利用开源项目 TrendRadar 打造一个属于自己的 “今日热榜”


摘要
在信息爆炸的时代,如何从众多 APP 和海量信息中精准获取有价值的内容,成为每个人面临的挑战。TrendRadar 作为一个开源的热点新闻聚合分析系统,通过智能化的技术手段,为用户提供了一个高效、个性化的新闻获取解决方案。本文将从技术架构、核心功能、实现原理等多个维度,全面解析这个值得关注的开源项目。
1. 项目概述
TrendRadar 是一个基于 Python 开发的热点新闻聚合与智能分析系统,支持从多个主流平台抓取热点新闻,并通过自定义关键词进行智能筛选和推送。项目采用 GitHub Actions 自动化运行,支持多种通知渠道,具备零技术门槛部署的特点。

1.1 核心特性
- 全网热点聚合:集成知乎、微博、抖音、百度热搜等 11+ 主流平台
- 智能内容筛选:支持普通词、必须词(+)、过滤词(!)三种语法
- 多推送模式:当日汇总、当前榜单、增量监控三种运行模式
- 多渠道通知:支持企业微信、飞书、钉钉、Telegram、邮件等推送渠道
- 热点趋势分析:基于权重算法的新闻热度排序与趋势追踪
- AI 智能分析:基于 MCP 协议的对话式分析功能(v3.0.0 新增)
1.2 效果演示
GitHub Actions 一键部署:
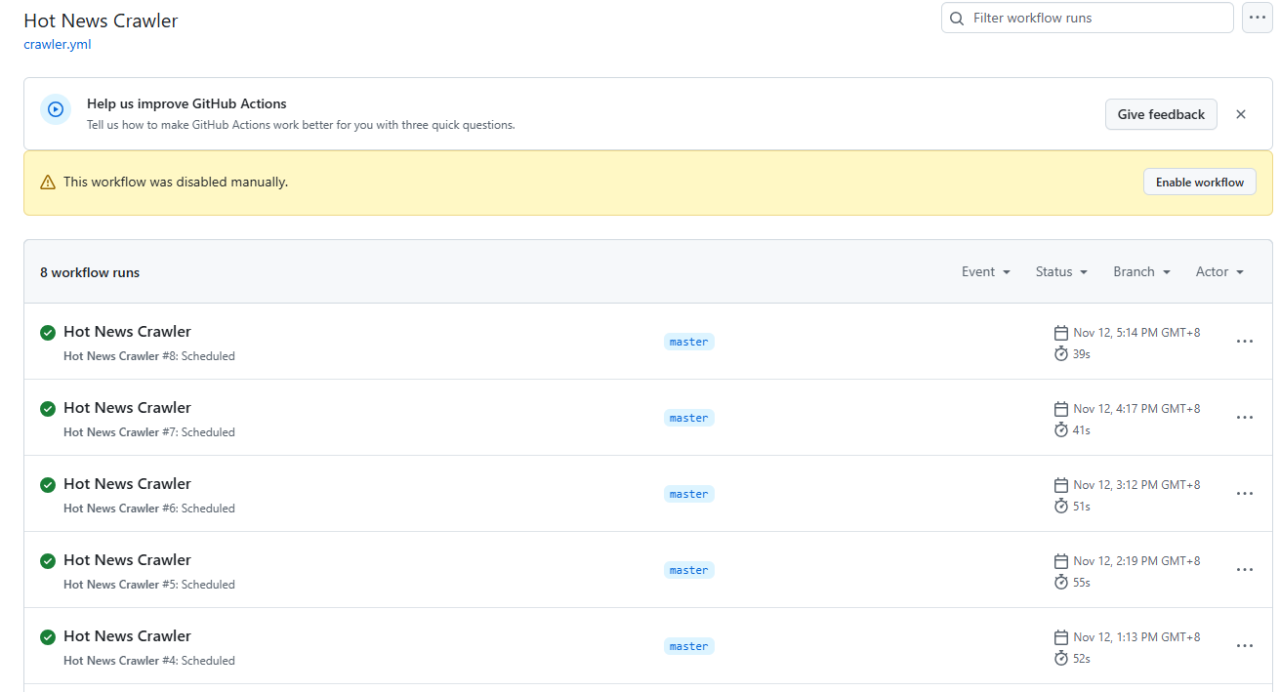
H5页面生成:
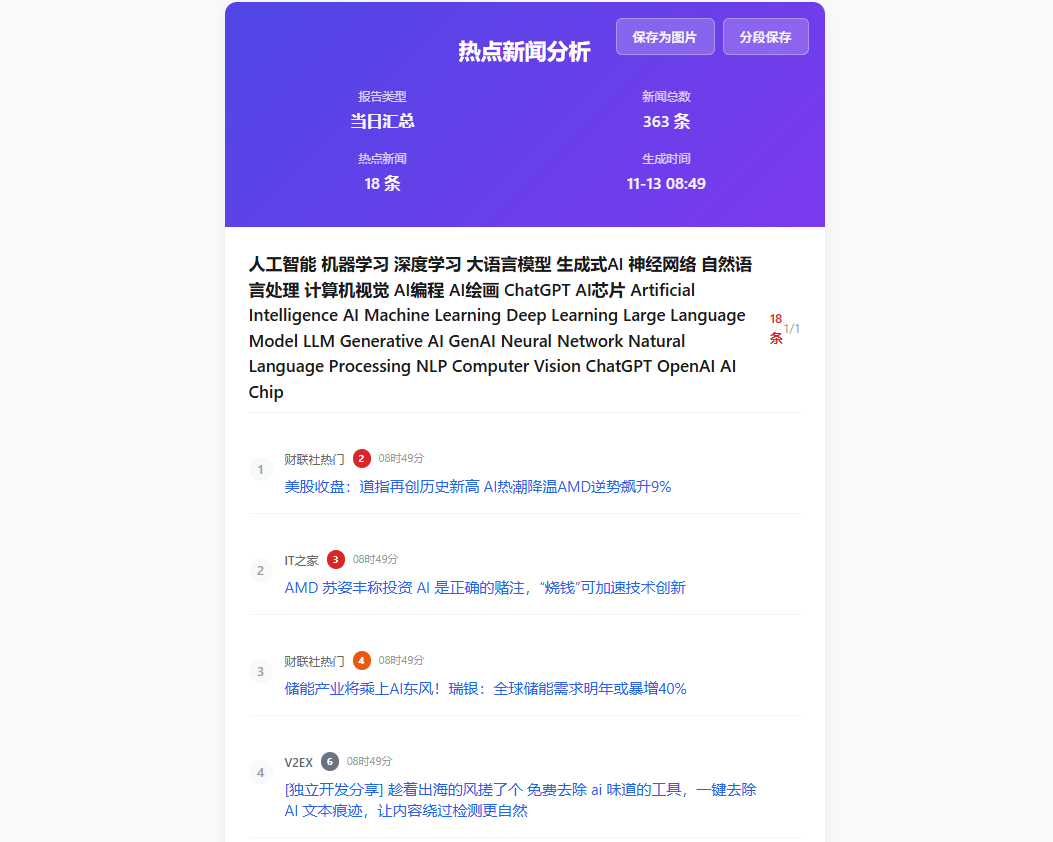
内容推送:
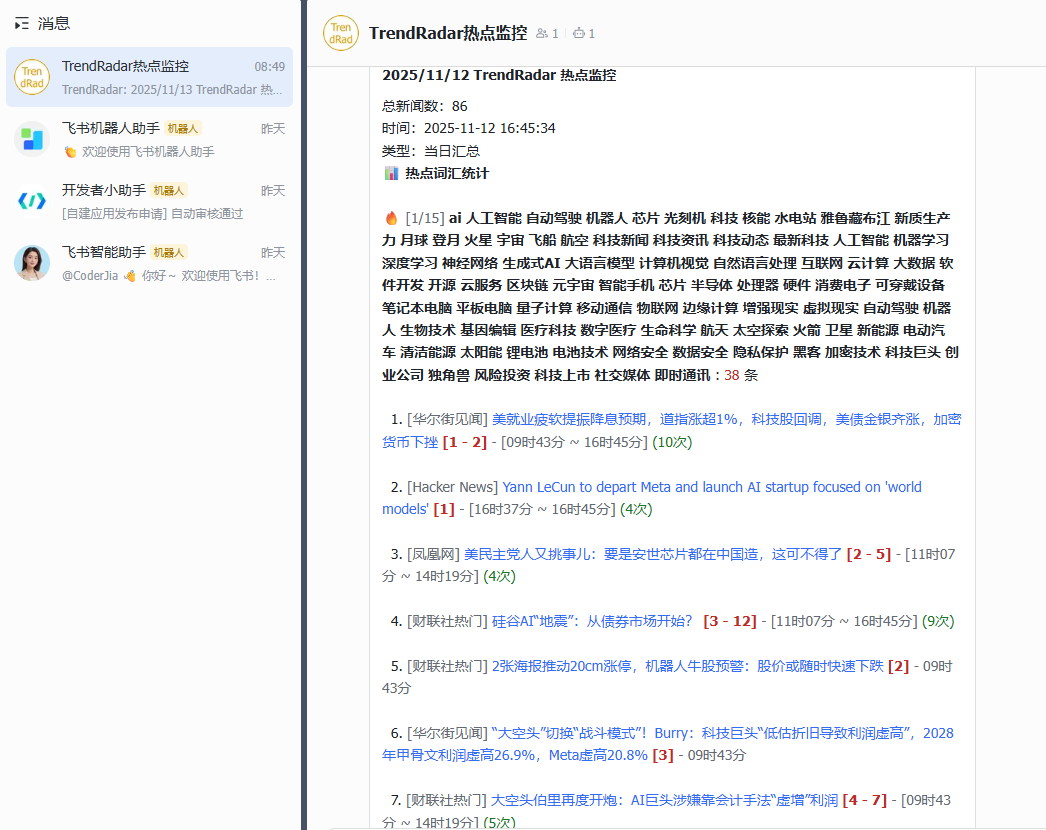
2. 技术架构分析
2.1 系统架构
TrendRadar 采用单体应用架构,所有功能集中在 main.py 文件中,这种设计便于用户快速部署和升级。系统整体架构可以分为以下几个核心模块:
TrendRadar/
├── 配置管理模块 (config/*.yaml, config/frequency_words.txt)
├── 数据获取模块 (DataFetcher)
├── 数据处理模块 (数据解析、统计分析)
├── 报告生成模块 (HTML/Markdown 生成)
├── 通知推送模块 (多渠道适配器)
├── AI 分析模块 (MCP 服务器)
└── 自动化部署 (GitHub Actions)2.2 核心技术栈
| 技术领域 | 使用技术 | 说明 |
|---|---|---|
| 开发语言 | Python 3.x | 主要编程语言 |
| 配置管理 | YAML | 配置文件格式,支持复杂配置结构 |
| 网络请求 | requests | HTTP 客户端库,支持代理和重试机制 |
| 数据处理 | pytz | 时区处理,支持北京时间标准化 |
| 通知服务 | Webhook API | 支持企业微信、飞书、钉钉等多种平台 |
| AI 协议 | MCP (Model Context Protocol) | 标准化的 AI 工具调用协议 |
| 部署平台 | GitHub Actions | 自动化运行和版本管理 |
3. 核心功能实现解析
3.1 数据获取引擎
系统核心的数据获取功能通过 DataFetcher 类实现:
class DataFetcher:
def __init__(self, proxy_url: Optional[str] = None):
self.proxy_url = proxy_url
def fetch_data(self, id_info: Union[str, Tuple[str, str]]) -> Tuple[Optional[str], str, str]:
