用Python爬虫抓取免费代理IP


作者:HDMI,JUST WANT AND JUST DO
blog地址:http://zhihu.com/people/hdmi-blog
不知道大家有没有遇到过“访问频率太高”这样的网站提示,我们需要等待一段时间或者输入一个验证码才能解封,但这样的情况之后还是会出现。出现这个现象的原因就是我们所要爬取的网页采取了反爬虫的措施,比如当某个ip单位时间请求网页次数过多时,服务器会拒绝服务,这种情况就是由于访问频率引起的封ip,这种情况靠解封不能很好的解决,所以我们就想到了伪装本机ip去请求网页,也就是我们今天要讲的使用代理ip。
目前网上有许多代理ip,有免费的也有付费的,例如西刺代理等,免费的虽然不用花钱但有效的代理很少且不稳定,付费的可能会好一点,不过今天我只爬取免费的代理并将检测是否可用,将可用ip存入MongoDB,方便下次取出。
运行平台:Windows
Python版本:Python3.6
IDE: Sublime Text
其他:Chrome浏览器
简述流程为:
步骤1:了解requests代理如何使用
步骤2:从代理网页爬取到ip和端口
步骤3:检测爬取到的ip是否可用
步骤4:将爬取的可用代理存入MongoDB
步骤5:从存入可用ip的数据库里随机抽取一个ip,测试成功后返回
对于requests来说,代理的设置比较简单,只需要传入proxies参数即可。
不过需要注意的是,这里我是在本机安装了抓包工具Fiddler,并用它在本地端口8888创建了一个HTTP代理服务(用Chrome插件SwitchyOmega),即代理服务为:127.0.0.1:8888,我们只要设置好这个代理,就可以成功将本机ip切换成代理软件连接的服务器ip了。
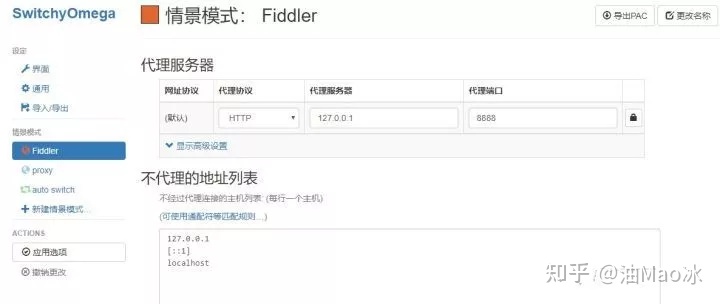
import requestsproxy ='127.0.0.1:8888'proxies ={'http':'http://'+ proxy,'https':'http://'+ proxy}try:response = requests.get('http://httpbin.org/get',proxies=proxies)print(response.text)except requests.exceptions.ConnectionErroras e:print('Error',e.args)
这里我是用来http://httpbin.org/get作为测试网站,我们访问该网页可以得到请求的有关信息,其中origin字段就是客户端ip,我们可以根据返回的结果判断代理是否成功。返回结果如下:
{"args":{},"headers":{"Accept":"*/*","Accept-Encoding":"gzip, deflate","Connection":"close","Host":"httpbin.org","User-Agent":"python-requests/2.18.4"},"origin":"xx.xxx.xxx.xxx","url":"http://httpbin.org/get"}
接下来我们便开始爬取代理IP,首先我们打开Chrome浏览器查看网页,并找到ip和端口元素的信息。
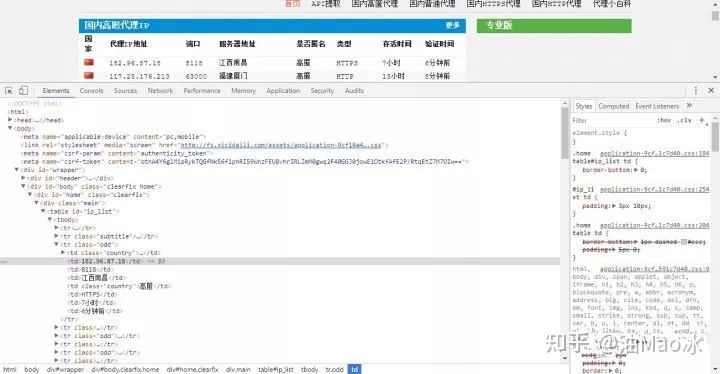
