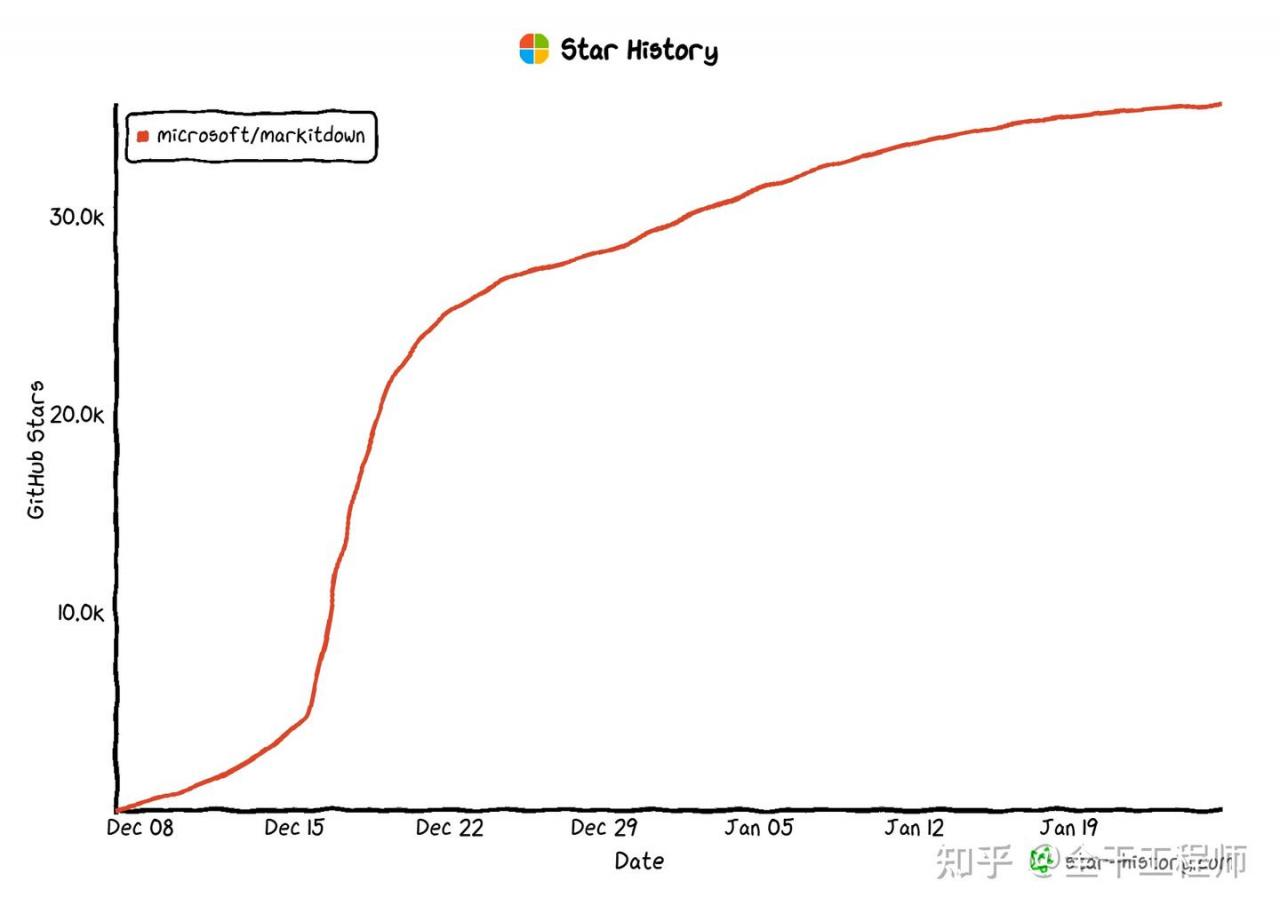
MarkItDown: 微软开源的文档转换神器


随着AI越来越深入我们的生活,经常需要处理各种格式的文件,有PDF、Word文档、Excel, 如果可以把这些文件的核心内容以简洁的Markdown语法呈现,投喂给大模型可以让大模型更好的理解我们的私有信息
MarkItDown 是微软开源的一款 Python 工具,可用于将各种文件格式转换为 Markdown 格式。而且还支持集成像GPT-4o这样的多模态LLM,可以直接对图片、音频文件进行更高效的信息处理。
主要特性
- 多格式支持: 支持多种文件类型的转换,包括:
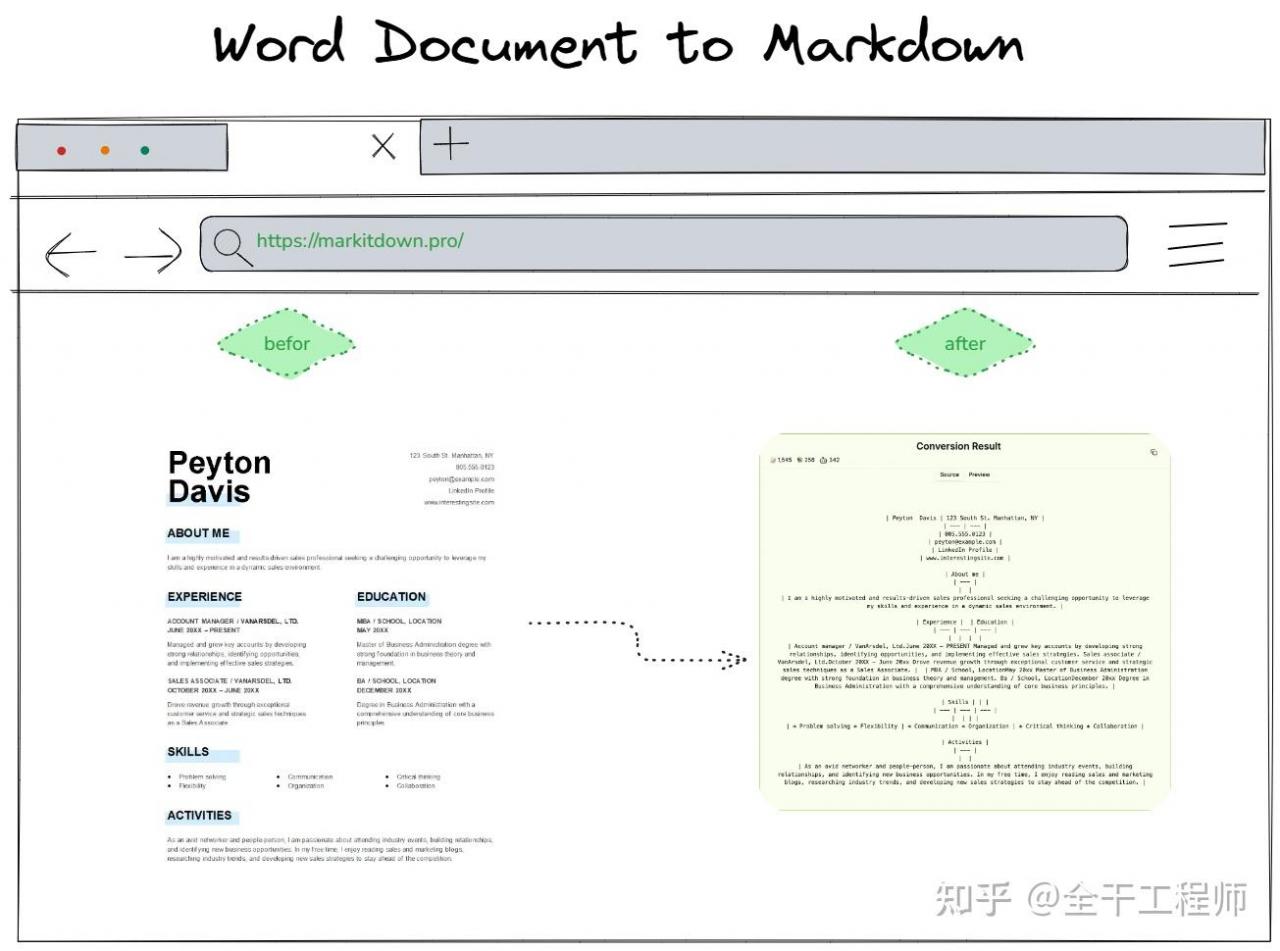
- 办公文档 (PDF, PowerPoint, Word, Excel)
- 图像文件 (支持 EXIF 元数据提取和 OCR)
- 音频文件 (支持 EXIF 元数据提取和语音转录)
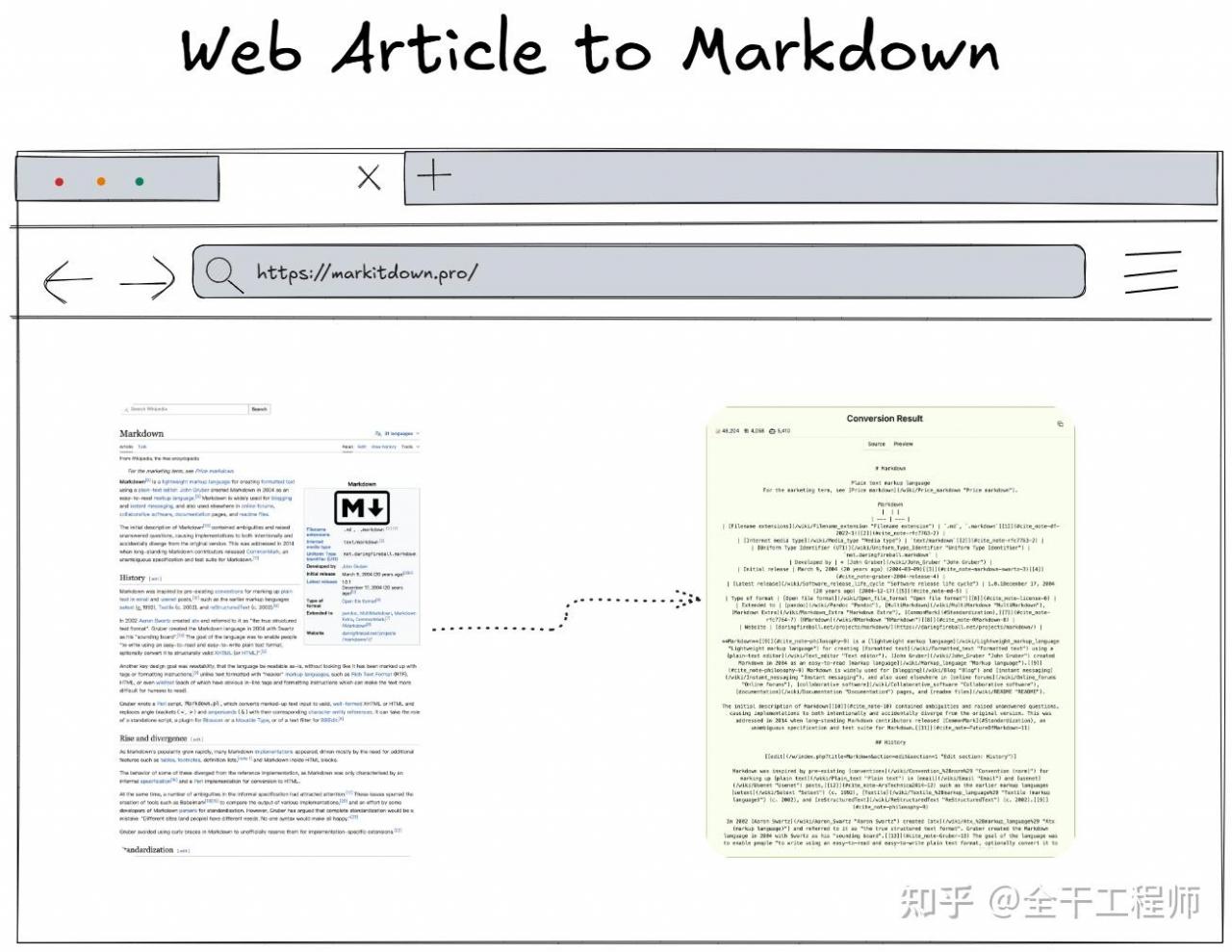
- HTML(支持维基百科等特殊处理)
- 文本格式 (CSV, JSON, XML)
- 压缩文件 (ZIP,可迭代处理内部文件)
- 便于处理: 将不同格式的文件内容提取为 Markdown 格式,便于进一步处理、索引或文本分析。
- 大模型兼容: 许多大型语言模型都使用 Markdown 格式,MarkItDown 为这些模型提供了理想的输入格式。
安装方法
pip install markitdown
或者从源代码安装:
git clone https://github.com/microsoft/markitdown
pip install -e .
使用方法
1. 命令行工具
markitdown path-to-file.pdf > document.md
或指定输出文件:
markitdown path-to-file.pdf -o document.md
通过管道传输内容:
cat path-to-file.pdf | markitdown
2. Python API
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("test.xlsx")
print(result.text_content)
3. 与大语言模型集成
from markitdown import MarkItDown
from openai import OpenAI
client = OpenAI()
md = MarkItDown(llm_client=client, llm_model="gpt-4o")
result = md.convert("example.jpg")
print(result.text_content)
4. Docker 支持
构建镜像:
docker build -t markitdown:latest .
运行镜像:
docker run --rm -i markitdown:latest < ~/your-file.pdf > output.md
核心技术
markitdown 核心代码非常少, 大概1500行左右,稍微研究一下就可以发现它本质是一个掉包侠,是根据文件的扩展名自动选择转换工具我做了下简单的总结
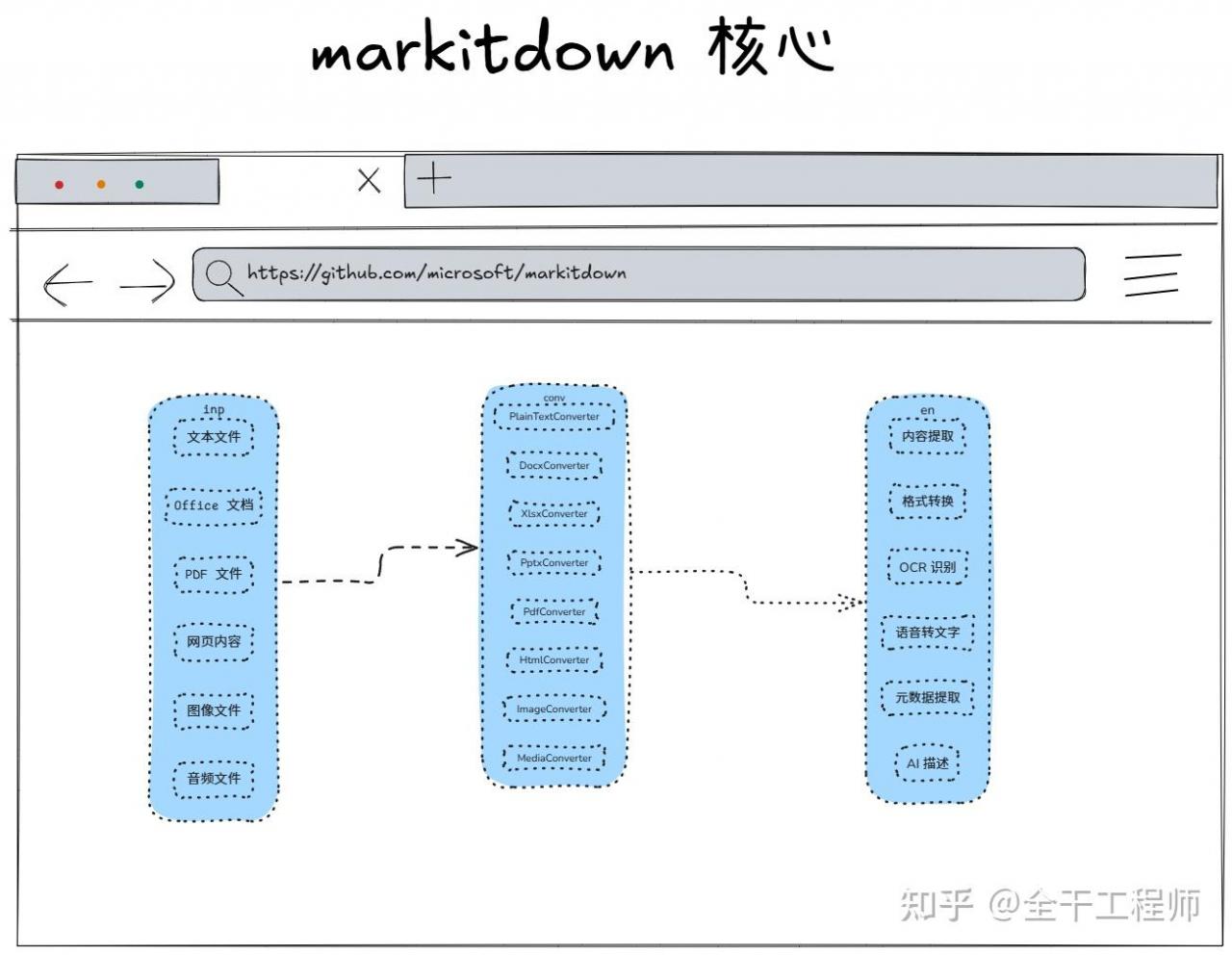
- 外部库集成
- mammoth: DOCX 转 HTML
- markdownify: HTML 转 Markdown
- pandas: 处理 Excel 文件
- pdfminer: 提取 PDF 文本
