)搜索引擎
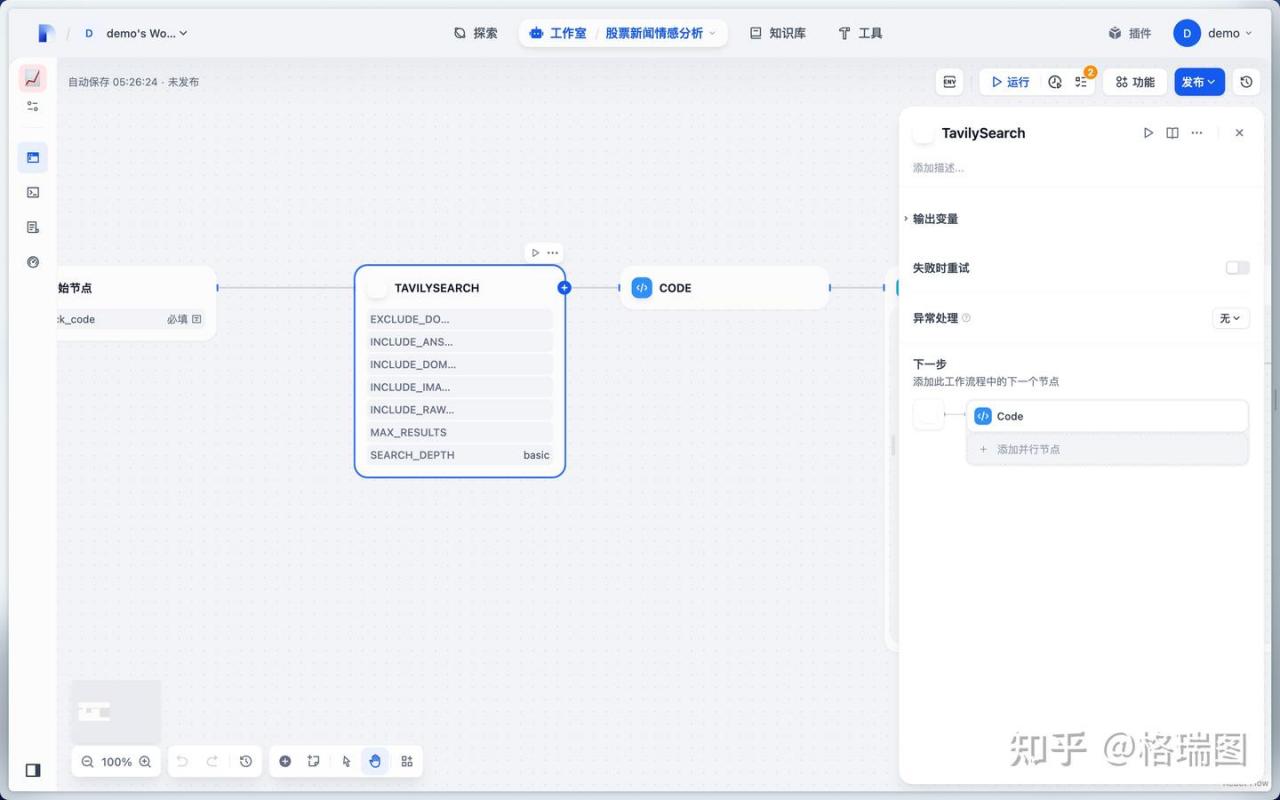
01.不了解当前节点是什么插件。
通过在 Dify 市场搜索 Tavily 得知是一个强大的原生 AI 搜索引擎和网页内容提取工具,提供高度相关的搜索结果和网页原始内容提取。
02.进入详情页面点击下载到本地。
03.通过插件本地插件按钮安装。
04.浏览本地文件安装插件。
05.安装完毕。