可以看到,代理IP以表格存储ip地址及其相关信息,所以我们用BeautifulSoup提取时很方便便能提取出相关信息,但是我们需要注意的是,爬取的ip很有可能出现重复的现象,尤其是我们同时爬取多个代理网页又存储到同一数组中时,所以我们可以使用集合来去除重复的ip。
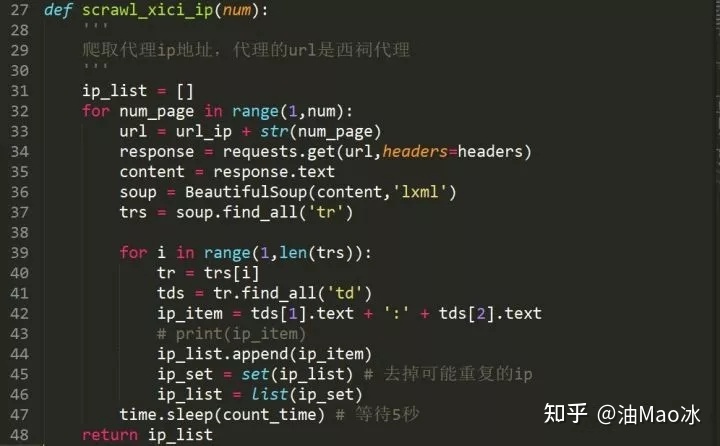
将要爬取页数的ip爬取好后存入数组,然后再对其中的ip逐一测试。
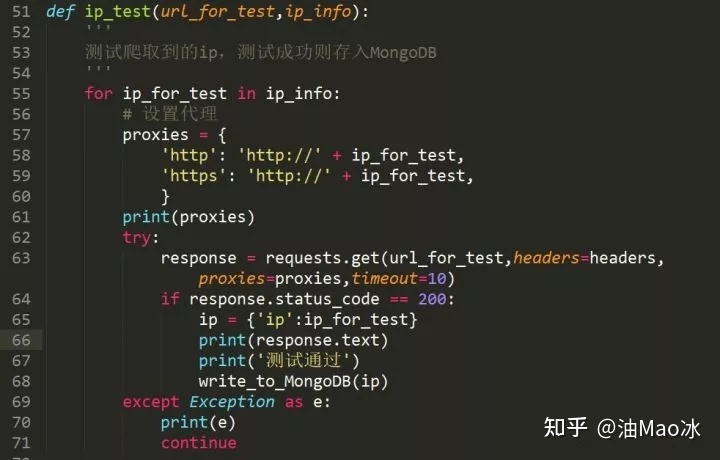
这里就用到了上面提到的requests设置代理的方法,我们使用http://httpbin.org/ip作为测试网站,它可以直接返回我们的ip地址,测试通过后再存入MomgoDB数据库。
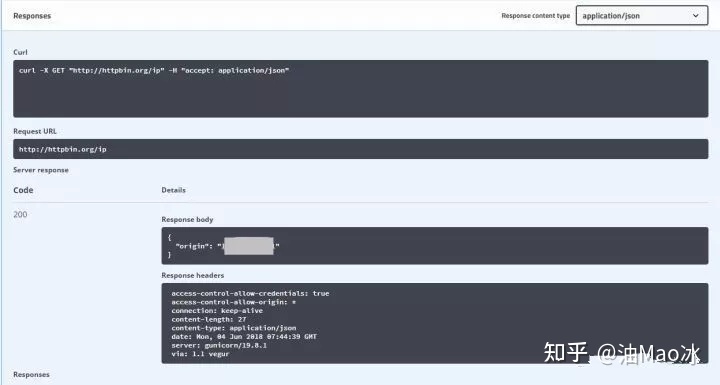
连接数据库然后指定数据库和集合,再将数据插入就OK了。
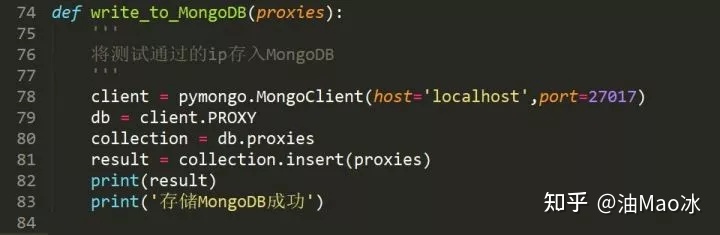
最后运行查看一下结果吧
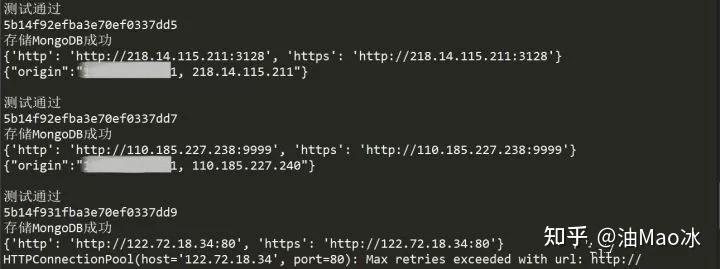
运行了一段时间后,难得看到一连三个测试通过,赶紧截图保存一下,事实上是,毕竟是免费代理,有效的还是很少的,并且存活时间确实很短,不过,爬取的量大,还是能找到可用的,我们只是用作练习的话,还是勉强够用的。现在看看数据库里存储的吧。
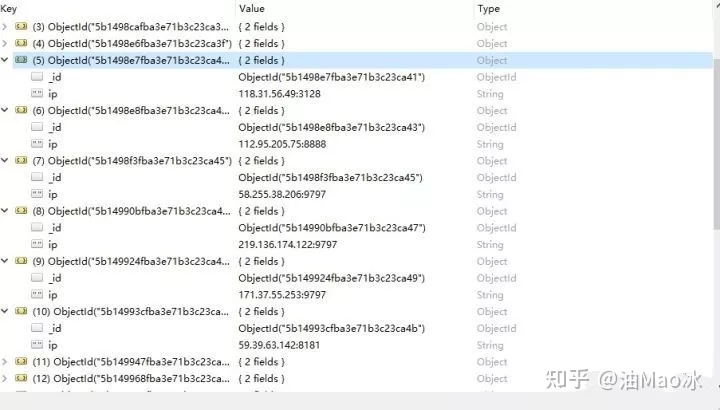
因为爬取的页数不多,加上有效ip也少,再加上我没怎么爬,所以现在数据库里的ip并不多,不过也算是将这些ip给存了下来。现在就来看看怎么随机取出来吧。
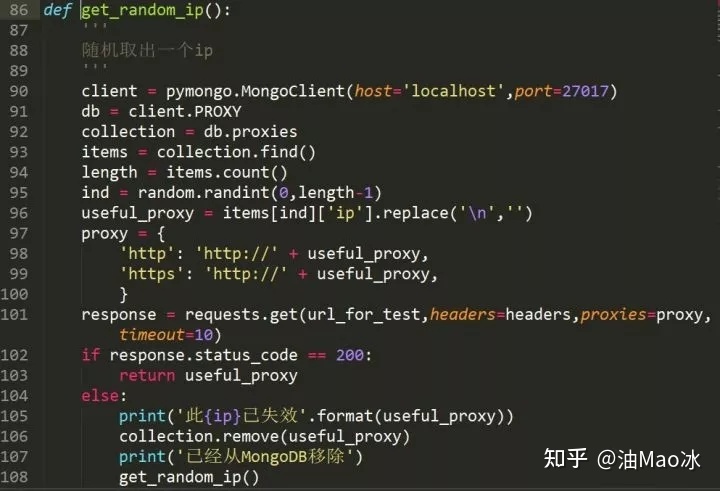
由于担心放入数据库一段时间后ip会失效,所以取出前我重新进行了一次测试,如果成功再返回ip,不成功的话就直接将其移出数据库。
这样我们需要使用代理的时候,就能通过数据库随时取出来了。
总的代码如下:
import randomimport requestsimport timeimport pymongofrom bs4 importBeautifulSoup# 爬取代理的URL地址,选择的是西刺代理url_ip ="http://www.xicidaili.com/nt/"# 设定等待时间set_timeout =5# 爬取代理的页数,2表示爬取2页的ip地址num =2# 代理的使用次数count_time =5# 构造headersheaders ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'}# 测试ip的URLurl_for_test ='http://httpbin.org/ip'def scrawl_xici_ip(num):'''爬取代理ip地址'''ip_list =[]for num_page in range(1,num):url = url_ip + str(num_page)response = requests.get(url,headers=headers)if response.status_code ==200:content = response.textsoup =BeautifulSoup(content,'lxml')trs = soup.find_all('tr')for i in range(1,len(trs)):tr = trs[i]tds = tr.find_all('td')ip_item = tds[1].text +':'+ tds[2].text# print(ip_item)ip_list.append(ip_item)ip_set =set(ip_list)# 去掉可能重复的ipip_list = list(ip_set)time.sleep(count_time)# 等待5秒return ip_listdef ip_test(url_for_test,ip_info):'''测试爬取到的ip,测试成功则存入MongoDB'''for ip_for_test in ip_info:# 设置代理proxies ={'http':'http://'+ ip_for_test,'https':'http://'+ ip_for_test,}print(proxies)try:response = requests.get(url_for_test,headers=headers,proxies=proxies,timeout=10)if response.status_code ==200:ip ={'ip':ip_for_test}print(response.text)print('测试通过')write_to_MongoDB(ip)exceptExceptionas e:print(e)continuedef write_to_MongoDB(proxies):'''将测试通过的ip存入MongoDB'''client = pymongo.MongoClient(host='localhost',port=27017)db = client.PROXYcollection = db.proxiesresult = collection.insert(proxies)print(result)print('存储MongoDB成功')def get_random_ip():'''随机取出一个ip'''client = pymongo.MongoClient(host='localhost',port=27017)db = client.PROXYcollection = db.proxiesitems = collection.find()length = items.count()ind = random.randint(0,length-1)useful_proxy = items[ind]['ip'].replace('\n','')proxy ={'http':'http://'+ useful_proxy,'https':'http://'+ useful_proxy,}response = requests.get(url_for_test,headers=headers,proxies=proxy,timeout=10)if response.status_code ==200:return useful_proxyelse:print('此{ip}已失效'.format(useful_proxy))collection.remove(useful_proxy)print('已经从MongoDB移除')get_random_ip()def main():ip_info =[]ip_info = scrawl_xici_ip(2)sucess_proxy = ip_test(url_for_test,ip_info)finally_ip = get_random_ip()print('取出的ip为:'+ finally_ip)if __name__ =='__main__':main()