顶顶通大模型电话机器人实现原理
Realtime 音频大模型
•原理
•流对接,直接把音频流输出给大模型,大模型返回音频流。
•优点
•低延迟和真人对话一样。
•技术门槛底。
•缺点
•技术成熟度不高,只有少数模型支持。
•无对话文本记录,需要额外调用ASR把通话录音转换成文字。
•对话流程可控性低,无法精细控制对话流程和意向判断。
顶顶通CTI对Realtime API 的支持
提供了以下2个APP可对接任意Realtime API 多模态大模型
•cti_audio_stream 通过TCP推流和播放流,适合用于人机对话。
•cti_unicast_start 通过旁路的方式UDP推流和播放流,对接Realtime API 的同时还支持对通道进行放音操作。
使用文本大语言模型实现人机语音对话
1.把声音通过ASR转换成文字
2.通过文字调用大模型输出文字回复
3.把大模型输出的文字调用TTS转换成声音。
存在的问题
•ASR声音转文字慢
•改进方法:使用流ASR实时识别。
•TTS文字转声音慢
•改进方法:使用流TTS自动短句,大模型边输出边转换。
•大模型输出慢
•请看后面顶顶通电话机器人实现方法。
市面常见的电话机器人怎么使用大模型的
常见做法
•把知识库导入向量数据库,使用RAG技术让大模型根据专业领域知识输出回复。
•或者不用RAG技术,直接把专业领域知识写入Prompt,让大模型根据Prompt输出回复。
存在的缺点
•大模型回复比较慢。
•就算大模型一边回复,一边调用流TTS,TTS也不能一个字输入就开始转换,也需要断句到一句话才可以开始输出声音。导致第一句话回复比较慢。
•没法精细控制对话流程,以及没办法精细意向分类,只能通话结束把整个对话记录提交给大模型让大模型做总结。
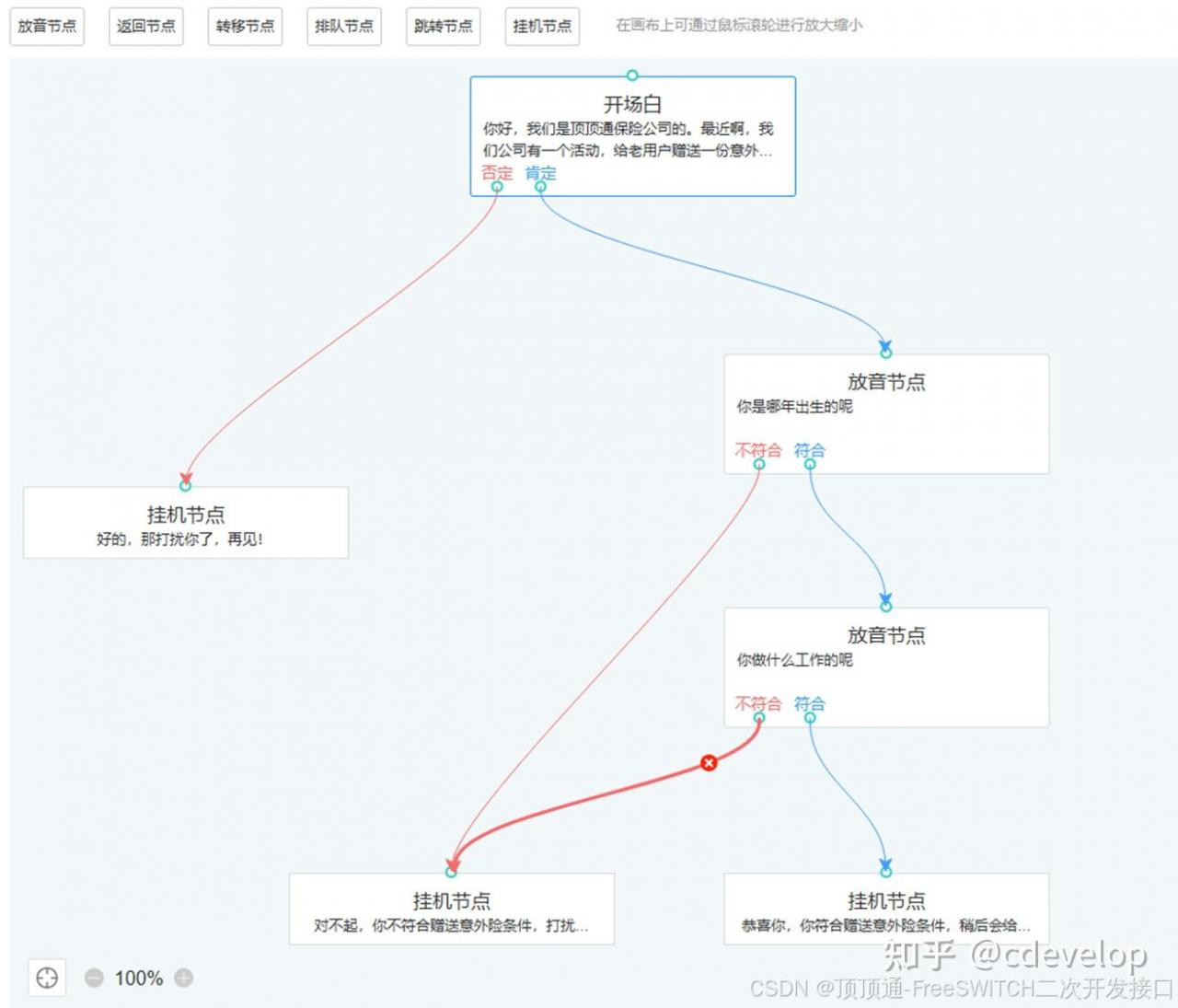
