你们初刷leetcode时会怀疑自己的智商吗?

会!有个感觉太正常了!
我当初找工作的时候开始刷题,看着LeetCode题解区大神,一个题目N种解法,变着玩出花来。
而我挠破头皮也想不出一种解法,甚至有时候想出了暴力解法,写出的代码也是磕磕碰碰,一堆error warning!甚至怀疑是不是选错了专业,这根本不适合我。
于是我就不刷了!对,我不刷了。
我开始去搜索、询问大佬们是怎么刷的,好家伙,果然被我找到了方法,而且还总结出了套路,算法也就那么回事。后来看到一个题目,就能立刻反应出考察的是哪个类型,丝滑无比。
下面我会从以下 3 个方便来阐述如何简化算法学习:
- 算法刷题套路汇总
- 普通人如何理解算法
- 刷题工具有什么讲究
下面是我当初做的笔记,中间是我在纸质笔记本上画拍照存下来便于理解。

大家应该注意到了,我把题目做了分门归类,几乎所有的算法可以归类到以下 14 种模式:
- 1.滑动窗口
- 2.二指针或迭代器
- 3.快速和慢速指针或迭代器
- 4.合并区间
- 5.循环排序
- 6.原地反转链表
- 7.树的宽度优先搜索(Tree BFS)
- 8.树的深度优先搜索(Tree DFS)
- 9.Two Heaps
- 10.子集
- 11.经过修改的二叉搜索
- 12.前 K 个元素
- 13.K 路合并
- 14.拓扑排序
那要怎么刷才能让自己不感到智商不够呢?
首先你要了解这些模式,然后针对每一种模式去大量练习,比如动态规划,刷他个20道同类型题目,这样下次在遇到变型题也能马上上手。
刚开始,即使是同一道题,第一次做出来了,隔几天再来也是毫无头绪,非常正常,不要怀疑自己!
这时我每一次刷题,会把这次的思考和遇到的问题,为什么没写出来的原因,记录下来,以便每次都能有进步。
这就是「总结归纳」,比如下面是我曾经对「整数拆分」这道题的做题笔记记录:
我记性不太好,脑子也没有特别聪明,每刷一次记录一次,开头是时间,后面是做题备注,类似错题笔记一样,如果你没有什么好的方法,强烈建议也像我这样记录,别着急,慢慢来,量变引起质变!

方法就是:总结归纳+刻意练习。至于怎么做?我后面会展开来细说。
现在工作也比较久了,虽然不用为了面试去刻意刷题,但当时养成的习惯仍然保留了下来。
去年我利用业余时间,刷了几百道题,作为一名有经验的开发人员,虽然现在不用为了面试去刷太多题,但程序员写代码算是个手艺活,刷题能够保持手感,并且LeetCode会有一些很有意思的新题,做出来也非常有成就感,像打游戏一样,很上头。
下面是我今年在LeetCode年度报告出了,发的朋友圈截图:


面试刷题抓重点
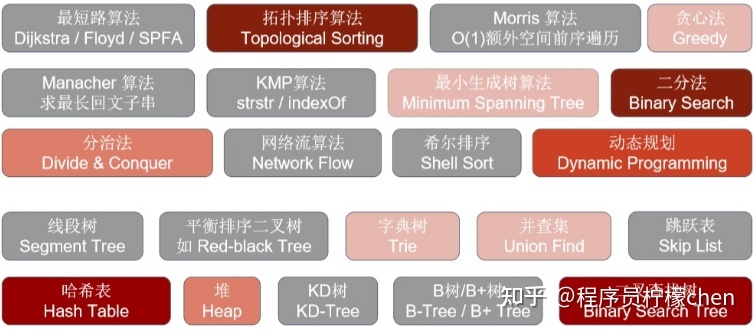
大部分同学刷题是为了面试,在我们精力有限的情况下,并不一定要把上面说的 14 种模式都完全刷一遍,下面这张图做了比较好的总结,有选择性的刷题,颜色越深面试碰到的概率越高,刷!
