Github上好玩的50个python项目汇总

1、syncPlaylist:在网易云音乐与 QQ 音乐之间同步歌单。易于使用、配置方便、代码简单,用到的技术:requests + beautifulsoup 以及 selenium + phantomjs
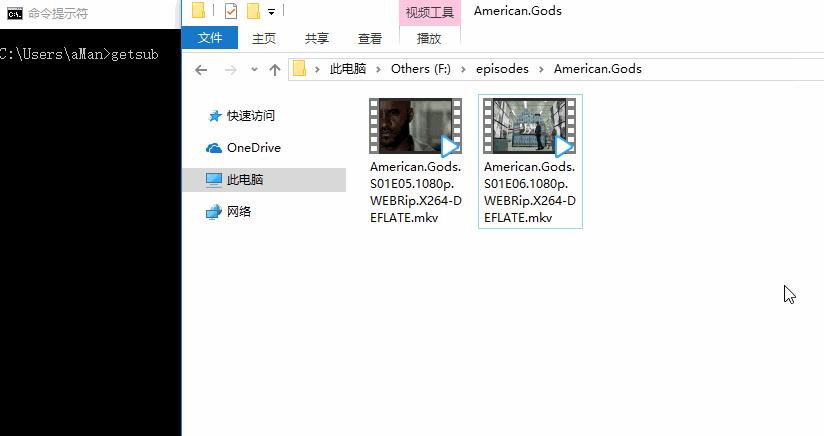
2、GetSubtitles:通过拖曳视频文件进终端,一步下载字幕 到视频对应文件夹,并重命名字幕名称为视频名称。Ubuntu 16.04、Windows 10上测试通过,同时兼容 Python2、3。Python 的魅力之一就是可以快速实现一个适合自己的小工具 Cool ✌️
3、huey:结合 redis 实现的轻量任务队列,但是支持功能还是很多的:
- 多进程、多线程、协程
- 任务定时执行
- 任务执行失败重试
- 结果存储
4、simiki:一个简单的个人 Wiki 框架,便于快速搭建 Wiki 页。使用 Markdown 书写 Wiki, 生成静态 HTML 页面。Wiki 源文件按目录分类存放, 方便管理维护。中文文档
5、pyecharts:Echarts+Python 实现的一个用于生成 Echarts 图表的类库
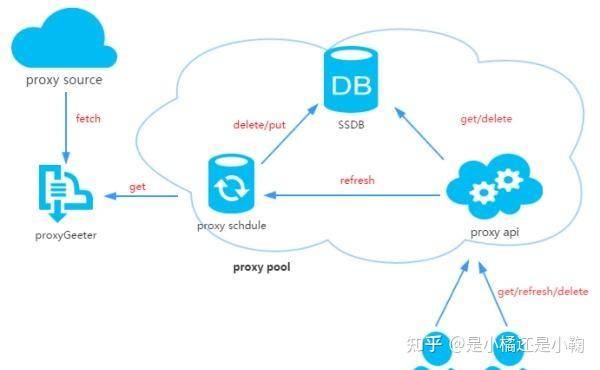
6、proxy_pool:基于 Python 的自建代理 IP 池服务,通过网络爬虫抓取互联网上免费的代理 IP,本地校验、剔除失效的代理IP,从而实现高可用的代理 IP 池。最后使用 Flask 搭建提供代理 IP 服务,包括代理池刷新、无效代理删除、代理获取等。该项目设计文档详细、模块结构简明易懂,同时适合爬虫新手更好的学习爬虫技术
7、WeiboSpider:分布式微博爬虫,支持快速抓取和稳定抓取两种运行模式。项目模块逻辑清晰、注释丰富、便于定制化自己的需求。同时,对于小白用户,可以通过演示视频快速入门,也提供QQ群答疑,已经持续维护一年多。靠谱的项目,小伙伴们要赶快上车~

8、pygorithm:一个帮助学习主要算法的库,可以通过理解这些算法的实现,提高自己的算法水平。冒泡排序示例:
>>> from pygorithm.sorting import bubble_sort >>> my_list = [12, 4, 3, 5, 13, 1, 17, 19, 15] >>> sorted_list = bubble_sort.sort(my_list) >>> print(sorted_list) >>> [1, 3, 4, 5, 12, 13, 15, 17, 19]
9、newspaper:强大的提取 Web 的内容、文章的库,支持多种语言,安装命令 pip3 install newspaper3k。示例代码:
>>> from newspaper import Article >>> url = ‘http://fox13now.com/2013/12/30/new-year-new-laws-obamacare-pot-guns-and-drones/‘ >>> article = Article(url) >>> article.download() >>> article.html ‘<!DOCTYPE HTML><html itemscope itemtype=”http://...’ >>> article.parse() >>> article.authors [‘Leigh Ann Caldwell’, ‘John Honway’] >>> article.publish_date datetime.datetime(2013, 12, 30, 0, 0) >>> article.text ‘Washington (CNN) — Not everyone subscribes to a New Year’s resolution…’ >>> article.top_image ‘http://someCDN.com/blah/blah/blah/file.png‘ >>> article.movies [‘http://youtube.com/path/to/link.com‘, …] >>> from newspaper import Article >>> url = ‘http://www.bbc.co.uk/zhongwen/simp/chinese_news/2012/12/121210_hongkong_politics.shtml‘ >>> a = Article(url, language=’zh’) # Chinese >>> a.download() >>> a.parse() >>> print(a.text[:150]) 香港行政长官梁振英在各方压力下就其大宅的违章建 筑(僭建)问题到立法会接受质询,并向香港民众道歉。 梁振英在星期二(12月10日)的答问大会开始之际 在其演说中道歉,但强调他在违章建筑问题上没有隐瞒的 意图和动机。 一些亲北京阵营议员欢迎梁振英道歉, 且认为应能获得香港民众接受,但这些议员也质问梁振英有 >>> print(a.title) 港特首梁振英就住宅违建事件道歉
10、faker:用于生成假数据的库,支持多种语言,你值得拥有。示例代码:
fake.address() # ‘辽宁省雪市静安廉街b座 998259’ fake.street_address() # ‘巢湖街U座’ fake.building_number() # ‘x座’ fake.city_suffix() # ‘市’ fake.latitude() # Decimal(‘-0.295126’) fake.province() # ‘湖北省’
11、binlog2sql:从 MySQL binlog 解析出你要的 SQL。根据不同选项,提供如下功能
- 数据快速回滚,闪回原理与实践
- 主从切换后新 master 丢数据的修复
- 从 binlog 生成标准SQL,带来的衍生功能
12、pandas-tutorial:这套 pandas 教程包含从初级到进阶的内容,适合初学者和希望进阶建立知识体系的数据科学从业者阅读。作者还在持续更新高级内容,你值得拥有
13、pysheeet:Python 速查表,在线阅读
14、robobrowser:提供多种模拟操作网页的库,比如获得网页内容、访问链接、点击按钮、填充并提交表单、上传文件。使用简单、API 友好。适用于想要通过脚本流程化操作,某些未提供这些操作接口的场景,示例代码如下:
# 上传文件 from robobrowser import RoboBrowser # Browse to a page with an upload form browser = RoboBrowser() browser.open(‘http://cgi-lib.berkeley.edu/ex/fup.html‘) # Find the form upload_form = browser.get_form() upload_form # <RoboForm upfile=, note=> # Choose a file to upload upload_form[‘upfile’] # <robobrowser.forms.fields.FileInput…> upload_form[‘upfile’].value = open(‘path/to/file.txt’, ‘r’) # Submit browser.submit(upload_form)
15、ItChat:开源的微信个人号SDK,提供了丰富的功能。从而使得 Python 调用微信、发送消息、传输文件等操作只需要编写极少的代码,示例代码如下:
import itchat itchat.auto_login() itchat.send(‘Hello, filehelper’, toUserName=’filehelper’)
16、records:Kenneth Reitz 大神的for Humans™系列,Records 是一个支持大多数主流关系数据库的原生 SQL 查询第三方库。API 友好,使用简单、支持命令行模式、功能多样。与此同时该库只有 500 行代码,可以当作入门阅读源码的项目,同时学习大神的编程技巧与习惯,示例代码如下:
import records db = records.Database(‘postgres://…’) # 连接数据库 rows = db.query(‘select * from active_users’) # 执行原生 SQL # 遍历结果 for r in rows: print(r.name, r.user_email) # 友好的 print 格式 print(rows.dataset) # username|active|name |user_email |timezone # ——–|——|———-|—————–|————————– # model-t |True |Henry Ford|[email protected]|2016-02-06 22:28:23.894202 # 支持将结果导出成不同格式 print(rows.export(‘json’)) # json print(rows.export(‘csv’)) # csv print(rows.export(‘yaml’)) # yaml rows.export(‘df’) # pandas 的 df 对象 with open(‘report.xls’, ‘wb’) as f: f.write(rows.export(‘xls’)) # xls
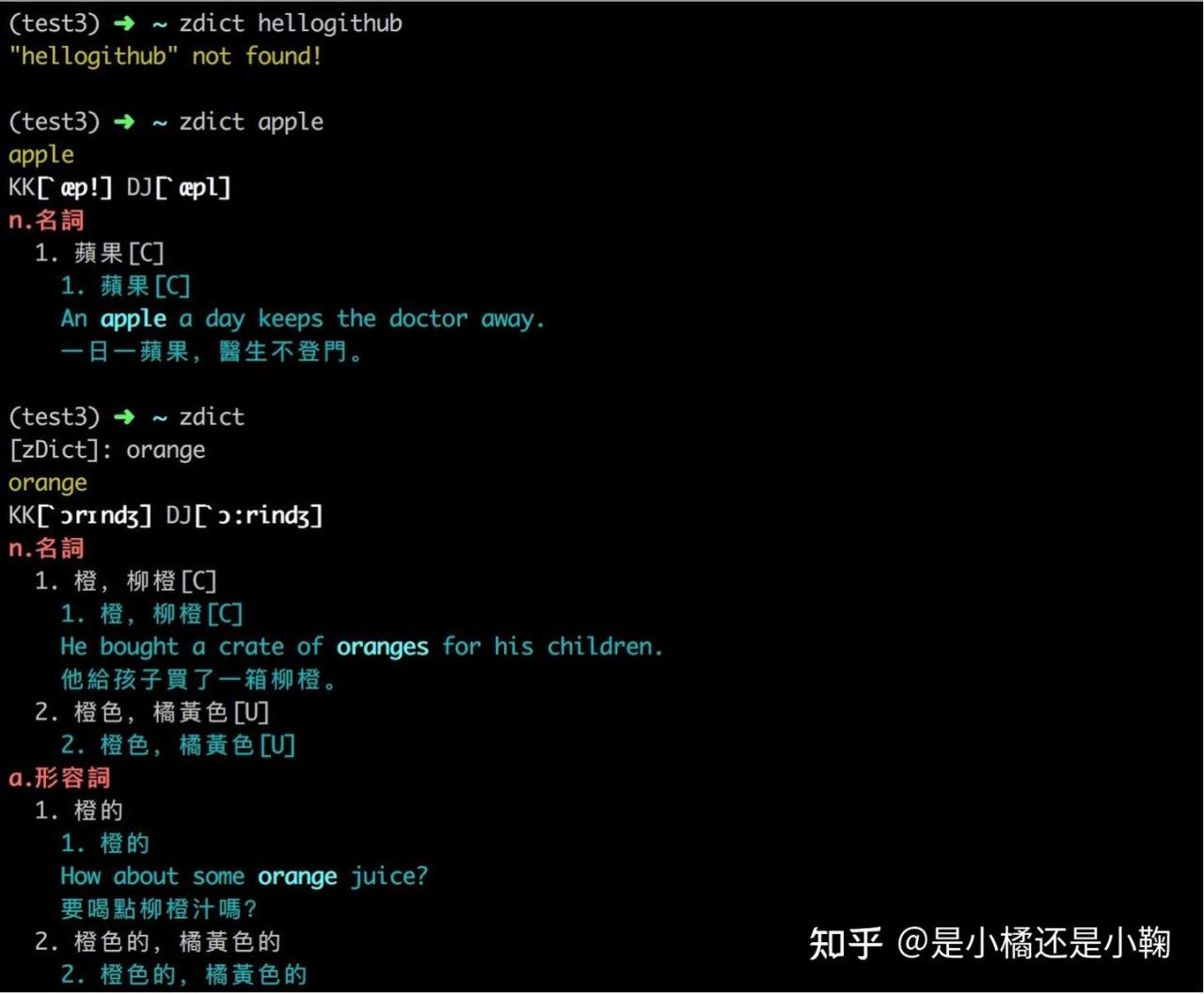
17、zdict:方便的终端字典工具,支持多种字典和参数、翻译结果高亮、以及交互模式查询。安装命令 pip install zdict(仅支持 Python3)。查询效果如下图所示:
18、joblib:使用 Python 方便的进行并行计算,示例代码如下:
from joblib import Parallel, delayed from math import sqrt Parallel(n_jobs=1)(delayed(sqrt)(i**2) for i in range(10))
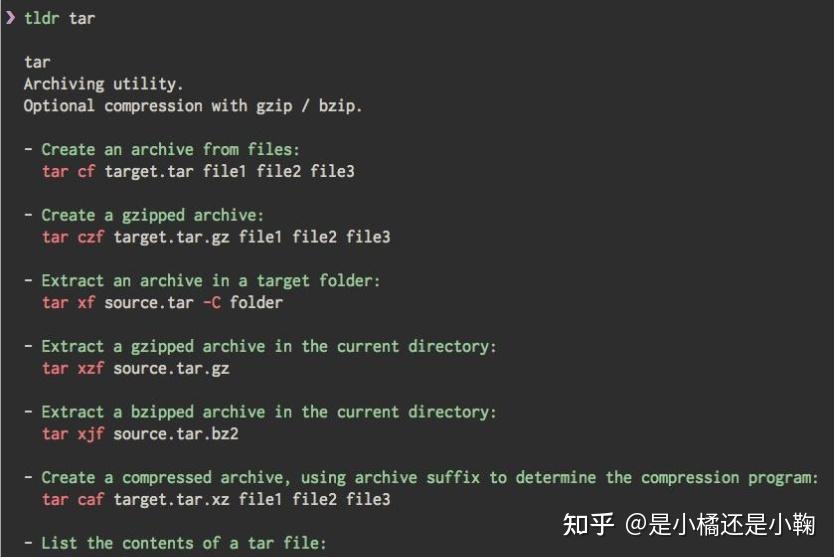
19、tldr-python-client:Linux man 解释一般都太长了,很多时候我们就想用一些比较常用的命令,但却记不起来。这个时候如果不 Google,就可以用 tldr(简化 man 的工程)。该项目为 Python 客户端实现
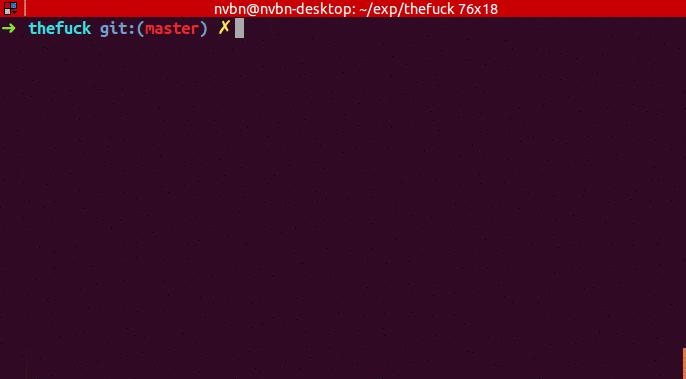