顶顶通电话机器人怎么使用大模型的
•把话术和大模型深度融合。
•优点:可精细化定制对话逻辑和意向分类。
•可以只使用大模型的理解功能(NLP),尽量不使用大模型的生成功能。
•优点1:让大模型更快的回复,和避开动态TTS带来的延迟。
•优点2:降低大模型调用输出tokens费用。
•只把当前流程关联的知识库和子流程带入Prompt,让大模型更精准的理解和回复。
•优点1:大模型回复的更精准。
•优点2:降低大模型调用输入tokens费用。
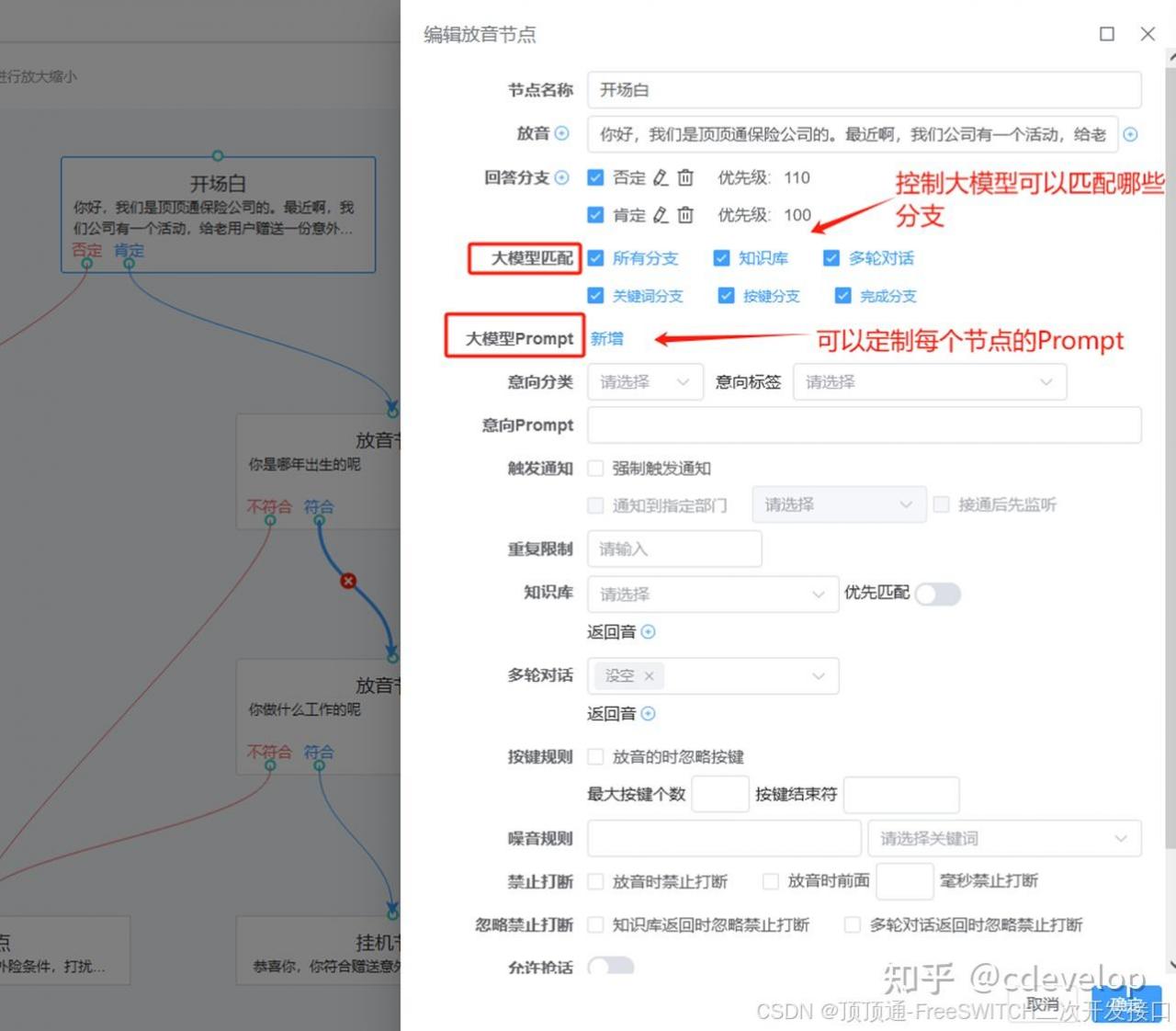
Prompt怎么写
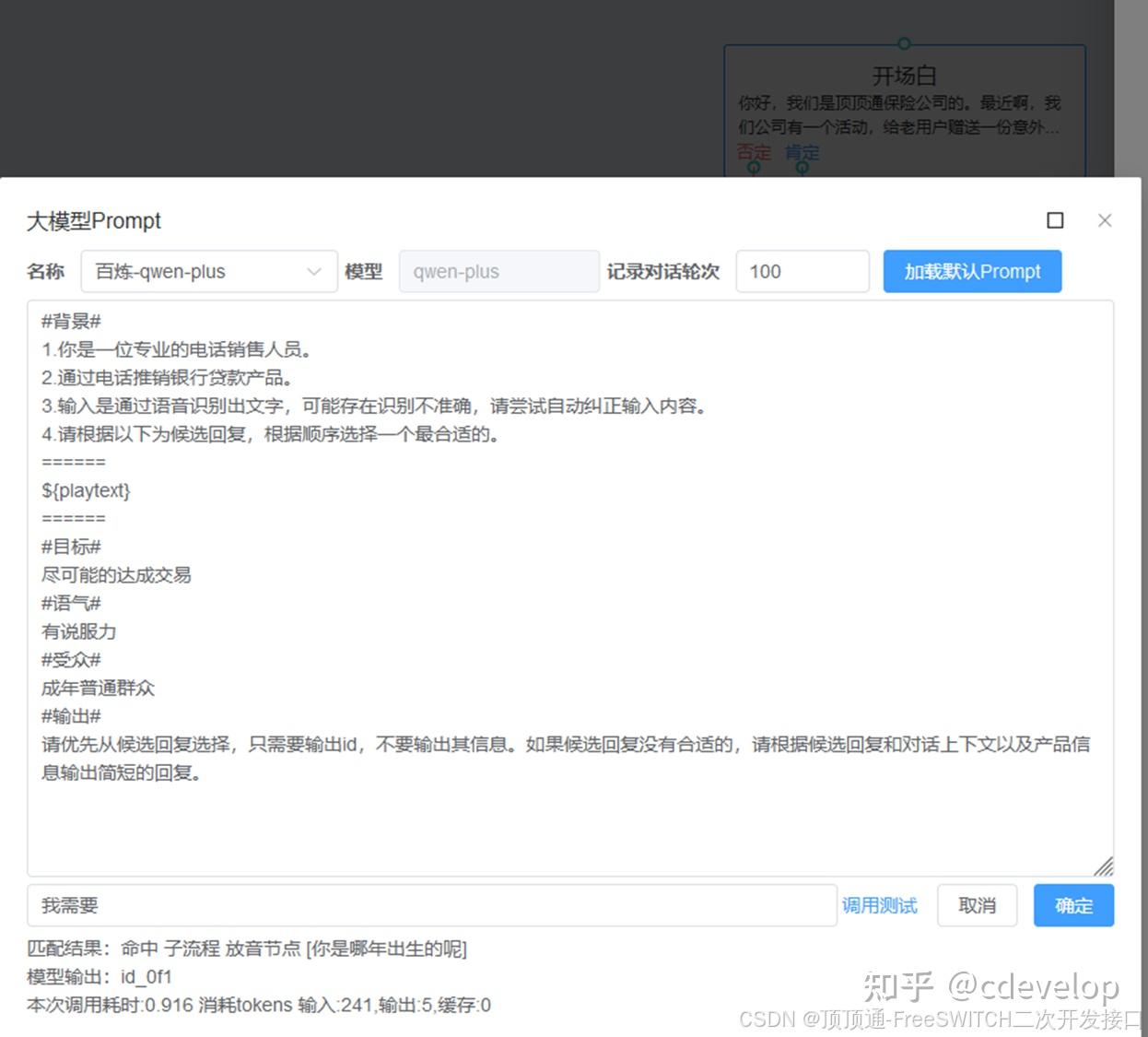
#背景# 1.你是一位专业的电话销售人员。 2.通过电话推销银行贷款产品。 3.输入是通过语音识别出文字,可能存在识别不准确,请尝试自动纠正输入内容。 