全自动内容日报:n8n 喂饭级教程!零门槛做出高颜值资讯卡片


大家好呀,我是 茉茉,一位专注于分享 AI 智能体实战技能的博主。
还在手动抓取 AI 资讯、花时间做日报图?AI 时代,效率才是王道!
传统的内容制作流程太慢、太费力,很多创作者都卡在了 稳定日更 这一步。
解决方案来了! 我做了一套 全自动 AI 日报生成工作流。
这套流程能帮你:自动抓取资讯、代码排版、一键生成精美图片并保存到本地。 整个过程无需人工干预。
今天,茉茉就手把手把这个工具和流程分享给你。跟我一起,把 AI 变成你的专属小编! 咱们开始吧。
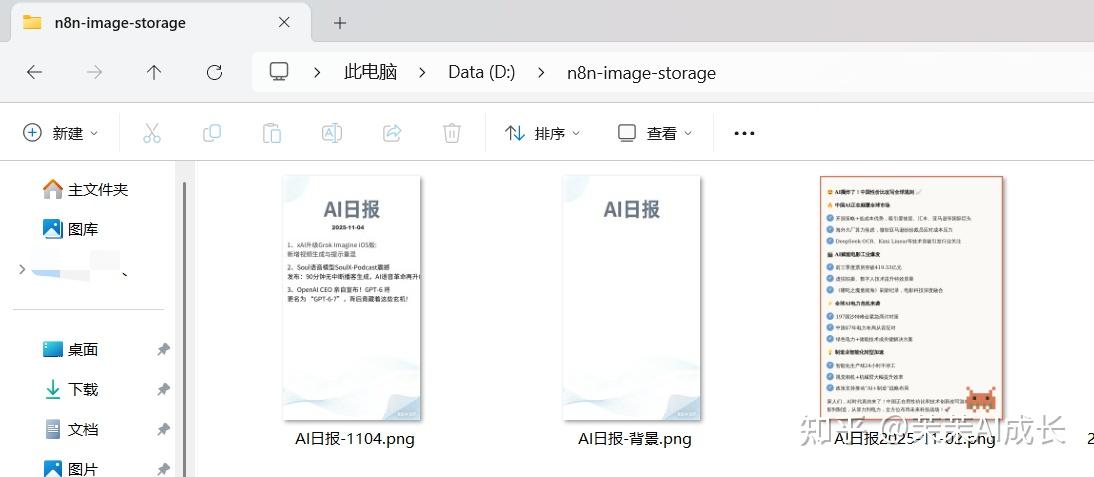
一、效果如图
生成的图片会保存在本地
二、工作流全景
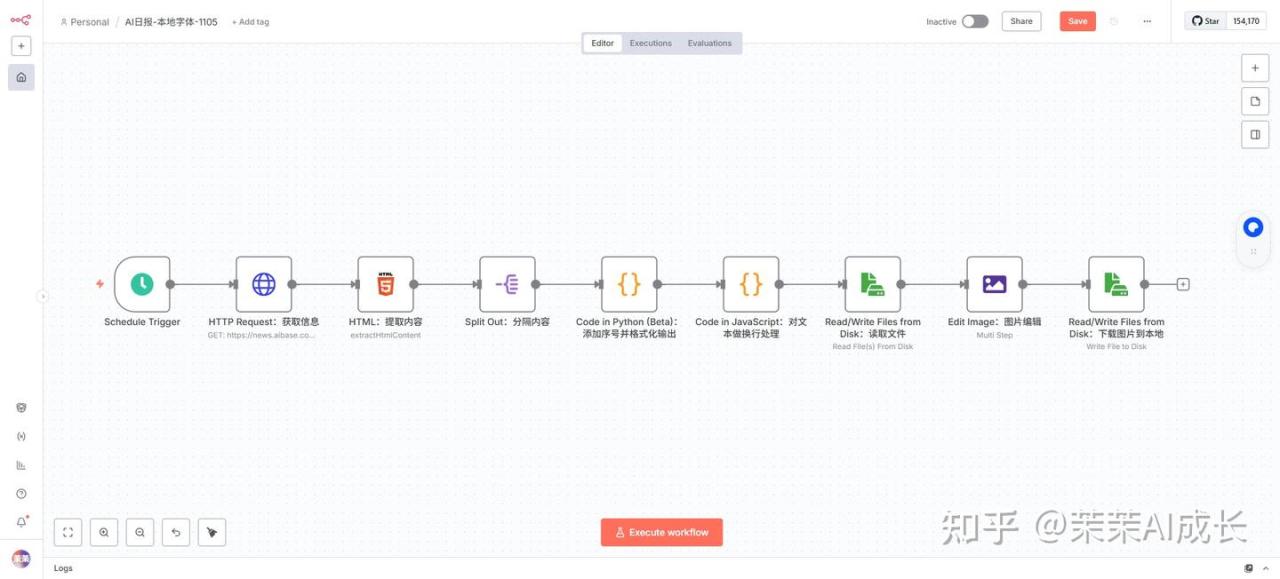
三、工作流拆解(主要节点)
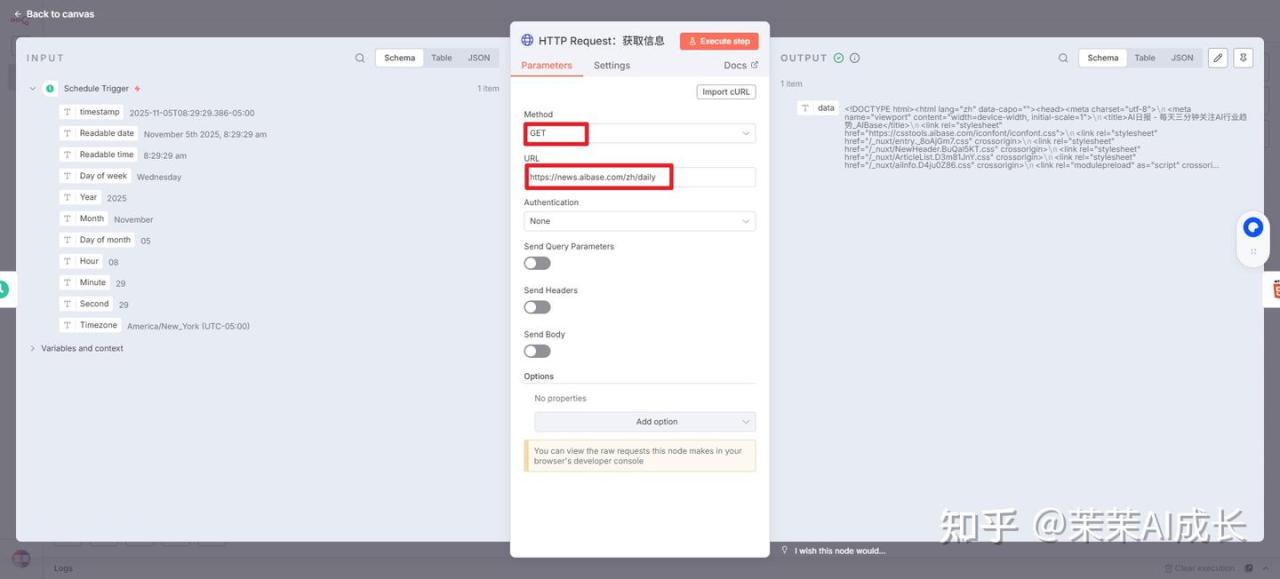
(一)HTTP Request:获取信息
向指定的 URL(网址)发送 HTTP 请求(GET、POST等),并在收到响应后处理返回的数据(例如 HTML 或 JSON)。