20、thefuck:在 Linux 命令行中,当你输入的命令有错误后,直接输入 fuck 就可以自动执行修复后的命令,效果图如下:
21、youtube-dl:强大的视频下载工具,支持几百个国内外主流视频网站。正如名字一样,最初是为了下载 youtube 上的视频而开发的。如果有国外服务器的朋友,可以充分利用这个工具,下载 youtube 上的视频,速度不要太爽。下面介绍安装、下载视频等命令:
# 1. 安装命令:sudo pip install youtube-dl Installing collected packages: youtube-dl Successfully installed youtube-dl-2017.12.14 # 2. 查看 URL 支持格式:youtube-dl –list-formats URL format code extension resolution note 134 mp4 450×360 DASH video 449k , avc1.4d4015, 25fps, video only 17 3gp 176×144 small , mp4v.20.3, mp4a.40.2@ 24k 36 3gp 300×240 small , mp4v.20.3, mp4a.40.2 18 mp4 450×360 medium , avc1.42001E, mp4a.40.2@ 96k 43 webm 640×360 medium , vp8.0, vorbis@128k (best) # 3. 选择格式下载视频:youtube-dl -f 18 URL (18为mp4 450×360格式) [youtube:playlist] Downloading playlist PLF90USSyuoYzPhhFG7XFBRn63Zvs–lNP – add –no-playlist to just download video JyLducMVYVg [youtube:playlist] PLF90USSyuoYzPhhFG7XFBRn63Zvs–lNP: Downloading webpage [download] Downloading playlist: 情满四合院完整版 [youtube:playlist] playlist 情满四合院完整版: Downloading 42 videos [download] Downloading video 1 of 42 … # 4. 下载完成后,最后使用 https://github.com/houtianze/bypy 库把下载的视频同步到百度网盘上
22、jieba:强大的 Python 分词库,拿来直接用就好。示例代码如下:
# encoding=utf-8 import jieba seg_list = jieba.cut(“我来到北京清华大学”, cut_all=True) print(“Full Mode: ” + “/ “.join(seg_list)) # 全模式 seg_list = jieba.cut(“我来到北京清华大学”, cut_all=False) print(“Default Mode: ” + “/ “.join(seg_list)) # 精确模式 seg_list = jieba.cut(“他来到了网易杭研大厦”) # 默认是精确模式 print(“, “.join(seg_list)) seg_list = jieba.cut_for_search(“小明硕士毕业于中国科学院计算所,后在日本京都大学深造”) # 搜索引擎模式 