"""获取指定ID数据,支持重试"""
url = f"https://newsnow.busiyi.world/api/s?id={id_value}&latest"
# 代理支持、重试机制、错误处理
proxies = {"http": proxy_url, "https": proxy_url} if self.proxy_url else None
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36",
"Accept": "application/json, text/plain, */*",
}
# 带重试的数据获取逻辑
response = requests.get(url, proxies=proxies, headers=headers, timeout=10)
return response.text, id_value, alias
技术亮点:
- 统一数据源:基于 newsnow 项目的 API,简化了多平台适配的复杂性
- 异常处理:内置重试机制,提高数据获取的成功率
- 代理支持:支持 HTTP 代理,适配不同网络环境
3.2 智能关键词匹配系统
TrendRadar 的核心优势在于其灵活的关键词匹配系统:
def matches_word_groups(title: str, word_groups: List[Dict], filter_words: List[str]) -> bool:
"""检查标题是否匹配词组规则"""
title_lower = title.lower()
# 1. 过滤词检查(优先级最高)
if any(filter_word.lower() in title_lower for filter_word in filter_words):
return False
# 2. 词组匹配检查
for group in word_groups:
required_words = group["required"] # 必须词(+)
normal_words = group["normal"] # 普通词
# 必须词检查:所有必须词都必须包含
if required_words:
all_required_present = all(
req_word.lower() in title_lower for req_word in required_words
)
if not all_required_present:
continue
# 普通词检查:包含任意一个即可
if normal_words:
any_normal_present = any(
normal_word.lower() in title_lower for normal_word in normal_words
)
if not any_normal_present:
continue
return True
return False
匹配规则:
- 普通词:标题包含任意一个即匹配
- 必须词(+):标题必须同时包含所有必须词
- 过滤词(!):包含过滤词直接排除,优先级最高
- 词组管理:通过空行分隔不同词组,独立统计分析
3.3 热度权重算法
系统采用智能权重算法重新排序新闻热点,突破各平台算法限制:
def calculate_news_weight(title_data: Dict, rank_threshold: int = CONFIG["RANK_THRESHOLD"]) -> float:
"""计算新闻权重,用于排序"""
ranks = title_data.get("ranks", [])