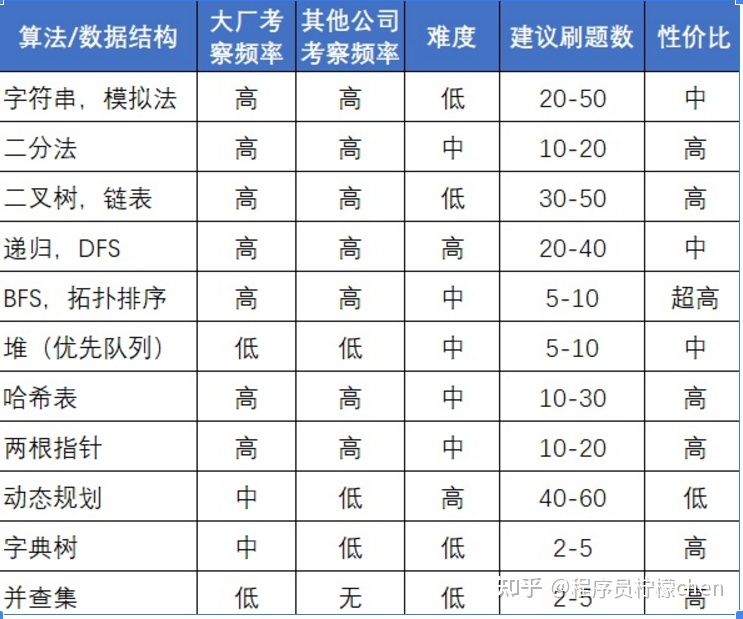
下面这张图也做了类似的总结,还给出了大厂考察频率、小公司考察频率,甚至性价比都给你算出来了,还有什么理由不去刷性价比最高的呢!
非常重要的算法模式比如:二分法、二叉树、链表、BFS、DFS、双指针、哈希表、字典树、各种排序,这些必须做到熟练掌握。
刷题套路方法
我们知道歪果仁在算法刷题方面,是比国内程序员早的,早上国外互联网大厂用算法能力考核候选人的时候,国内还没有这一说,所以国外有一门算法课把面试中常见的算法总结出了套路,下面就是课程原文链接,英语好的同学可以去看看。
这篇算法解题模式套路已经有人做了翻译,下面我也会引用过来,建议大家全文阅读一遍:
作者:Fahim ul Haq
机器之心编译
参与:Panda
算法解题套路
咱们在面试程序员岗位时往往需要经历一个编程面试过程,雇主会借此考验面试者的技术实力。
然而,这些技术问题有时候却和我们的实际工作并无太大关系,也由此可能给我们的编程面试准备阶段带来很大的压力。
曾在 Facebook 和微软工作过的 http://Educative.io 创始人 Fahim ul Haq 近日发文总结了编程面试所遇到的问题的 14 种最常见的模式,也许能帮你看清各种编程面试问题「背后的真相」。
对很多开发者来说,编程工作的面试准备很容易让人焦虑。面试要涉及的东西实在太多,其中很多还往往与开发者的日常工作无关,只会额外增添压力。
这种现状导致了一个后果:现在的开发者往往需要花费数周时间在 LeetCode 等网站上了解综合数百个问题。
与我谈过的开发者在面试前的一个常见焦虑问题是:我是否已经解决过足够多的实际问题?我本可以做到更多吗?
这就是我想要帮助开发者了解每个问题背后的底层模式的原因——这样他们就不必担忧解决数百个问题以及被 LeetCode 整得疲惫不堪了。
如果你理解面试的通用模式,你就可以将其用作模板,从而解决各种层级的稍有不同的问题。
这里我将列出最常见的 14 种模式,它们可被用于解决任何编程面试问题。
另外我还会说明如何识别每种模式,并会为每种模式提供一些问题示例。
这些内容都只是蜻蜓点水——我强烈建议你看看课程《Grokking the Coding Interview: Patterns for Coding Questions》,里面提供了全面的解释、示例和编程实践。
下面的模式说明假设你已经知悉了数据结构。如果你还不了解,那需要补充一下知识点哦。
我们今天将说明以下 14 种模式:
- 1.滑动窗口
- 2.二指针或迭代器
- 3.快速和慢速指针或迭代器
- 4.合并区间
- 5.循环排序
- 6.原地反转链表
- 7.树的宽度优先搜索(Tree BFS)
- 8.树的深度优先搜索(Tree DFS)
- 9.Two Heaps
- 10.子集
- 11.经过修改的二叉搜索
- 12.前 K 个元素
- 13.K 路合并
- 14.拓扑排序
我们开始吧!
1.滑动窗口
滑动窗口模式是用于在给定数组或链表的特定窗口大小上执行所需的操作,比如寻找包含所有 1 的最长子数组。
从第一个元素开始滑动窗口并逐个元素地向右滑,并根据你所求解的问题调整窗口的长度。
在某些情况下窗口大小会保持恒定,在其它情况下窗口大小会增大或减小。
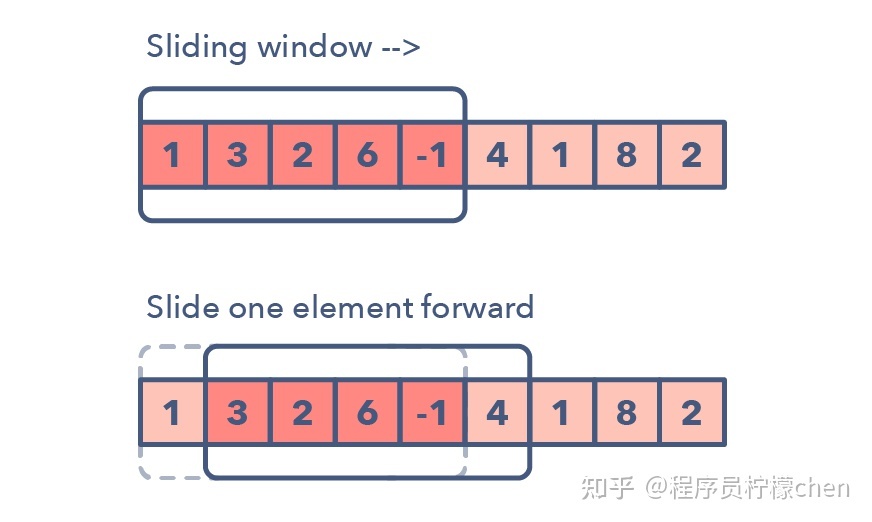
下面是一些你可以用来确定给定问题可能需要滑动窗口的方法:
- 问题的输入是一种线性数据结构,比如链表、数组或字符串
- 你被要求查找最长/最短的子字符串、子数组或所需的值
你可以使用滑动窗口模式处理的常见问题:
- 大小为 K 的子数组的最大和(简单)
- 带有 K 个不同字符的最长子字符串(中等)
- 寻找字符相同但排序不一样的字符串(困难)
2.二指针或迭代器
二指针(Two Pointers)是这样一种模式:
两个指针以一前一后的模式在数据结构中迭代,直到一个或两个指针达到某种特定条件。
二指针通常在排序数组或链表中搜索配对时很有用:比如当你必须将一个数组的每个元素与其它元素做比较时。
二指针是很有用的,因为如果只有一个指针,你必须继续在数组中循环回来才能找到答案。
