Docker神器OCRmyPDF:一键让扫描版PDF变可搜索文档!

Docker神器OCRmyPDF:一键让扫描版PDF变可搜索文档!
兄弟们有没有遇到过这种情况?收到同事发来的合同扫描件,想在PDF里找某个条款,结果发现根本搜不到!今天二冰带来的这个OCRmyPDF项目,能让你的扫描件PDF秒变可搜索文档,关键还能用Docker一键部署!
一、项目简介
OCRmyPDF(GitHub地址:https://github.com/ocrmypdf/OCRmyPDF)是个基于Docker的PDF处理神器。它通过OCR技术给扫描件PDF添加文字层,就像给图片穿上了隐形文字盔甲,让你能直接搜索/复制文档内容!

二、五大核心优势
- 1. 智能优化:自动矫正歪斜页面、去除扫描阴影
- 2. 多语言支持:内置中/英/法/西等主流语言包
- 3. 无损处理:保留原始排版,文字层透明叠加
- 4. 批处理模式:支持命令行批量OCR
- 5. Docker加持:三分钟完成部署,不污染主机环境
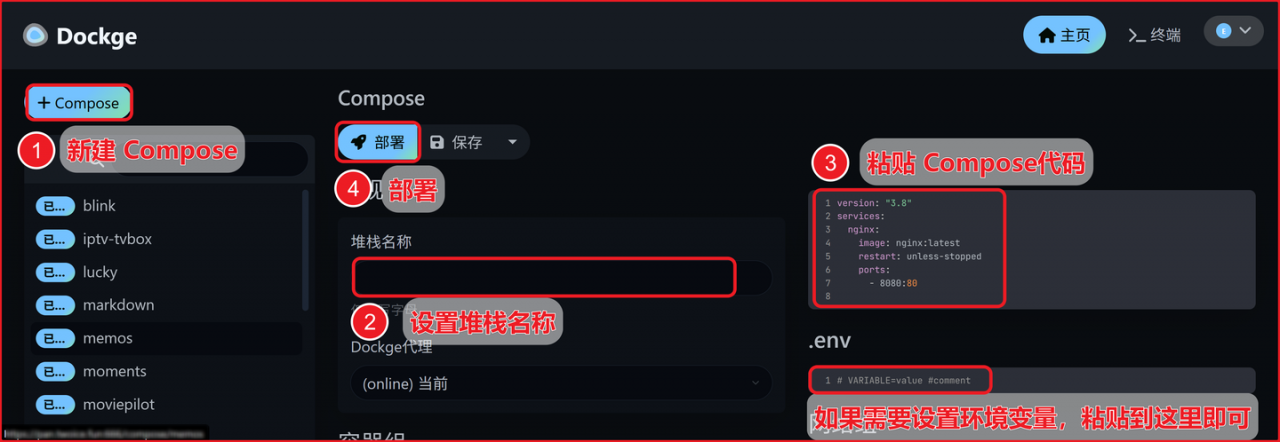
三、Docker部署攻略
打开Dockge面板 -> 创建堆栈 -> 设置堆栈名称 -> 粘贴compose代码 -> 30秒启动成功!
四、实战效果展示
- 1. 把扫描件PDF扔进
input目录 - 2. 执行OCR命令:
docker exec ocrmypdf ocrmypdf input/合同扫描件.pdf output/可搜索版.pdf- 3. 查看处理效果:

处理后
五、进阶玩法
批量处理脚本
#!/bin/bash
for file in ./input/*.pdf; do
filename=$(basename "$file")
docker exec ocrmypdf ocrmypdf "$file" "./output/${filename%.*}_ocr.pdf"
done常用参数说明
六、避坑指南
- 1. 中文乱码:确保终端使用UTF-8编码
- 2. 权限问题:检查output目录写权限
- 3. 处理失败:尝试添加
--force-ocr参数 - 4. 性能优化:多核CPU可加
--jobs 4参数
七、项目总结
经过二冰实测,这个项目特别适合:
✅ 法务处理合同扫描件
✅ 学生整理电子版教材✅ 档案数字化工作人员
处理后的PDF文字识别准确率在95%以上,而且保留了原始排版。要说缺点的话,处理100页以上的文件时需要耐心等待(建议喝杯咖啡)。
综合评分:★★★★☆(扣一星因为处理大文件略慢)
推荐指数:必装工具!特别是需要处理扫描文档的兄弟!
技术宅改造世界,从让PDF可搜索开始!觉得有用的话记得点赞收藏,欢迎在评论区交流心得!
最后,奉上我的超级无敌至尊docker库,二冰平时玩过的docker都整理到了这个仓库中了,一直在更新中,希望有github账号的兄弟能去给点个star,不知道玩啥的,都去这里面找,都给你们分好类了
仓库链接:https://github.com/TWO-ICE/Awes