n8n+crawl4ai爬取网站信息并用大模型整理输出到本地


1.使用DOCKER部署n8n和crawl4ai
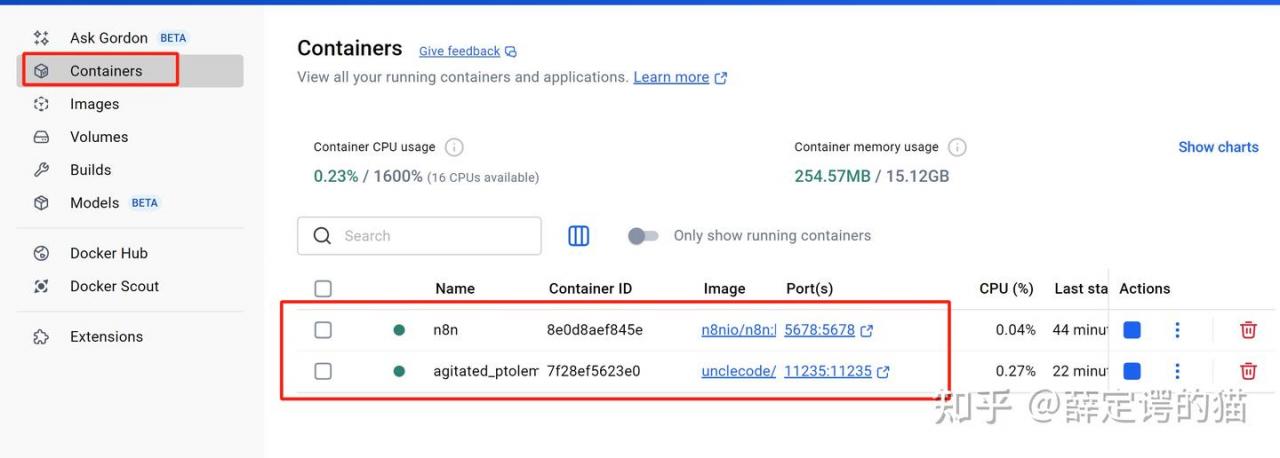
部署crawl4ai的命令:
docker run --rm=false -it -d --name crawl4ai -e CRAWL4AI_API_TOKEN=12345 -p 11235:11235 -v