url是https://news.aibase.com/zh/daily
https://news.aibase.com/zh/daily是 AIBase 的“AI日报” 栏目,它提供每天只需三分钟就能了解 AI 行业最新趋势、热点新闻、模型发布以及产品更新等深度资讯。
这里返回的是最新的AI行业深度资讯
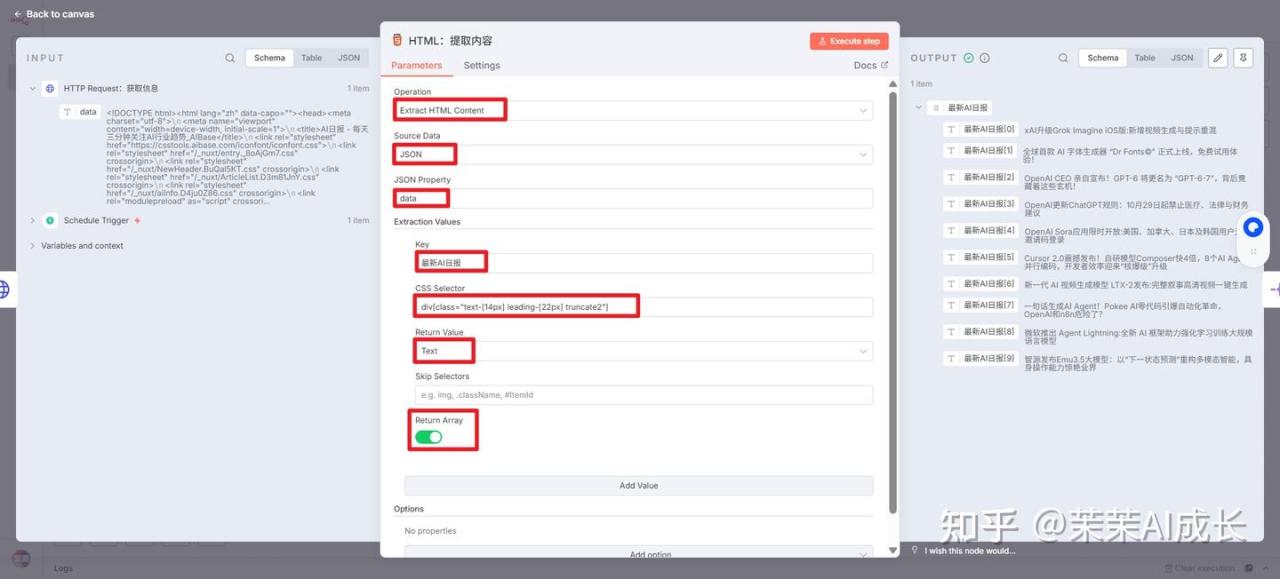
(二)HTML:提取内容
从上一个 HTTP 请求返回的 HTML 源代码中,根据用户指定的 CSS Selector提取出目标内容(例如“昆仑万维”等新闻标题)。
CSS Selector填写的是div[class="text-[14px] leading-[22px] truncate2"]
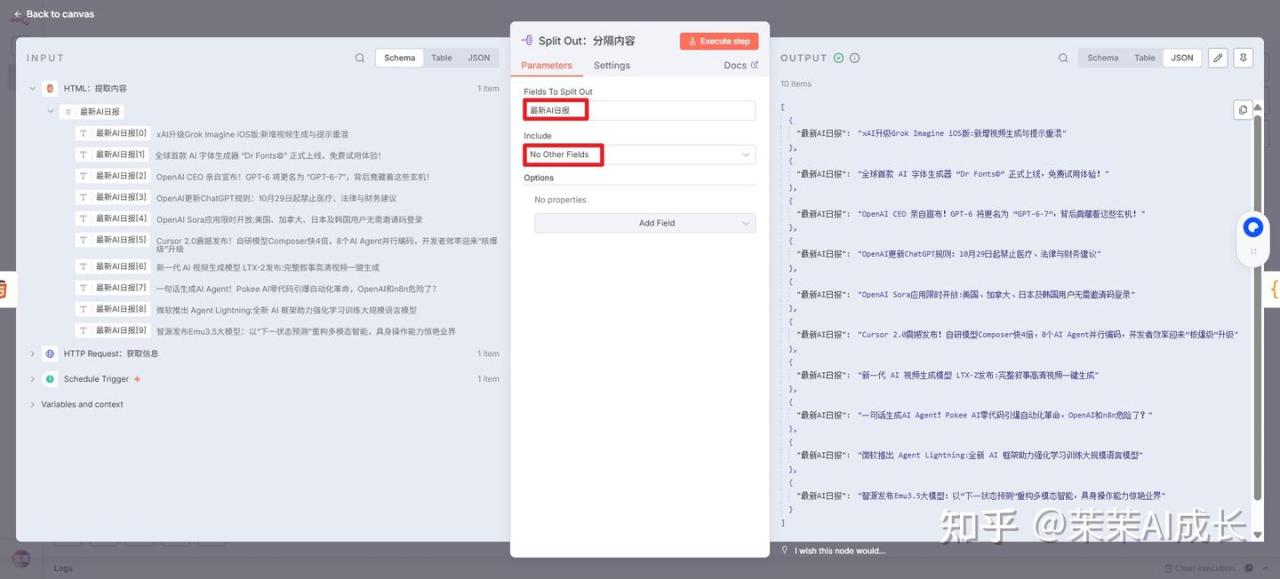
(三)Split Out:分隔内容
将输入数据中的一个字段(本例中是包含多个新闻条目的 最新AI日报 数组)拆分成单独的、多条输出数据,以便后续的节点能对每一条新闻进行独立处理。