count = title_data.get("count", len(ranks))
weight_config = CONFIG["WEIGHT_CONFIG"]
# 排名权重:Σ(11 - min(rank, 10)) / 出现次数
rank_scores = [11 - min(rank, 10) for rank in ranks]
rank_weight = sum(rank_scores) / len(ranks) if ranks else 0
# 频次权重:min(出现次数, 10) × 10
frequency_weight = min(count, 10) * 10
# 热度加成:高排名次数 / 总出现次数 × 100
high_rank_count = sum(1 for rank in ranks if rank <= rank_threshold)
hotness_ratio = high_rank_count / len(ranks) if ranks else 0
hotness_weight = hotness_ratio * 100
# 综合权重计算
total_weight = (
rank_weight * weight_config["RANK_WEIGHT"] + # 排名权重 60%
frequency_weight * weight_config["FREQUENCY_WEIGHT"] + # 频次权重 30%
hotness_weight * weight_config["HOTNESS_WEIGHT"] # 热度权重 10%
)
return total_weight
算法特点:
- 排名导向:排名越低(排名数字越小)的新闻权重越高
- 持续性奖励:重复出现的新闻获得更高权重
- 热点加成:高排名新闻的持续出现获得额外奖励
- 可调节性:权重配置可通过配置文件动态调整
4. 运行模式解析
TrendRadar 提供三种不同的运行模式,适应不同用户需求:
4.1 当日汇总模式 (daily)
report:
mode: "daily" # 当日汇总模式
特点:
- 推送时机:按时推送(默认每小时)
- 显示内容:当日所有匹配新闻 + 新增新闻区域
- 适用场景:日报总结、全面了解当日热点趋势
4.2 当前榜单模式 (current)
特点:
- 推送时机:按时推送(默认每小时)
- 显示内容:当前榜单匹配新闻 + 新增新闻区域
- 适用场景:实时热点追踪、了解当前最火的内容
技术实现:
if mode == "current":
# 加载完整的历史数据
analysis_data = self._load_analysis_data()
# 只处理 last_time 等于最新时间的新闻
for source_id, source_titles in results.items():
filtered_titles = {}
for title, title_data in source_titles.items():
if title_info[source_id][title]["last_time"] == latest_time:
filtered_titles[title] = title_data
4.3 增量监控模式 (incremental)
特点:
- 推送时机:有新增才推送,无新增时静默
- 显示内容:新出现的匹配频率词新闻
- 适用场景:避免重复信息干扰,高频监控场景
增量检测逻辑:
def detect_latest_new_titles(current_platform_ids: Optional[List[str]] = None) -> Dict:
"""检测当日最新批次的新增标题"""
# 解析最新文件
latest_file = files[-1]
latest_titles = parse_file_titles(latest_file)
# 汇总历史标题
historical_titles = set()
for file_path in files[:-1]:
historical_data = parse_file_titles(file_path)
for source_id, titles_data in historical_data.items():
for title in titles_data.keys():
historical_titles.add(title)
# 找出新增标题
new_titles = {}
for source_id, latest_source_titles in latest_titles.items():
source_new_titles = {}
for title in latest_source_titles.keys():
if title not in historical_set:
source_new_titles[title] = latest_source_titles[title]
5. 通知推送架构
5.1 多通道支持
TrendRadar 支持 6+ 种通知渠道,采用适配器模式设计:
def send_to_notifications(stats: List[Dict], report_data: Dict,
report_type: str, update_info: Optional[Dict] = None,
proxy_url: Optional[str] = None) -> Dict[str, bool]:
"""多渠道统一推送接口"""
results = {}
# 各平台调用
if feishu_url:
results["feishu"] = send_to_feishu(feishu_url, report_data, report_type)
if dingtalk_url:
results["dingtalk"] = send_to_dingtalk(dingtalk_url, report_data, report_type)
if telegram_token and telegram_chat_id:
results["telegram"] = send_to_telegram(
telegram_token, telegram_chat_id, report_data, report_type
)
# ... 其他平台
return results
5.2 消息分批处理
针对不同平台的推送限制,实现了智能分批功能:
def split_content_into_batches(report_data: Dict, format_type: str,
update_info: Optional[Dict] = None,
max_bytes: int = None) -> List[str]:
"""分批处理消息内容,确保词组标题+至少第一条新闻的完整性"""
# 确保词组标题+第一条新闻的原子性
for word_group in report_data["stats"]:
word_header = f"🔥 {word_group['word']} : {word_group['count']} 条"
first_news = word_group["titles"][0]
# 检查词组标题+第一条新闻是否超出限制
test_content = current_batch + word_header + first_news
if len(test_content.encode("utf-8")) >= max_bytes:
# 开启新批次
batches.append(current_batch)
current_batch = word_header + first_news
# 继续添加剩余新闻
for news in word_group["titles"][1:]:
if current_batch_can_fit(news):
current_batch += news
else:
batches.append(current_batch)
current_batch = news
6. AI 智能分析模块 (v3.0.0 新增)
6.1 MCP 协议集成
TrendRadar v3.0.0 引入了基于 Model Context Protocol (MCP) 的 AI 分析功能:
# 创建 FastMCP 2.0 应用
mcp = FastMCP('trendradar-news')
# 全局工具实例(在第一次请求时初始化)
_tools_instances = {}
def _get_tools(project_root: Optional[str] = None):
"""获取或创建工具实例(单例模式)"""
if not _tools_instances:
_tools_instances['data'] = DataQueryTools(project_root)
_tools_instances['analytics'] = AnalyticsTools(project_root)
_tools_instances['search'] = SearchTools(project_root)
_tools_instances['config'] = ConfigManagementTools(project_root)
_tools_instances['system'] = SystemManagementTools(project_root)
return _tools_instances
# ==================== 数据查询工具 ====================
@mcp.tool
async def get_latest_news(
platforms: Optional[List[str]] = None,
limit: int = 50,
include_url: bool = False
) -> str:
6.2 AI 分析工具集
系统提供了 13 种智能分析工具,分为四大类别:
基础查询工具:
get_latest_news– 获取最新新闻get_news_by_date– 按日期查询新闻get_trending_topics– 获取热点话题
智能检索工具:
search_news– 智能搜索新闻search_related_news_history– 历史关联新闻检索
高级分析工具:
analyze_topic_trend– 话题趋势分析analyze_data_insights– 数据洞察分析analyze_sentiment– 情感分析find_similar_news– 相似新闻查找generate_summary_report– 摘要报告生成
系统管理工具:
get_current_config– 获取当前配置get_system_status– 系统状态检查trigger_crawl– 手动触发爬取
6.3 自然语言分析能力
用户可以通过自然语言与系统对话:
# 示例对话场景
[