- BeautifulSoup: 解析 HTML 和 XML
局限性
虽说 MarkItDown 已经相当强大,但是人无完人,还是有很多局限性
- 复杂 HTML/CSS 布局可能无法完全保留
- 图像仅保留为引用,不直接嵌入
- 音频/视频仅转换元数据和转录,不包含媒体文件
结语
MarkItDown 为文档转换提供了一个强大而灵活的解决方案,无论是个人用户还是企业用户,都能从中受益。其广泛的格式支持和易用性使其成为文档处理工作流中不可或缺的工具。
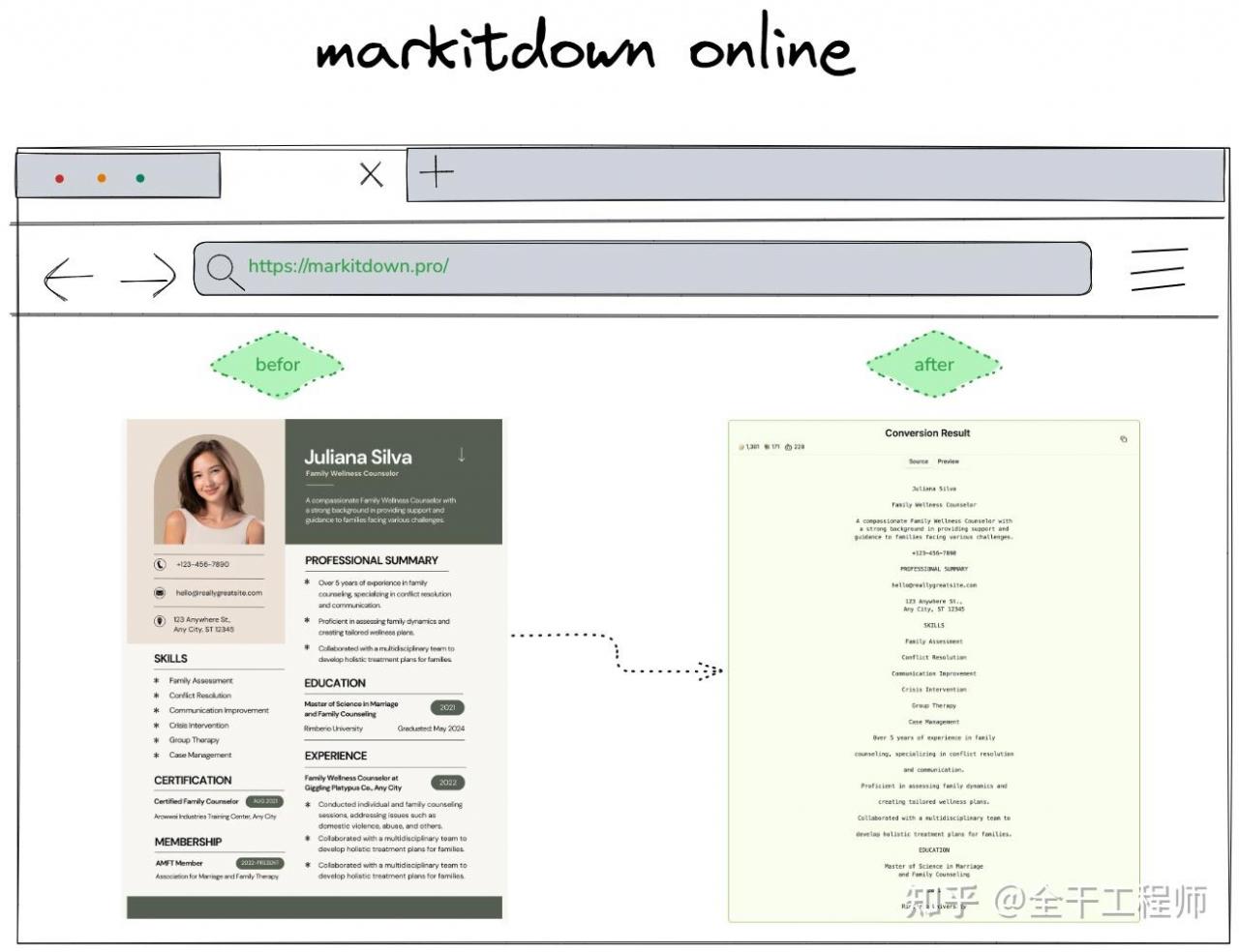
有热心网友提供了在线版本:
- markitdown 在线:markitdown.pro