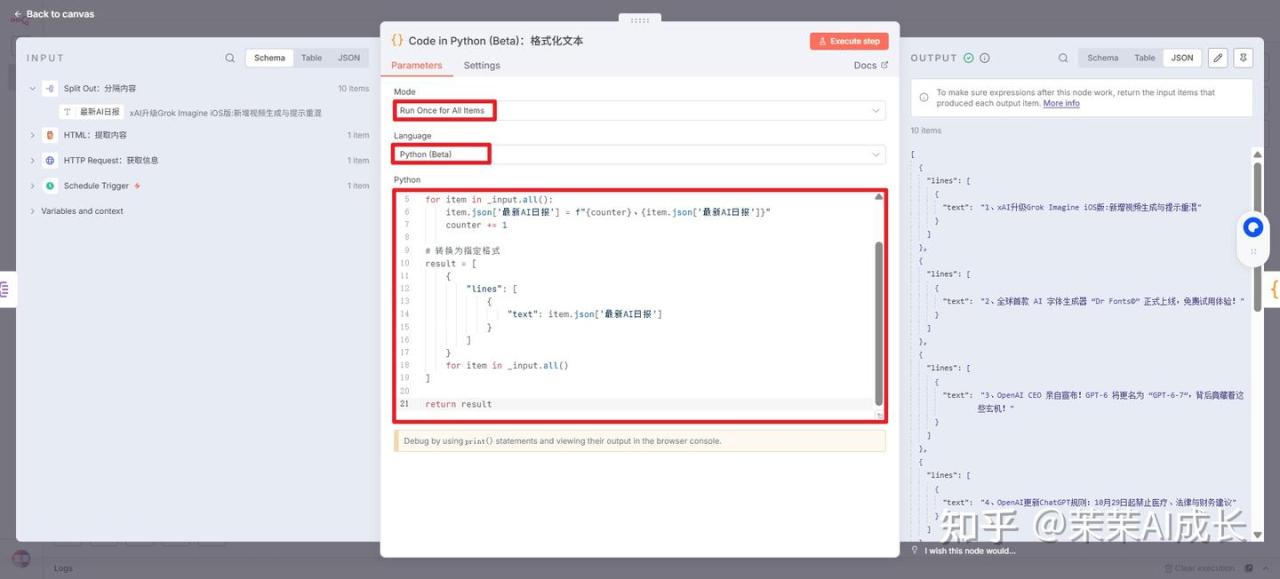
(四)Code in Python (Beta):格式化文本
对输入的每一条“最新AI日报”新闻内容添加序号同时进行格式化处理
# 序号计数器 counter = 1 # Loop over input items and add 序号到 “最新AI日报” 内容的最前面 for item in _input.all(): item.json[‘最新AI日报’] = f”{counter}、{item.json[‘最新AI日报’]}” counter += 1 # 转换为指定格式 result = [ { “lines”: [ { “text”: item.json[‘最新AI日报’] } ] } for item in _input.all() ] return result
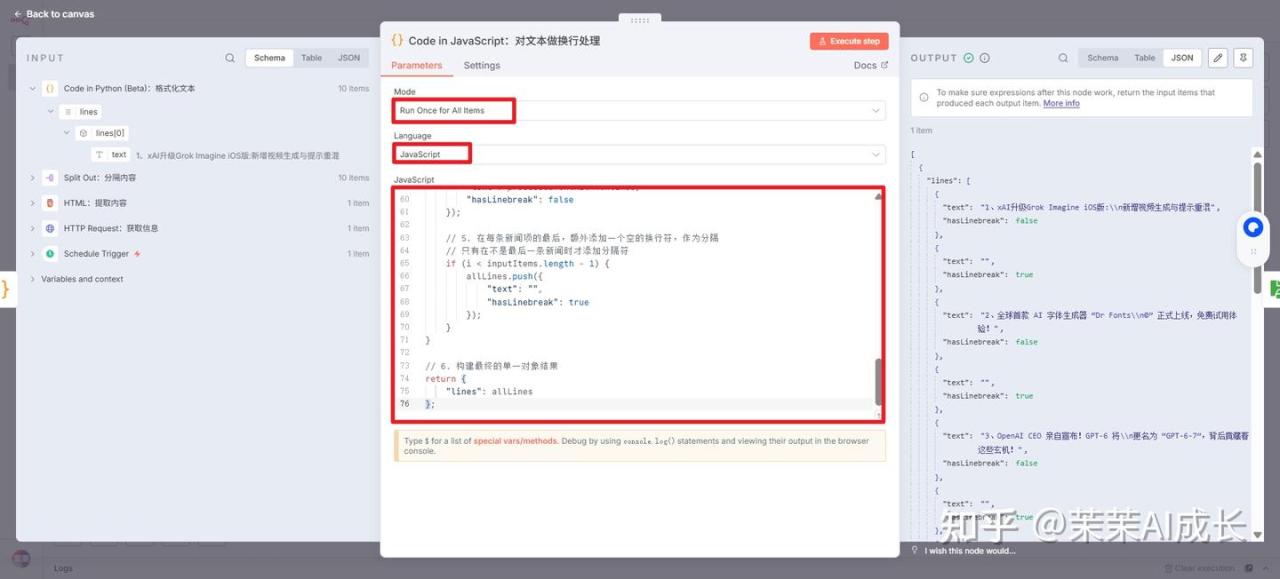
(五)Code in JavaScript:对文本做换行处理
将输入的每条新闻内容进行格式化处理(每行限制在 25 个字符内并插入换行符 \n),然后将所有处理后的新闻项整合成一个单一的 JSON 对象结构,并用空行分隔每条新闻。