06.回到工作室可以看到节点已正确显示图标以及可以进行授权。
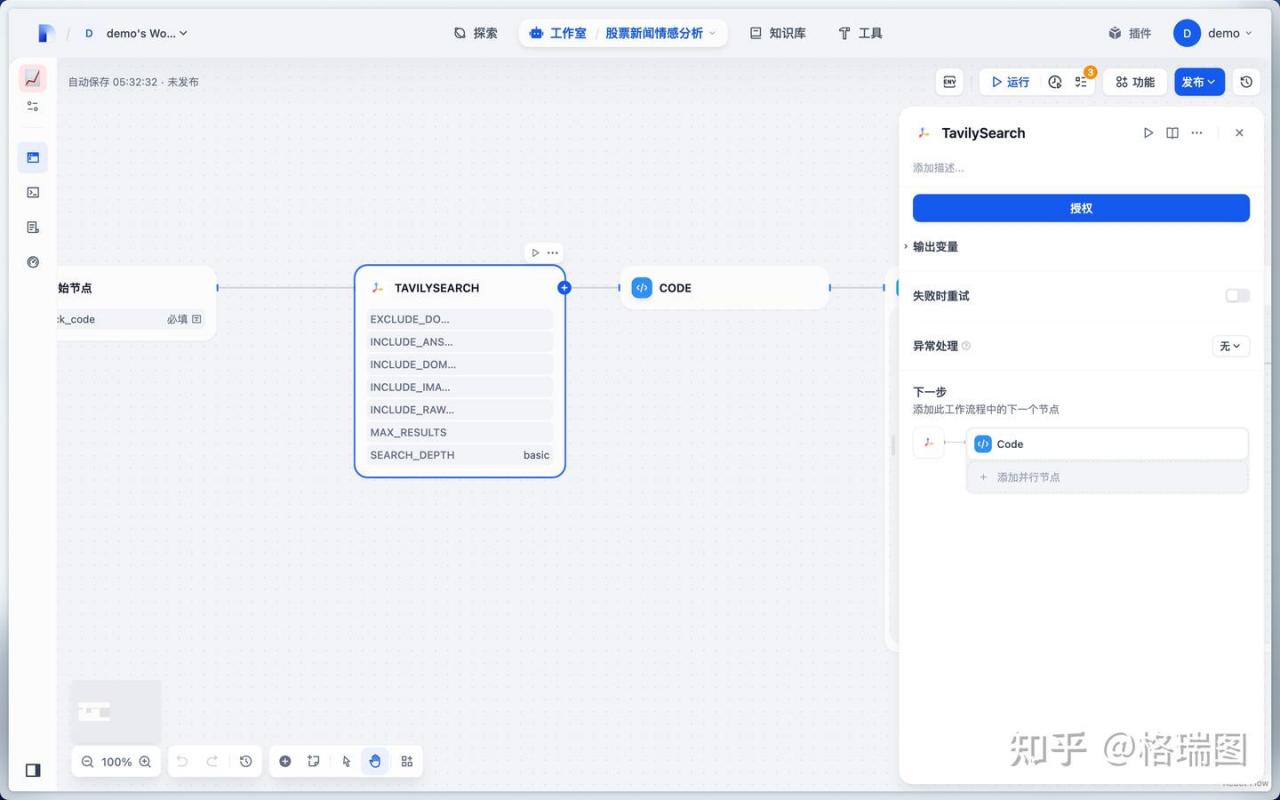
07.设置授权。
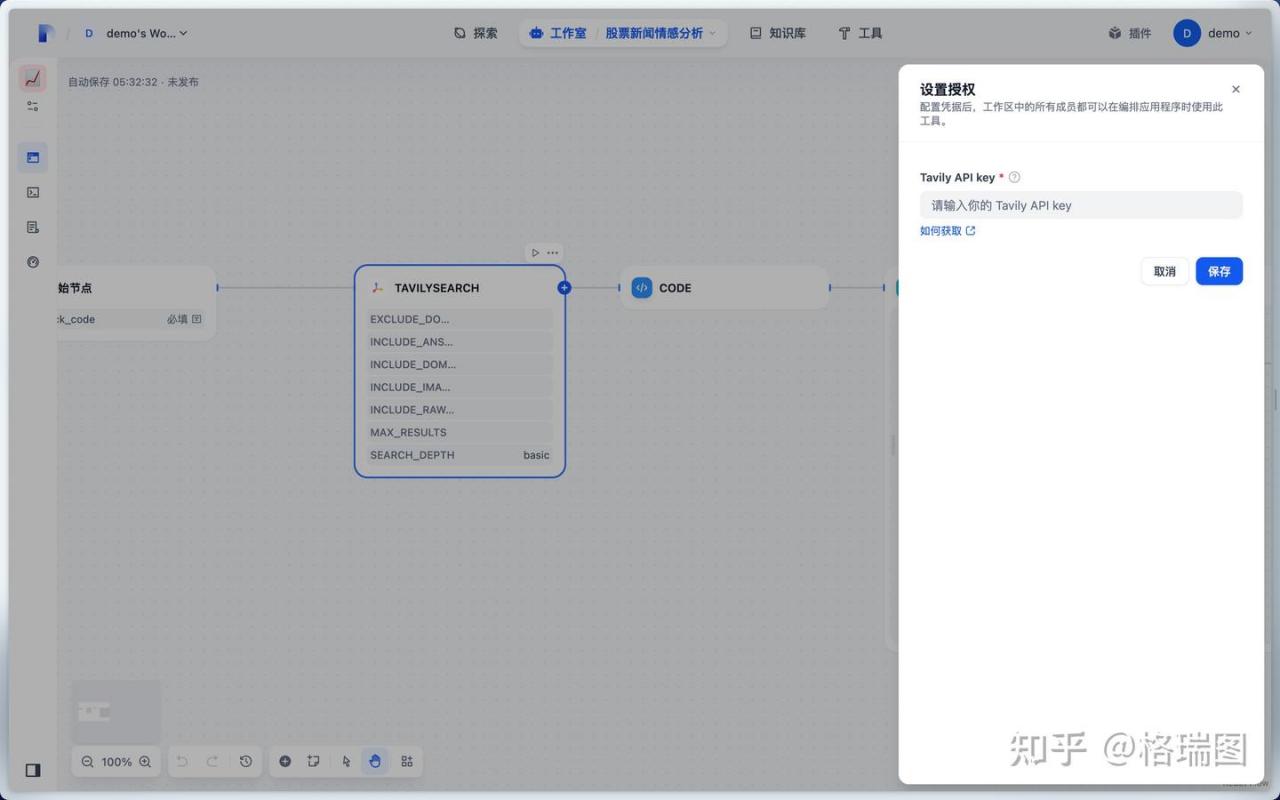
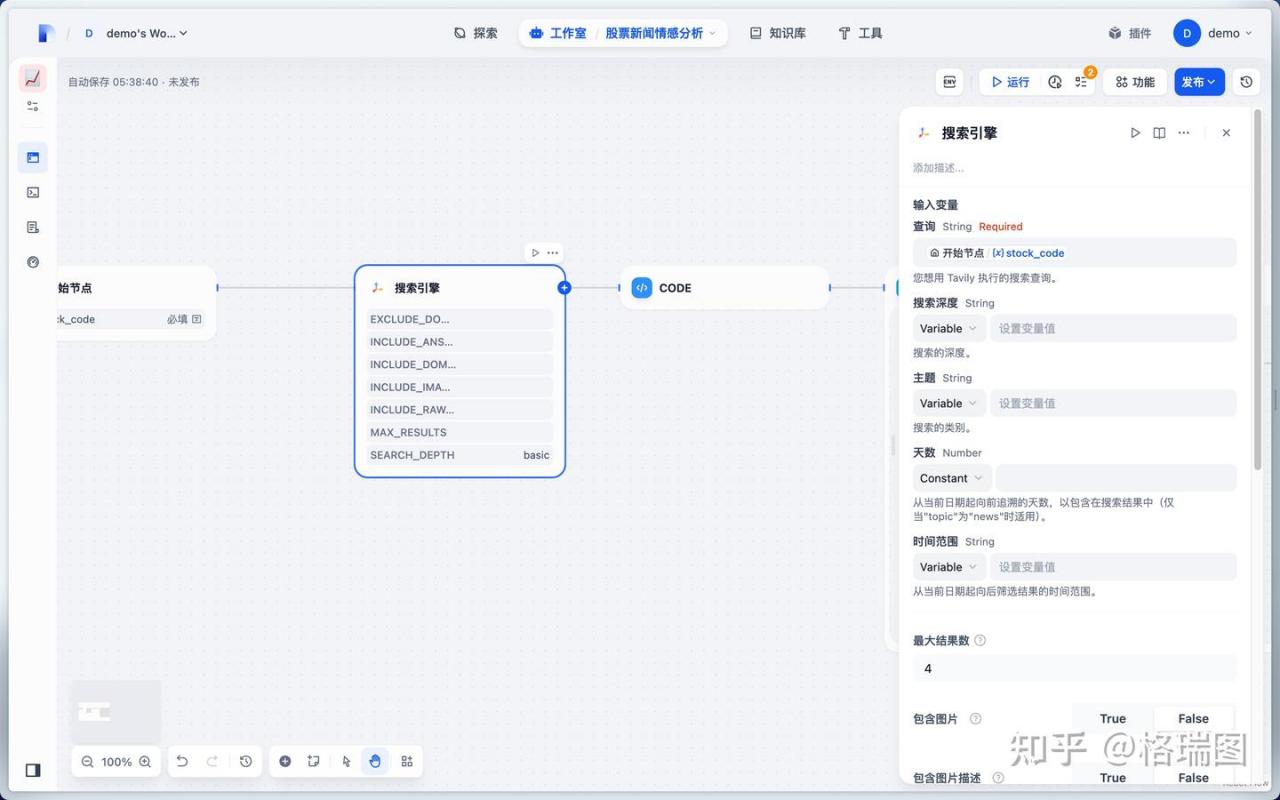
08.很多参数需要设置。
(4)代码节点
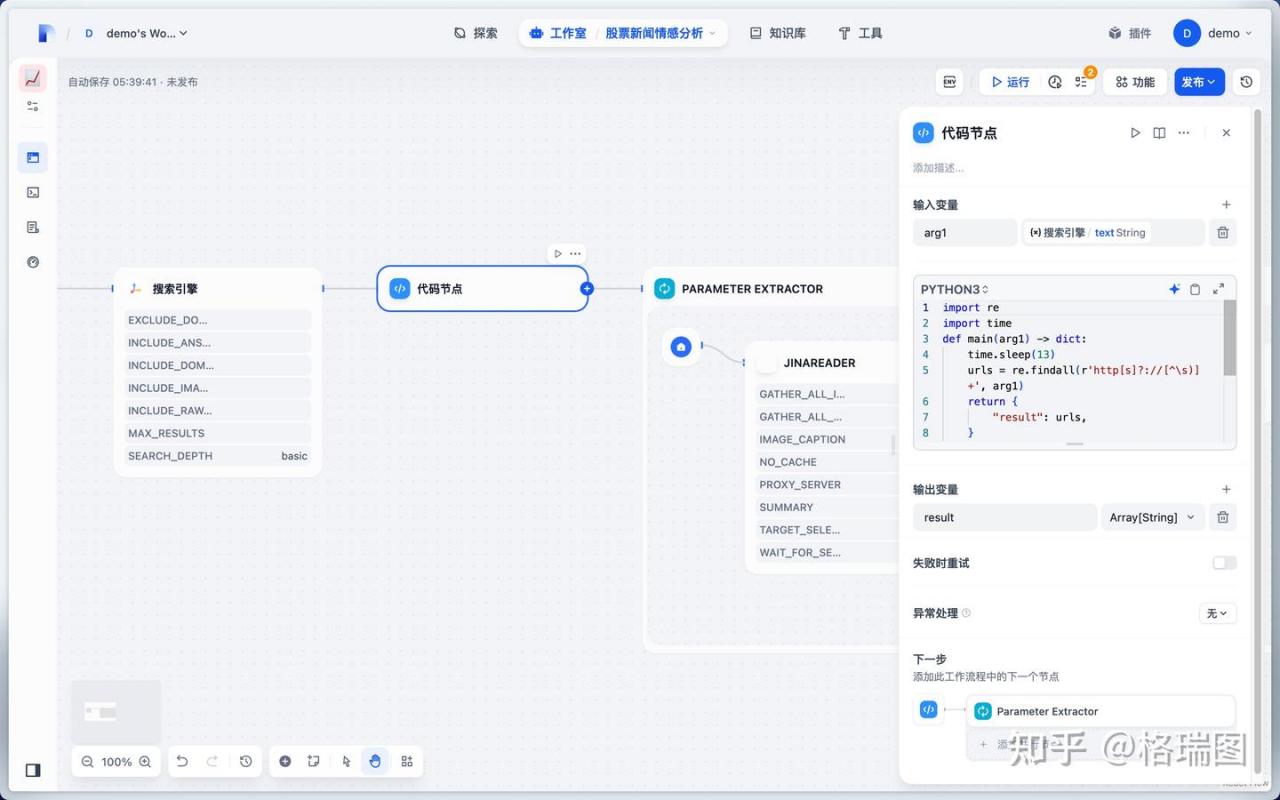
