白嫖coze+飞书,搭建自己的微信公众号每日跟踪AI总结机器人,告别资讯焦虑
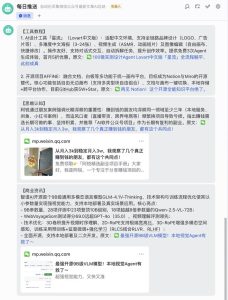
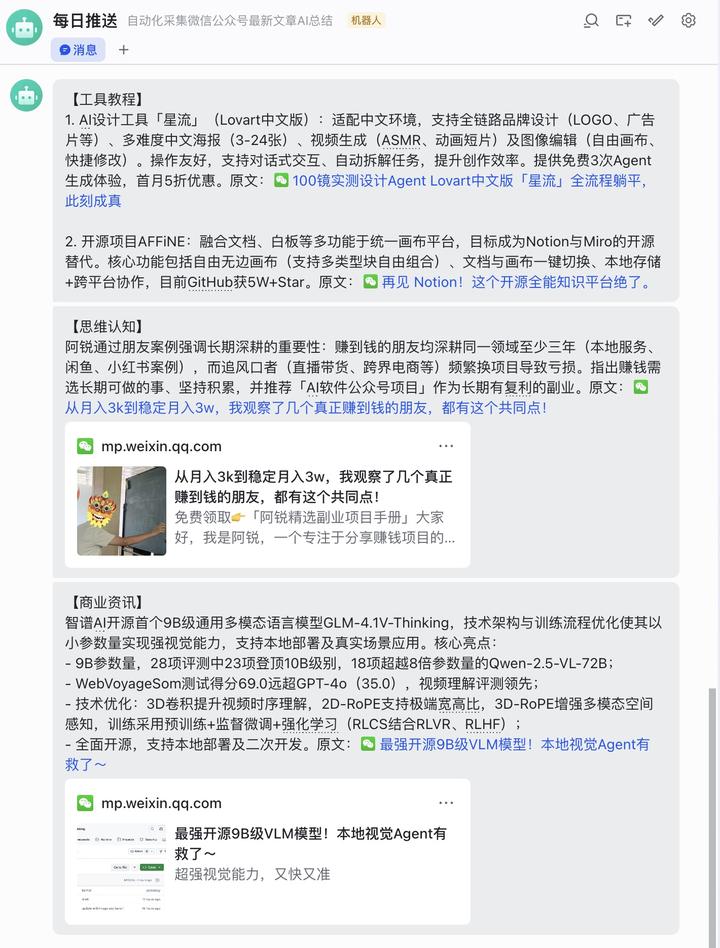
不知道你是否也有被信息爆炸的困扰,感觉自己逐渐沦为被平台推送支配的工具人?是否想按照自己的意志获取信息流,将自己的有限的时间投入到真正有价值的信息中?如果你也有同样的困扰,这篇文章将作为一个起点,扭转你与平台的地位,让你开始自主决定眼前信息的来源、信息的质量、信息展现的形式。
微信公众号是垂类信息干货的主流平台,面对AI时代的资讯爆炸,想要紧跟工具应用的更迭,需要关注众多博主阅读大量文章,非常耗费精力,因此我开始尝试通过大模型和工作流的方式构建自动化机器人帮我采集总结,每天形成简报推送给我,以此过滤低质信息,提高整体效率。
方案摸底
当前wcpluspro、优采云、新榜等成熟平台主要面向公众号历史文章批量采集,作为每天运行的汇总小工具,这种按时按个收费价格的确实不值得,因此我开始抱着白嫖的心态探索自建方案,说干就干,步骤拆解后调研过程如下:
1. 微信公众号文章采集方案
- 方案一:影刀 RPA 通过微信公众平台后台接口进行页面抓取
优点:技术门槛较低,可视化页面编写采集程序
缺点:需要桌面化系统和浏览器配合,占用系统控制权,微信公众号平台需要扫码登录 - 方案二:python selenium库通过模拟浏览器访问微信公众号后台接口进行脚本抓取
优点:脚本环境依赖简单,只需要偶尔配合浏览器扫码登录
缺点:脚本编写有门槛,微信公众号平台2-3天会登陆过期,需要扫码登录 - 方案三:通过开源项目WeWe RSS采集公众号文章,通过RSS阅读器进行阅读
优点:整体比较优雅,无需了解微信机制,页面配置,展现友好
缺点:需要科学上网,云服务器+docker部署等资源技术,有接口不稳定帐号失效等问题 - 方案四:通过anyproxy客户端代理解析微信https接口信息进行数据抓取
优点:从协议层模拟实际访问,无风控风险,适合长期大规模方案
缺点:多端开发,协议插件代理复杂
2. 大模型总结分析汇总方案
- 方案一:全量获取文章内容使用大型语言模型(LLMs)高效总结多文档内容
问题点:多文档长文本可能超出上下文范围会使大模型失效,无法一次性灌入理解 - 方案二:先对单篇文章进行摘要抽取,在讲多篇摘要内容交给大模型归类汇总
3. 机器人消息推送方案
- 方案一:微信推送机器人方案
面向个人微信的推送服务项目:chatgpt-to-wechat、NGCBot、智能微秘书等均面临封号下架风险,集体阵亡。
当前微信生态只支持企业微信推送消息服务,企业微信需要自建服务代理,固定域名公网IP备案,成本较大。(可采纳 server酱Turbo 版进行服务号信息推送,但多文字展现形式较差,与其他服务号信息混杂无法隔离,收费 8元/月) - 方案二:飞书推送机器人方案 飞书开发平台创建个人应用,通过调用API接口可向个人发送消息,调研上限 1W/月,完全满足
最终方案
- python脚本通过微信cookie采集按照公众号关注列表查询最新文章信息(可选择性将采集数据落盘到Mysql数据库)
- 调用coze工作流对每日文章进行摘要总结、质量打分、领域分类
- 汇总今日重点信息通过飞书机器人发送至飞书消息
- 定时任务每天定时执行脚本
注意:
- 微信cookie只能模拟浏览器进行扫码刷新,python脚本相对RPA的环境更加直接(非技术人员可选择RPA)
- coze工作流:微信cookie和token会过期,需要手动刷新填入,但可以薅平台羊毛,单日500资源点,单篇20-30点消耗
项目实践
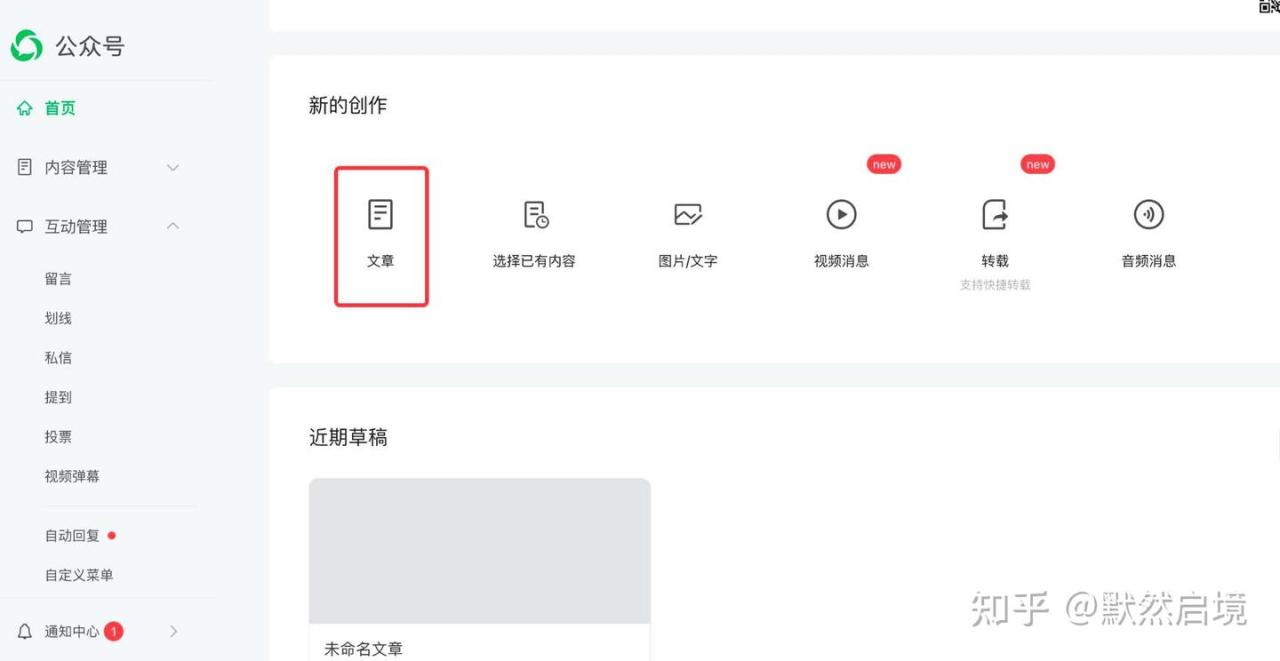
1. 抓取公众号最新文章列表
通过微信公众平台后台文章按钮进入
通过编辑页面后,点击超链接界面,可以搜索其他作者账号,查找账号所有文章列表
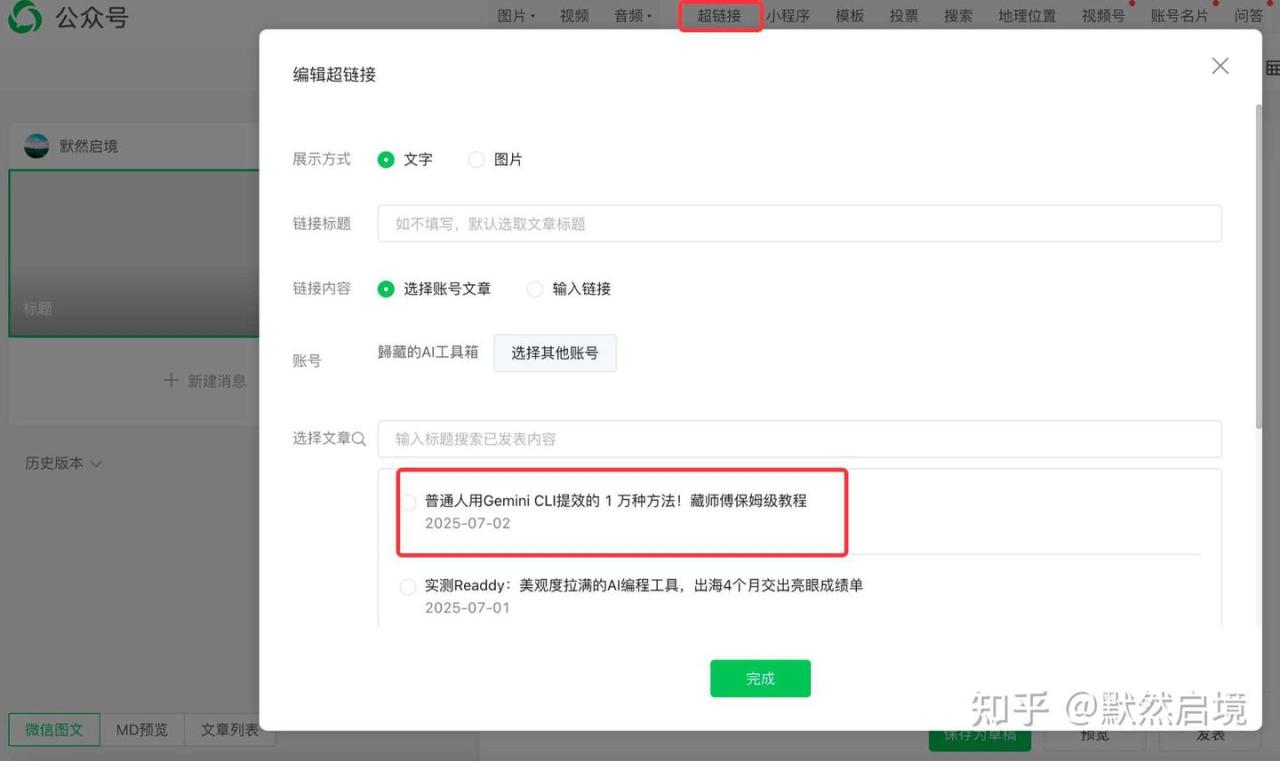
我们可以通过这两个搜索接口先查找到关注账号fakeid,然后通过fakeid来查寻账号历史文章列表
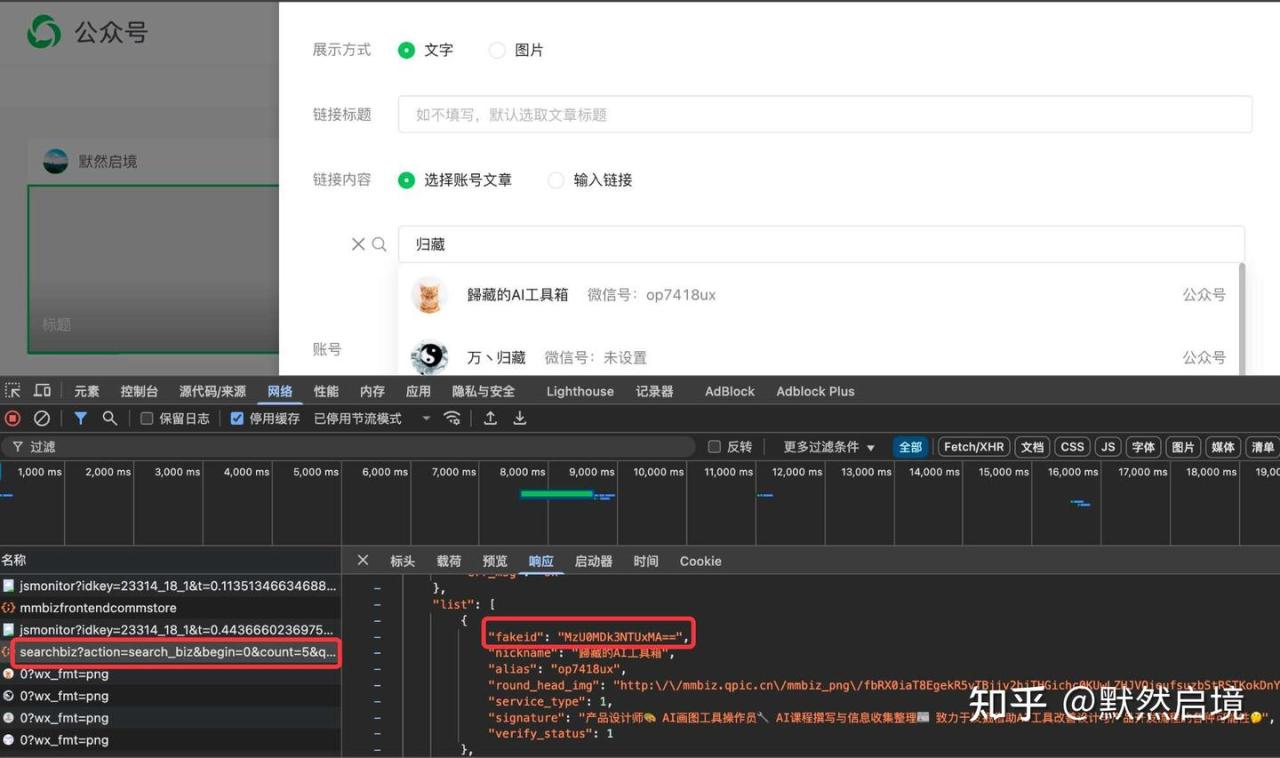
通过账号fakeid分页查询对应账号的文章列表,可从结果中解析到最新文章的url
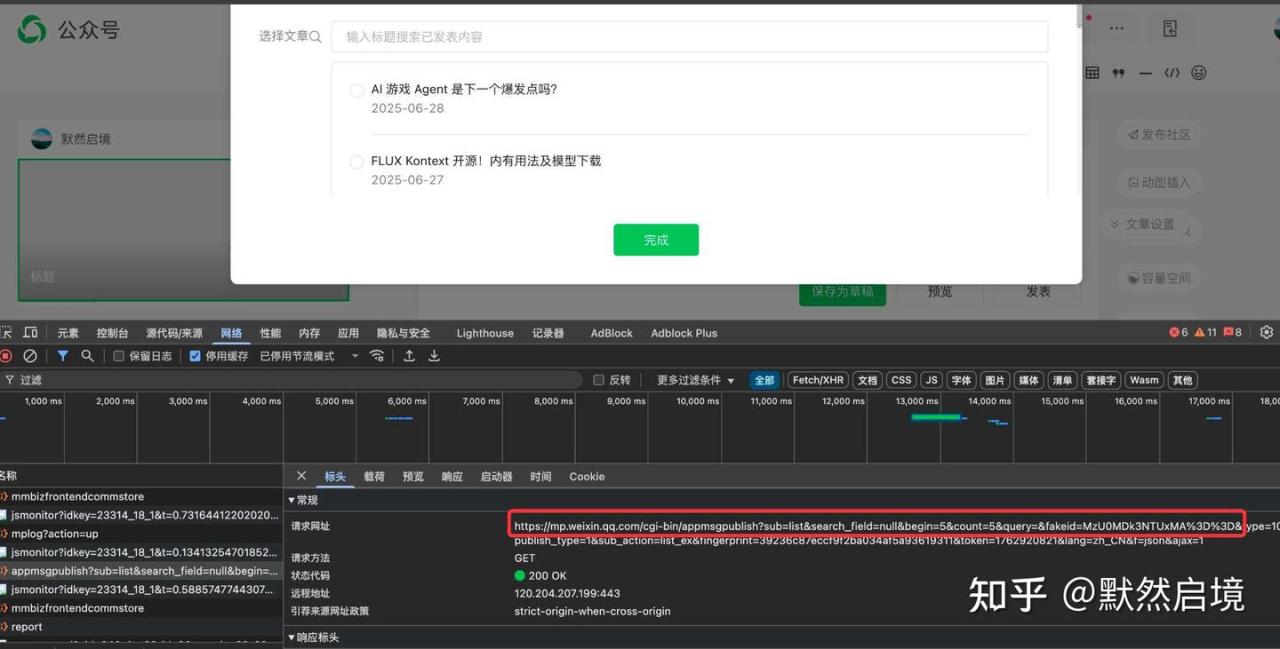
由于接口访问需要带平台cookie和token,因此Python自动化脚本可以调用selenium库定期登录微信公众号平台刷新cookie,然后刷新token,再依次遍历所关注的公众号账号列表,获取fakeid,然后获取最新文章列表,关键代码如下:
#爬取微信公众号文章,并存在本地文本中
def get_wechat_upper_article_url(cookies_str):
#query为要爬取的公众号名称
#公众号主页
url = 'https://mp.weixin.qq.com'
#设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
cookies = json.loads(cookies_str)
#登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,从这里获取token信息
response = requests.get(url=url, allow_redirects=False, cookies=cookies)
if not response.headers.get("Location"):
logging.info("微信cookie已过期,重新登录刷新")
cookies = weChat_login()
if not cookies:
feishu_send_message("微信cookie过期,请重新登录刷新")
return
cookies = json.loads(cookies)
response = requests.get(url=url,allow_redirects=False,cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.headers.get("Location")))[0]
logging.info("微信token:"+ token)
article_urls = []
for account_name, account_id in gzlist.items():
#搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token' : token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': account_name,
'begin': '0',
'count': '5'
}
#打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
logging.info("fakeid:" + fakeid)
#微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0',#不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
#打开搜索的微信公众号文章列表页
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
item = fakeid_list[0]
# 采集item示例
new_article = {
'title': item.get('title'),
'article_url': item.get('link'),
'account_id': account_id,
'account_name': account_name,
'publish_time': datetime.datetime.fromtimestamp(int(item.get("update_time"))).strftime('%Y-%m-%d %H:%M:%S'),
'collection_time': datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
}
logging.info("new_article:", new_article)
article_urls.append(item.get('link'))
time.sleep(2)
return article_urls
2. coze工作流大模型总结
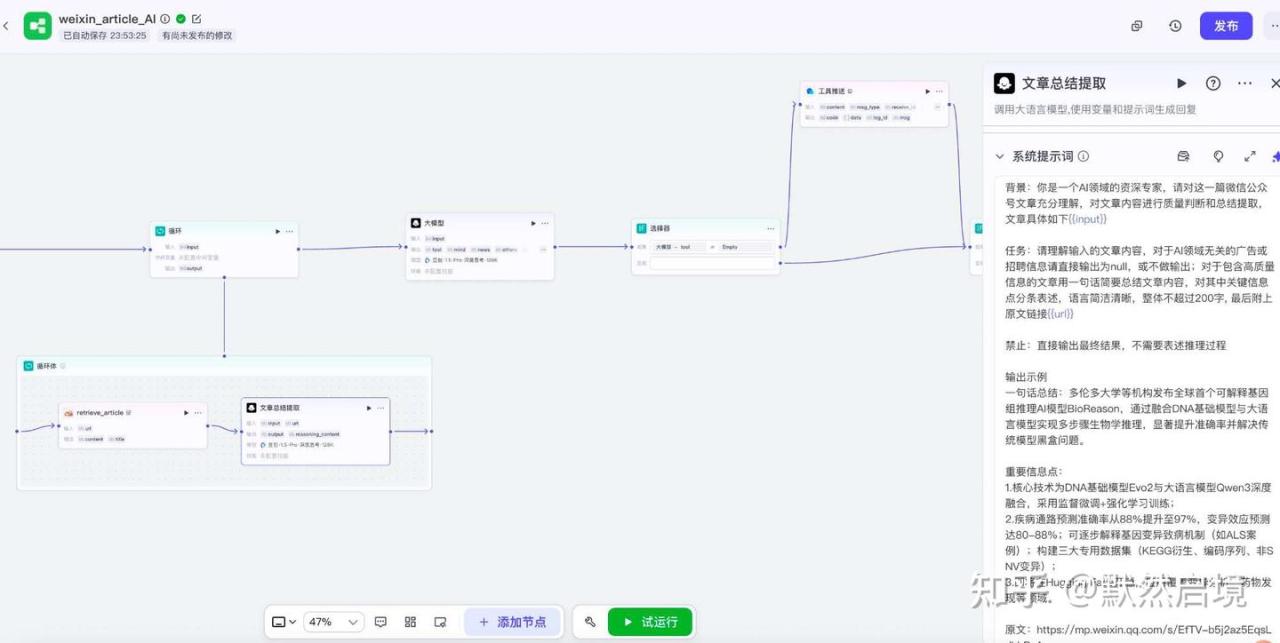
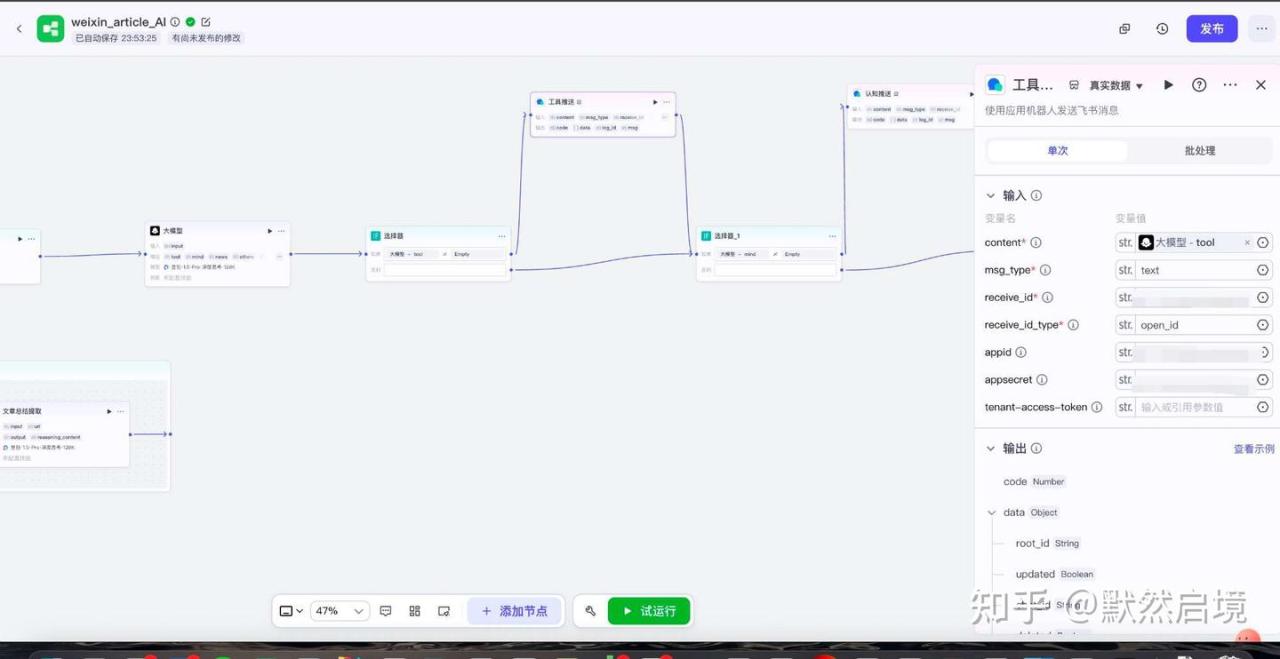
coze微信文章抓取AI总结分类飞书推送工作流全貌

使用AI大模型对单篇文章内容进行提取摘要,整体遍历后再分类汇总
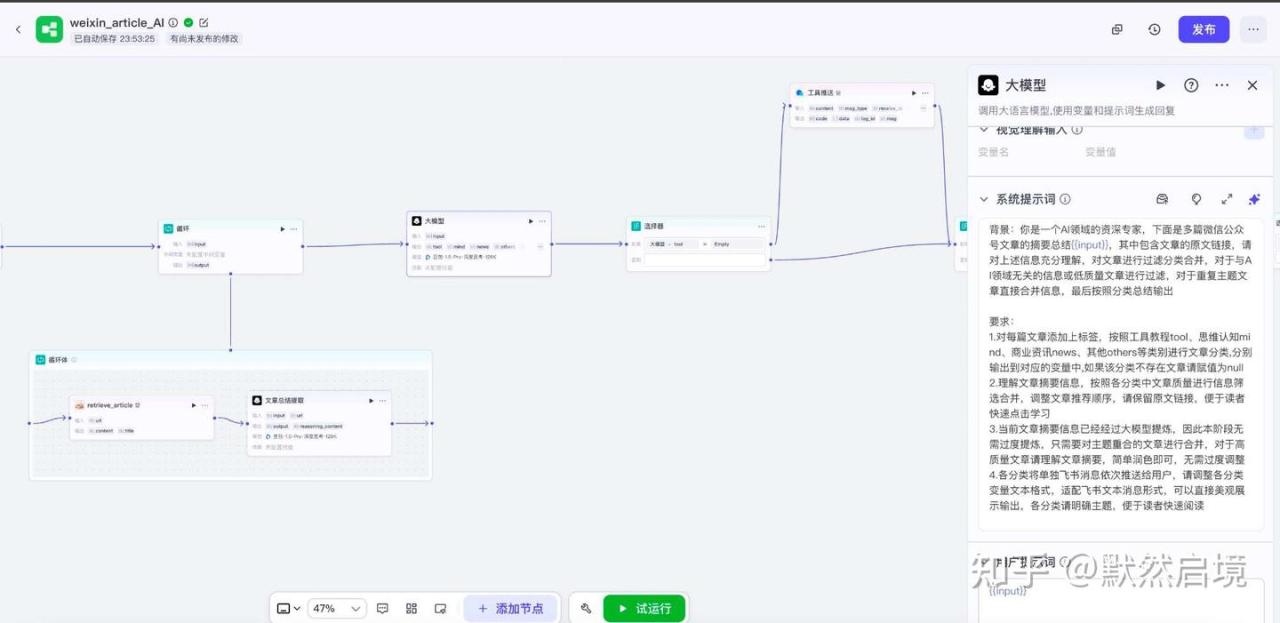
coze调用飞书机器人推送消息到个人飞书
通过coze API接口调用工作流需要使用个人访问令牌
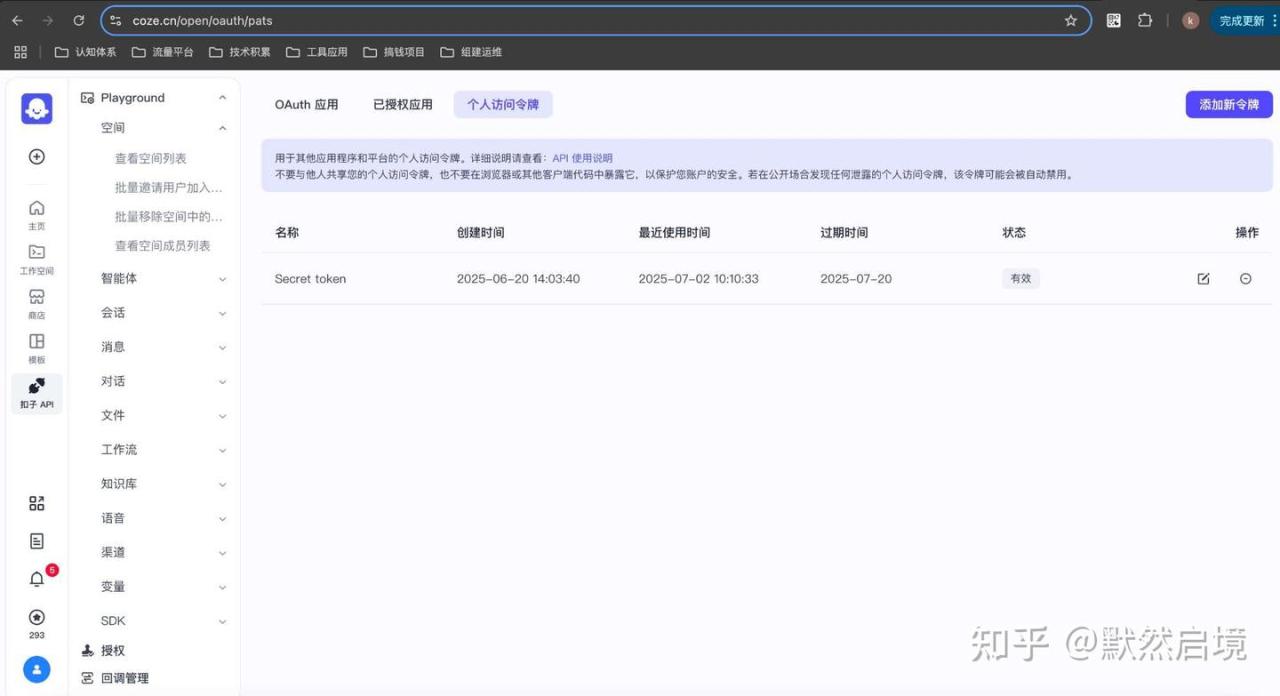
个人访问令牌最长有限期为一个月,可使用cookie调用接口刷新,具体调用函数如下:
def coze_workflow_run(token, workflow_id, parameters):
"""
通用Coze平台工作流API调用函数
:param token: Bearer Token字符串(不含'Bearer '前缀)
:param workflow_id: 工作流ID
:param parameters: dict类型,API参数
:return: 返回API响应内容
"""
logging.info("调用coze工作流开始")
url = 'https://api.coze.cn/v1/workflow/run'
headers = {
'Accept': '*/*',
'Authorization': f'Bearer {token}',
'Content-Type': 'application/json',
}
data = {
'workflow_id': workflow_id,
'parameters': parameters
}
response = requests.post(url, headers=headers, data=json.dumps(data))
try:
return response.json()
except Exception:
return response.text
3. 飞书机器人消息推送
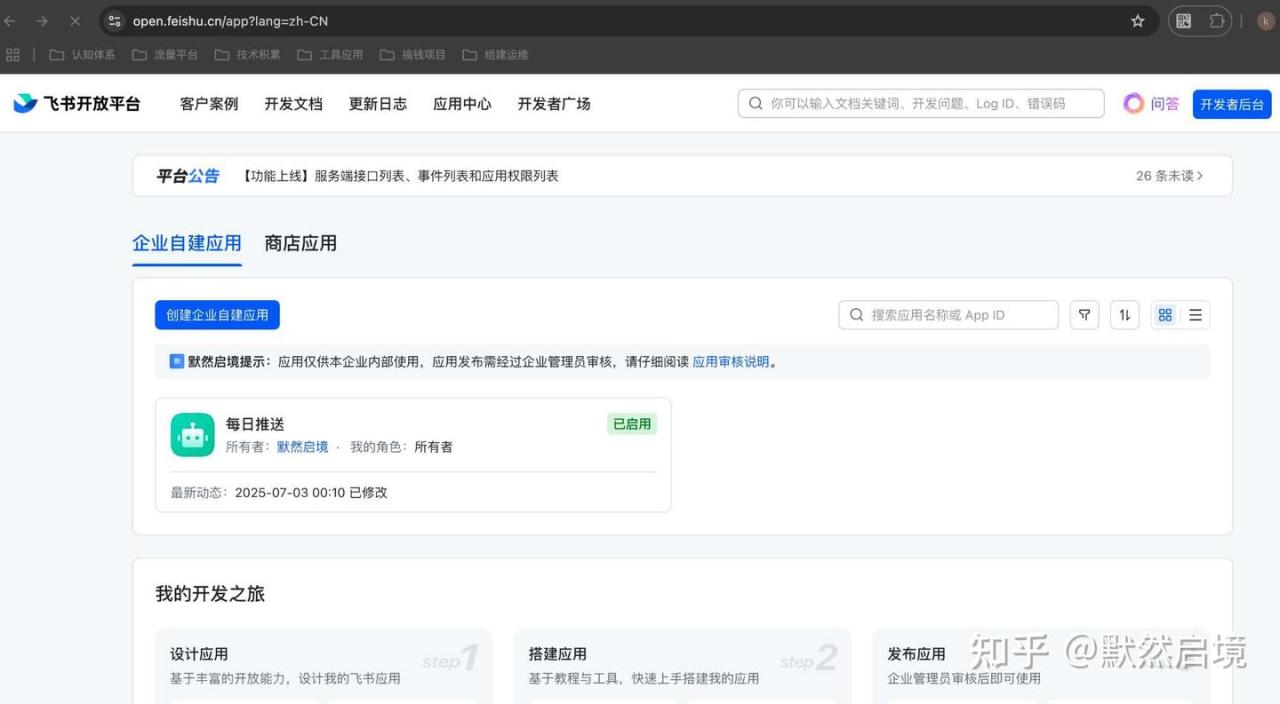
通过飞书开放平台自建每日推送机器人
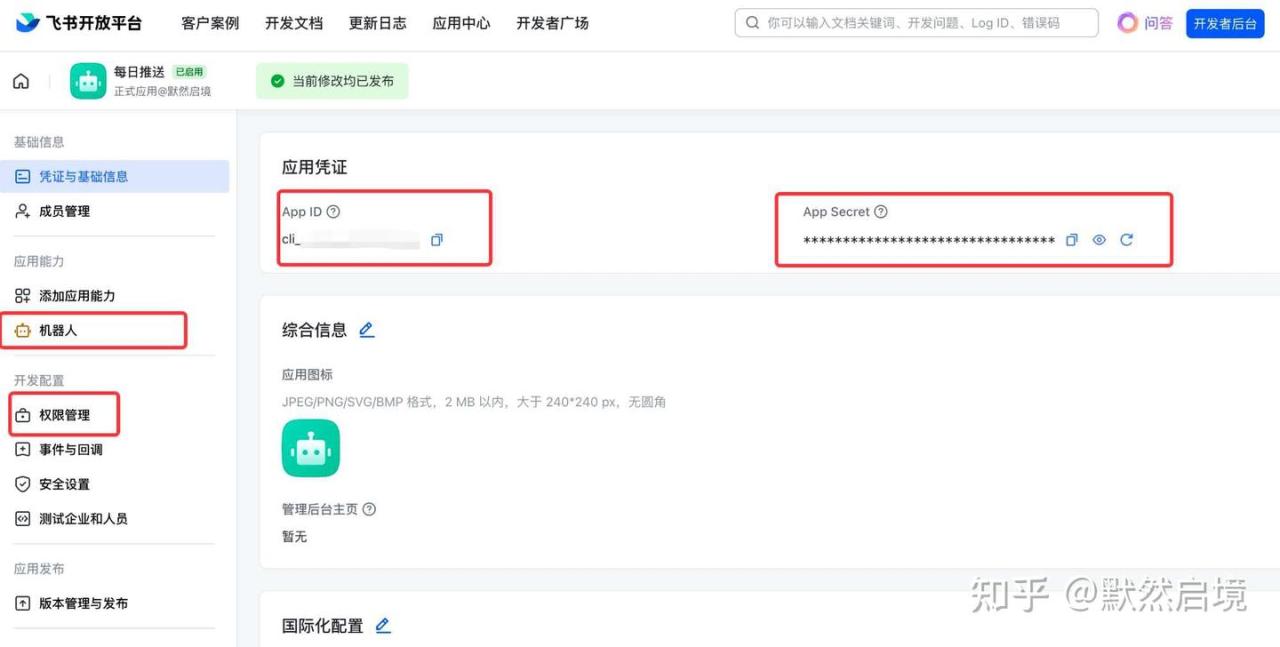
飞书开放平台自建应用添加机器人能力,申请消息发送权限,然后通过AppID和AppSecret进行接口访问
发送消息接口文档如下,可选择最简单的文本消息和open_id的类型发送,api 调用上限 1w/月,满足个人使用
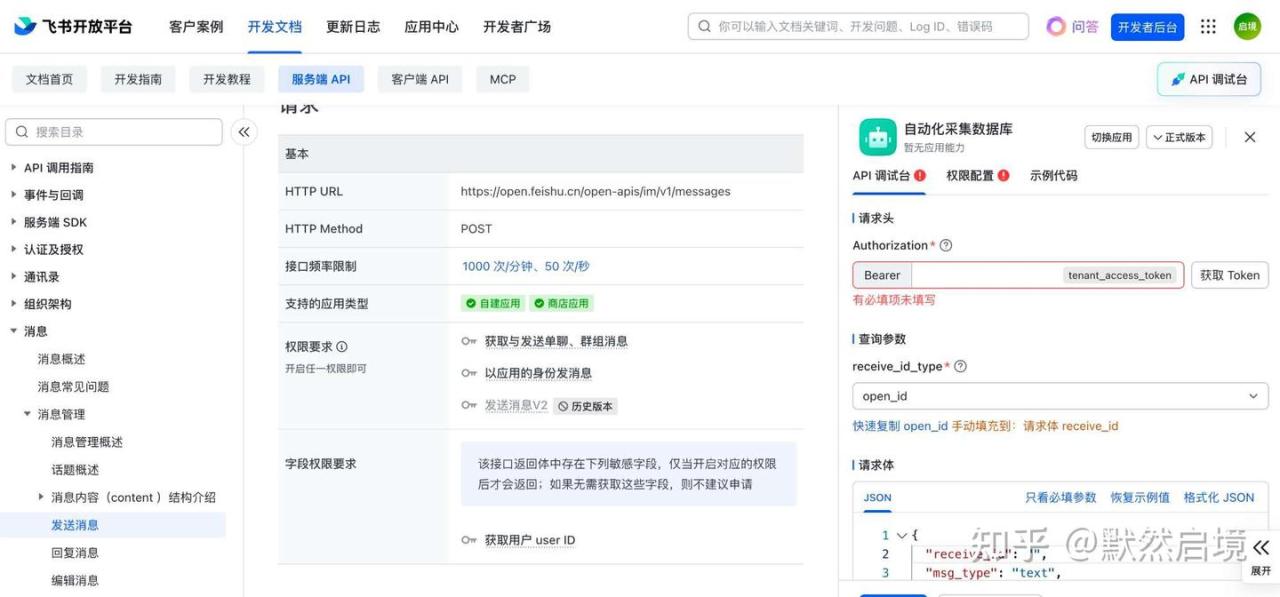
4. 定时任务
最终形成完整的自动化脚本,通过定时任务进行调度执行,最终形成每日独有的总结日报
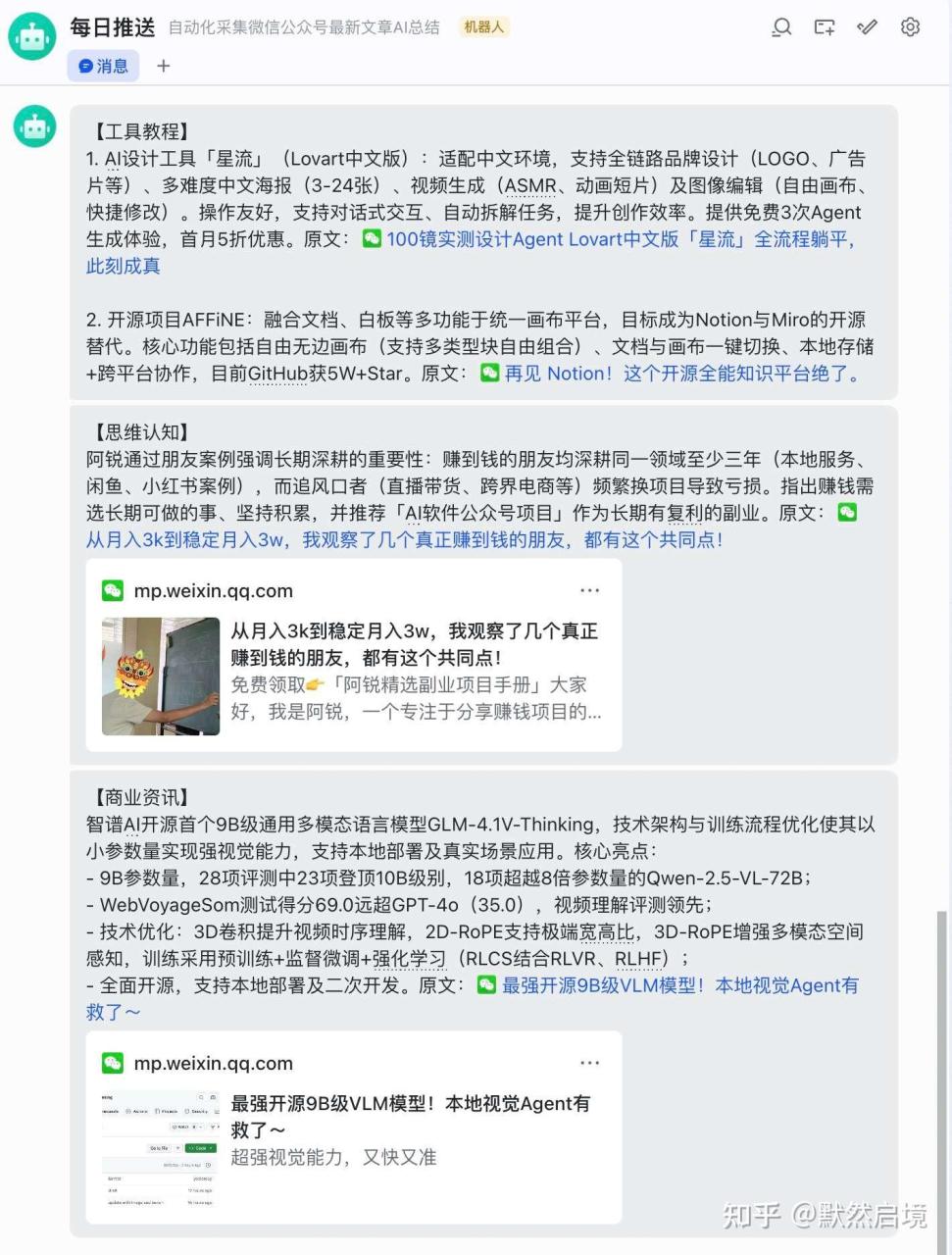
总结
以上是使用python脚本+coze工作流+飞书机器人进行微信公众号自动采集总结的实践思路,整体技术方案主打环境简单+资源白嫖,作为起步阶段,先达到可运行满足核心需求比较重要。至于版本2.0: RSS采集+企业微信推送方案要求的环境较为复杂,但运行效果差不多,因此暂时放一放,如果后续不满足日常需求了,我接着升级,继续给大家出教程
最后,欢迎大家在留言区写下你的建议和问题,随手点赞,一起飞。
** 需要完整工作流和脚本,请关注公众号并回复你的coze用户名,以便我邀请你加入coze共享空间,交流联系请扫码加我好友。