python爬取可转债数据
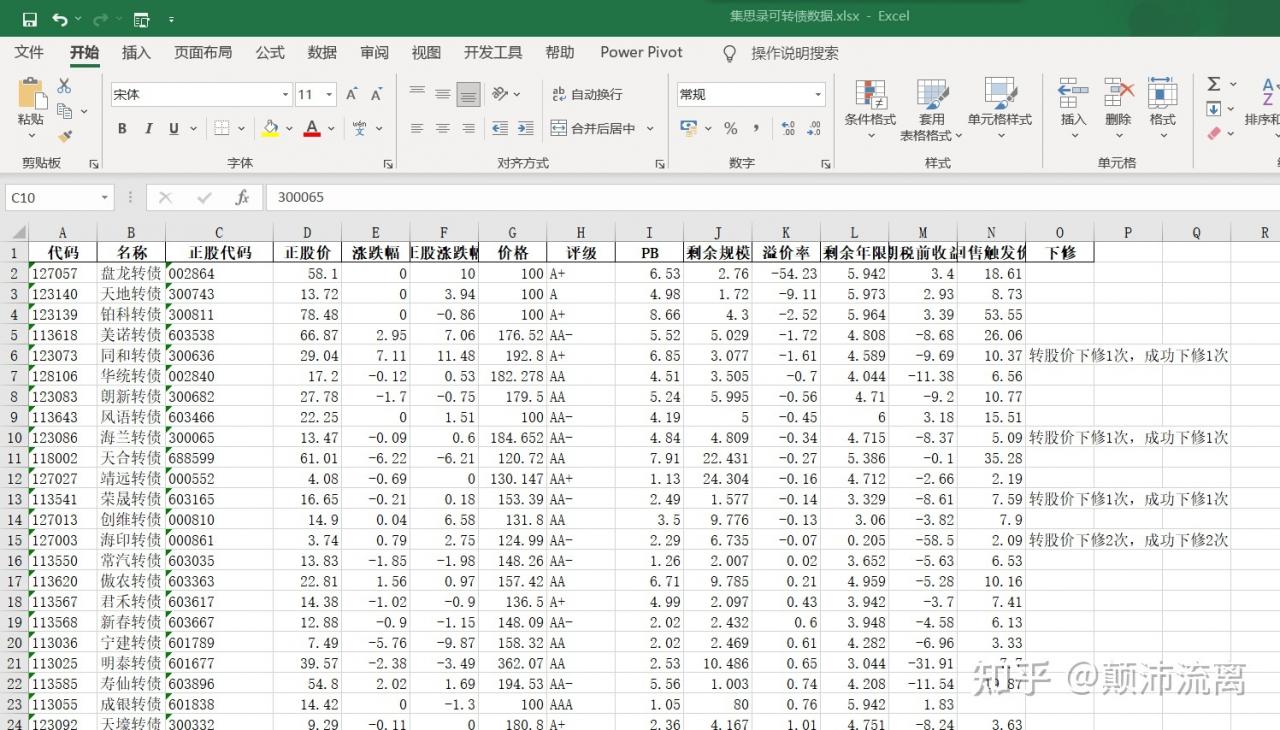
集思录这个网站里有很多详细的可转债数据,这些数据对我们分析可转债并作出投资决策有很大的帮助。但是我们对这些数据进行全面性的分析还是有一定麻烦,如果能把这些数据导入Excel或者pandas对我们分析无疑提供了很大的帮助。我们运用Python几行代码就可以将所有的可转债数据采集下来了。
import requests
import pandas as pd
import numpy as np首先我们向导入需要的python包。requests是一个python的一个爬虫库,我们用这个爬虫库可以十分的获取网页的数据。pandas和numpy这是用于对数据进行分析的。
headers_jsl={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0'}
jsl='https://www.jisilu.cn/data/cbnew/cb_list_new/?___jsl=LST___t=1637410410639'
data=requests.get(jsl,headers=headers_jsl).json()
list=[]
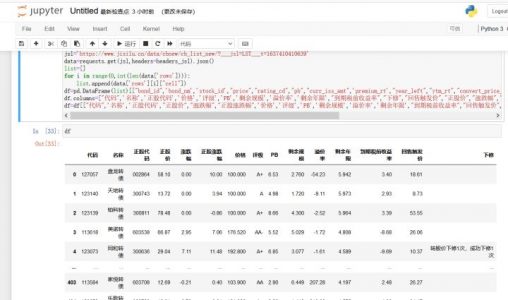
for i in range(0,int(len(data['rows']))):
list.append(data['rows'][i]["cell"])