import re
import time
def main(arg1) -> dict:
time.sleep(13)
urls = re.findall(r'http[s]?://[^\s)]+', arg1)
return {
"result": urls,
}代码解析:主要使用了正则表达式来匹配所有的网址。
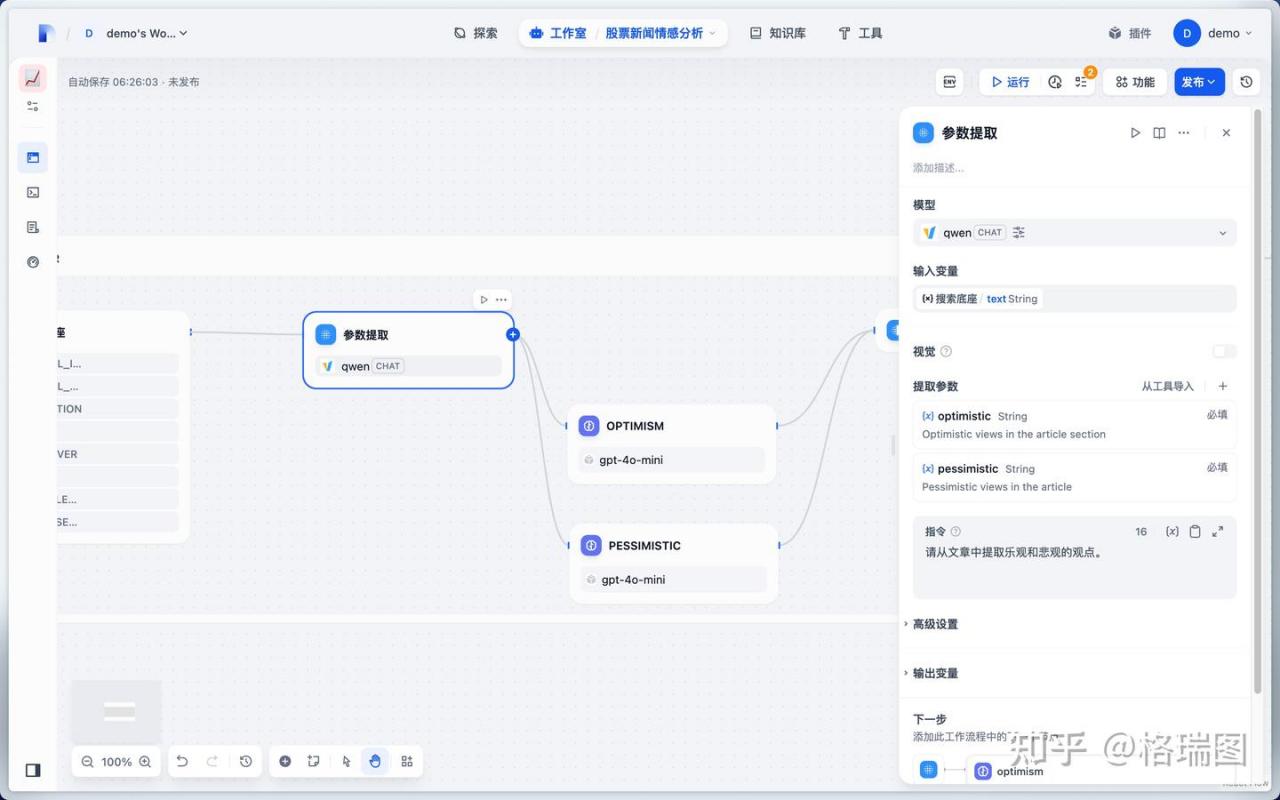
