你的「微信克隆人」来了,分享一个极具争议的开源项目!
链接:https://zhuanlan.zhihu.com/p/1961149424634950924
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
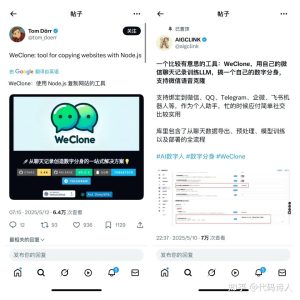
分享一个最近GitHub爆火,但是极具争议的开源项目—weclone。
一句话总结就是:能根据你上传的微信聊天记录,给自己克隆一个“数字分身”。
不仅能复刻你的说话方式、口头禅、聊天节奏,就连“嗯嗯”“哈哈”“咋啦”这种小细节都能精准还原。
如果你给的聊天记录中有语音数据。它还能结合 Spark-TTS模型,把你的声音一比一克隆出来,自动帮你回复语音消息。
你甚至不用担心它会乱说话,Weclon可以设置敏感词过滤,防止它胡说八道。
它还支持接入微信、QQ、飞书、Telegram 等全球主流社交平台,全平台通用。
想象一下,你正在跟一个熟悉的人微信对话,觉得语气一如既往、用词习惯熟悉得像老朋友——但你完全不知道,对面其实是一个“数字分身”。
是不是有点细思极恐?😨😨
因为效果过于惊人。所以它的争议也很大。
如果聊天数据被别有用心的人拿去训练,风险极高。
但是想象一下,要是企业用它来训练客服,把销冠的话术全都喂进去,直接复制出几个“销冠客服”,业绩翻倍不是梦啊。
说了这么多,下面我们来进行实操:
01
项目地址
https://github.com/xming521/WeClone
02
基础配置
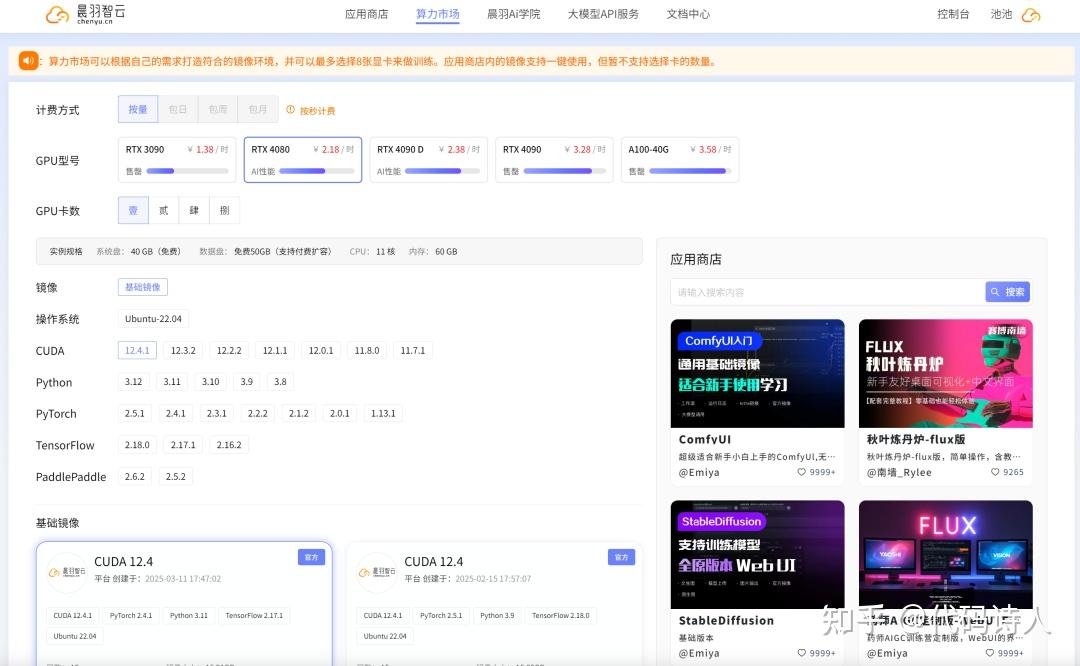
1.电脑配置:显卡显存最好16GB起步。
电脑配置不够的,可以考虑来晨羽,进行云端部署,数据完全隔离,不用担心隐私问题。
云端地址:https://www.chenyu.cn/console/shop
2、微信聊天记录:越多效果越真实,当然也是需要预处理。
这个项目默认会把数据里的手机号、身份证号、邮箱地址、网址这些敏感信息自动清理掉。
3、WeClone
- 用PyWxDump导出微信聊天记录(不支持4.0版本),转换为CSV。
- 数据预处理(去除隐私信息、无效数据,合并聊天内容)
- 微调大模型(可以用最新的Qwen3:8B模型试试)
- 绑定到聊天机器人(AstrBot全平台支持)
效果如何?
