Whisper WebUI隐藏功能曝光!多人说话自动区分,真香
作者:AGI罗盘
链接:https://zhuanlan.zhihu.com/p/1969560707201737497
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:https://zhuanlan.zhihu.com/p/1969560707201737497
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
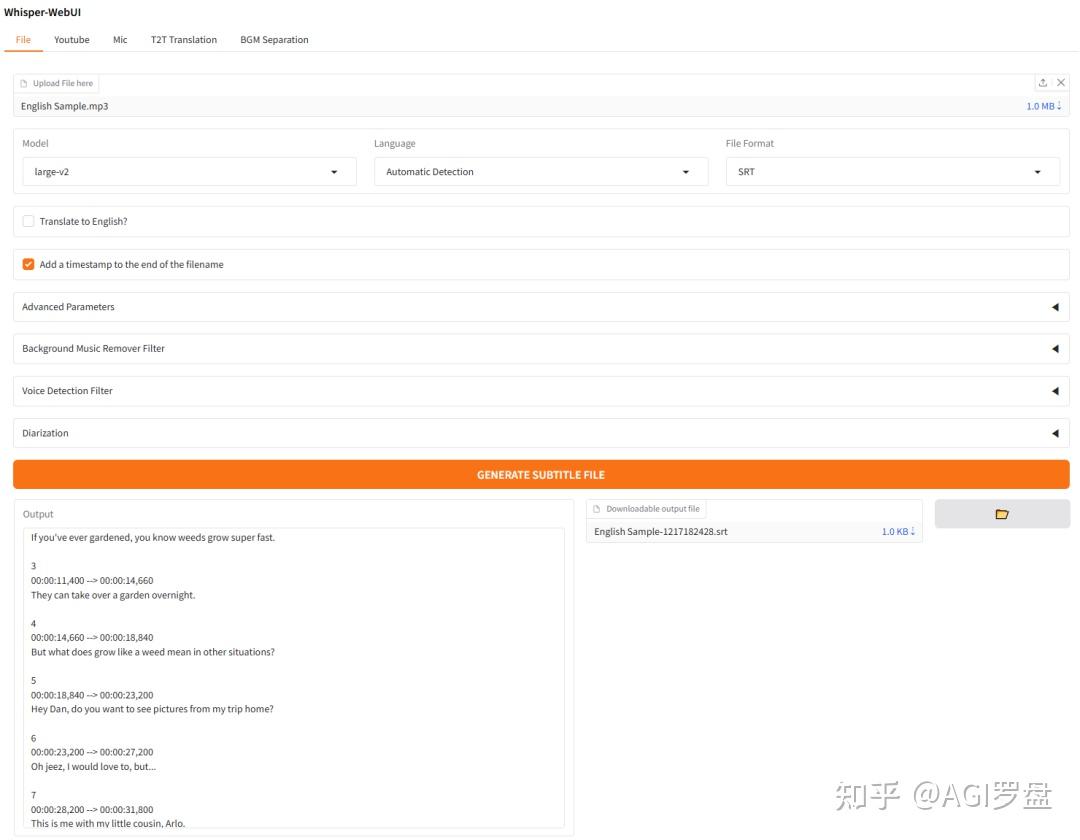
你有需要把录音转成文字的时候吗?要是你有这个需求,可以试试这个叫 Whisper WebUI 的工具。用的时候,你可以设定录音的原始语言,这样识别起来能更准一些。它能把结果变成好几种常用的格式,比如txt、json、srt、vtt这些,后面你想怎么用都挺方便,很容易就能和你手头的工作流程接上轨,操作起来也不费劲。
这个 Whisper WebUI 啊,说白了就是给那个很厉害的语音识别模型Whisper,包上了一层简单好用的网页操作界面。Whisper模型本事不小,能识别足足98种不同的语言。它本身就是为了听懂人说话和做翻译这些任务而训练的。
你用的时候很简单,就把手头的音频文件,像是mp3、wav、flac这些常见的格式,上传上去就行了。不管是开会需要整理个会议记录,做播客想编辑字幕,还是给视频配字幕,它都能帮你把里面的语音快速转成文字,也支持翻译成其他语言。
主要功能
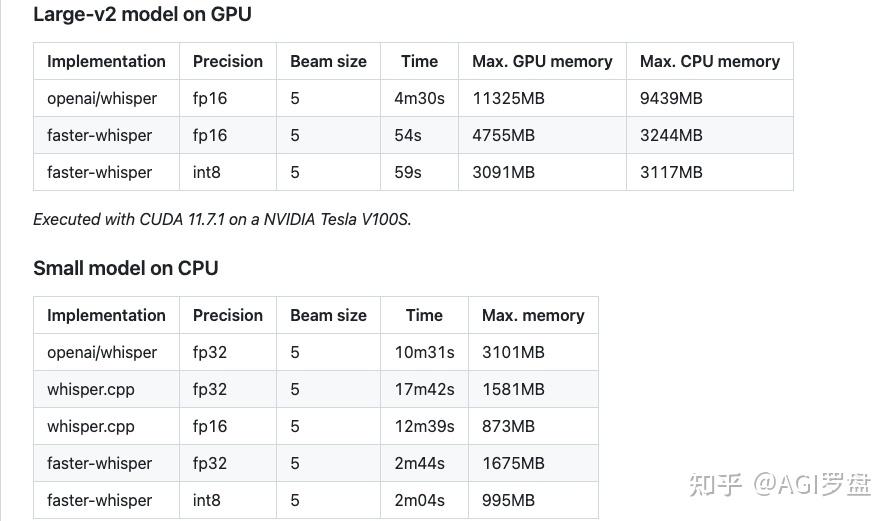
- whisper web不仅集成了官方的OpenAI模型,还支持高效的解决方案,如更快的whisper,在GPU、内存使用和转录速度方面进行了显著的优化。
- 更快耳语的峰值内存从11GB降低到4.7GB,转录速度提高了大约四倍。对于大量的高音量音频来说,这无疑是具有成本效益的。
担心特殊场景下的音频处理效果?
Whisper web通过对多个音频进行预处理和后处理,显著提高转录质量:
- silero VAD,智能语音活动检测,自动分段有效音频剪辑
- UVR精确的背景音乐分离优化了人声的清晰度
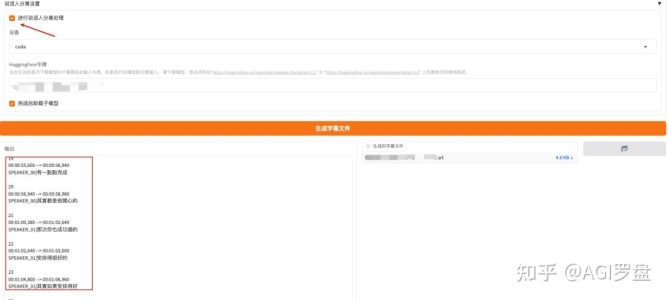
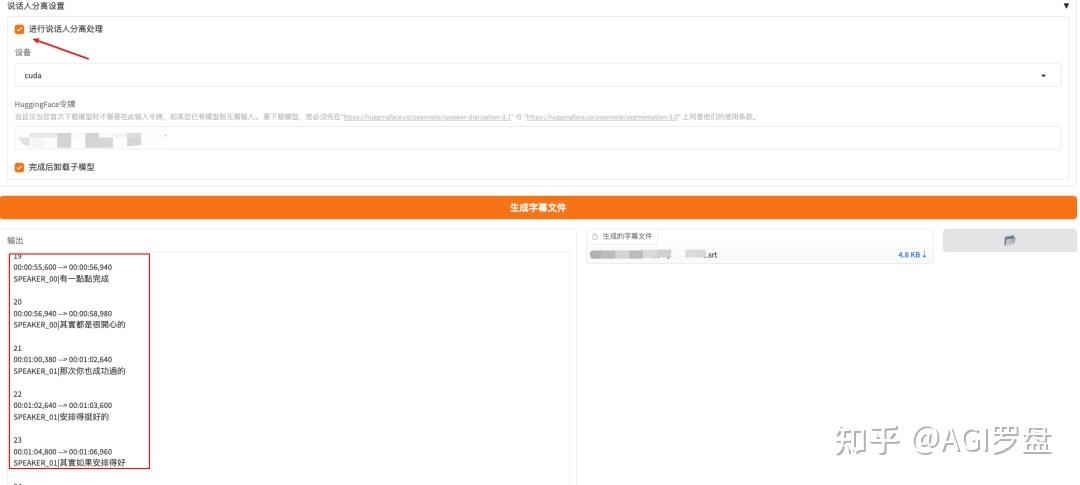
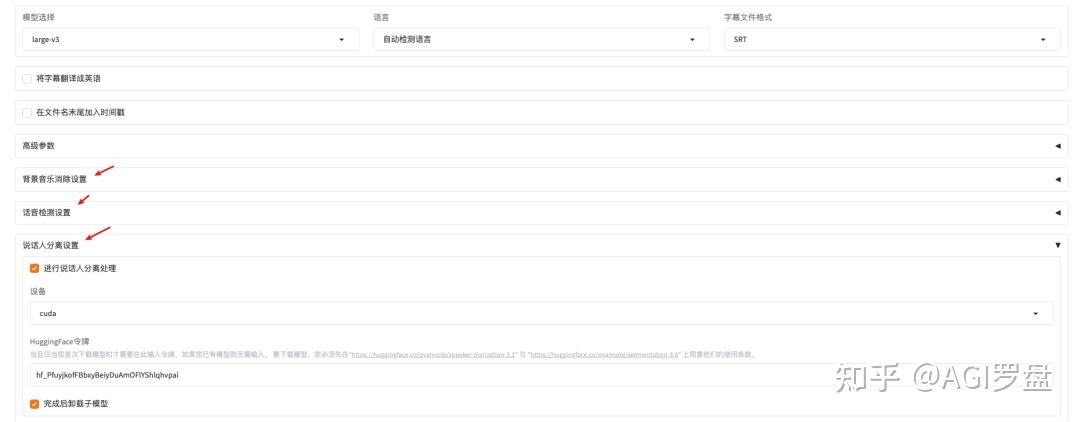
- pyannote的扬声器分离技术,可以轻松区分不同的扬声器
本项目还支持批量音频处理,自动生成字幕文件和压缩包,方便下载和管理。安全放心。API密钥仅存储在本地,并通过HTTPS加密发送
使用在线
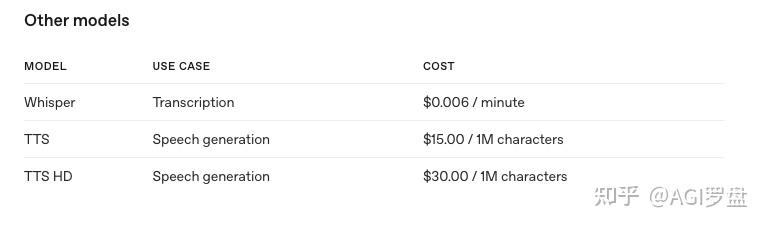
- 使用OpenAI Whisper API会产生成本。现在的账单是每分钟0.006美元。
- 您必须自己注册OpenAI API帐户。所有费用将由OpenAI直接支付。
本地部署
- 本项目兼容Windows、Linux、macOS平台。
- 你只需要安装Python 3.10-3.12。Git和FFmpeg可以根据官方手册启动。
- 如果你想加速,你也可以使用图形处理器,但必须预先设置CUDA环境。
Docker 部署:
git clone https://github.com/jhj0517/Whisper-WebUI.git
docker compose build
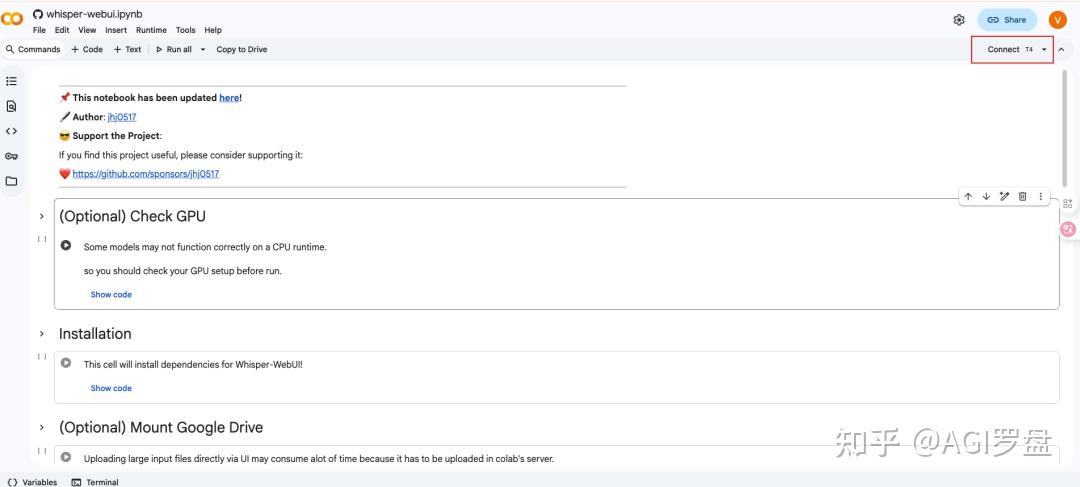
docker compose up也支持 google colab 直接运行,免费试用享用 T4 16 VRAM GPU。
无论您是专注于学术研究、媒体制作,还是为企业客户提供语义解决方案,Whisper于为多语种语音内容的高质量转录和翻译。