// 定义每行最大字符数 const MAX_CHARS = 25; // — 辅助函数:在长字符串中插入 \n 换行符 — function insertNewlines(text, maxChars) { if (!text) return “”; let result = “”; let start = 0; // 循环直到所有文本被处理 while (start < text.length) { let end = start + maxChars; if (end > text.length) { end = text.length; } // 提取当前片段 const segment = text.substring(start, end); result += segment; start = end; // 如果后面还有内容,则插入 \n if (start < text.length) { result += “\\n”; // 注意:这里是双反斜杠,以确保 JSON 字符串中包含字面量的 \n } } return result; } // — 主循环:处理数据并构建最终的单一对象结构 — const allLines = []; const inputItems = $input.all(); // Loop over input items and add a new field called ‘myNewField’ to the JSON of each one for (let i = 0; i < inputItems.length; i++) { const item = inputItems[i]; // 1. 整合您的需求: 添加新字段 ‘myNewField’ item.json.myNewField = 1; // 2. 提取原始文本 let originalText = “”; try { originalText = item.json.lines[0].text; } catch (e) { originalText = “文本提取失败”; } // 3. 在原始文本中插入 \n 换行符 const processedTextWithNewlines = insertNewlines(originalText, MAX_CHARS); // 4. 将处理后的长字符串作为一行添加到结果中 // 确保这行是当前新闻项的最后一行内容,所以 hasLinebreak 设置为 false allLines.push({ “text”: processedTextWithNewlines, “hasLinebreak”: false }); // 5. 在每条新闻项的最后,额外添加一个空的换行符,作为分隔 // 只有在不是最后一条新闻时才添加分隔符 if (i < inputItems.length – 1) { allLines.push({ “text”: “”, “hasLinebreak”: true }); } } // 6. 构建最终的单一对象结果 return { “lines”: allLines };
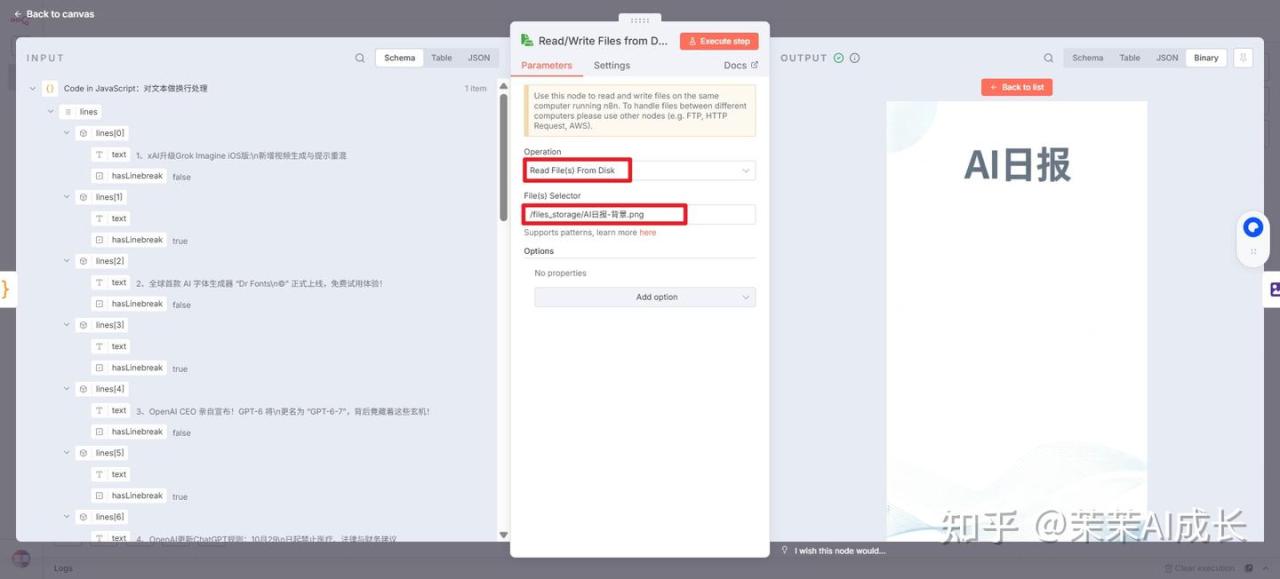
(六)Read/Write Files from Disk:读取文件