n8n_data:/home/node/.crawl4ai unclecode/crawl4ai:all-amd64部署n8n的命令:
docker volume create n8n_data
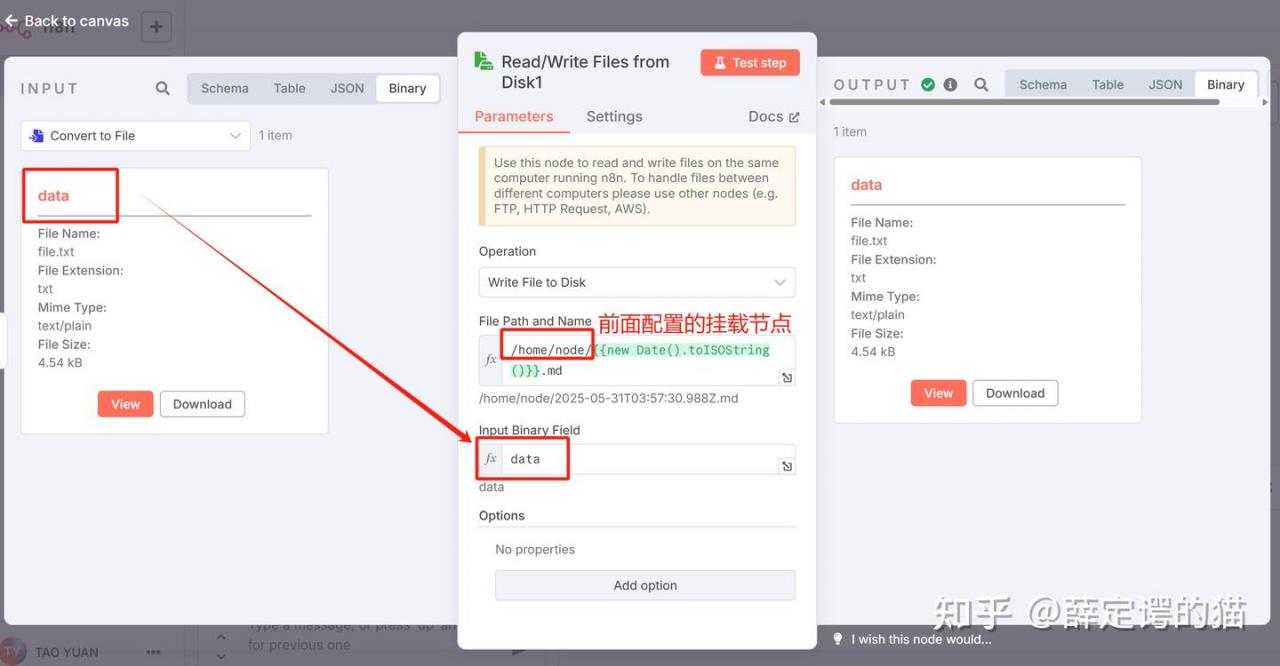
docker run -it --name n8n -p 5678:5678 -v D:\n8n:/home/node/ -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8n
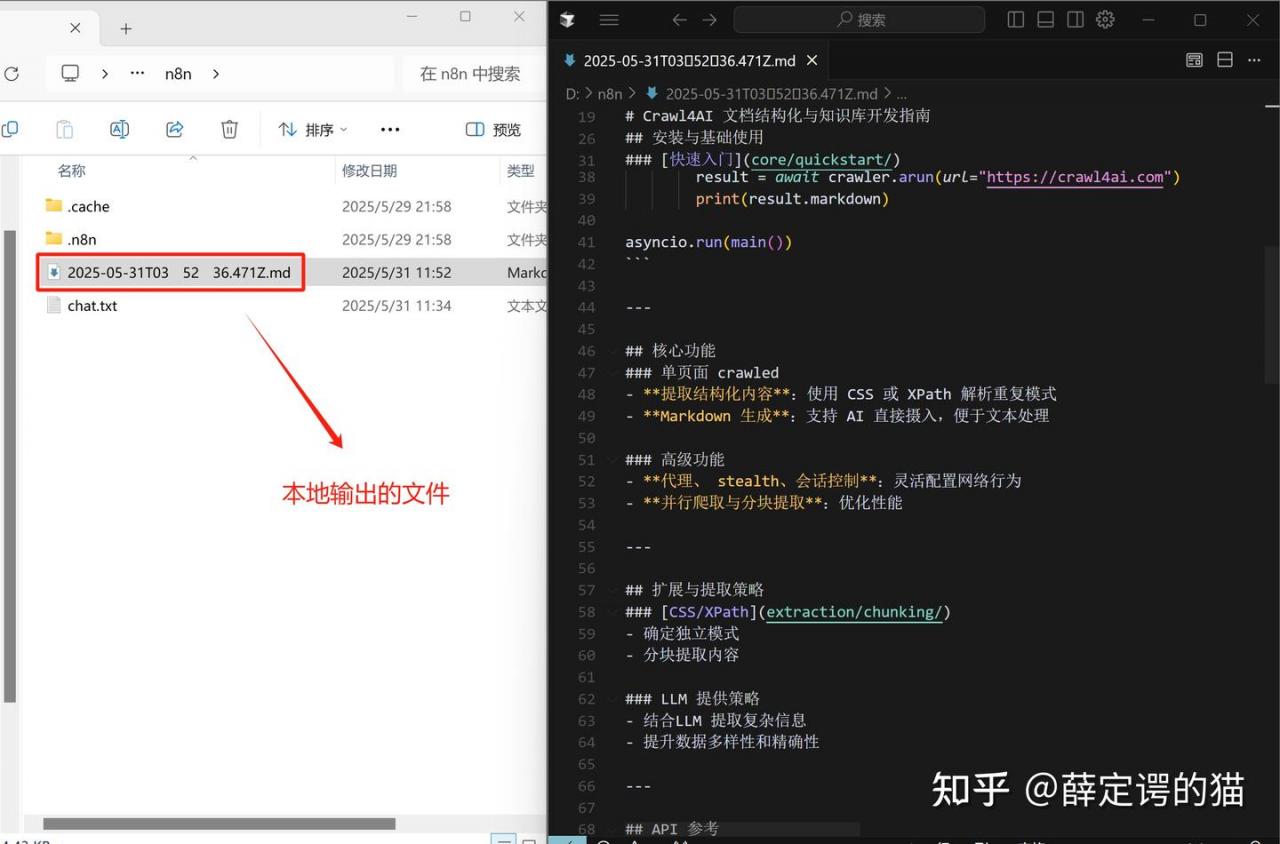
需要挂载到本地的目录(-v D:\n8n:/home/node/),否则后面无法将文件保存到本地!!!2.获取想要爬取的网站信息
(1)在想要获取的网站网址后面添加/sitemap.xml,获取该网站所有的url