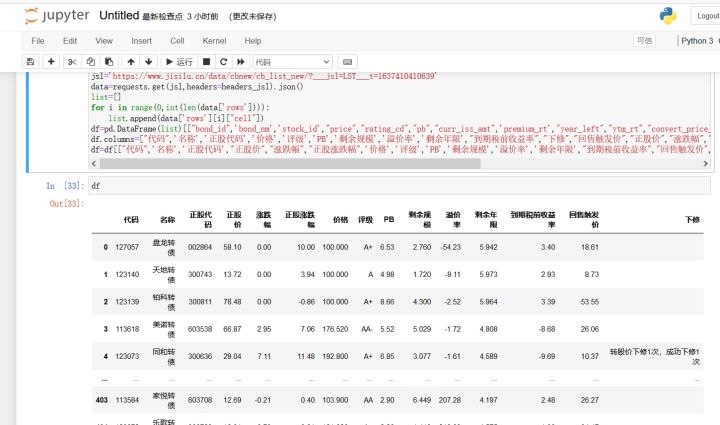
df=pd.DataFrame(list)[["bond_id",'bond_nm','stock_id',"price","rating_cd","pb","curr_iss_amt",'premium_rt',"year_left","ytm_rt","convert_price_tips","put_convert_price","sprice",'increase_rt','sincrease_rt']]
df.columns=["代码",'名称','正股代码','价格','评级','PB','剩余规模','溢价率','剩余年限',"到期税前收益率","下修","回售触发价","正股价","涨跌幅","正股涨跌幅"]
df=df[["代码",'名称','正股代码',"正股价","涨跌幅","正股涨跌幅",'价格','评级','PB','剩余规模','溢价率','剩余年限',"到期税前收益率","回售触发价","下修"]]我们在通过这简单的几行代码就可以将网页的数据采集下来了!
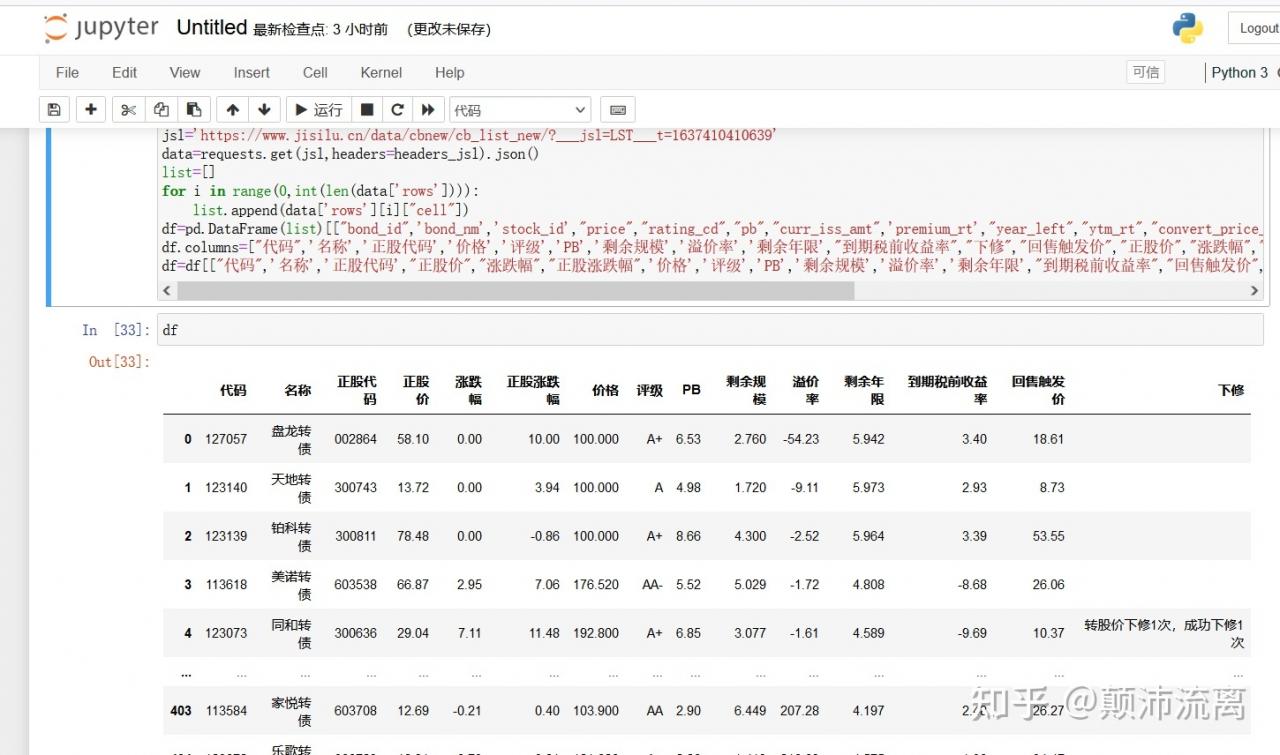
之后就可以用pandas自由的进行分析了。如果需要用Excel分析,我们只需要一行代码就可以把数据生成Excel文件。用Excel对可转债数据进行分析。
df.to_excel("集思录可转债数据.xlsx",index=None)