print(“, “.join(seg_list)) 【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学 【精确模式】: 我/ 来到/ 北京/ 清华大学 【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了) 【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
23、pydu:该库将平时常用的数据结构和工具都收录其中,可供日常开发的使用,同时方便学习与借鉴,丰富的文档能帮助新手更好的理解和使用它。这些实用的模块都是来自于开源项目和贡献者们的智慧,快来加入到这个项目中,让它变得更加实用和丰富
24、shell-functools:把函数式的编程带入 shell,从而让很多事情变得简单。通过 Python 的高阶函数和内置模块 os.path 与命令的管道结合,达到了强大、高效的功效。相比于单纯的命令实现更加的直观和容易理解,示例代码如下:
示例 1 # ls 查看当前目录下的文件 > ls document.txt folder image.jpg # 通过 map abspath 展示这些文件的绝对路径 > ls | map abspath /tmp/demo/document.txt /tmp/demo/folder /tmp/demo/image.jpg 示例 2 # find 命令找到的文件和目录 > find . ./folder ./folder/me.jpg ./folder/subdirectory ./folder/subdirectory/song.mp3 ./document.txt ./image.jpg # 把找到的结果中的文件,重命名在末尾追加 .bak (备份文件) > find | filter is_file | map basename | map append “.bak” me.jpg.bak song.mp3.bak document.txt.bak image.jpg.bak
25、tqdm:强大、快速、易扩展的 Python 进度条库。我想通过下面的示例代码和效果展示图,你会跑去给这个项目来个 Star 的
from tqdm import tqdm for i in tqdm(range(10000)): pass # 输出结果: # 76%|████████████████████████████ | 7568/10000 [00:33<00:10, 229.00it/s]
26、HAipproxy:使用 Scrapy+Redis 实现的高可用分布式 IP 代理池,为大型分布式爬虫提供高可用低延迟的代理 IP 资源。
from client.py_cli import ProxyFetcher args = dict(host=’127.0.0.1′, port=6379, password=’123456′, db=0) # 这里`zhihu`的意思是,去和`zhihu`相关的代理ip校验队列中获取ip # 这么做的原因是同一个代理IP对不同网站代理效果不同 fetcher = ProxyFetcher(‘zhihu’, strategy=’greedy’, redis_args=args) # 获取一个可用代理 print(fetcher.get_proxy()) # 获取可用代理列表 print(fetcher.get_proxies()) # or print(fetcher.pool)
文中所展示开源项目已经打包整理好 看下图自行获取哈: