你的「微信克隆人」来了,分享一个极具争议的开源项目!
最近一个叫 Weclon 的开源项目火了,
短短几天就在 GitHub 拿下 7K Star,但是争议极大。
一句话介绍:它可以用你的微信聊天记录,训练出一个“数字替身”。
你可以自己和自己聊天会是什么样子的?还可以捏造一个克隆的 crush。
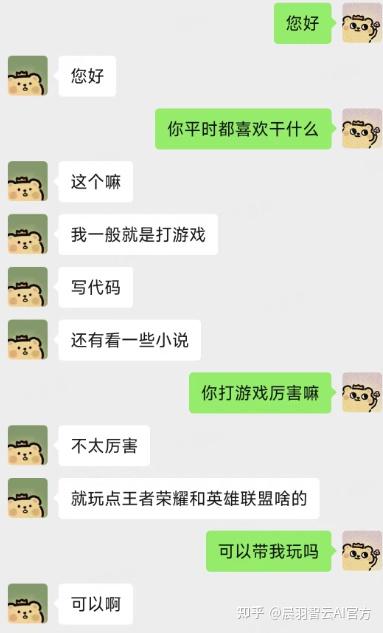
它能模仿你的语气、用词,甚至是聊天的思维方式,
连语音都能克隆,用的是 Spark TTS 模型。你还可以设置敏感词过滤,防止 AI 胡说八道,
训练完成后,这个替身还能接入各种社交平台,帮你自动回消息。
但也正因为如此,很多人担心隐私泄露——聊天记录一旦被滥用,风险极高。
不过如果用得好,场景也很强。比如企业可以拿销冠话术进行训练,就能克隆多个销冠,直接零成本提升业绩。
项目指路: https://github.com/xming521/weclone
下面是手把手带你安装部署使用这个神器。
环境搭建
1.cuda安装(已安装可跳过)
2.建议使用 uv安装依赖。安装uv后,可以使用以下命令创建一个新的Python环境并安装依赖项,注意这不包含音频克隆功能的依赖:
git clone https://github.com/xming521/WeClone.git
cd WeClone
uv venv .venv --python=3.10
source .venv/bin/activate # windows下执行 .venv\Scripts\activate
uv pip install --group main -e
如果要使用最新的模型进行微调,需要手动安装最新版LLaMA Factory:
uv pip install --upgrade git+https://github.com/hiyouga/LLaMA-Factory.git,同时其他依赖版本也可能需要修改,例如vllm pytorch transforms
3.将配置文件模板复制一份并重命名为setting.jsonc,后续配置修改在此文件进行:
cp settings.template.jsonc settings.jsonc
训练以及推理相关配置统一在文件
settings.jsonc
4.使用以下命令测试 CUDA 环境是否正确配置并可被 PyTorch 识别,Mac 不需要:
python -c "import torch; print('CUDA是否可用:', torch.cuda.is_available());"
5.(可选)安装 FlashAttention,加速训练和推理:
uv pip install flash-attn --no-build-isolation
模型下载
git lfs install
git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git
下载有问题使用其他方式下载:模型的下载
数据准备
运用 PyWxDump 提取微信聊天记录(4.0版本微信暂不支持)。建议先将手机的聊天记录备份至电脑。
下载软件并解密数据库后,点击聊天备份,导出类型为 CSV,可以导出多个联系人(不建议使用群聊记录)。
随后将导出的位于wxdump_tmp/export的csv文件夹放在./dataset目录,也就是不同人聊天记录的文件夹一起放在./dataset/csv。
数据预处理
这个项目默认会把数据里的手机号、身份证号、邮箱地址、网址这些敏感信息自动清理掉。
另外在settings.jsonc配置文件里还内置了一个屏蔽词库blocked_words,你要是想屏蔽其他内容,可以自己往里面加想屏蔽的关键词或句子(系统会自动把带这些屏蔽词的整句话都过滤掉)
执行下面的命令对数据进行处理,当然也可以根据聊天风格改动settings.jsonc的make_dataset_args。
weclone-cli make-dataset
现在系统暂时还只能靠时间窗口来管理消息。具体来说:要是同一个人连续发消息,只要间隔在
single_combine_time_window这个时间段内,系统就会自动用逗号把它们连成完整的一句话;
而qa_match_time_window这个参数专门用来配对问题和答案(比如用户提问和AI回答之间的时间差不超过这个数值才会被判定为有效问答对)。
咱们可以打开clean_dataset里的enable_clean开关,先给数据做个大扫除,这样效果会更好。现在流程是这样的:用llm judge当评分员给聊天记录打质量分(就是让AI自己判断对话质量),然后用vllm搞离线推理。
等看到评分分布直方图之后,调accept_score这个门槛值把达标分数线定好,最后再稍微调低train_sft_args里的lora_dropout参数,让模型更容易学到位。
配置参数并微调模型
(可选)修改 settings.jsonc 的 model_name_or_path 和 template 选择本地下载好的其他模型。
修改 per_device_train_batch_size 以及 gradient_accumulation_ste-ps来调整显存占用。
可以根据自己数据集的数量和质量修改train_sft_args的num_train_ep-ochs、lora_rank、lora_dropout等参数。
单卡训练
weclone-cli train-sft
多卡环境单卡训练,需要先执行export CUDA_VISIBLE_DEVICES=0
多卡训练
取消setting.jsons中deepseed
行代码注释,使用以下命令多卡训练:
uv pip install deepspeed
deepspeed --num_gpus=使用显卡数量 weclone/train/train_sft.py
使用浏览器demo简单推理
咱们可以先试不同参数组合,调好温度和top_p这两个数值。等找到最合适的配置之后,直接把参数填到settings.jsonc的infer_args里存好,这样后面正式跑模型的时候就能直接用啦!
weclone-cli webchat-demo
使用接口进行推理
weclone-cli server
部署到聊天机器人
AstrBot 是一个多平台 LLM 聊天机器人及开发框架,支持的平台有 QQ、QQ频道、Telegram、微信、企微、飞书。
使用步骤:
1.部署 AstrBot
2.在 AstrBot 中部署消息平台
3.执行weclone-cli server启动api服务
4.在 AstrBot 中新增服务提供商,类型选择 OpenAI,API Base URL 根据 AstrBot 部署方式填写(例如 docker 部署可能为http://172.17.0.1:8005/v1) ,模型填写gpt-3.5-turbo,API Key随意填写一个
5.微调后不支持工具调用,请先关掉默认的工具,消息平台发送指令: /tool off all,否则会没有微调后的效果。
6.根据微调时使用的default_system,在 AstrBot 中设置系统提示词。
检查
api_service的日志,尽量保证大模型服务请求的参数和微调时一致,tool 插件能力都关掉。
7. 调整采样参数,例如temperature、top_p、top_k等配置自定义的模型 参数。
部署需谨慎,大家量力而行,被技术拦住,但是有相关商业需求直接戳我,直接为您定制服务,如何找到我们