这种使用单个迭代器进行来回在时间和空间复杂度上都很低效——这个概念被称为「渐进分析(asymptotic analysis)」。
尽管使用 1 个指针进行暴力搜索或简单普通的解决方案也有效果,但这会沿 O(n²) 线得到一些东西。在很多情况中,二指针有助于你寻找有更好空间或运行时间复杂度的解决方案。
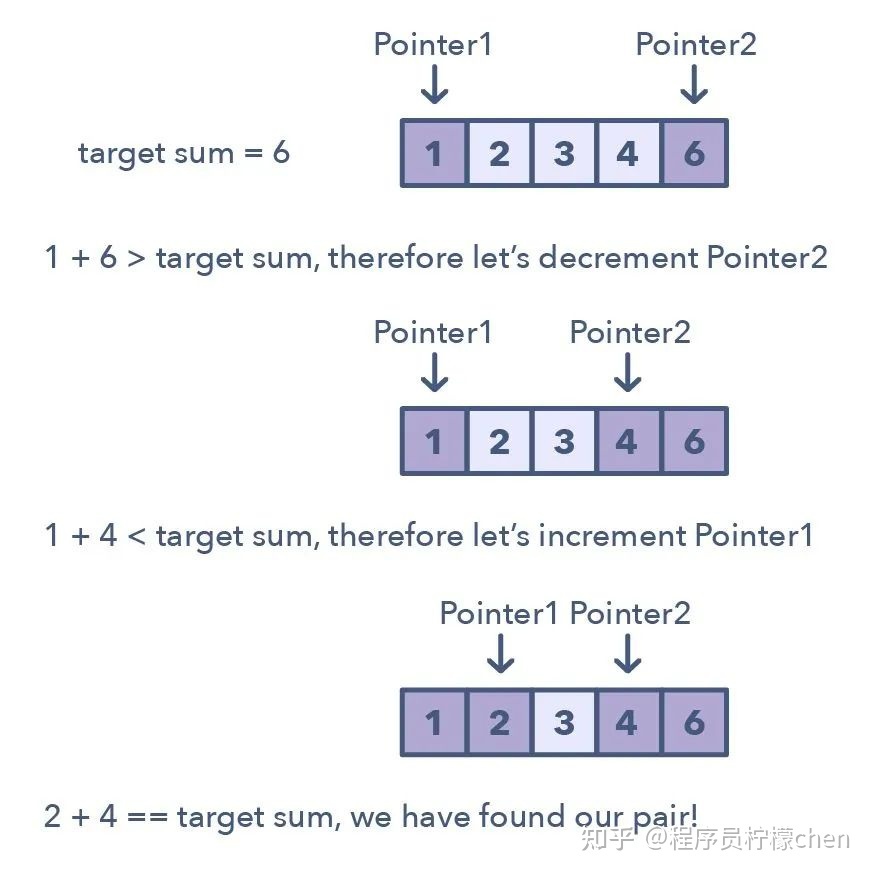
用于识别使用二指针的时机的方法:
- 可用于你要处理排序数组(或链接列表)并需要查找满足某些约束的一组元素的问题
- 数组中的元素集是配对、三元组甚至子数组
下面是一些满足二指针模式的问题:
- 求一个排序数组的平方(简单)
- 求总和为零的三元组(中等)
- 比较包含回退(backspace)的字符串(中等)
3.快速和慢速指针
快速和慢速指针方法也被称为 Hare & Tortoise 算法,该算法会使用两个在数组(或序列/链表)中以不同速度移动的指针。该方法在处理循环链表或数组时非常有用。
通过以不同的速度进行移动(比如在一个循环链表中),该算法证明这两个指针注定会相遇。只要这两个指针在同一个循环中,快速指针就会追赶上慢速指针。
