Dify知识流水线,搞定复杂 PDF(含MinerU本地部署教程)

大家好,上篇文章接介绍了Dify内置模板中的父子模式,今天聊一下另外一个内置模板,复杂PDF怎么玩。
先看一下这些内置模板的通用流程,基本都是从数据源导入文档、解析文档、整理成结构化的数据、最后存储到数据库中。

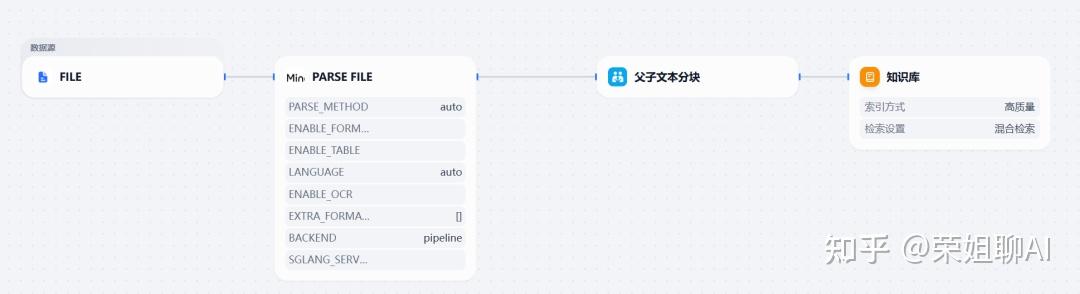
虽然用的还是父子文本分块,但是解析文档的节点变成了MinerU。
MinerU 是一款先进的开源文档提取器,专门用于将复杂的非结构化文档(例如常见的Office三件套Word、PDF、和PPT)转换为高质量、机器可读的格式(如Markdown和JSON)。MinerU 解决了文档解析中的诸多挑战,例如布局检测、公式识别和多语言支持,这些对于为 LLM 生成高质量的训练语料库至关重要。
所以说白了,解决这种复杂PDF的方案其实主要就是依靠MinerU强大的文档提取能力,提取PDF文件内的图像、表格及公式等。
1 整体流程
整体流程如下:数据源还是从本地文件举例。
选择通过知识流水线创建知识库。
选择Complex PDF with Images & Tables模版,或者从空白开始。
内置模板流程如下:
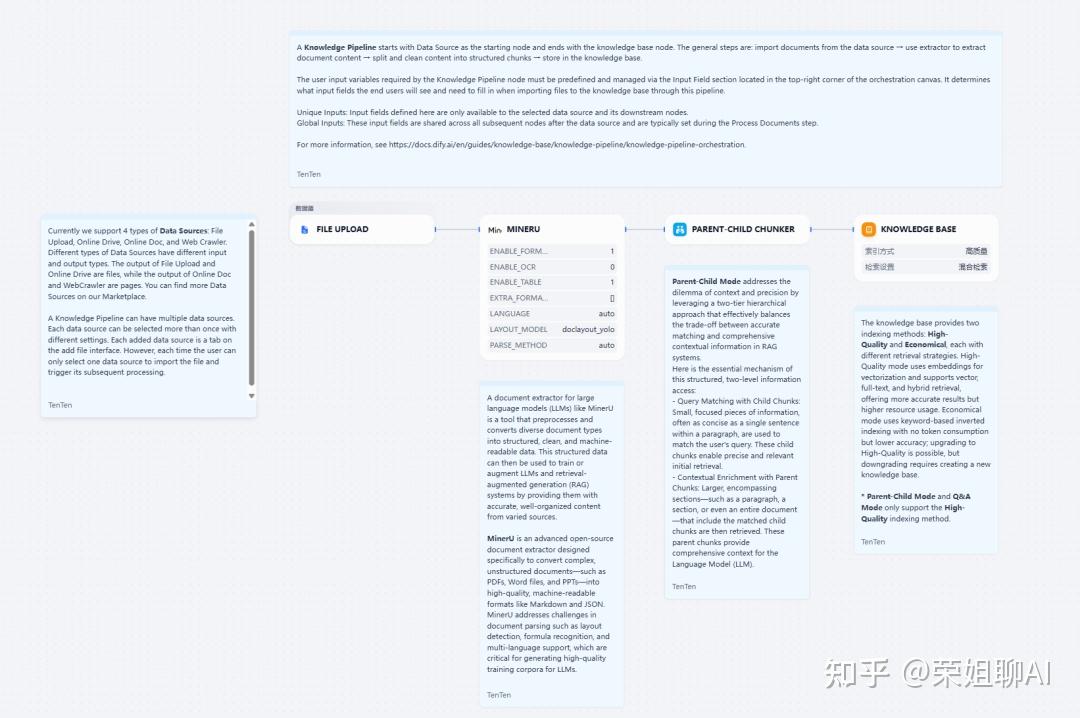
本次流程用到了两个插件:Mineru和父子文本分块。
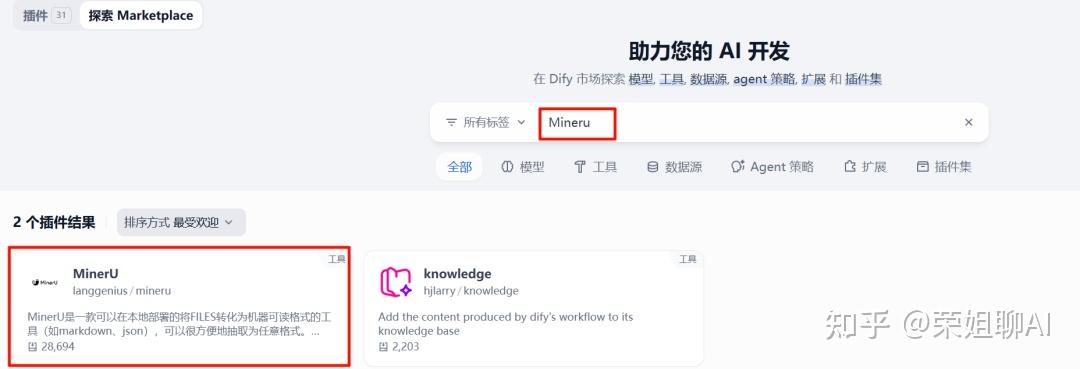
在插件市场搜索“Mineru”。MinerU是一款可以在本地部署的将FILES转化为机器可读格式的工具(如markdown、json),可以很方便地抽取为任意格式。