"查询今天热搜前10条新闻",
"分析'人工智能'这个话题最近一周的热度趋势",
"对比知乎和微博平台对'比特币'的关注度差异",
"搜索'华为'相关的正面新闻",
"生成今天的科技新闻摘要报告"
]
7. 部署架构与自动化
7.1 GitHub Actions 自动化
参考快速开始系统通过 GitHub Actions 实现完全自动化运行:
# .github/workflows/crawler.yml
name: Hot News Crawler
on:
schedule:
- cron: '0 * * * *' # 每小时运行一次
workflow_dispatch: # 支持手动触发
jobs:
crawl:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
- name: Install dependencies
run: |
pip install pyyaml requests
- name: Run crawler
env:
FEISHU_WEBHOOK_URL: ${{ secrets.FEISHU_WEBHOOK_URL }}
# ... 其他环境变量
run: python main.py
7.2 多样化部署方案
- GitHub Pages 部署:
- 一键 Fork 即可使用
- 自动生成精美网页报告
- 移动端完美适配
- Docker 容器化部署:
docker run -d --name trend-radar \
-v ./config:/app/config:ro \
-v ./output:/app/output \
-e FEISHU_WEBHOOK_URL="你的webhook" \
wantcat/trendradar:latest
- 本地化部署:
- 支持 Windows/Linux/macOS
- 提供自动化安装脚本
- 灵活的配置管理
8. 安全与隐私设计
8.1 配置安全
项目高度重视用户隐私和信息安全:
- Secrets 管理:所有敏感信息通过 GitHub Secrets 管理
- 配置隔离:Webhook URL 不暴露在代码仓库中
- 权限最小化:只请求必要的 API 权限
8.2 代理支持
def _setup_proxy(self) -> None:
"""设置代理配置"""
if not self.is_github_actions and CONFIG["USE_PROXY"]:
self.proxy_url = CONFIG["DEFAULT_PROXY"]
print("本地环境,使用代理")
else:
print("GitHub Actions环境,不使用代理")
9. 定制化和扩展性
平台扩展:
参考newsnow添加需要检测的平台:
# 添加新平台仅需配置修改
platforms:
- id: "new-platform"
name: "新平台名称"
关键词扩展:
在 /config/frequency_words.txt 文件添加自己感兴趣的关键词,支持普通词、必须词(+)、过滤词(!)三种语法。
AI
机器学习
+技术
# 新主题
金融
股市
+投资三种推送模式:
在 /config/config.yaml 文件中配置推送模式,包括当日汇总(daily)、当前榜单(current)、增量监控(incremental)以满足不通的人群需求:
# 推送模式选择
report:
mode: "daily" # 可选: "daily"|"incremental"|"current"
rank_threshold: 5 # 排名高亮阈值
推送时间窗口控制:
在 /config/config.yaml 文件中配置推送时间窗口控制,即控制推送时间和频率:
# 🕐 推送时间窗口控制(可选功能)
# 用途:限制推送的时间范围,避免非工作时间打扰
# 适用场景:
# - 只想在工作日白天接收推送(如 09:00-18:00)
# - 希望在晚上固定时间收到汇总(如 20:00-22:00)
push_window:
enabled: true # 是否启用推送时间窗口控制,默认关闭
# 注意:GitHub Actions 执行时间不稳定,时间范围建议至少留足 2 小时
# 如果想要精准的定时推送,建议使用 Docker 部署在个人服务器上
time_range:
start: "08:00" # 推送时间窗口开始(北京时间)
end: "18:00" # 推送时间窗口结束(北京时间)
once_per_day: false # 每天在时间窗口内只推送一次,如果 false,则窗口内每次执行都推送
push_record_retention_days: 7 # 推送记录保留天数
10. 项目价值与意义
10.1 技术价值
- 开源社区贡献:为技术社区提供了一个完整的新闻聚合解决方案
- 架构设计参考:展示了中小规模应用的优秀架构实践,文档详细,新手友好
- API 使用范例:演示了如何优雅地集成第三方服务 API
10.2 用户价值
- 信息获取革命:从被动接受算法推荐到主动获取信息
- 效率提升:大幅减少刷各类 APP 的时间浪费
- 个性化定制:支持个人专属的信息关注点,亦可定制开发,如输出markdown格式
11. 总结
TrendRadar 项目是开源精神与技术创新的完美结合,它不仅解决了信息过载时代的实际问题,更展示了一个优秀开源项目应有的特质:
技术创新性:采用 MCP 协议引入 AI 分析,实现与智能助手的无缝集成
用户友好性:30秒零门槛部署,支持多样化通知渠道
架构合理性:模块化设计,配置驱动,易于维护和扩展
社区活跃度:完善的文档,活跃的问题响应,持续的版本迭代
在信息日益碎片化的今天,TrendRadar 为我们提供了一个重新掌控信息主动权的工具。它不仅仅是一个技术项目,更是一种信息获取方式的革新。通过这个项目,我们看到了开源社区如何用技术创新解决实际问题,也见证了技术如何让生活变得更美好。
对于开发者而言,TrendRadar 提供了一个学习和实践的绝佳案例;对于用户而言,它提供了一个提升信息获取效率的实用工具。
本人早已萌生每日自动获取感兴趣的科技新闻并推送的想法,以避免每天在各类 APP 中频繁搜索热点信息的繁琐过程。然而,受限于新闻来源的不统一及整合方式的不明确,此计划迟迟未能实施。近期接触到的这一开源项目令我深受启发,其在消息源获取、数据整合及推送机制等方面均具备较高的参考价值。未来,我计划在深入学习该项目的基础上,进行个性化定制开发,以实现更契合个人需求的功能,例如生成markdown格式输入再到AI总结、配图等,方便在平台上发文等:
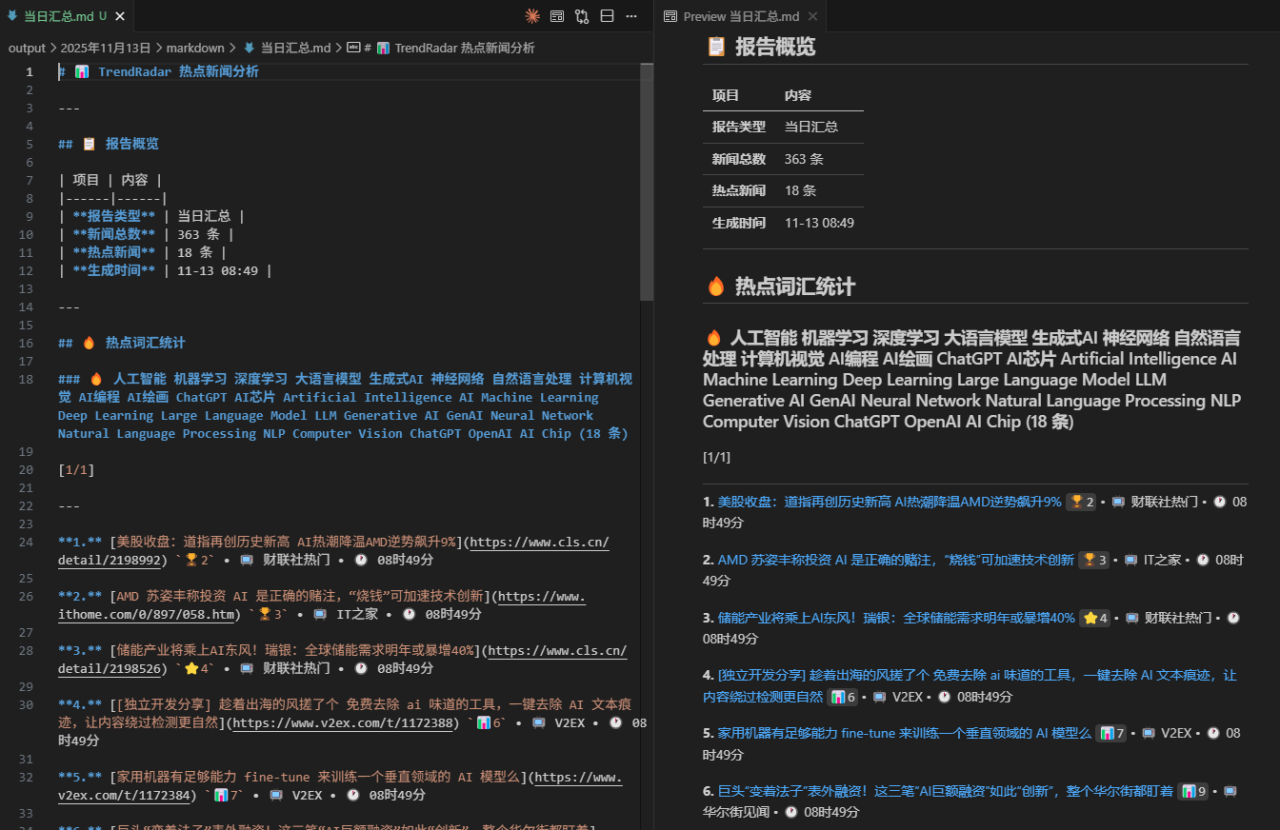
这正是优秀开源项目的价值所在——不仅解决技术问题,更创造实际价值,推动社会进步。
项目链接
- TrendRadar GitHub 仓库:https://github.com/sansan0/TrendRadar
- 在线演示:https://sansan0.github.io/TrendRadar/
- 项目文档:https://github.com/sansan0/TrendRadar/blob/master/readme.md
- 内容来源:https://newsnow.busiyi.world/
本文基于 TrendRadar v3.0.4 版本分析,项目持续更新中。