https://docs.crawl4ai.com/sitemap.xml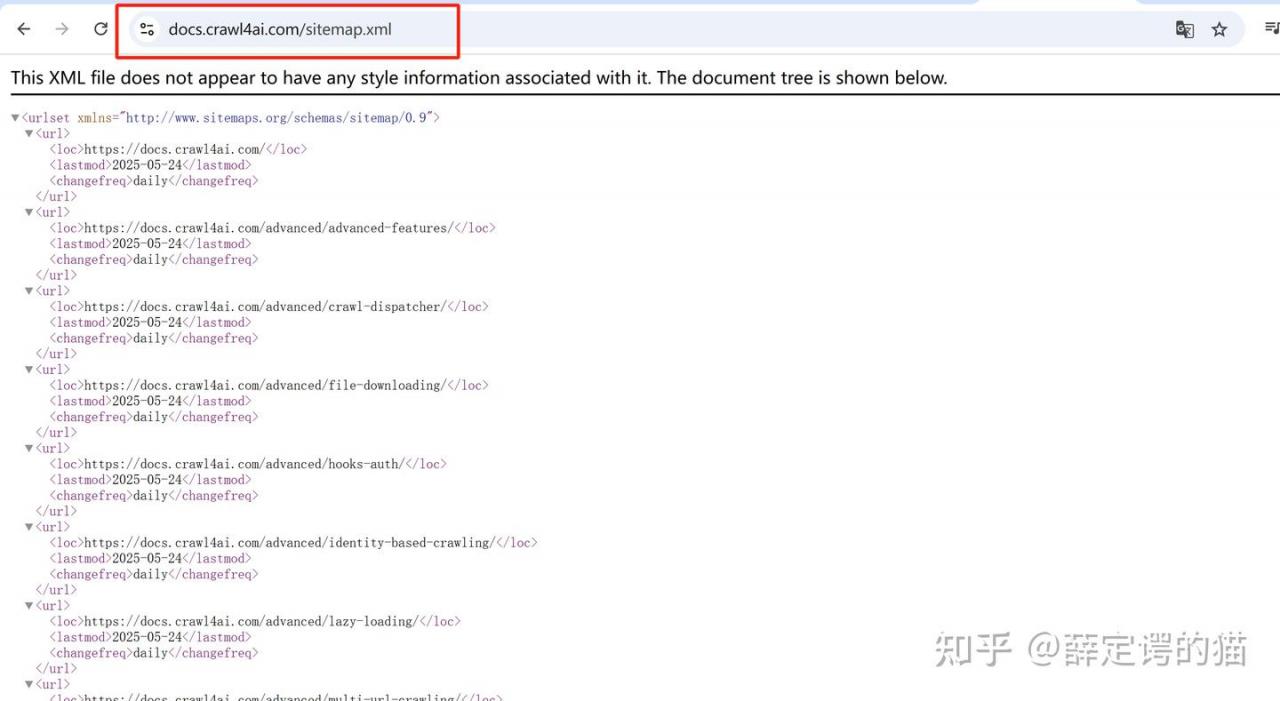
(2)添加/robot.txt,查看哪些信息是可以爬取的
3. AI agent提示词
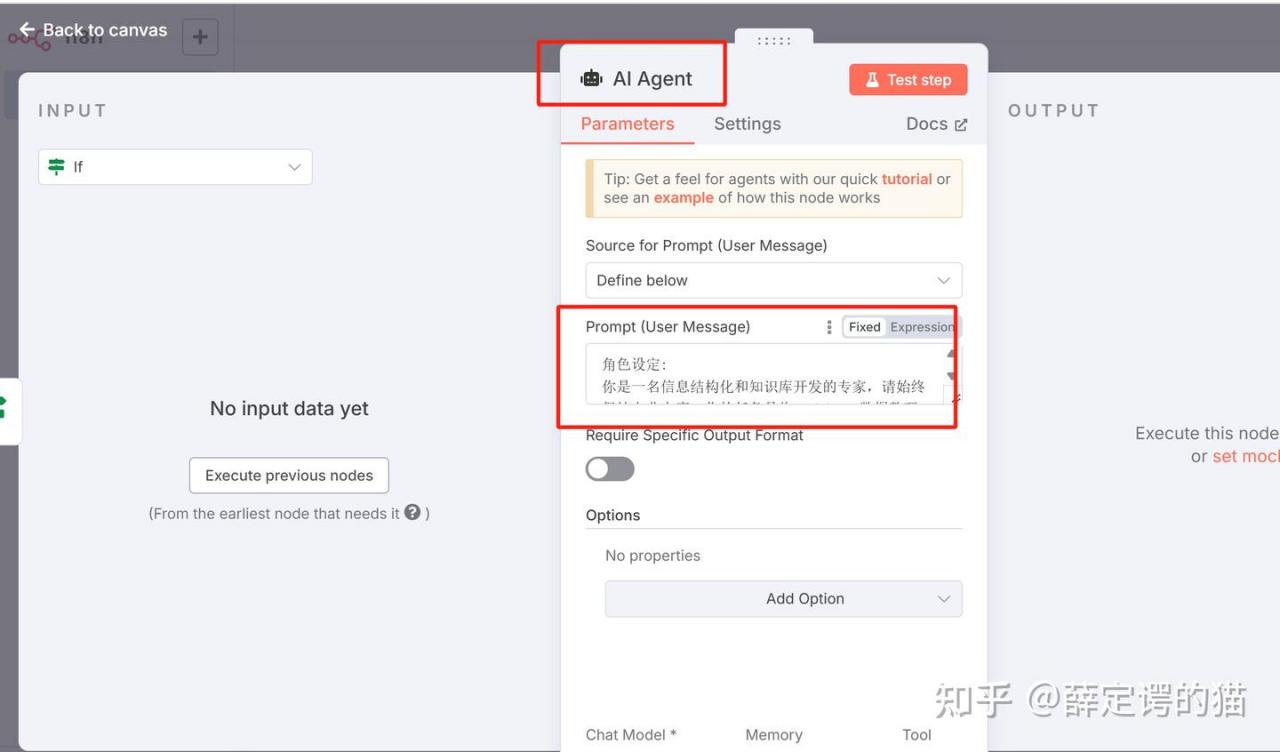
AI提示词设置:
角色设定:
你是一名信息结构化和知识库开发的专家,请始终保持专业态度。你的任务是将markdown 数据整理为适合LLM驱动的 RAG 知识库的结构化、易读格式。
任务要求:
1.内容解析
-识别 markdown 数据中的关键内容和主要结构。
2.结构化整理
-以清晰的标题和分层逻辑组织信息,使其易于检索和理解。
-保留所有可能对回答用户查询有价值的细节。
3.创建 FAQ(如适用)
-根据内容提炼出常见问题,并提供清晰、直接的解答。
4.提升可读性
-采用项目符号、编号列表、段落分隔等格式优化排版,使内容更直观
5.优化输出
-严格去除AI生成的附加说明,仅保留清理后的核心数据,使内容更直观,并且输出的内容为中文。
响应规则:
1.完整性:确保所有相关信息完整保留,避免丢失对搜索和理解有价值的内容
2.精准性:FAQ需紧密围绕内容,确保清晰、简洁且符合用户需求。
3.结构优化:确保最终输出便于分块存储、向量化处理,并支持高效检索。
数据输入:
<markdown>{{ $json.result.markdown }}</markdown>4. 整体工作流架构
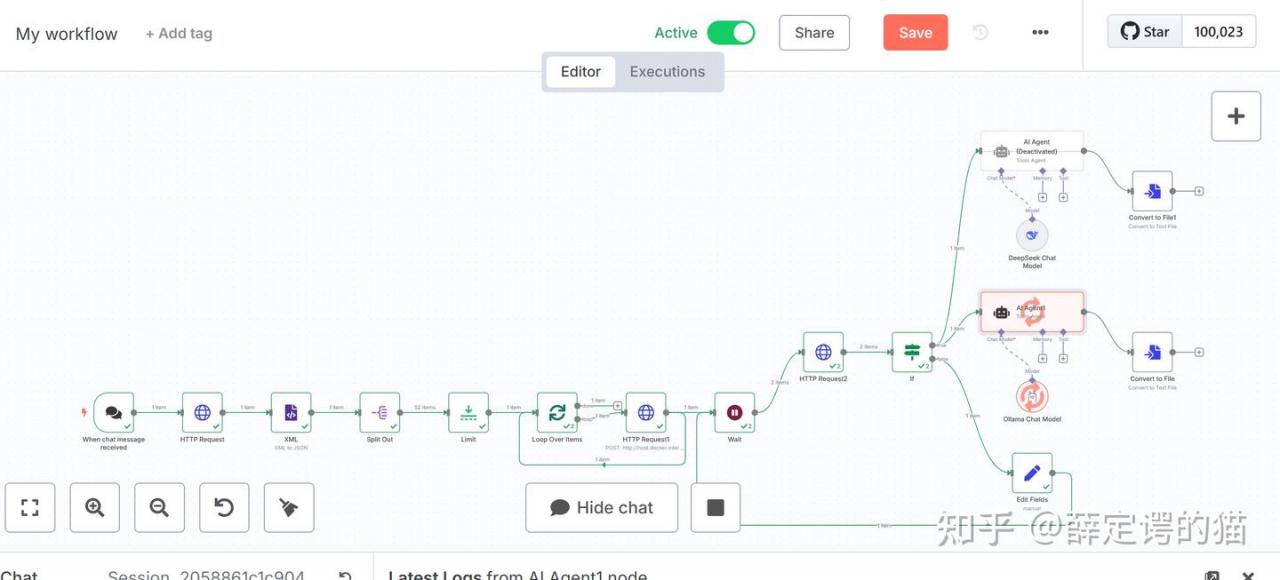
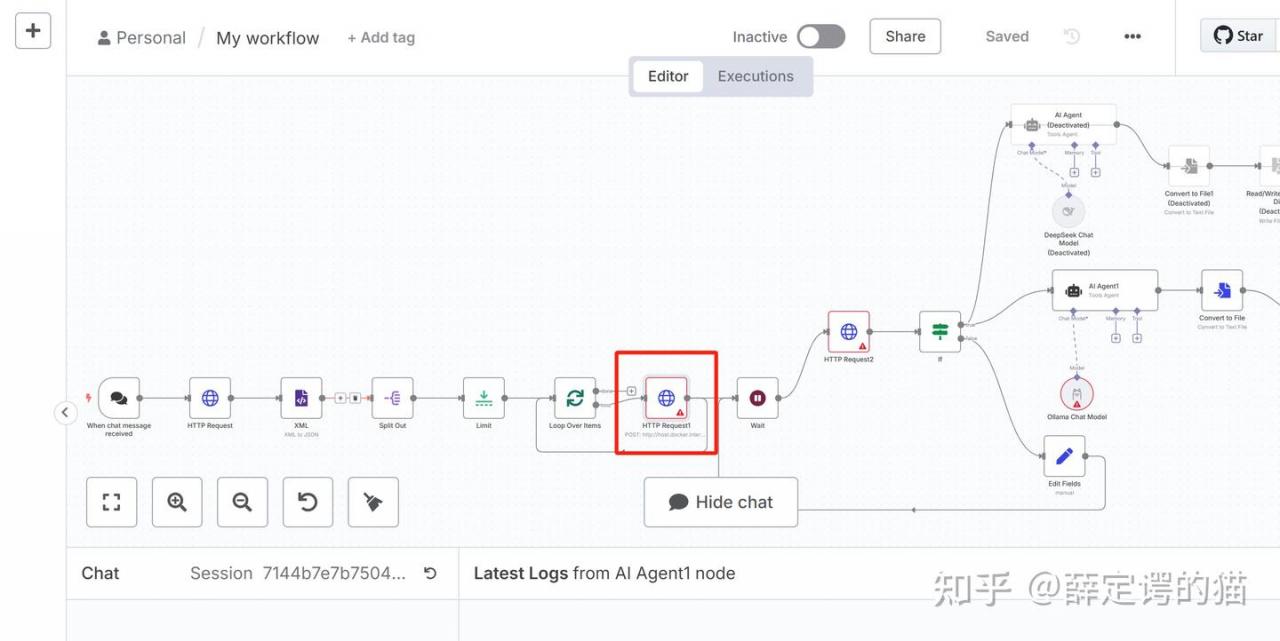
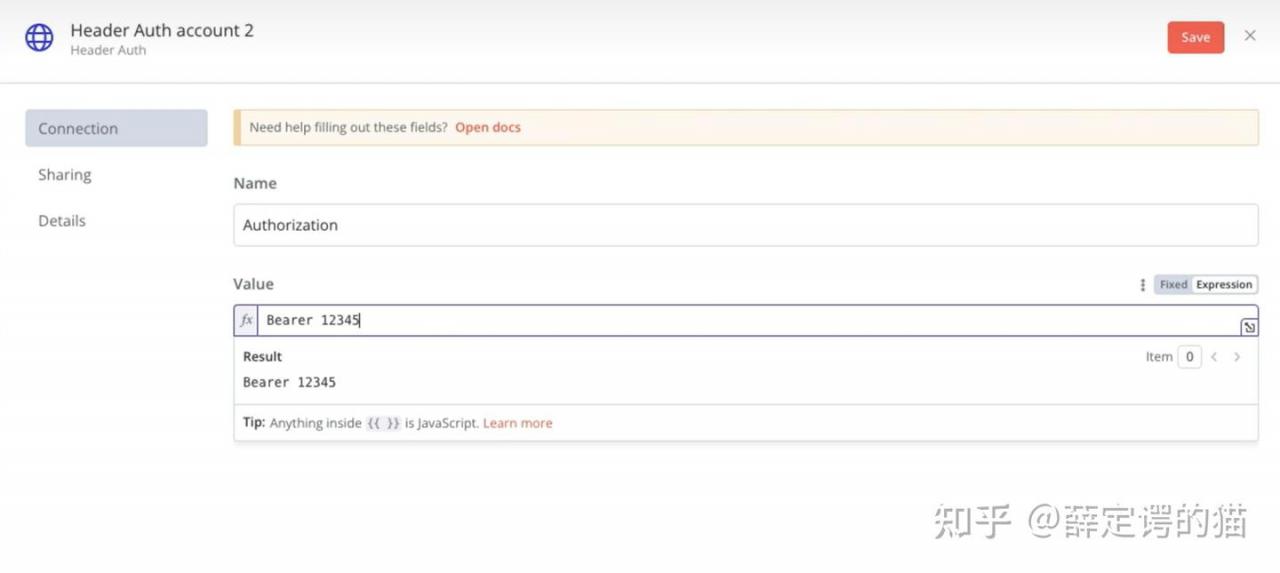
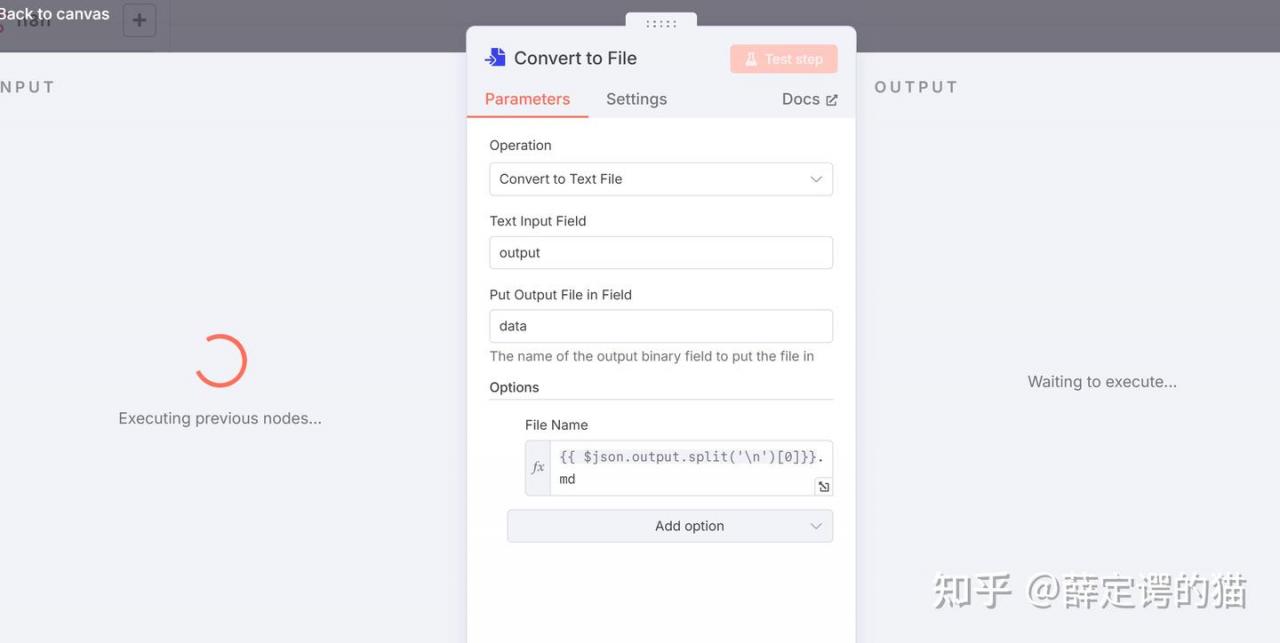