(5)参数抽取
01.参数抽取是一个迭代节点。对前面代码抽取到的网址清单进行迭代。
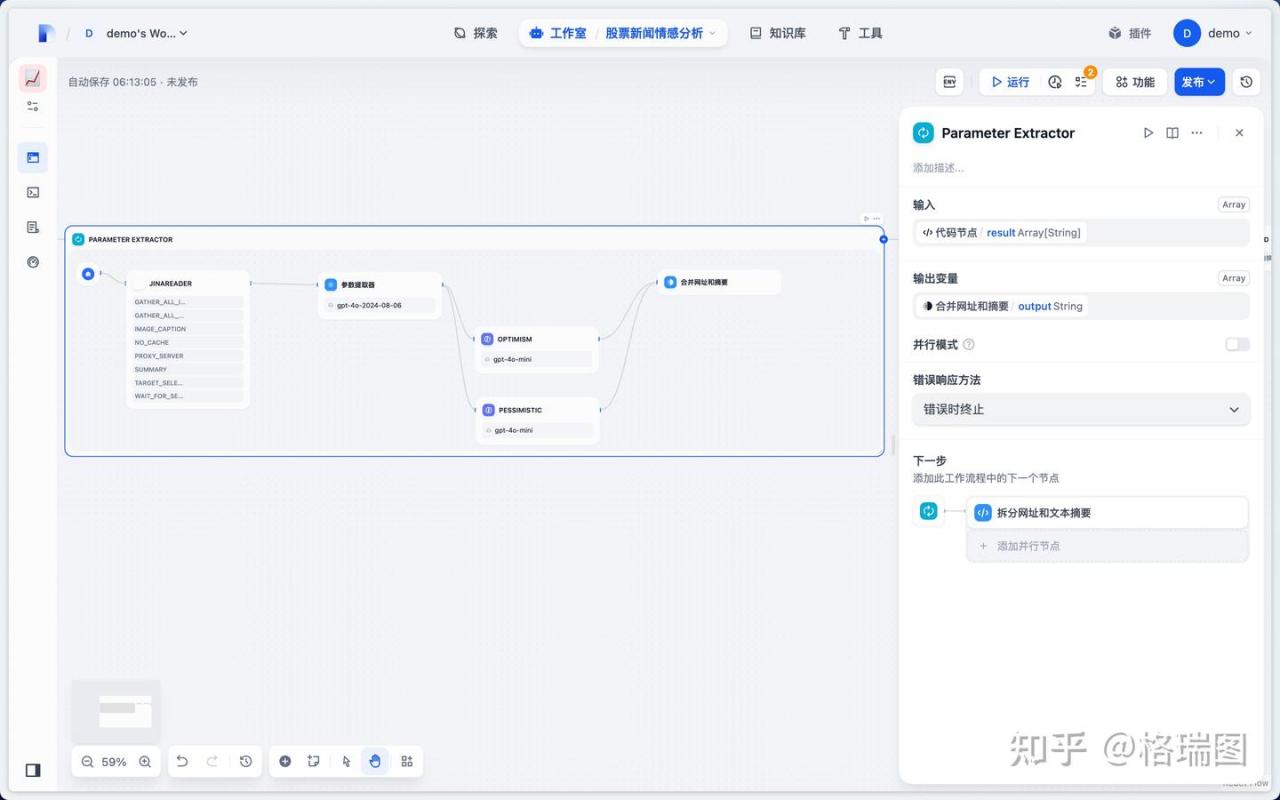
02.暂时
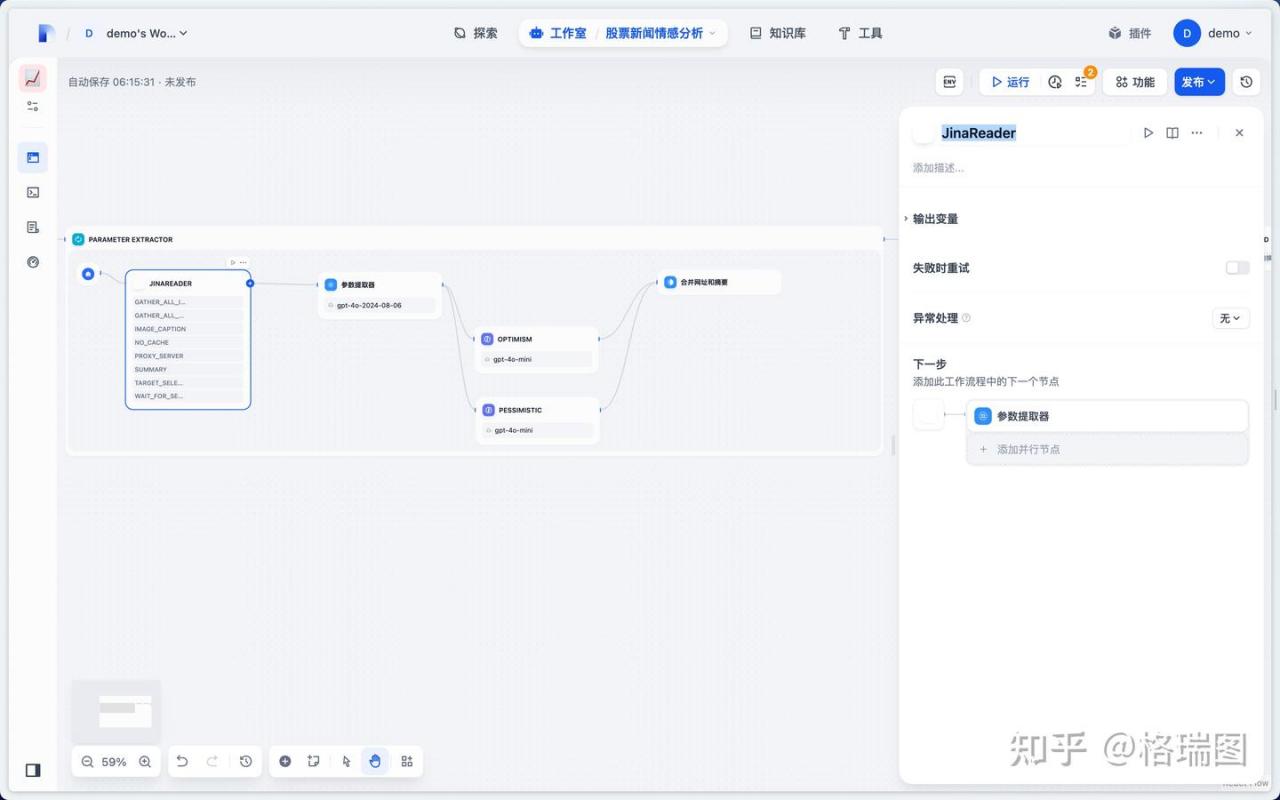
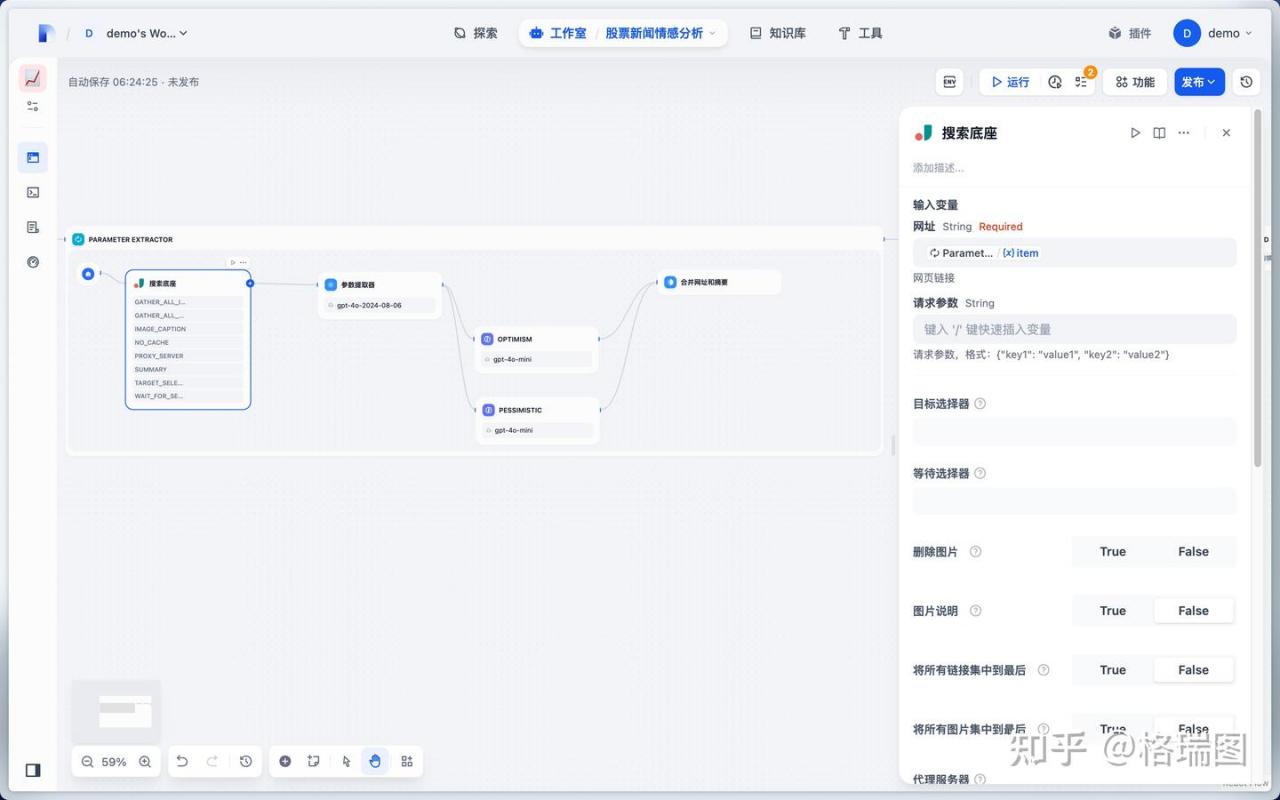
03.搜索 Jina 得知应为工具 Jina AI。您的搜索底座,从此不同!