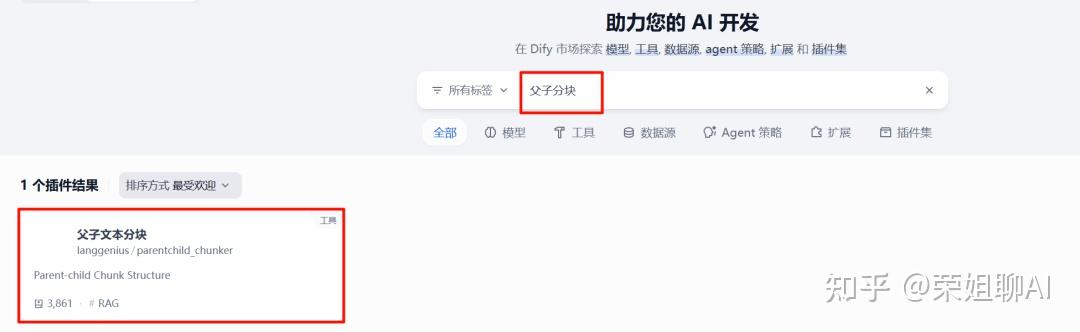
在插件市场搜索“父子分块”安装父子文本分块插件。
2 节点配置
2.1 数据源节点
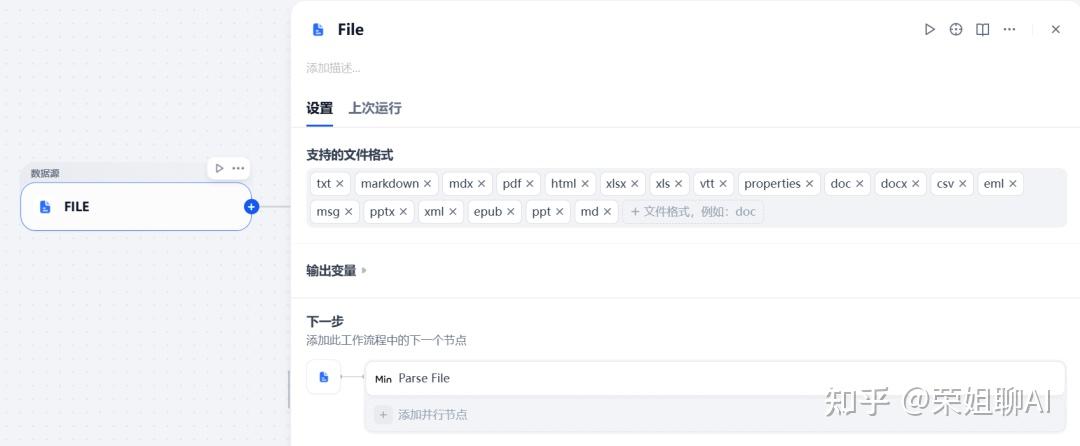
数据源节点是知识库最重要的基石,不同类型的数据源具有不同的输入和输出类型,比如文件上传和在线网盘的输出是文件,而在线文档和网页爬虫的输出是页面。在市场中可以看到很多类型的数据源,像Firecrawl、Notion、Jina Reader、GitHub等等,这里选择文件上传作为数据源。
2.2 MinerU节点
MinerU节点是一款文档提取器的插件,一种用于预处理并将不同文档类型转换为结构化、干净且机器可读的数据的工具。
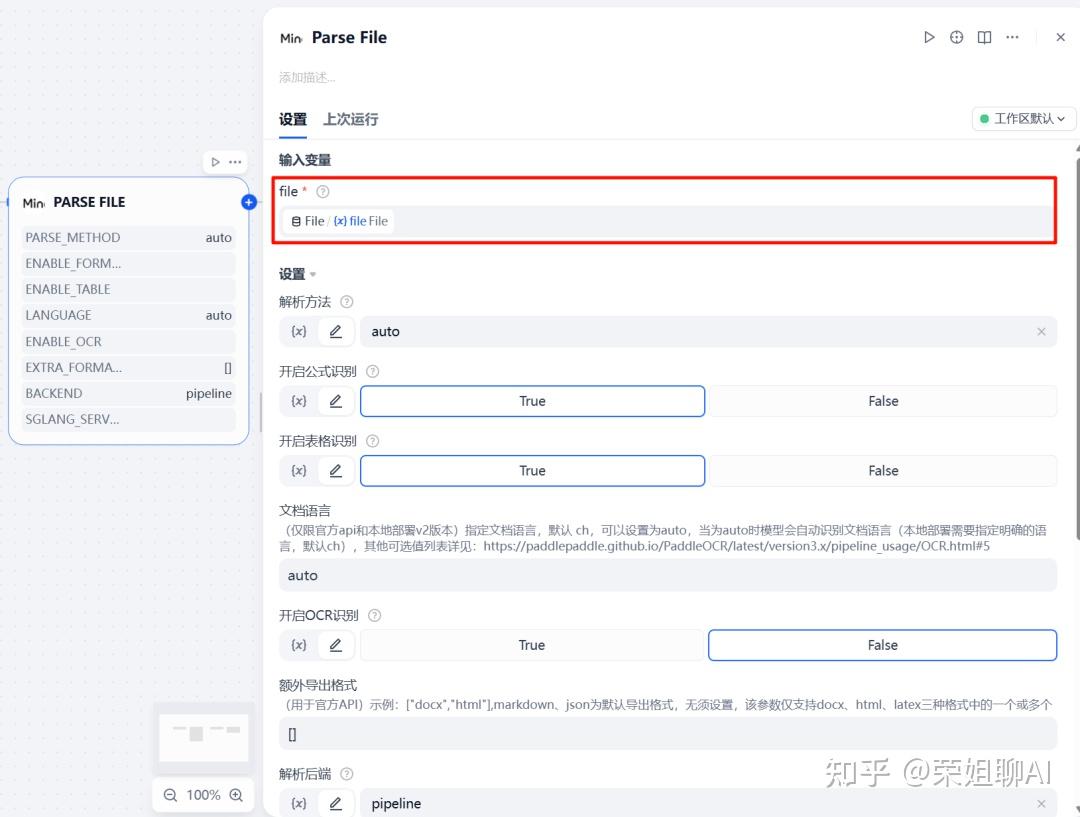
输入变量file接收数据源节点FILE的输出。(支持 pdf, ppt, pptx, doc, docx, png, jpg, jpeg)
输入参数设置:
- 解析方法:(用于本地部署v1和v2版本)解析方法,可以是auto, ocr, 或 txt。默认是auto。如果结果不理想,请尝试ocr。
- 开启公式识别:(用于官方API和本地部署v2版本)是否开启公式识别。
- 开启表格识别:(用于官方API和本地部署v2版本)是否开启表格识别。
- 文档语言:(仅限官方api和本地部署v2版本)指定文档语言,默认 ch,可以设置为auto,当为auto时模型会自动识别文档语言(本地部署需要指定明确的语言,默认ch)。