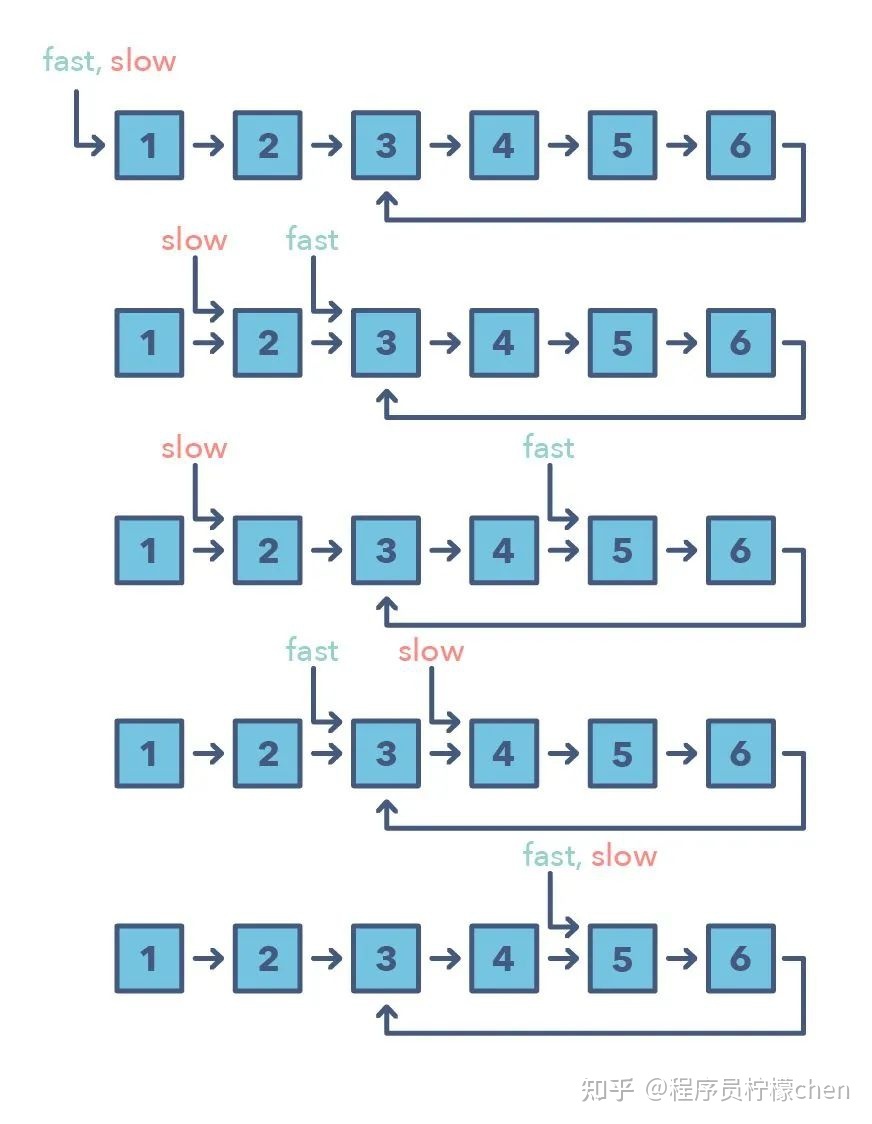
如何判别使用快速和慢速模式的时机?
- 处理链表或数组中的循环的问题
- 当你需要知道特定元素的位置或链表的总长度时
何时应该优先选择这种方法,而不是上面提到的二指针方法?
- 有些情况不适合使用二指针方法,比如在不能反向移动的单链接链表中。使用快速和慢速模式的一个案例是当你想要确定一个链表是否为回文(palindrome)时。
下面是一些满足快速和慢速指针模式的问题:
- 链表循环(简单)
- 回文链表(中等)
- 环形数组中的循环(困难)
4.合并区间
合并区间模式是一种处理重叠区间的有效技术。
在很多涉及区间的问题中,你既需要找到重叠的区间,也需要在这些区间重叠时合并它们。该模式的工作方式为:
给定两个区间(a 和 b),这两个区间有 6 种不同的互相关联的方式:
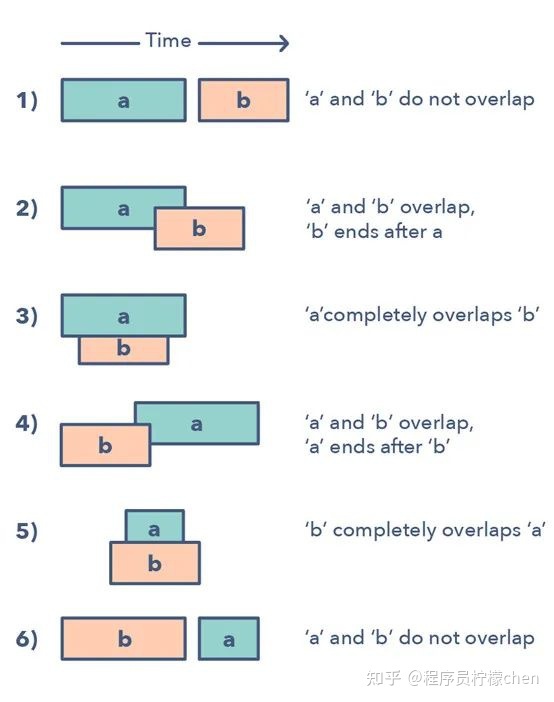
理解并识别这六种情况有助于你求解范围广泛的问题,从插入区间到优化区间合并等。
那么如何确定何时该使用合并区间模式呢?