以下是使用Qwen2.5-14B-Instruct模型,大概3万条处理后的有效数据,loss(损失值)降到了3.5左右的效果。
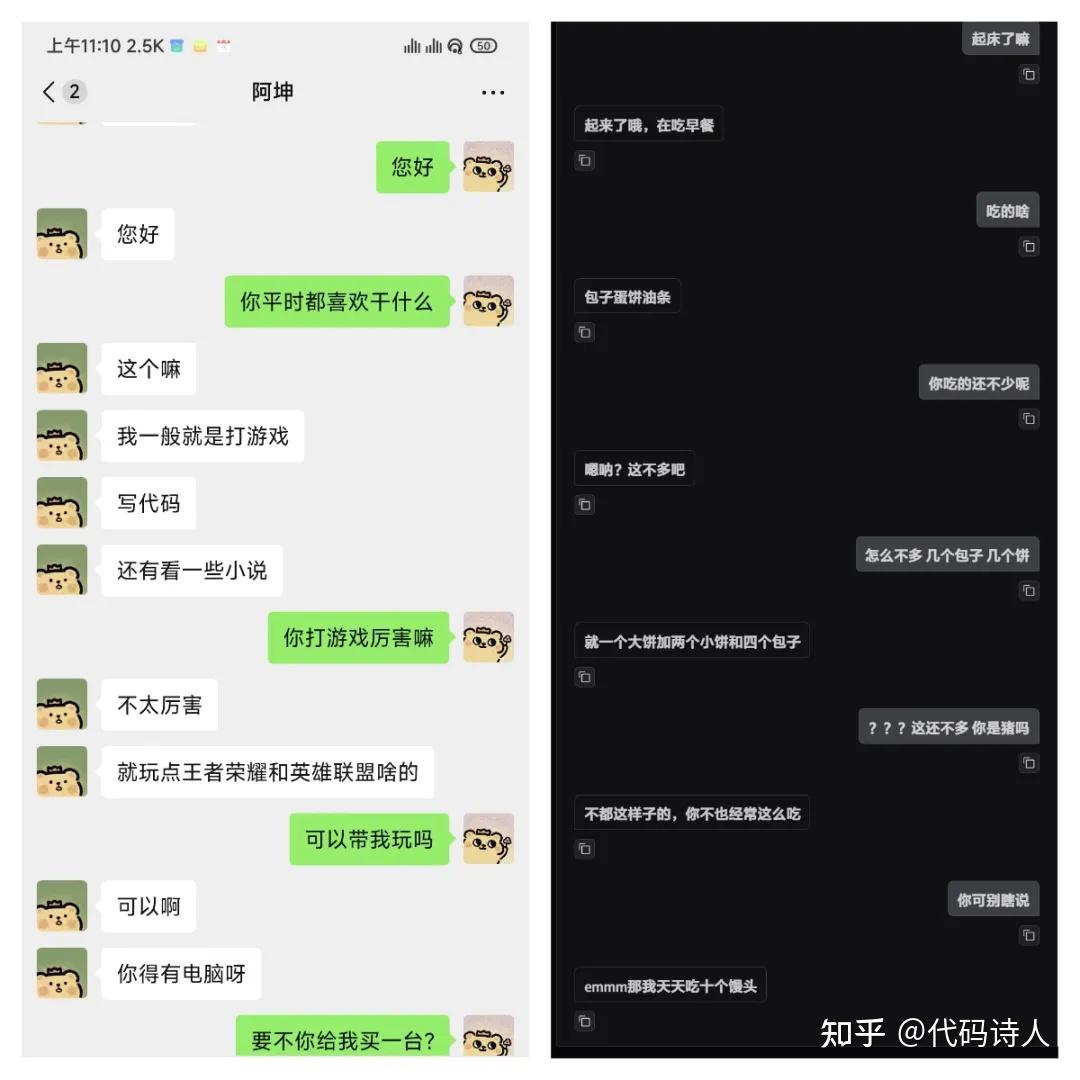
聊天效果展示
更详细的教程,Github项目地址里都准备好了。感兴趣的朋友可以操作起来。

你会怎么使用数字分身呢?欢迎在留言讨论~