python+selenium爬取动态网页数据
1. 安装selenium
2. Selenium+BeautifulSoup爬网页信息
3. selenium操作网页
4. Selenium 的缺点
5. amazon实例
6. 数据异步加载
遇到动态网页是在爬虫的时候,发现网页检查的内容在网页源码中找不到,所以就不能爬那些源码中找不到的内容,百度之后才知道网页是分动态、静态网页的。静态网页,随着html代码的生成,页面的内容和显示效果就基本上不会发生变化了——除非你修改页面代码。而动态网页则不然,页面代码虽然没有变,但是显示的内容却是可以随着时间、环境或者数据库操作的结果而发生改变的。
因此在大多数网页中,网页检查的内容是大于网页源码的内容。
知乎、博客上对于爬动态网页一般有两种方法
- 分析网页的js请求,什么一套并没大看懂…
- selenium模拟浏览器行为
selenium方法我个人理解的就是让程序帮你操作网页,触发网页的js请求,再获取的网页源码就有了想要到内容(纯属小白理解…)
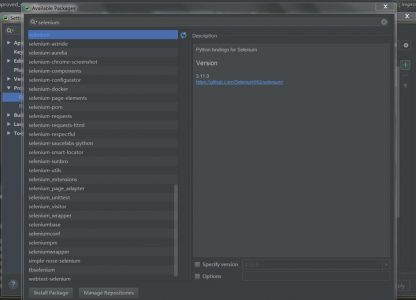
1. 安装selenium
pycharm对于安装一些库还是很方便的,直接在file->Setting->Project->Project Interpreter中点击右上角绿色的小加号 搜索安装 就可以了。
selenium默认的浏览器是火狐浏览器,安装一个火狐。也可以用chrome,再安装一个chrome驱动器就可以,我觉得装浏览器比起装驱动还是简单一点的,就用的火狐浏览器。
2. Selenium+BeautifulSoup爬网页信息
selenium模拟浏览器爬虫还是有很多好处
1.可以简简单单爬动态网页
2.不用设置代理,不用担心ip被封!
直接贴一段代码吧
from selenium import webdriver
from bs4 import BeautifulSoup
AMAZON='https://www.amazon.cn'
#打开浏览器
driver=webdriver.Firefox()
#打开亚马逊主页
driver.get(AMAZON)
#driver.page_source可以获取当前源码,用BeautifulSoup解析网页
page=BeautifulSoup(driver.page_source,'html5lib')
#查找语句就跟用requests+beautifulsoup一样的
page.find_all('') 3. selenium操作网页
1.有的网页内容是随着下滑滑动条不断加载的,这时候要模拟页面滚动的操作
#拖动到页面最底部,=0为拖动到页面最顶部
js="var q=document.documentElement.scrollTop=document.body.scrollHeight"
driver.execute_script(js)
怎么判断页面是否到底这个还没有研究出来...不过我是根据页面内容总数来设置几次拖动最底部2.设置页面等待时间
可以看看这个博客,闪电侠和凹凸曼讲的好好玩
3.保存网页图片到本地
第一种方法
import urllib.request
img='https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1521002829933&di=e847be634ddca575e8487788ce681caa&imgtype=0&src=http%3A%2F%2Fimg5.duitang.com%2Fuploads%2Fpeople%2F201504%2F01%2F20150401152419_CPwNR.jpeg'
save_name='./0.jpg'
urllib.request.utlretrieve(img, save_name)第二种方法
import requests
img='https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1521002829933&di=e847be634ddca575e8487788ce681caa&imgtype=0&src=http%3A%2F%2Fimg5.duitang.com%2Fuploads%2Fpeople%2F201504%2F01%2F20150401152419_CPwNR.jpeg'
req=requests.get(img)
save_name='./0.jpg'
f=open(save_name,'ab')
f.wirte(req.content)
f.close()4. Selenium 的缺点
————摘自为什么不推荐Selenium写爬虫
- 速度慢。每次运行爬虫都打开一个浏览器,如果没有设置,还会加载图片、JS等等一大堆东西;
- 占用资源太多。有人说,把
Chrome换成无头浏览器PhantomJS,原理都是一样的,都是打开浏览器,而且很多网站会验证参数,如果对方看到你是以PhantomJS去访问,会BAN掉你的请求,然后你又要考虑更换请求头的事情,事情复杂程度不知道多了多少,为啥学Python?因为Python简单啊,如果有更快、更简单的库可以实现同样的功能,为什么不去使用呢? - 对网络的要求会更高。
Selenium加载了很多可能对您没有价值的补充文件(如css,js和图像文件)。 与仅仅请求您真正需要的资源(使用单独的HTTP请求)相比,这可能会产生更多的流量。 - 爬取规模不能太大。你有看到哪家公司用
Selenium作为生产环境吗? - 难。学习
Selenium的成本太高,只有我一个人觉得Selenium比Requests难一百倍吗?
5. amazon实例
爬亚马逊用户购买的记录
因为代码有文件读取,下面的代码是不能直接跑的,看看主要思路吧
import time
from selenium import webdriver
from bs4 import BeautifulSoup
import json
import urllib.request
import csv
AMAZON='https://www.amazon.cn'
file=open('./user_pages.txt')
users=[]
for i in file:
users.append(i.strip('\n'))
driver=webdriver.Chrome()
driver.implicitly_wait(10)
for i in users:
print(i)
driver.get(i)
time.sleep(5)
save=[i[47:75]]
# print(save)
page = BeautifulSoup(driver.page_source, 'html5lib')
comment=page.find_all('span',class_='a-size-large a-color-base')
try:
comment_num = int(comment[1].string)
except:
comment_num = 5
if comment_num<=10:
iteration_num=0
else:
iteration_num = comment_num / 8
# print(iteration_num)
while iteration_num>0: ### 拖动滚动条以加载全部记录
time.sleep(4)
iteration_num = iteration_num - 1
js = "var q=document.documentElement.scrollTop=10000"
driver.execute_script(js)
page = BeautifulSoup(driver.page_source, 'html5lib')
record=page.find_all('a',class_='a-link-normal a-text-normal')
for i in record:
save.append(AMAZON+i.get('href'))
print(save)
time.sleep(5)
driver.close()——————————————— 更新 ——————————————-
6. 数据异步加载
这种需要滚动条来控制内容刷新的东西好像叫做异步加载。
上述代码中为了加载用户全部购买记录需要使用代码:
js = "var q=document.documentElement.scrollTop=10000"
driver.execute_script(js)这句话的意思是把页面的滚动条下拉到底部,这时候网页进行一次加载
如果用这个方法的话要下拉多次滚动条(while循环),等待数据完全加载之后再获取数据。这个方法在我自己实现的时候出现了 【下拉几次滚动条之后界面就不更新】的问题。
另一种方法是笔者终于搞懂了的分析js请求,其实没那么难。下面是某问题的答案
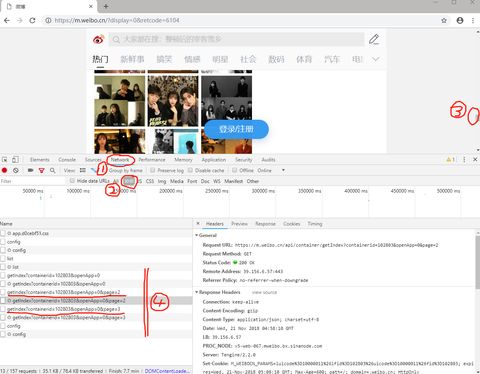
原理上下拉滚动条刷新内容和点击下一页刷新内容是一样的。都是请求一个新的url,而这个url更新是有规律的。
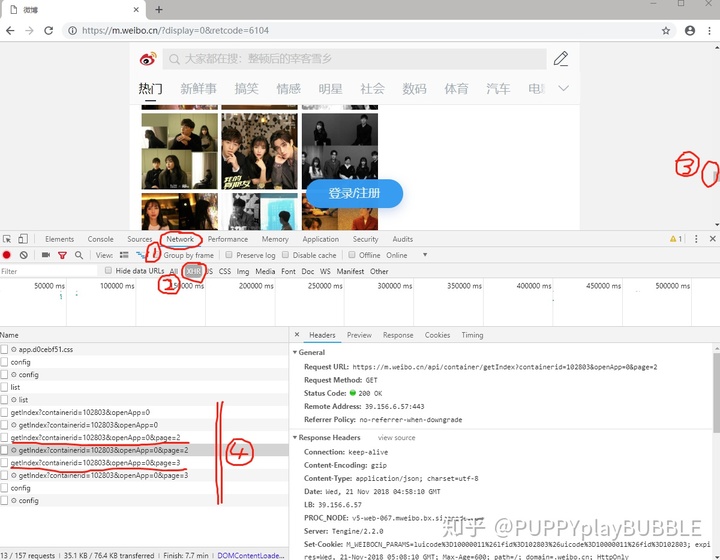
- 点开网页后,右键->检查
- Network->XHR
- 这时下拉页面滚动条让内容刷新
- 会看到圈4框中的内容刷新了,点开圈4横线处右侧就会显示此时请求的url。
很容易发现规律 https://m.weibo.cn/api/container/getIndex?containerid=102803&openApp=0&page=xx
此后就可以写for循环来获取加载的内容了:
for i in range(1,N):
url = 'https://m.weibo.cn/api/container/getIndex?containerid=102803&openApp=0&page=%d'%i
driver.get(url)