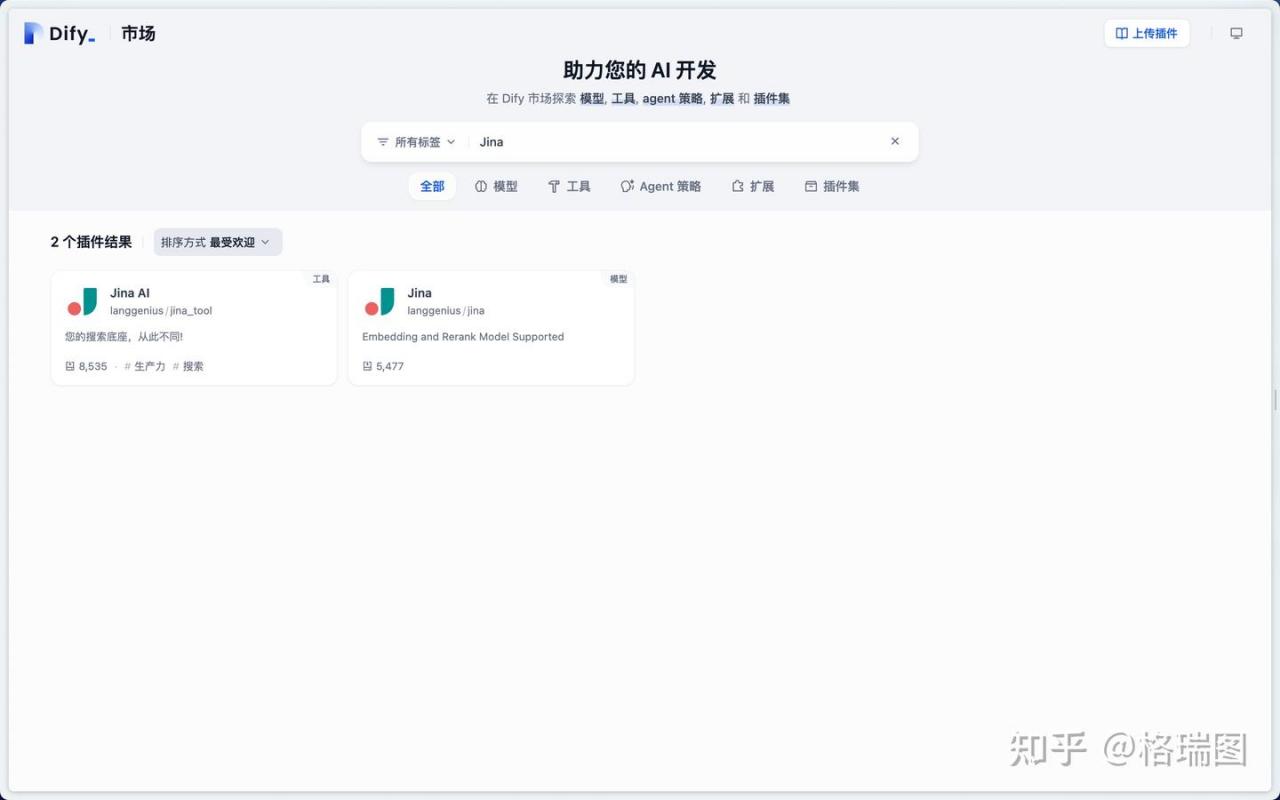
04.按照(3)中搜索引擎插件安装方式安装此工具。
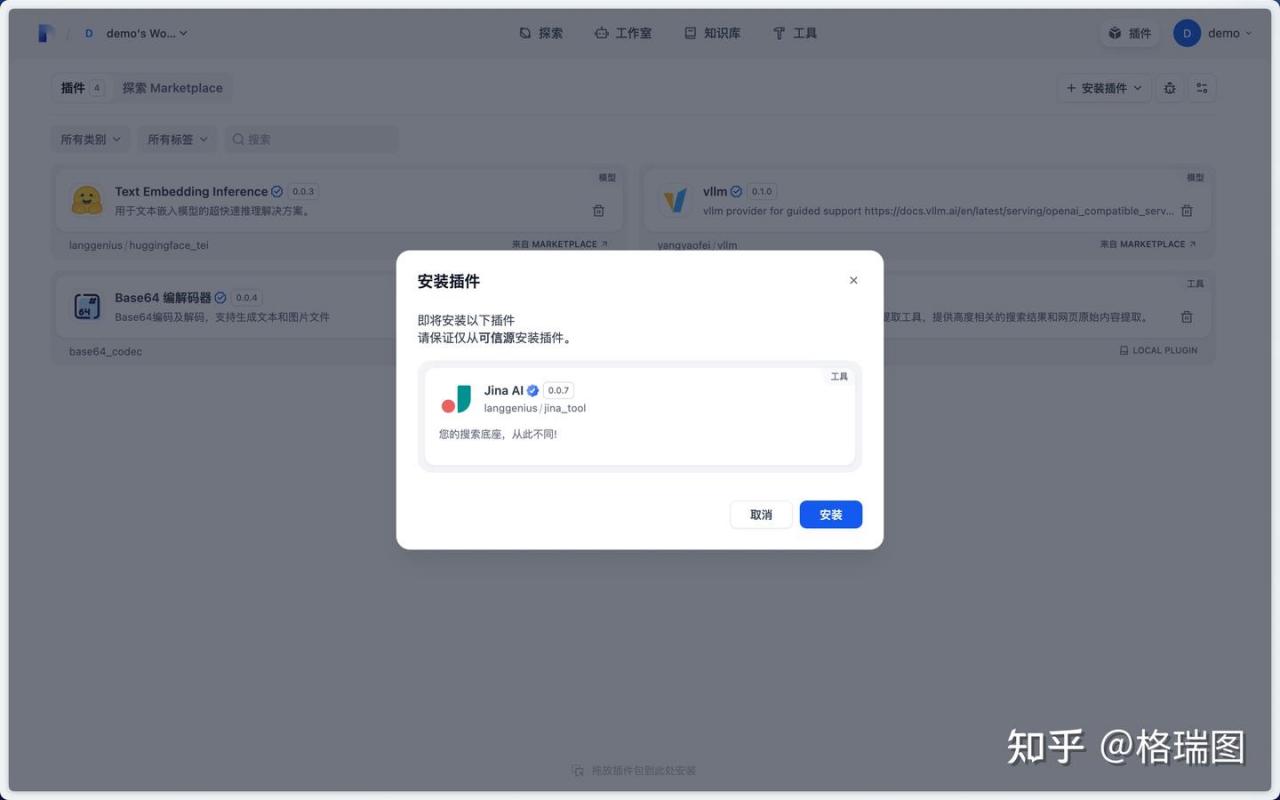
05.授权 官方很炫酷 ~
(6)参数提取
01.切换为本地部署的 DeepSeek-R1-Distill-Qwen-32B。
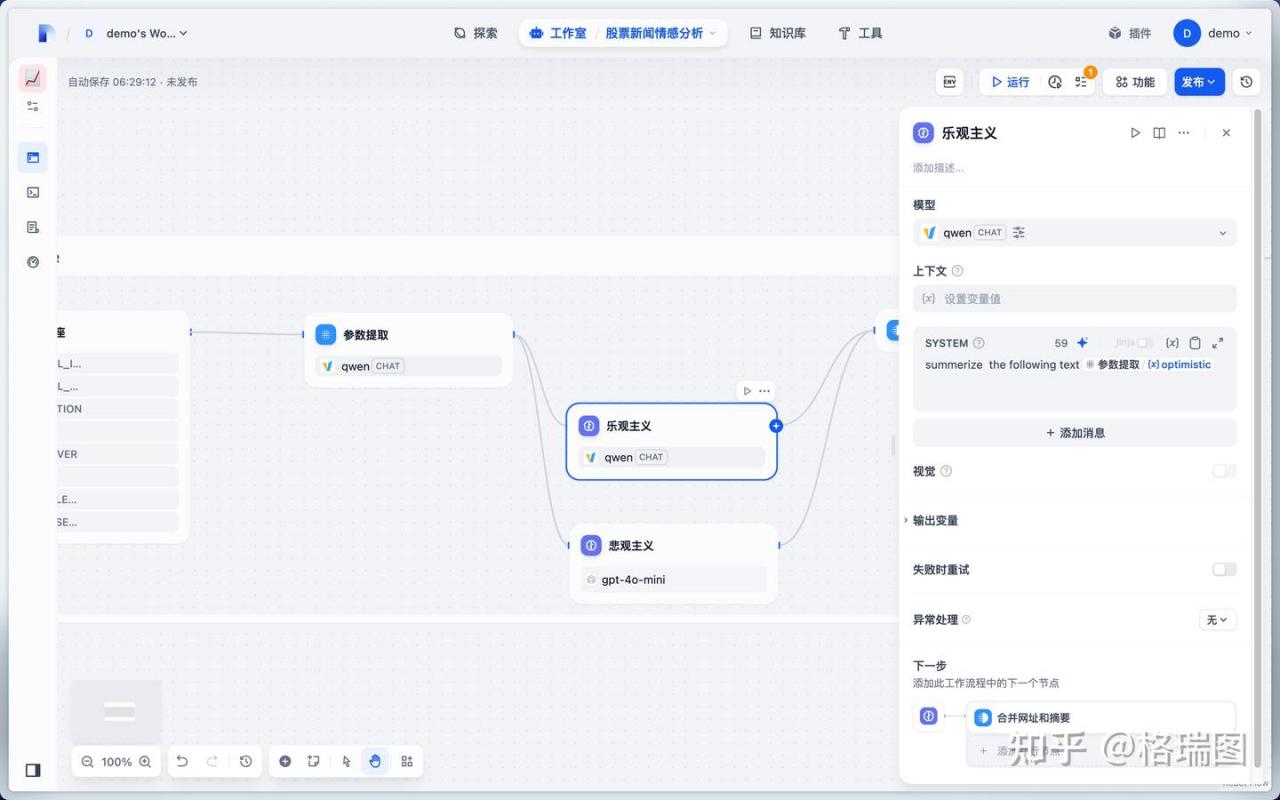
02.乐观主义。
03.悲观主义
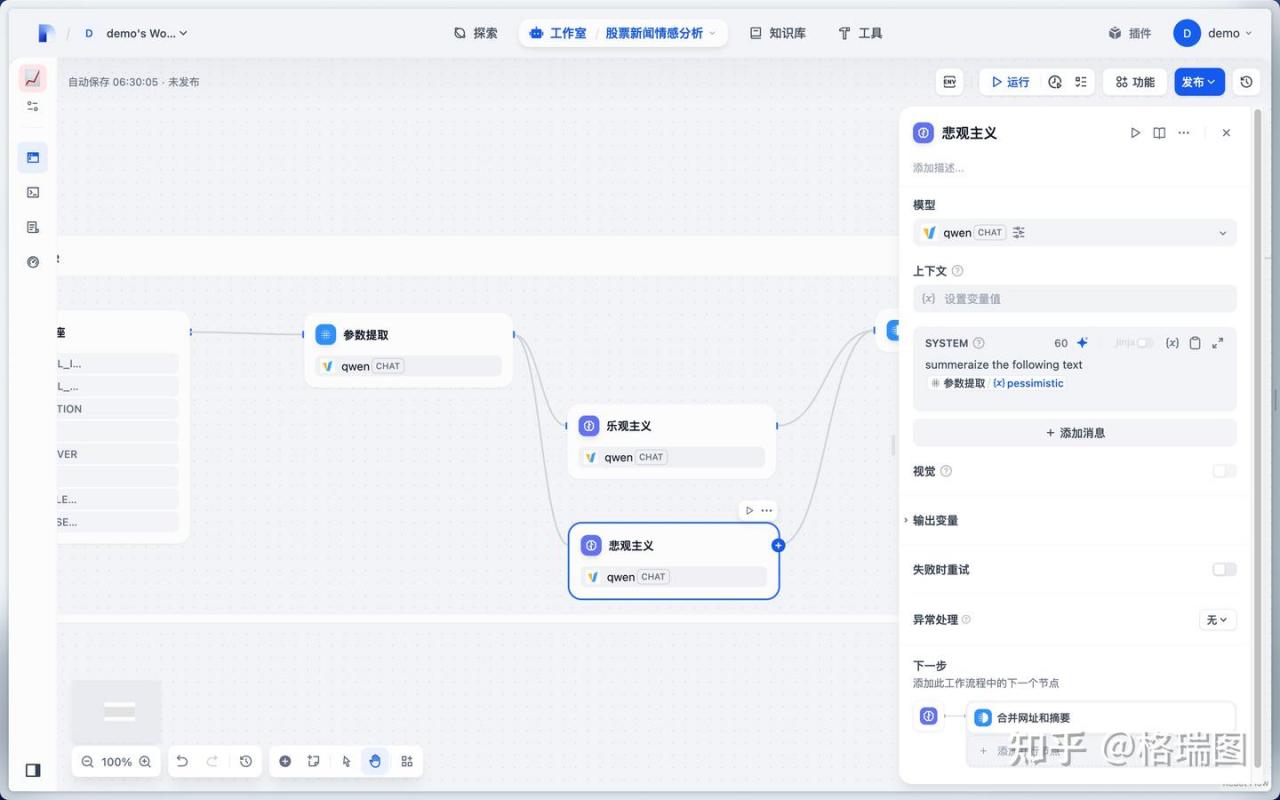