部分关键节点配置:
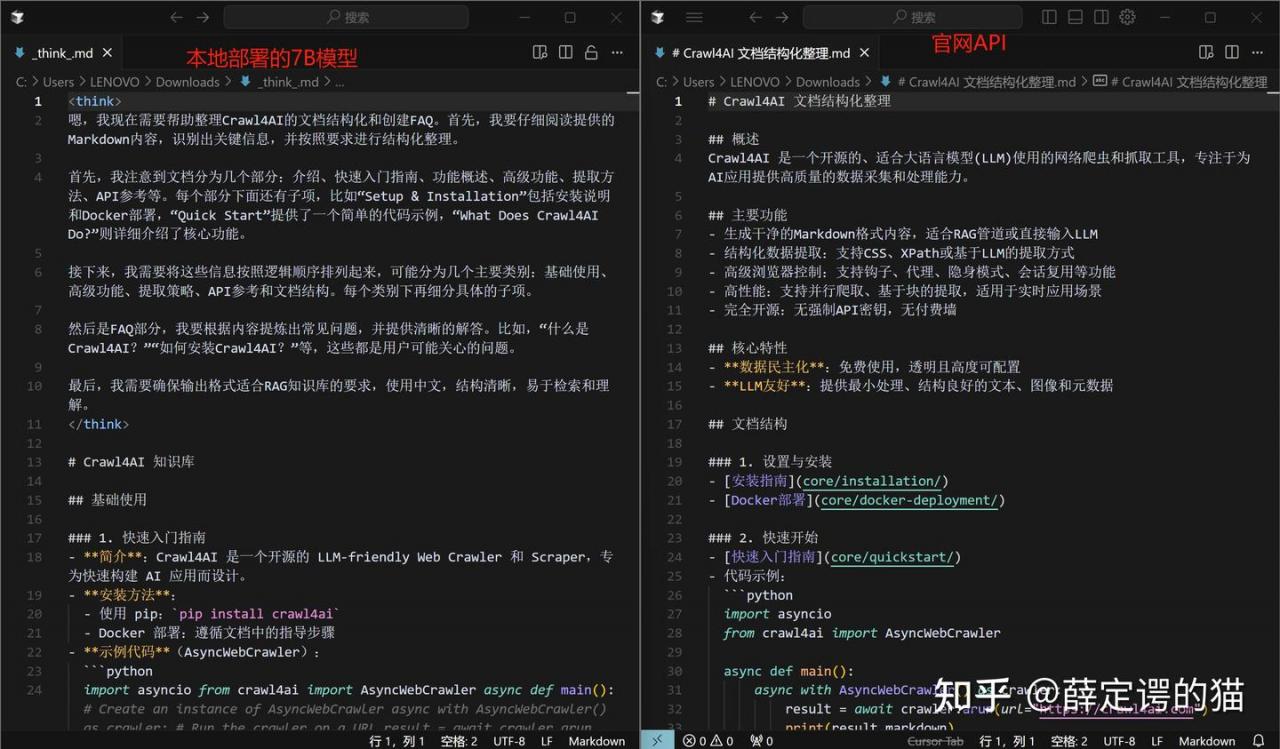
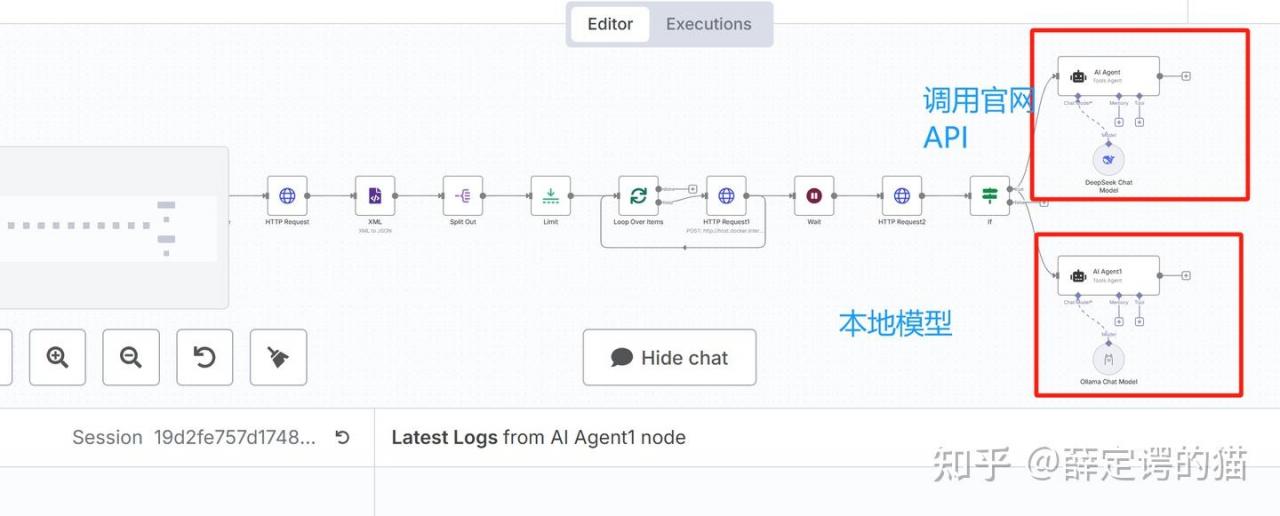
5.调用官网LLM的API与本地部署LLM模型效果对比
本地模型为 deepseek-r1:7b SIZE:4.7GB
采用n8n来构建对比测试系统,其中输入和提示词一样:
使用相同提示词下输出结果对比: