6.1K Star!文档解析神器MonkeyOCR:PDF转Markdown秒级完成,碾压传统OCR工具!
MonkeyOCR是什么
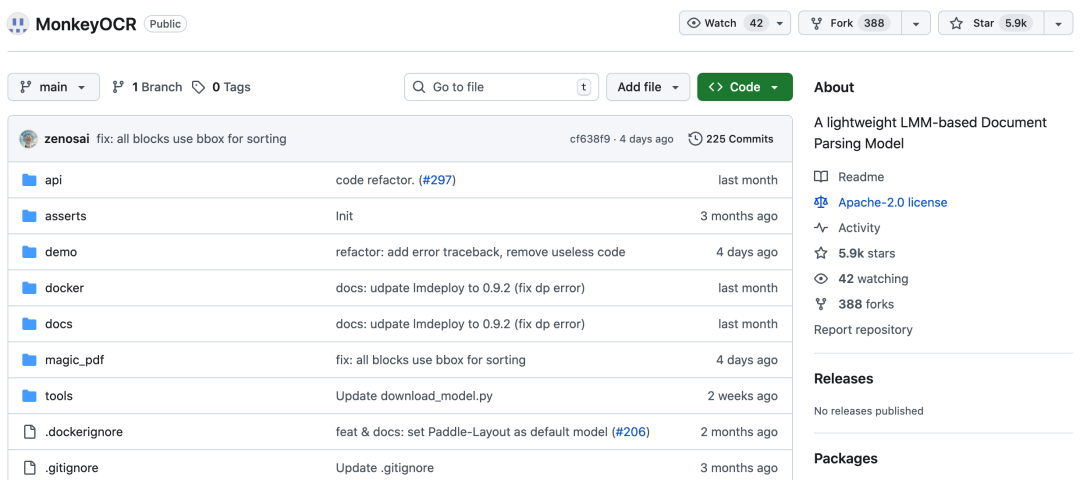
开源成就
•
Star数已经收获6.1K Star,热度持续攀升
•
主开发语言基于Python开发,支持多种部署方式
•
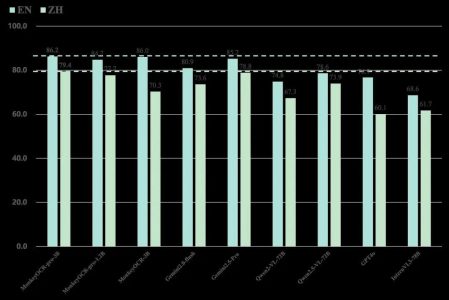
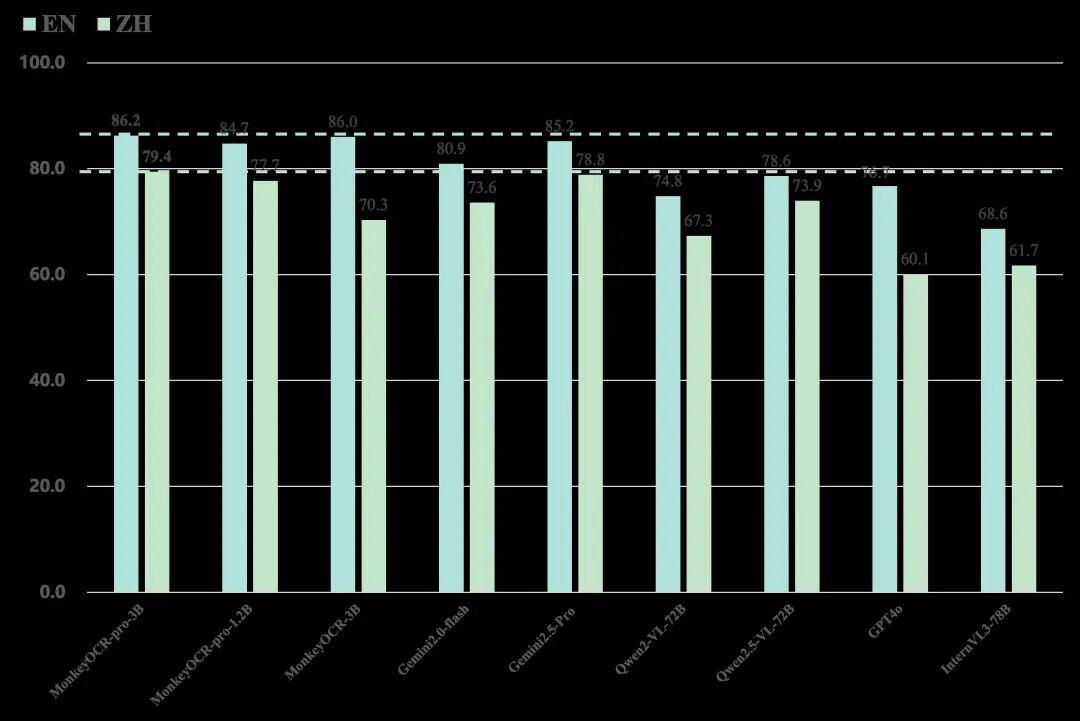
性能碾压在OmniDocBench基准测试中超越GPT-4o、Gemini 2.5-Pro等闭源大模型
核心功能
•
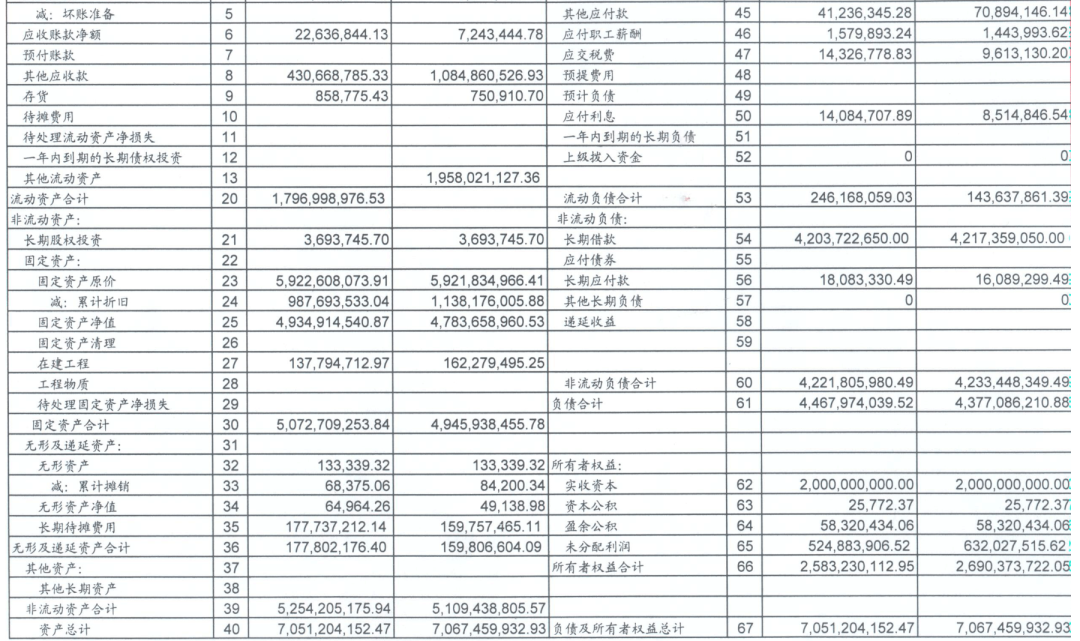
全场景文档解析,支持学术论文、财务报表、新闻报刊等9种PDF页面类型,中英文文档通吃
•
精准的结构识别,公式表格不在话下,我试着上传了几篇带复杂数学公式的论文,识别准确率让人惊喜
•
智能关系预测,不仅能识别内容,还能理解文档结构层级,输出的Markdown保持原文档逻辑关系
•
多种模型规格,提供1.2B、3B两个版本,1.2B版本仅需8GB显存就能运行,普通游戏显卡都能跑起来
•
灵活的部署方式,支持Docker一键部署、本地安装、FastAPI服务等多种方式,还提供了Gradio可视化界面
性能表现
MonkeyOCR-pro-3B在olmOCR-Bench测试中得分75.8,超过了Nanonets OCR、GPT-4o等商业方案,在表格识别任务上准确率高达87.5%,而1.2B轻量版也达到了71.8分,性能损失仅1.6%但速度提升36%
# 端到端文档解析,简单一行命令 python parse.py input_path # 指定解析任务类型 python parse.py input_path-t text/formula/table # 批量处理目录下的PDF并按页拆分结果 python parse.py input_path-s
安装指南
•
Docker部署最省心,官方提供了完整的docker-compose配置,支持Gradio界面和FastAPI服务
# 构建镜像 dockercomposebuildmonkeyocr # 启动Gradio演示界面(7860端口) dockercomposeupmonkeyocr-demo # 启动FastAPI服务(7861端口) dockercomposeupmonkeyocr-api
•
本地安装也很简单,按照官方安装指南配置好环境后,用huggingface或modelscope下载模型权重即可
# 下载MonkeyOCR-pro-3B模型 python tools/download_model.py-n MonkeyOCR-pro-3B # 或下载1.2B轻量版 python tools/download_model.py-n MonkeyOCR-pro-1.2B
•
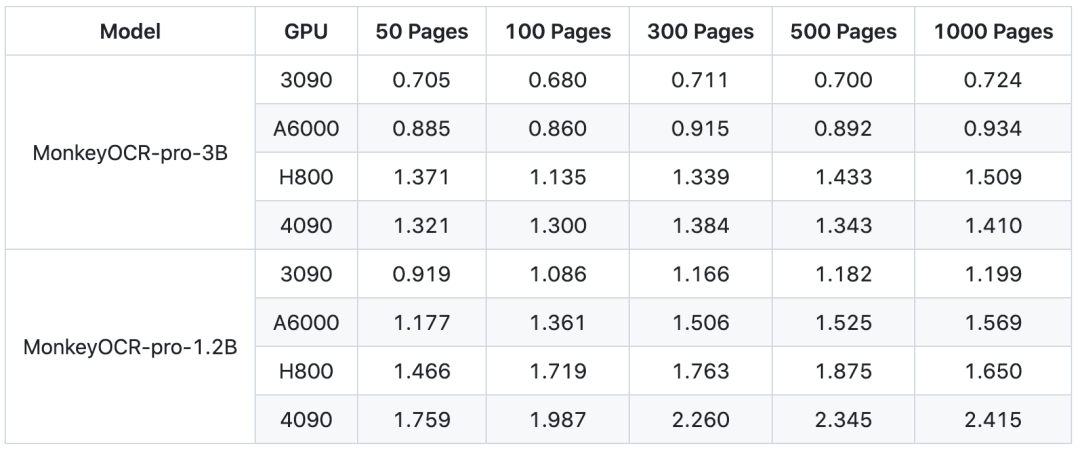
硬件要求友好,测试过的GPU包括3090、4090、A6000、V100甚至4060 8GB显存都能运行量化后的模型,对个人用户很友好
•
支持量化部署,通过AWQ量化技术可以进一步降低显存占用,官方提供了完整的量化教程
用MonkeyOCR处理了几十份技术文档和学术论文,转换出来的Markdown格式工整规范,公式表格都保留完好,特别是那些带复杂排版的财务报表,以前要手动整理半天,现在几秒钟就搞定了,虽然需要一定的技术门槛来部署,但对于经常处理文档的开发者和研究人员来说,这个工具绝对是效率神器,在文档解析这个细分领域,MonkeyOCR已经做到了开源天花板
项目图片
END 往期推荐
-
14.5K Star!开源AI编程助手,专为大型项目和复杂任务而生!
-
407K Star!GitHub上最全的精选资源库,程序员必备的技术宝库!
-
18.5K Star!AI浏览器自动化神器,告别繁琐的网页操作!
-
13.7K Star!Google官方AI代理开发神器,多智能体系统开发效率翻倍!
-
8.7K Star!不用GPU也能搞语音合成,推荐这个25MB的语音合成神器,从App到嵌入式,从Web到桌面软件,哪里都能用