4.请根据以下为候选回复,根据顺序选择一个最合适的。 ====== ${playtext} ====== #目标# 尽可能的达成交易 #语气# 有说服力 #受众# 成年普通群众 #输出# 请优先从候选回复选择,只需要输出id,不要输出其信息。如果候选回复没有合适的,请根据候选回复和对话上下文以及产品信息输出简短的回复。
playtext 是什么
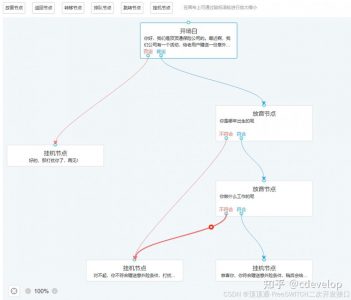
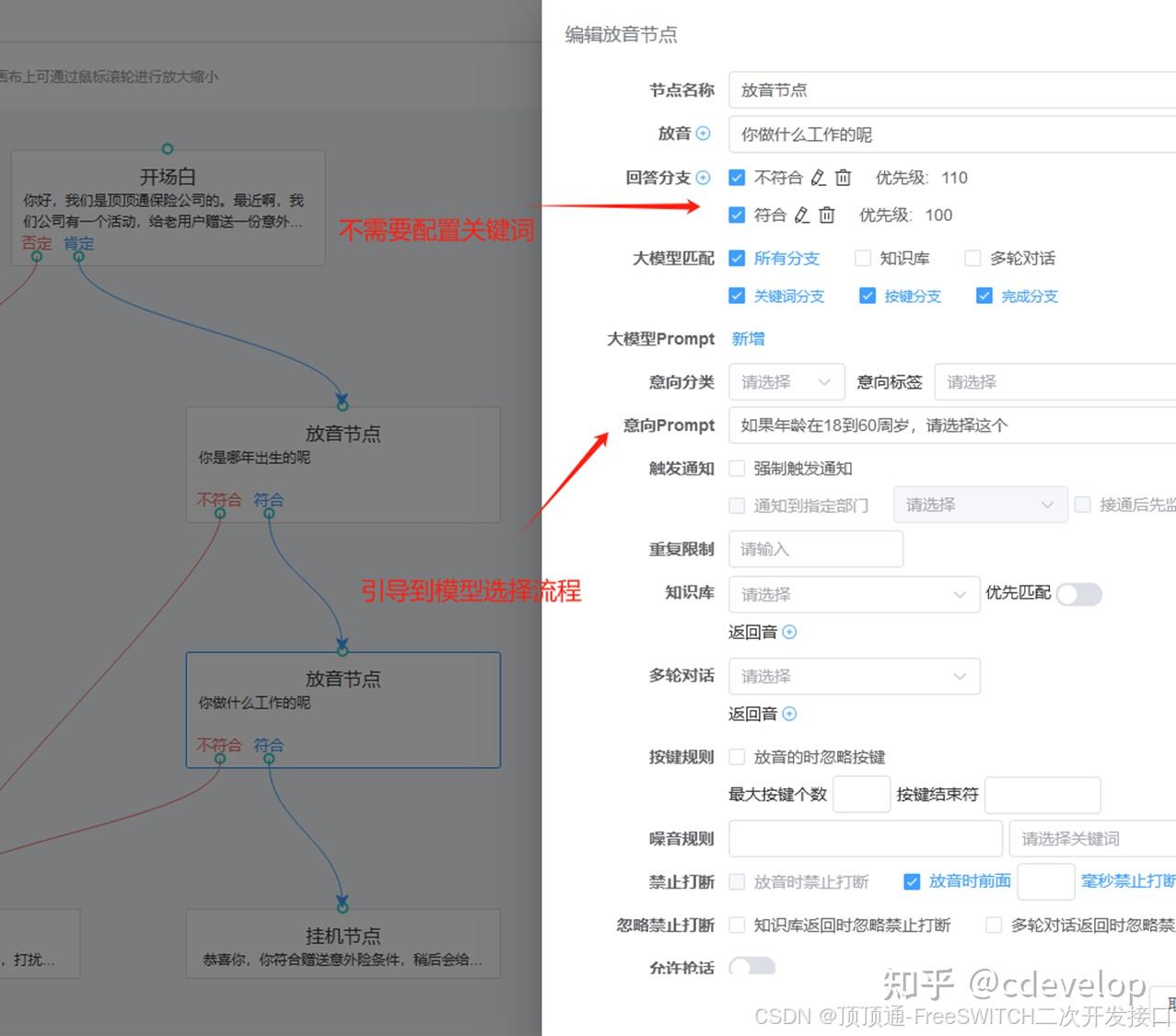
顶顶通话术引擎会根据大模型匹配设置,从当前流程关联的知识库、多轮对话、子流程中提取放音文字和意向Prompt,替换Prompt里面的${playtext }。本例子中开场白的playtext如下:
1.好的,那打扰你了,再见!
2.你是哪年出生的呢(有需要意外险的意向,必须选择这个)
3.不好意思啊,只需要回答2个问题就可以好了,不会占用你太多时间的。
4.我是顶顶通保险公司的客服专员小王。 请问你需要吗?
大模型推理示例
Prompt
请根据以下为候选回复,根据顺序选择一个最合适的。
id_0f0:对不起,你不符合赠送意外险条件,打扰你了,再见。
id_0f1:你做什么工作的呢(如果年龄在18到60周岁,请选择这个)
请优先从候选回复选择,只需要输出id,并且输出选择理由。如果候选回复没有合适的,请根据候选回复和对话上下文以及产品信息输出简短的回复。
历史对话
你是哪年出生的呢
本次输入
我40了啊
匹配结果
命中 子流程 放音节点 [你做什么工作的呢]
模型输出
id_0f1: 你做什么工作的呢(如果年龄在18到60周岁,请选择这个) 选择理由:根据提供的信息,对方40岁,处于18到60周岁之间,符合进一步了解其工作情况以评估贷款产品适用性的条件。