从文件系统中指定的路径(/files_storage/AI日报-背景.png)读取一个名为“AI日报-背景.png”的背景图片文件,作为后续流程的数据输入或用于显示。
(七)Edit Image:图片编辑
在从上一个节点获取的图片(“AI日报”背景图)上,以多步骤操作的方式,根据输入的文本内容和日期信息(2025-11-05)进行文本叠加,从而生成最终的新闻日报图片。
Font Name or ID这里想使用中文字体,需要自己挂载一下。
n8n里的画板节点不能直接使用中文字体
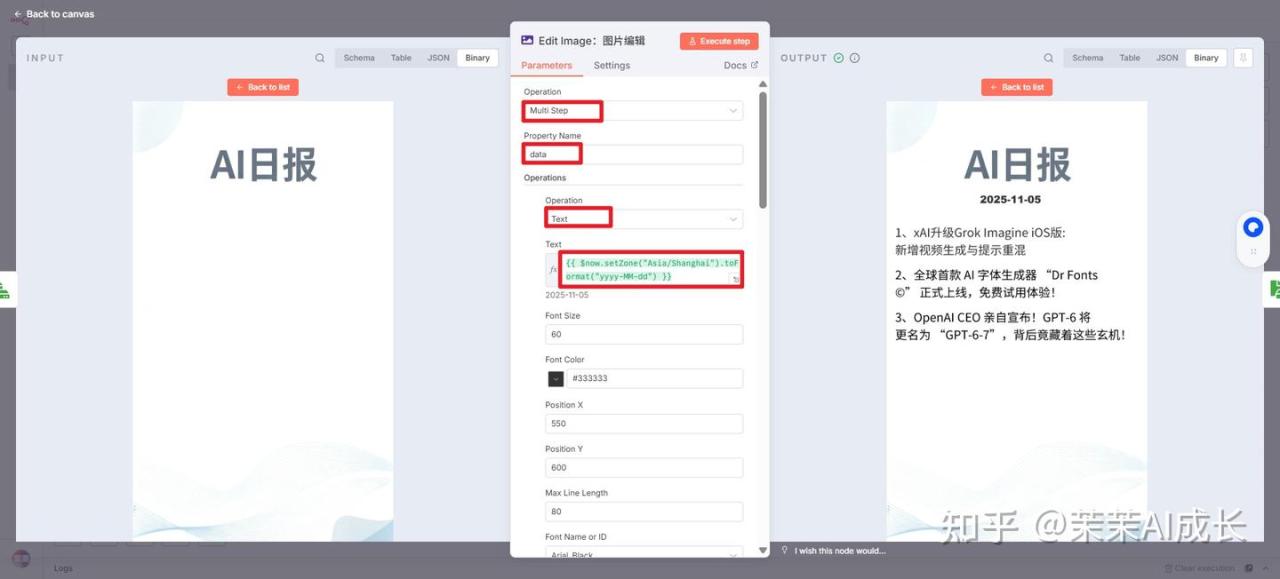
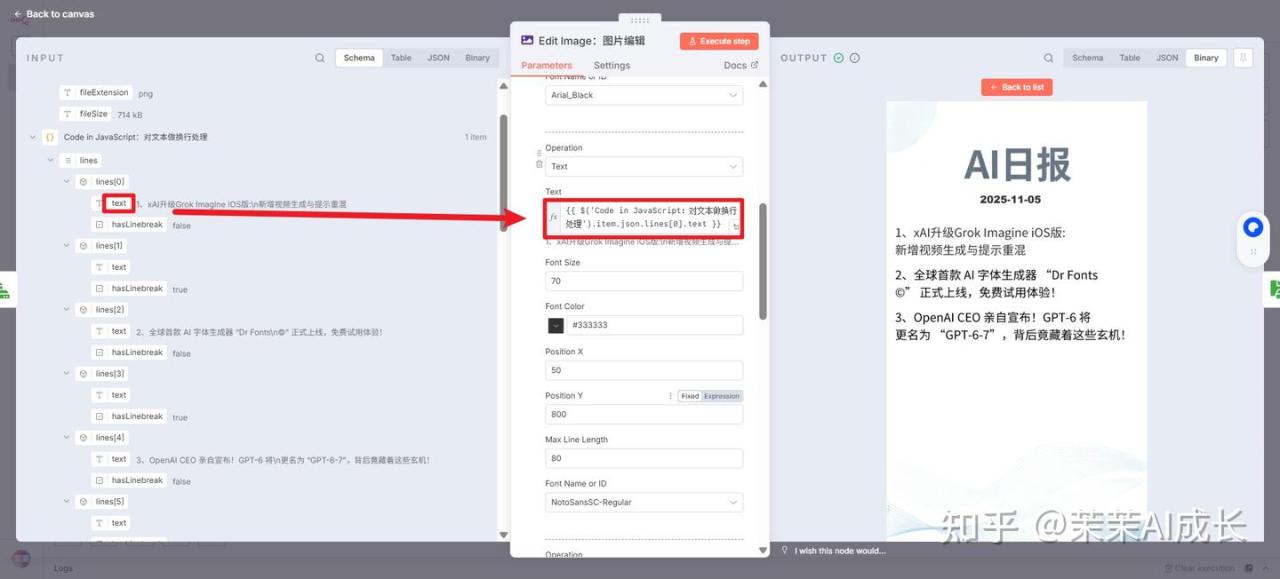
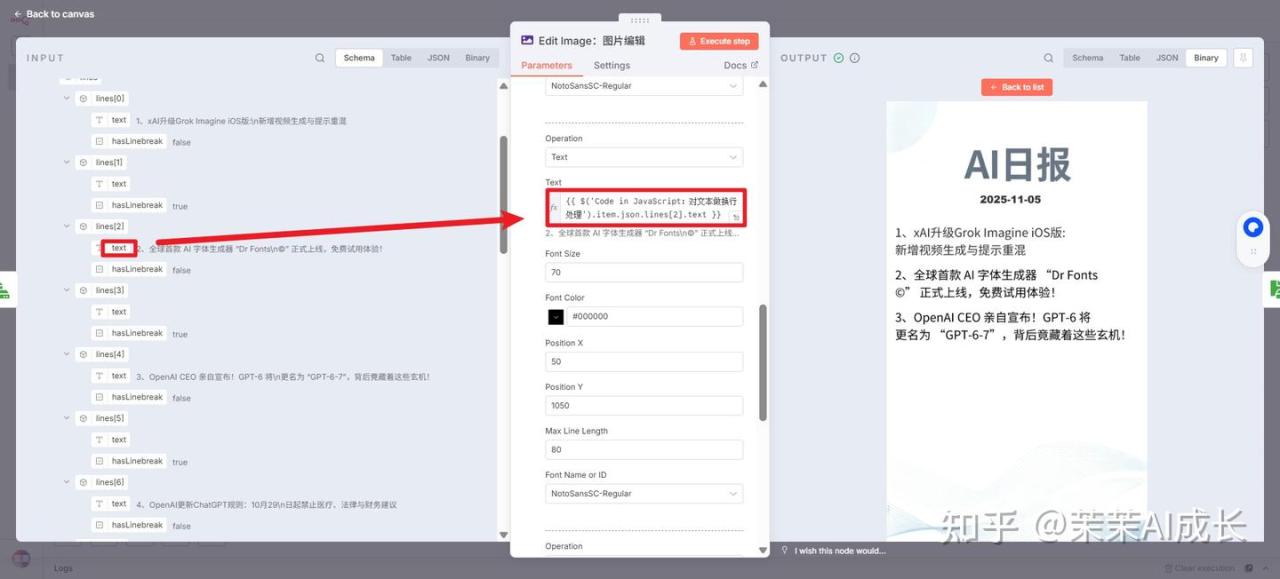
对分隔的文本进行一一设置即可
(八)Read/Write Files from Disk:下载图片到本地
将上一步骤(Edit Image 节点)生成的、带有新闻内容的“AI日报”图片数据,写入到文件系统中的指定路径(/files_storage/AI日报-1104.png)进行保存。
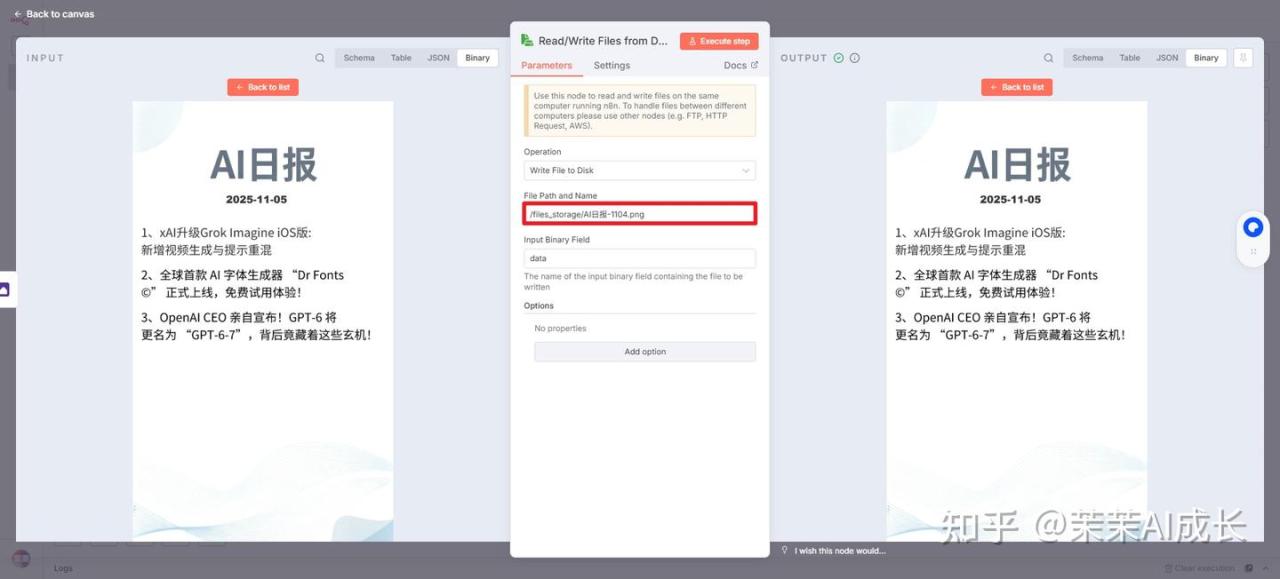
整个工作流就到此结束了,这个工作流里主要是给大家说一下画板节点的使用,n8n里面的画板节点基本都用数字控制,需要用户自己调整的地方比较多,其他节点在之前的文章中基本都提及过。
四、第二种图文卡片制作工作流
大家如果想偷懒的话,可以调用全妙-网络热点信息播报MCP Server收集信息
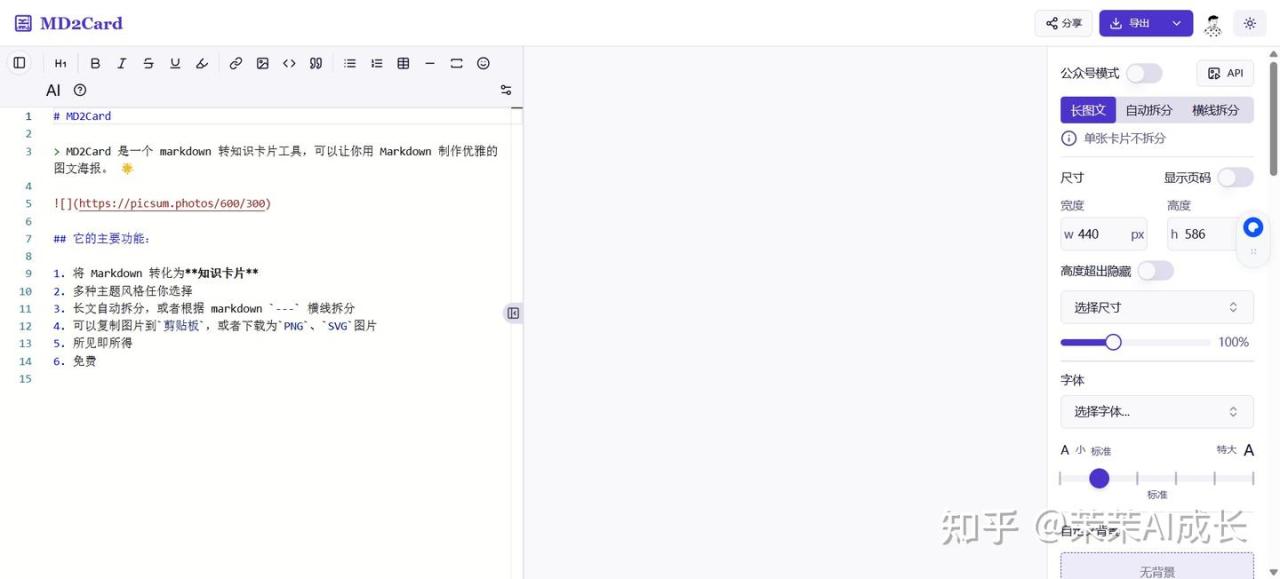
不想投入时间去调试图片坐标和字体的伙伴,可以通过MD2Card 设计自己想要的图片,网址是 https://md2card.cn/zh/editor
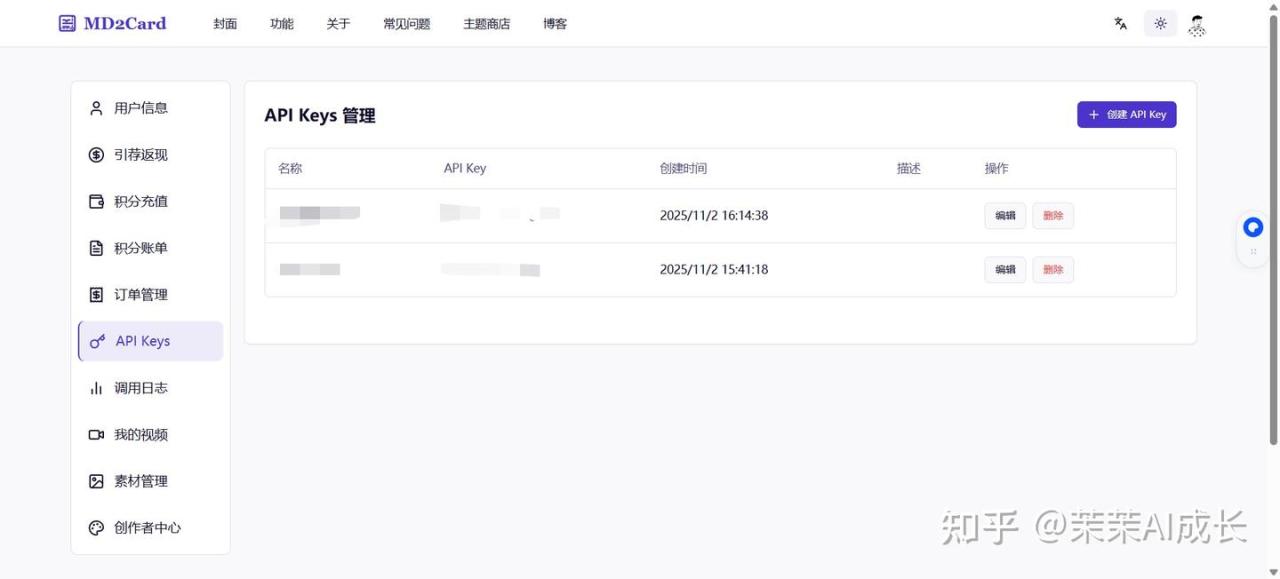
也可以通过api调用来生成图片
这样,你就能用更少的配置,快速实现图文卡片的生成。简单来说,就是用成熟的第三方服务,替代了 n8n 中最耗费精力的“Edit Image”节点。
五、工作流效果

六、工作流全貌
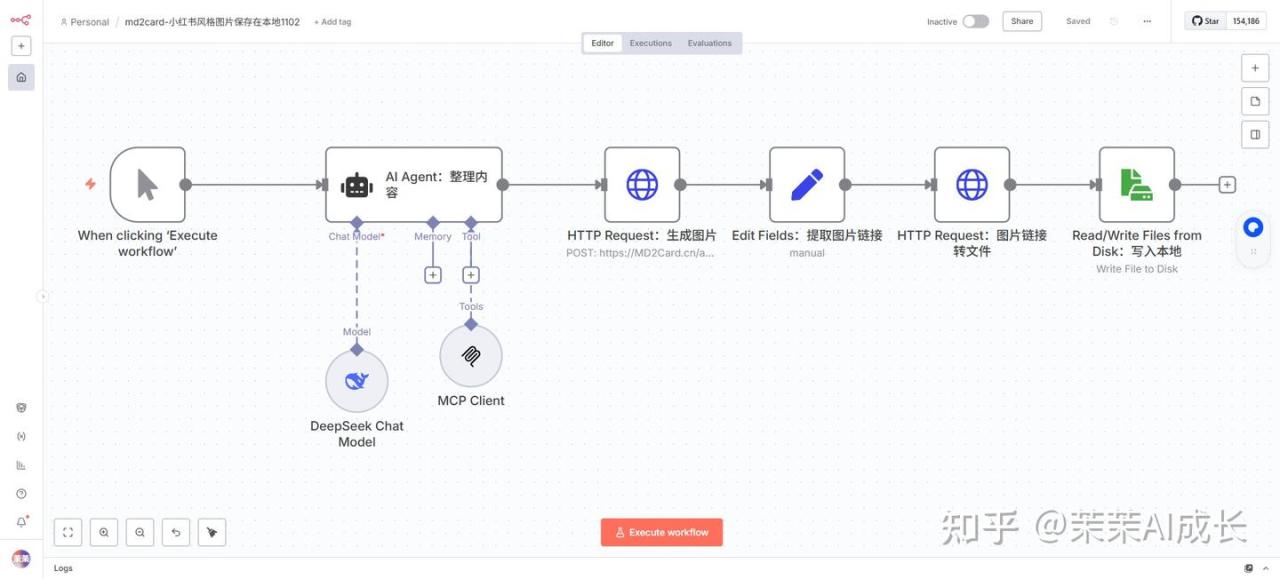
感兴趣的伙伴可以试着搭建一下,如果有想要了解这个工作流的伙伴可以文末找我~