- 开启OCR识别:(用于官方API)是否开启OCR识别。
- 额外导出格式:(用于官方API)示例:[“docx”,”html”],markdown、json为默认导出格式,无须设置,该参数仅支持docx、html、latex三种格式中的一个或多个
- 解析后端:(用于本地部署v2版本)示例:pipeline、vlm-transformers、vlm-sglang-engine、vlm-sglang-client,默认值为pipeline。
- sglang-server地址:(用于本地部署v2版本 解析后端为vlm-sglang-client时)示例:http://127.0.0.1:8000,默认值为空。
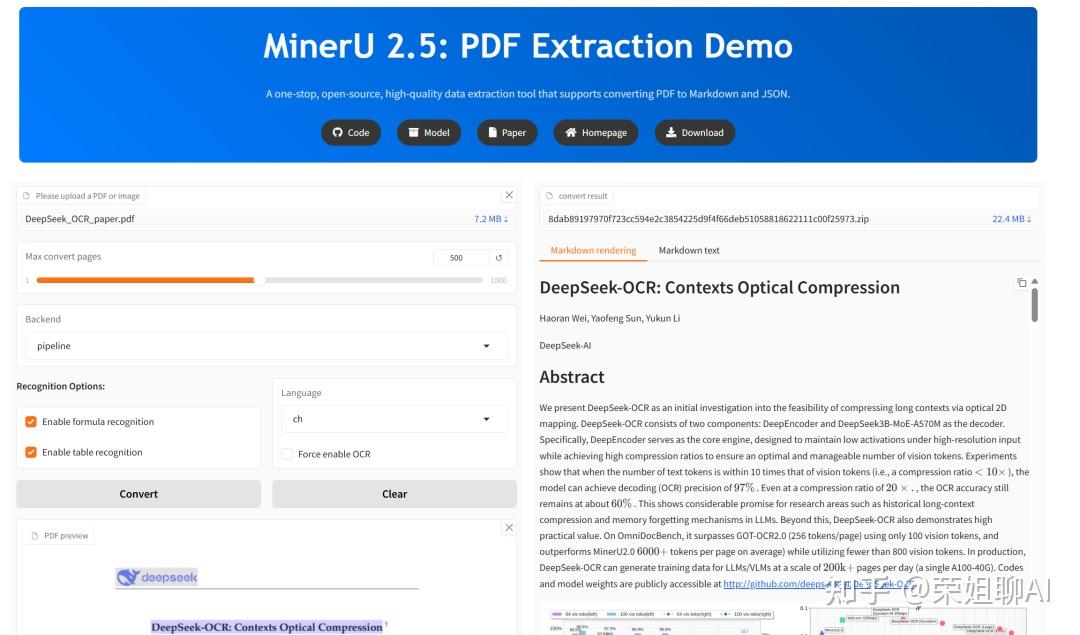
既然识别复杂PDF主要靠这个插件,那就先检测一下MinerU插件的能力吧。
我用Deepseek-OCR的那篇论文来测试一下,先来测试表格功能,下面是PDF中的表格信息:
MinerU识别后的信息,完美还原了表格信息。

再看看对数学公式的识别,看到这种公式真的头大,还好毕业了,终于不用算来算去了。

识别公式效果:

2.3 父子文本分块节点
父子模式(Parent-Child Mode) 通过利用一种双层分层方法,解决了上下文和精确性之间的两难问题,它在 RAG 系统中有效地平衡了准确匹配和全面的上下文信息之间的权衡。
以下是这种结构化的、双层信息访问的基本机制:
- 使用子块进行查询匹配 (Query Matching with Child Chunks): 使用小的、集中的信息片段(通常简洁到只是段落中的一个句子)来匹配用户的查询。这些子块能够实现精确且相关的初始检索。
- 使用父块丰富上下文 (Contextual Enrichment with Parent Chunks): 随后,检索包含匹配到的子块的、更大的、涵盖范围更广的部分——例如一个段落、一个章节,甚至整个文档。这些父块为大型语言模型 (LLM) 提供了全面的上下文。
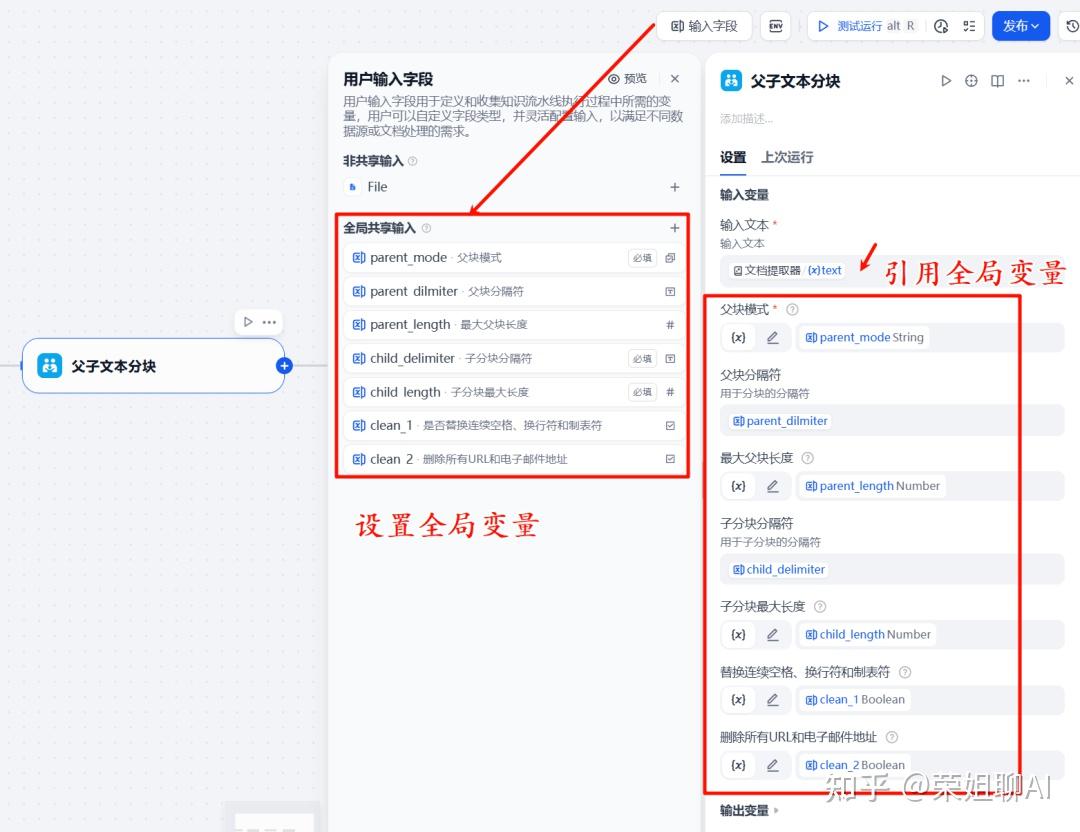
在这个模块中,我们可以看到8个参数。
1、输入文本:指定要进行分块处理的原始文本内容,这里接收文档提取器的结果。
2、父块模式:根据分隔符和最大块长度将文本拆分为段落,使用拆分文本作为检索的父块或整个文档用作父块并直接检索。所以这里面有两个选项:
- paragraph (段落模式):将文本段落拆分为父块
- full_doc (全文档模式):将整个文档用作父块(超过10,000个 token 的文本将被截断)
3、父块分隔符:设定一个或多个字符,用作将文本分割成父块的边界。
4、最大父块长度:用于分块的最大长度。如果一个按分隔符切分出来的段落超过了这个长度,它将被强行再次分割,以确保没有父块会过长。
5、子分块分隔符:用于子分块的分隔符。设定一个或多个字符,用于在已经切分好的父块内部进行二次分割,从而创建更小的子块。
6、子分块最大长度:用于子分块的最大长度。这确保了用于检索的文本块是小而精确的。如果按子块分隔符切分出的句子超过此长度,也会被强行分割。
7、替换连续空格、换行符和制表符:是否移除文本中的连续空格、换行符和制表符。
8、删除所有URL和电子邮件地址:是否移除文本中的URL和电子邮件地址。
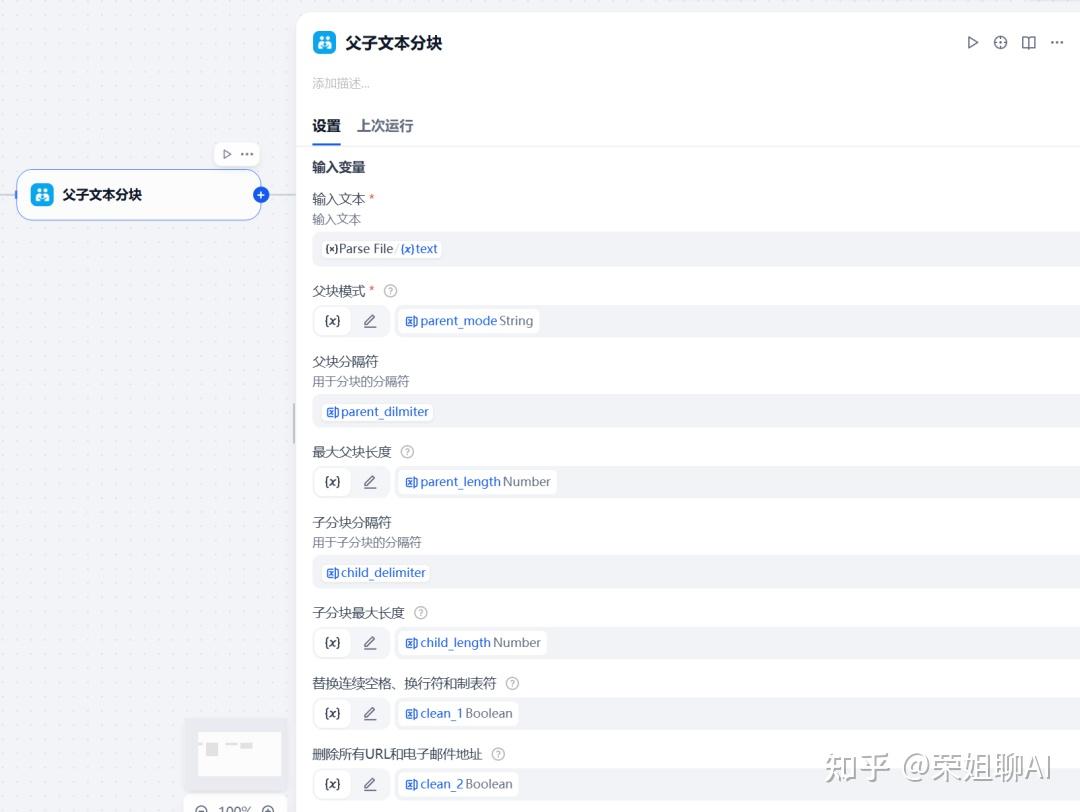
除了第一个输入的文本外,剩下的7个参数可以设置全局变量,方便进行灵活测试。
2.4 知识库节点
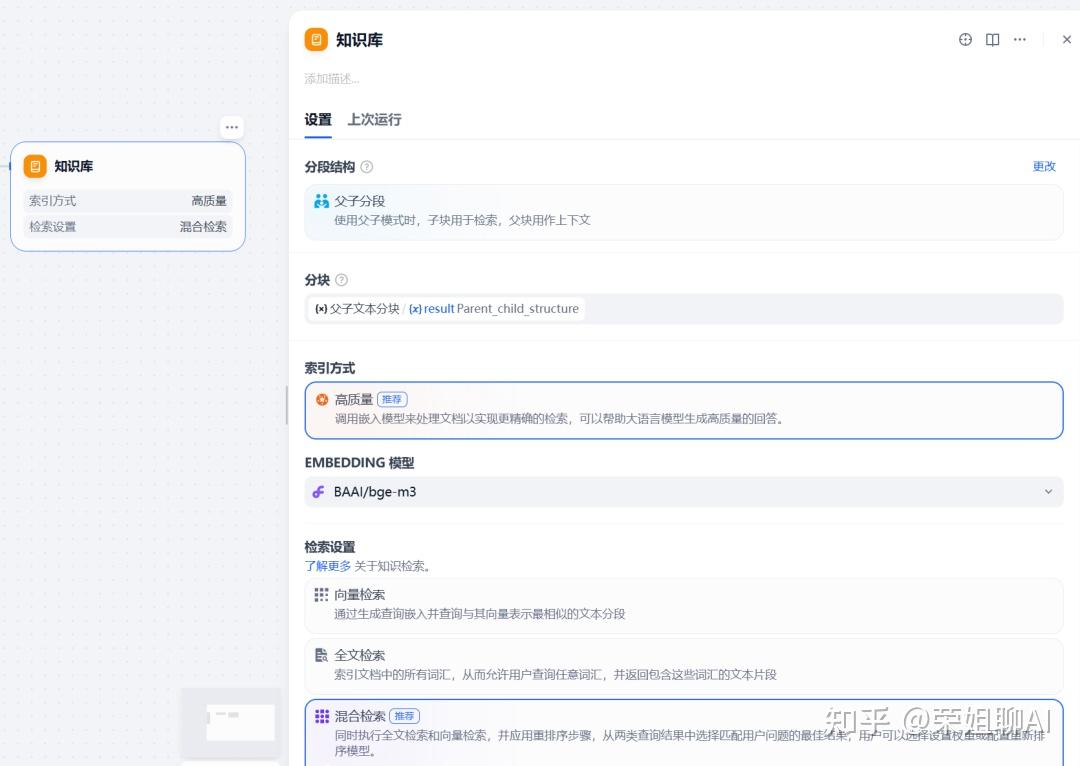
知识库提供两种索引方法:高质量(High-Quality)和经济型(Economical),每种方法都有不同的检索策略。高质量模式使用嵌入(embeddings)进行向量化,并支持向量、全文和混合检索,能提供更准确的结果,但资源消耗也更高。经济型模式使用基于关键字的倒排索引,没有 token 消耗,但准确性较低;可以从经济型升级到高质量,但降级则需要创建一个新的知识库。
父子模式(Parent-Child Mode)和问答模式(Q&A Mode)仅支持高质量索引方法。
所以这次的案例只能选择高质量索引方法。
具体配置如下:
1、分段结构:Dify 知识库支持三种分块结构:通用、父子和问答。每个知识库只能有一种结构。前一节点的输出必须与所选的分块结构相匹配。所以这里只能选择父子分段。
2、分块:接收父子文本分块节点的输出。
3、索引方式:知识库提供两种索引方法:高质量 (High-Quality) 和 经济 (Economical),两者各有不同的检索策略。但是父子模式只支持高质量索引。
- 高质量模式:使用 embeddings 进行向量化,支持向量检索、全文检索和混合检索。这种方式能提供更准确的结果,但资源消耗也更高。
- 经济模式:采用基于关键词的反向索引,不消耗 token,但准确度较低。此模式可以升级到高质量模式,但无法降级(如需降级,必须重新创建一个新的知识库)。
4、EMBEDDING模型:选择一个合适的向量模型模型。
5、检索设置:可选择向量检索、全文检索、混合检索。推荐使用混合检索。选择一个合适的重排序模型。
- 向量检索:通过生成查询嵌入并查询与其向量表示最相似的文本分段
- 全文检索:索引文档中的所有词汇,从而允许用户查询任意词汇,并返回包含这些词汇的文本片段
- 混合检索:同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果,用户可以选择设置权重或配置重新排序模型。
3 测试
把Deepseek-OCR的论文拿来测试一下,上传PDF文档。

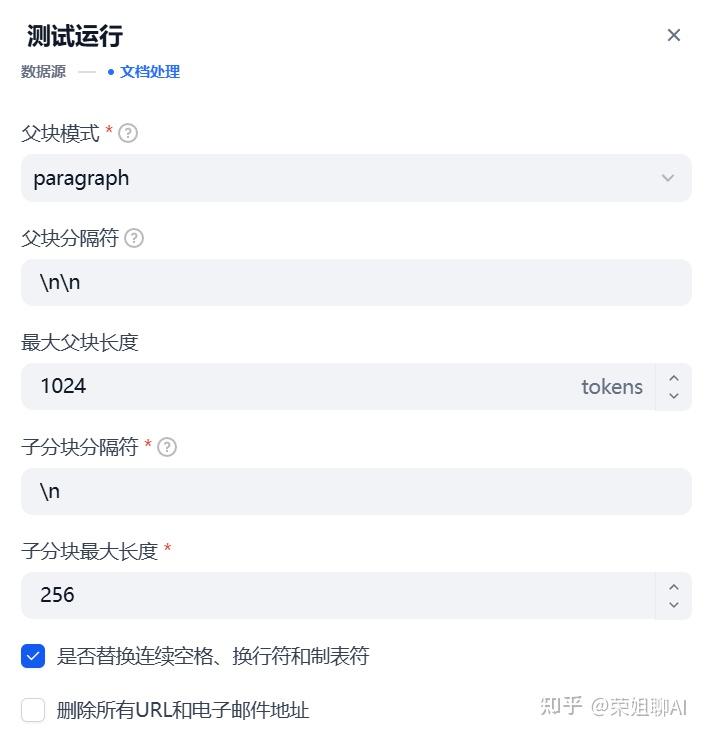
设置父子分块节点的参数:
运行效果:

4 MinerU 介绍及本地部署
官网地址:https://mineru.net/
可以在线使用、申请API接口、下载客户端使用。
更重要的是,支持本地部署。
4.1 在线使用
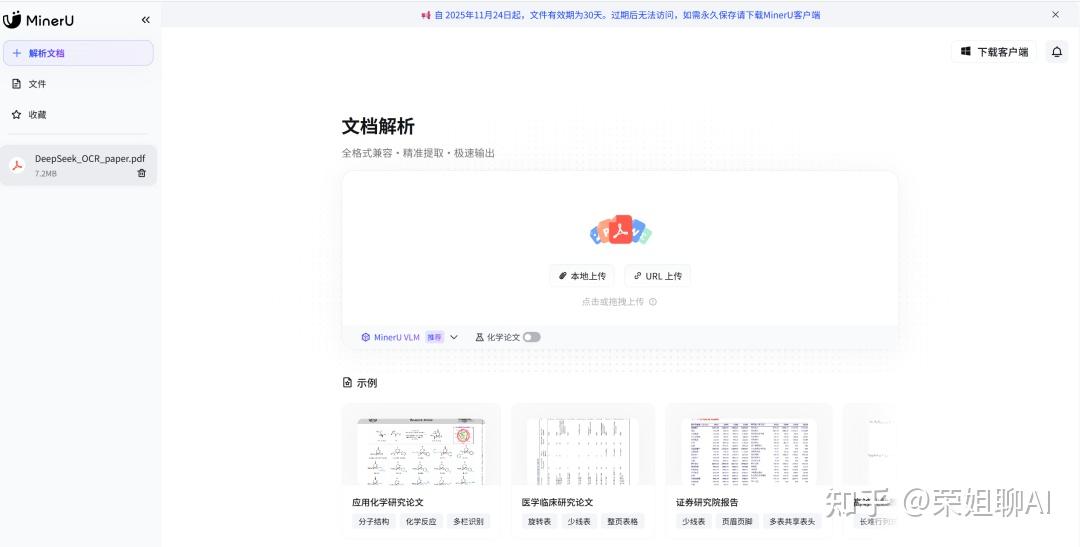
上传PDF文件,可以看到解析成Markdown格式的文档。而且还有个翻译服务,可以自己配置模型进行翻译。
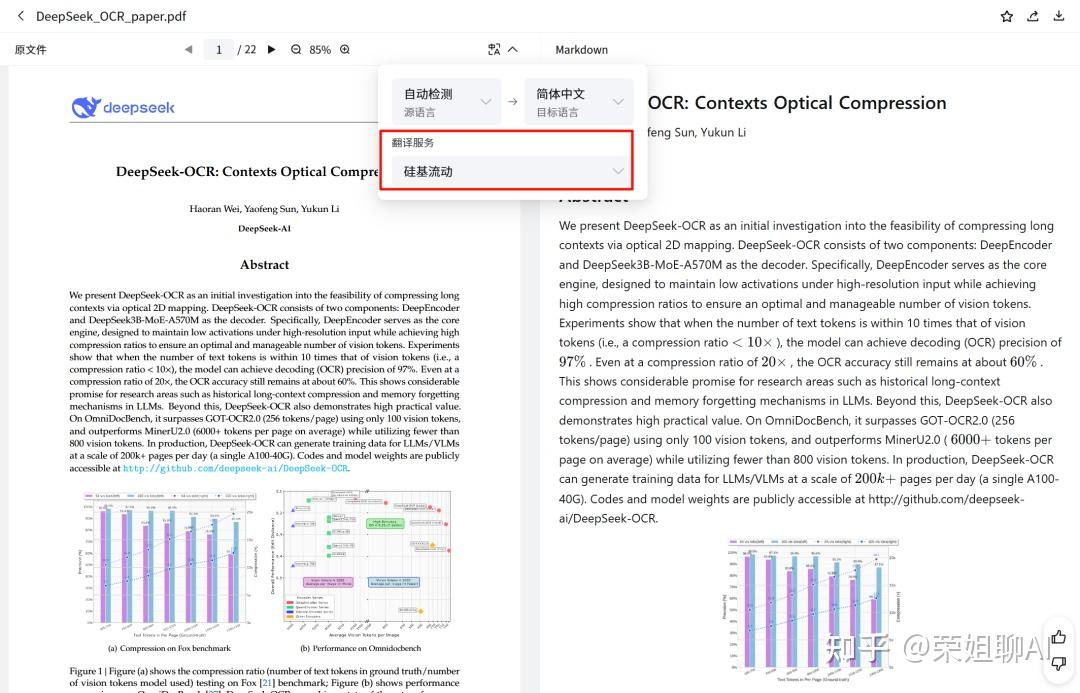
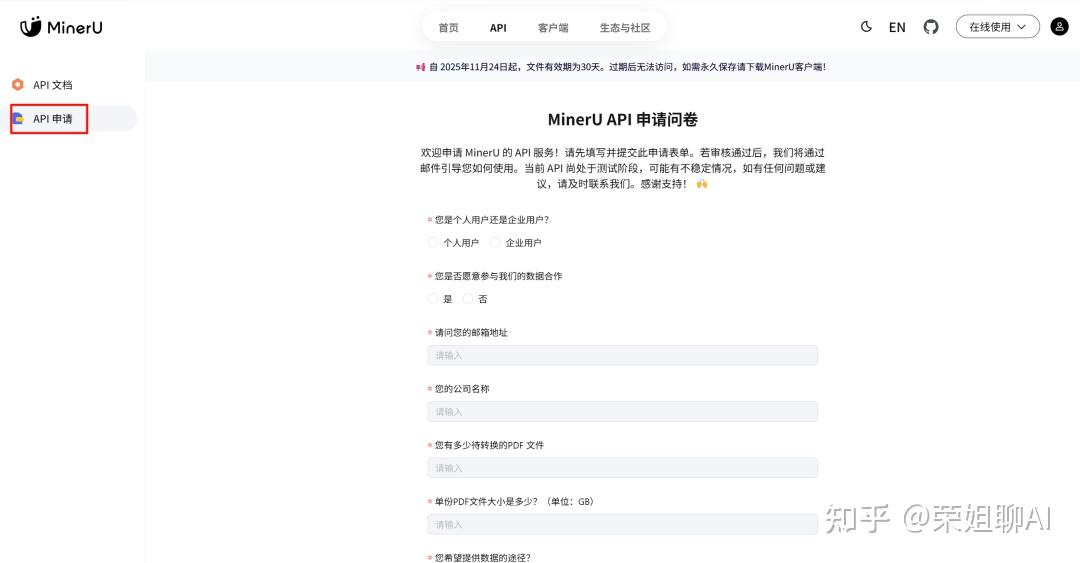
4.2 API申请
可以填写问卷申请API接口。
这个是之前我申请通过的邮件回复,14天有效期,有了这个可以在Dify的插件中填写官方的API了。

4.3 客户端使用
可以下载客户端进行使用。

4.4 本地部署
前面说了那么多,如果想在Dify中使用MinerU,最好的方法还是本地部署。
先看一下对安装MinerU的软硬件环境:

4.4.1 本地部署
1、下载代码
项目地址:https://github.com/opendatalab/MinerU
2、安装MinerU
在代码目录新建一个隔离的虚拟环境
python -m venv .venv激活虚拟环境
D:\MinerU-master>.\.venv\Scripts\activate
安装运行:
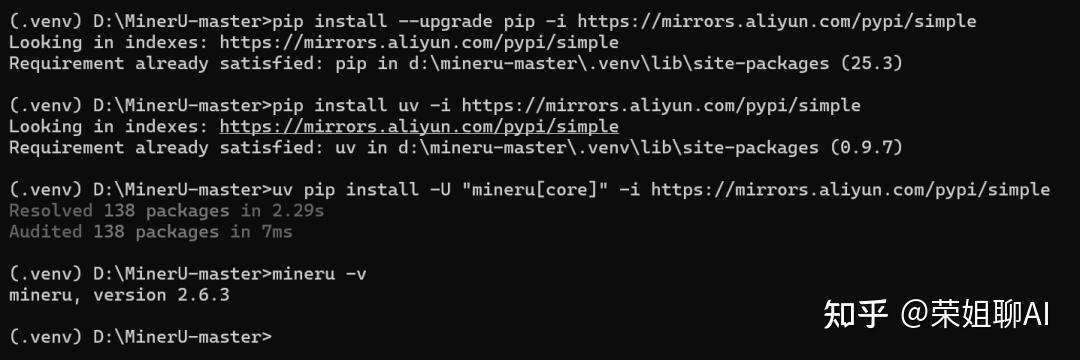
pip install --upgrade pip -i https://mirrors.aliyun.com/pypi/simple
pip install uv -i https://mirrors.aliyun.com/pypi/simple
uv pip install -U "mineru[core]" -i https://mirrors.aliyun.com/pypi/simple 然后输入mineru -v检查一下是否安装成功。
3、启动gradio webui 可视化前端
(.venv) D:\MinerU-master>mineru-gradio --server-name 127.0.0.1 --server-port 7860
4、在浏览器中访问 http://127.0.0.1:7860 使用 Gradio WebUI。
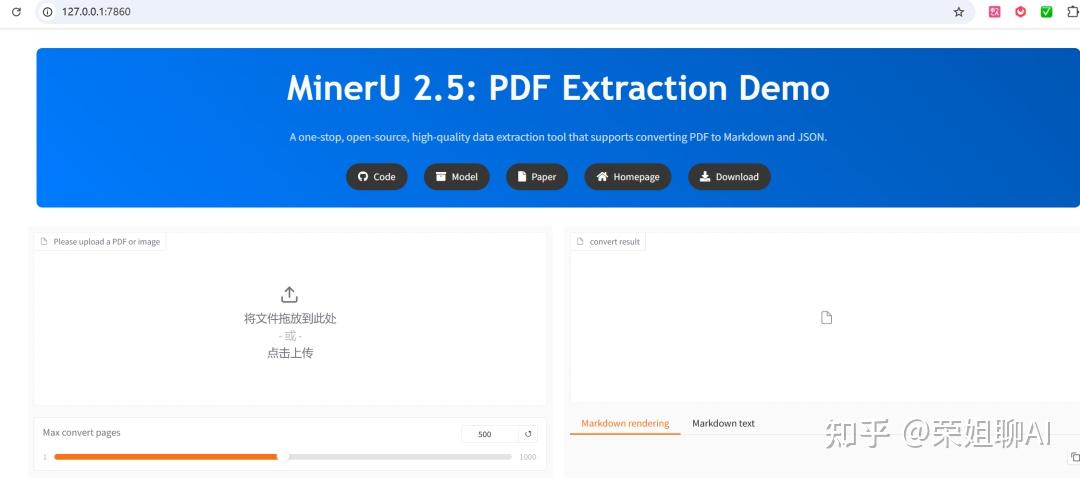
解析后的结果:
4.4.2 启动API服务
开启API服务:
(.venv) D:\MinerU-master>mineru-api --host 127.0.0.1 --port 8000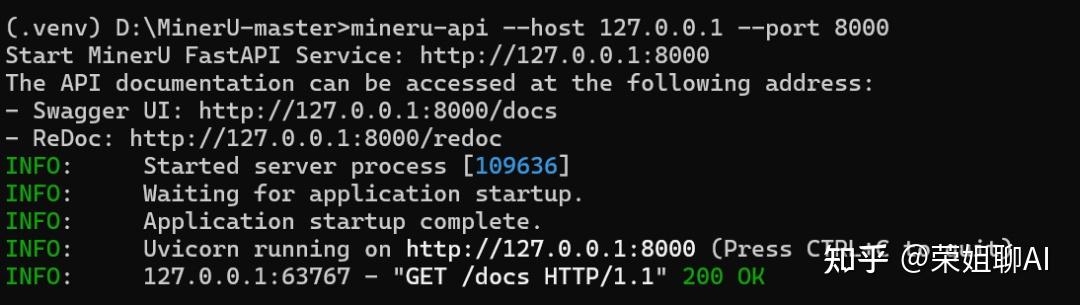
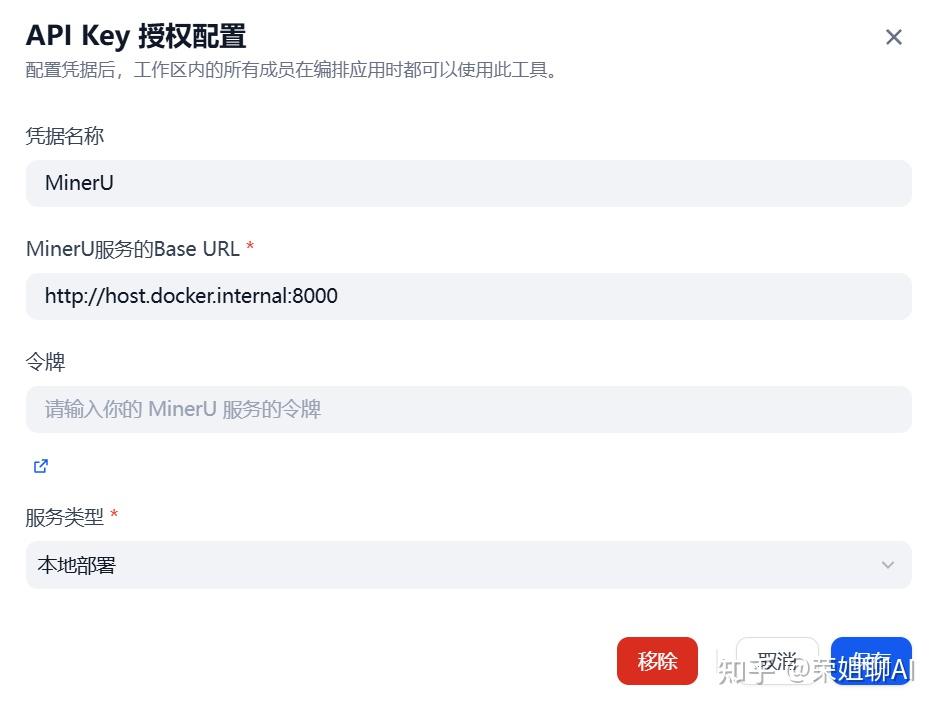
4.4.3 Dify中使用MinerU
在Dify中设置MinerU插件的授权,重点是URL信息:
http://host.docker.internal:8000
部署好后就可以在Dify中调用MinerU的接口了。
新建一个最简单的工作流,开始节点增加一个文件类型的参数,上传PDF文档来验证。
4.5 总结与实践提醒
Dify 的知识流水线为我们提供了极高的灵活性,而 MinerU 插件则是攻克复杂 PDF(如图表、公式)的利器。两者结合,让本地化、自动化的复杂文档处理成为了可能。
最后有个重要的实践提醒:我这次测试是在一台32G内存的Windows办公本上部署的,老实说,解析速度是真的挺慢的!
这说明 MinerU 的本地化方案对硬件还是有一定要求的(毕竟要跑模型)。
如果大家要在实际工作中使用,建议还是配备性能好一点的设备(比如使用官方推荐的GPU环境),以获得更流畅的体验。