上述 3 个节点都在调用大语言模型,切换为本地模型。
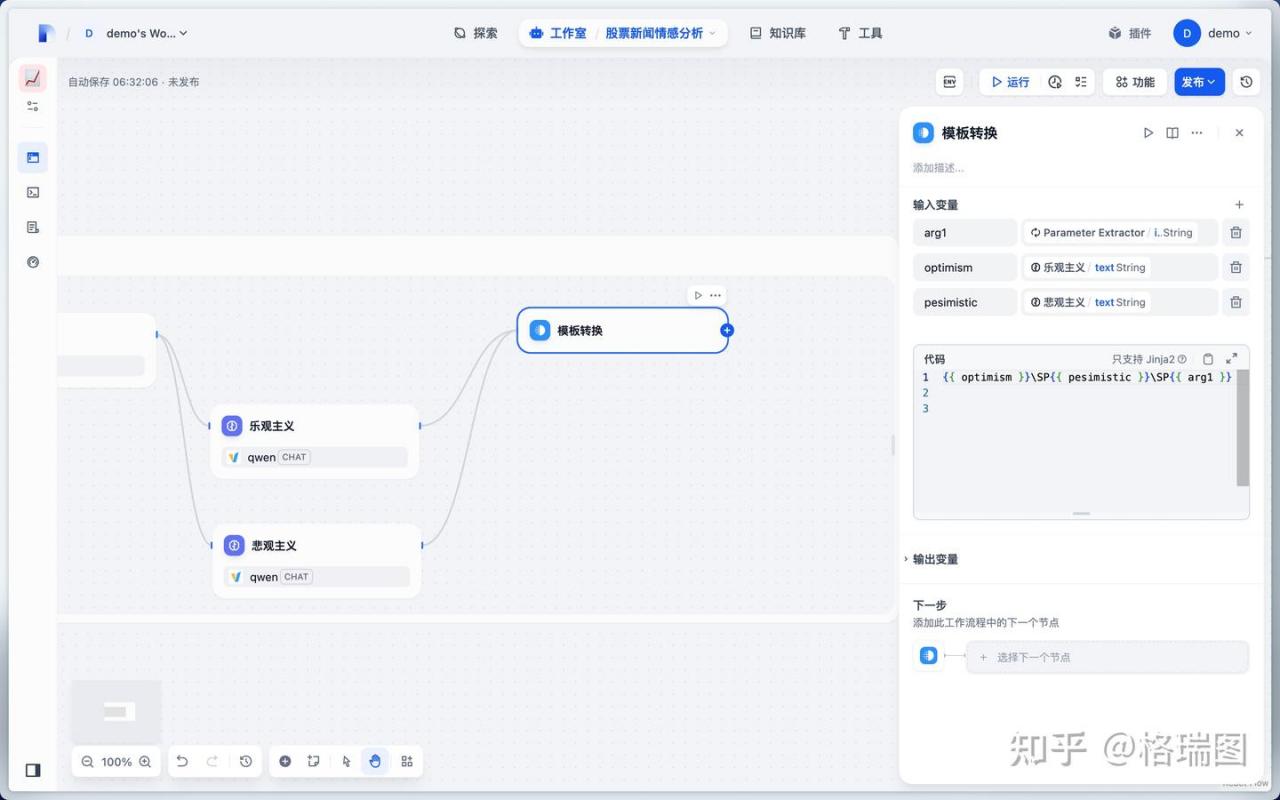
(7)模板转换
使用 Jinja2 语法输出格式化数据。
(8)脚本拆分
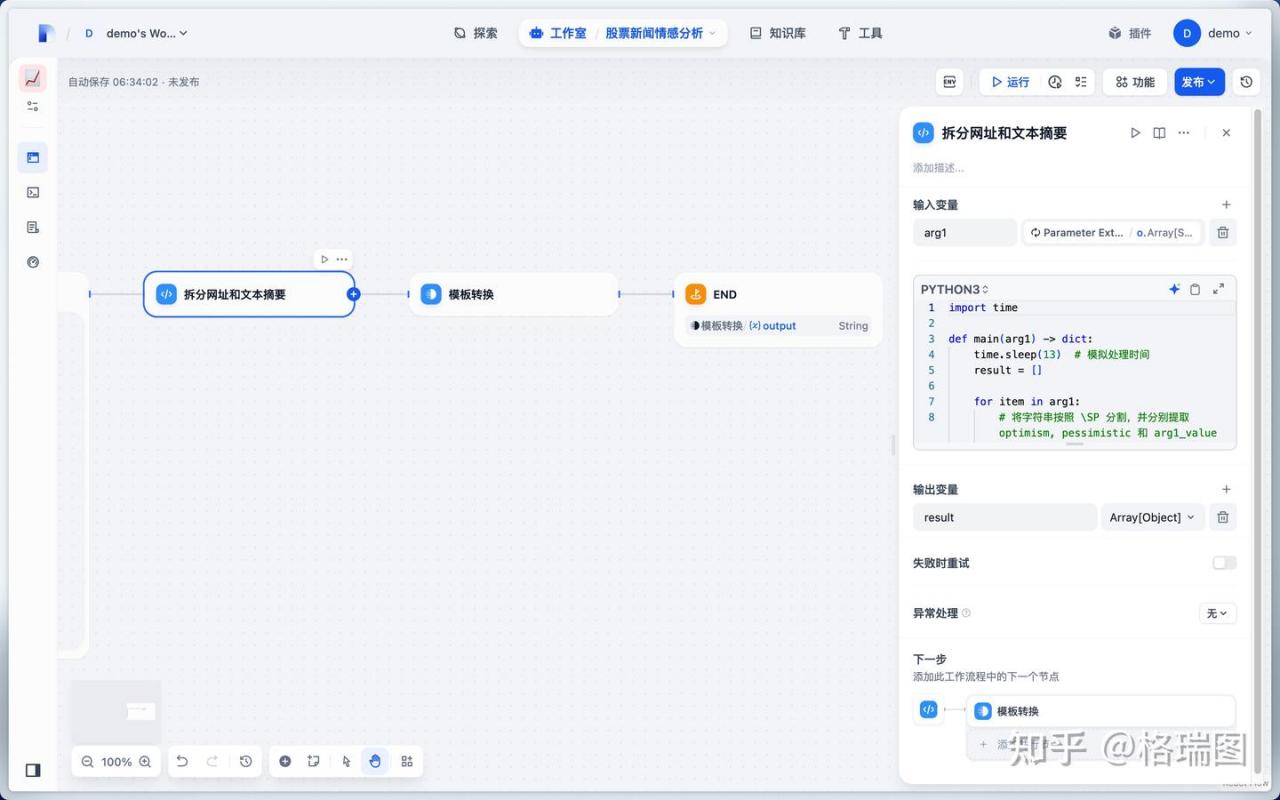
import time
def main(arg1) -> dict:
time.sleep(13) # 模拟处理时间
result = []
for item in arg1:
# 将字符串按照 \SP 分割,并分别提取 optimism, pessimistic 和 arg1_value
optimism, pessimistic, arg1_value = item.split('\\SP')
# 将文本中的换行符替换为空格
arg1_value = arg1_value.replace('\n', ' ')
# 将处理后的数据添加到结果列表中
result.append({
'optimism': optimism.strip(),
'pessimistic': pessimistic.strip(),
'arg1': arg1_value.strip()
})
return {
"result": result,
}使用 Python 脚本对每行数据进行切分。
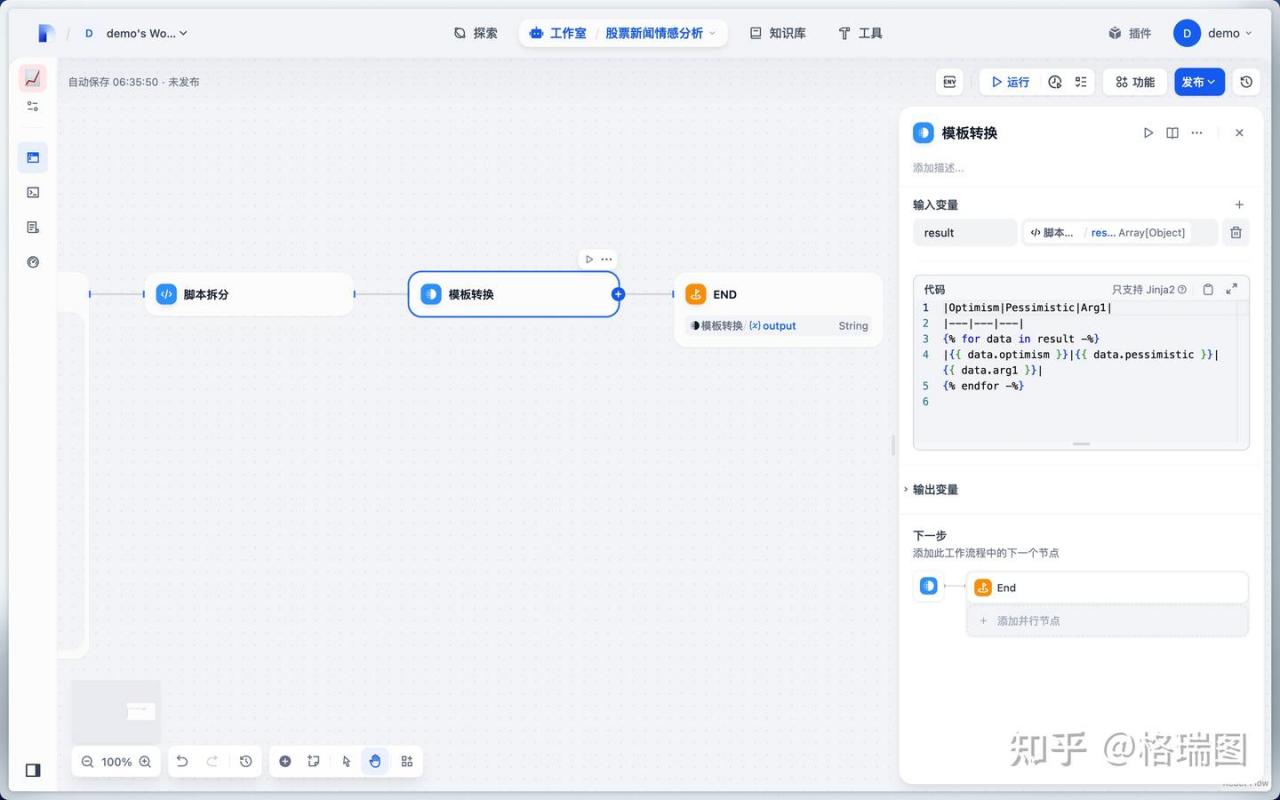
(9)模板转换
使用 Jinja2 语法将脚本拆分的列表转换为 Markdown 表格。
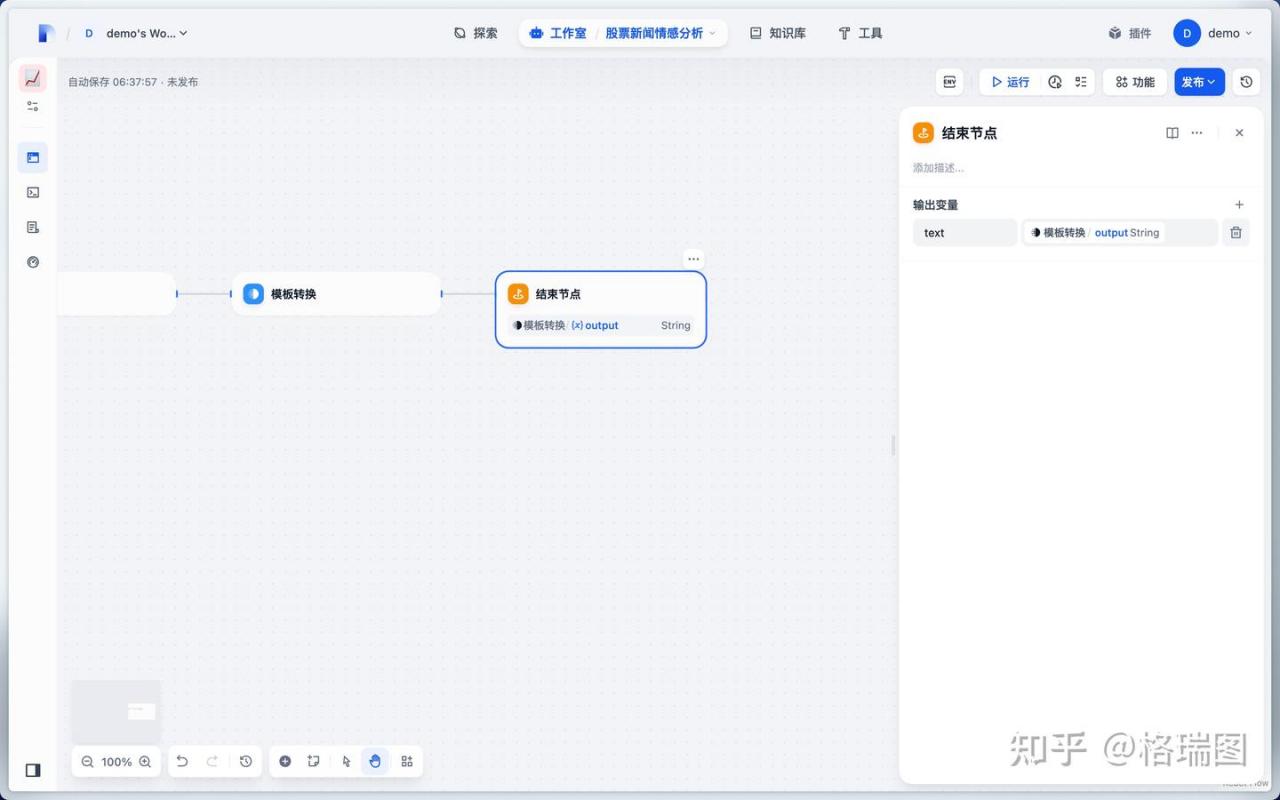
(0)结束节点
定义工作流流程结束和结果类型。
N、后记

~