- 如果你被要求得到一个仅含互斥区间的列表
- 如果你听到了术语「重叠区间(overlapping intervals)」
合并区间模式的问题:
- 区间交叉(中等)
- 最大 CPU 负载(困难)
5. 循环排序
这一模式描述了一种有趣的方法,处理的是涉及包含给定范围内数值的数组的问题。
循环排序模式一次会在数组上迭代一个数值,如果所迭代的当前数值不在正确的索引处,就将其与其正确索引处的数值交换。
你可以尝试替换其正确索引处的数值,但这会带来 O(n^2) 的复杂度,这不是最优的,因此要用循环排序模式。
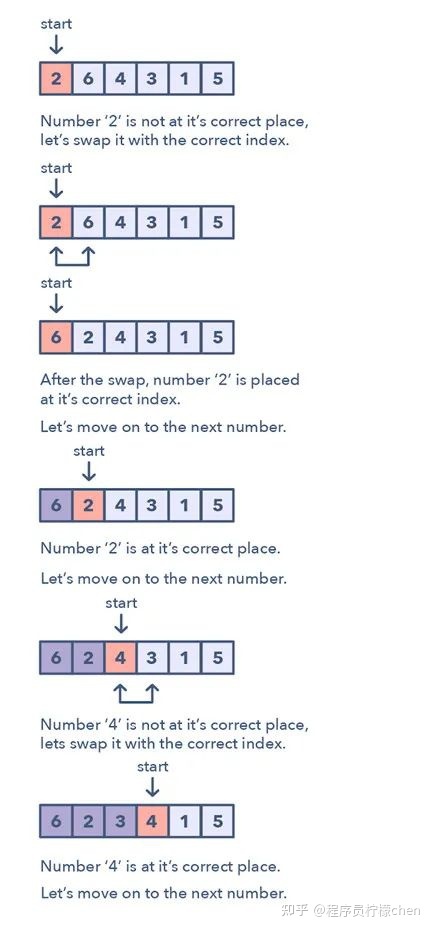
如何识别这种模式?
- 涉及数值在给定范围内的排序数组的问题
- 如果问题要求你在一个排序/旋转的数组中找到缺失值/重复值/最小值
循环排序模式的问题:
- 找到缺失值(简单)
- 找到最小的缺失的正数值(中等)
6. 原地反转链表
在很多问题中,你可能会被要求反转一个链表中一组节点之间的链接。
通常而言,你需要原地完成这一任务,即使用已有的节点对象且不占用额外的内存。这就是这个模式的用武之地。
该模式会从一个指向链表头的变量(current)开始一次反转一个节点,然后一个变量(previous)将指向已经处理过的前一个节点。
以锁步的方式,在移动到下一个节点之前将其指向前一个节点,可实现对当前节点的反转。
另外,也将更新变量「previous」,使其总是指向已经处理过的前一个节点。
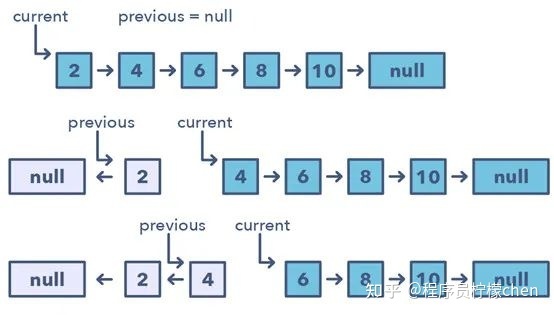
如何识别使用该模式的时机:
- 如果你被要求在不使用额外内存的前提下反转一个链表
原地反转链表模式的问题:
- 反转一个子列表(中等)
- 反转每个 K 个元素的子列表(中等)
7.树的宽度优先搜索(Tree BFS)
该模式基于宽度优先搜索(BFS)技术,可遍历一个树并使用一个队列来跟踪一个层级的所有节点,之后再跳转到下一个层级。
任何涉及到以逐层级方式遍历树的问题都可以使用这种方法有效解决。
Tree BFS 模式的工作方式是:将根节点推至队列,然后连续迭代知道队列为空。在每次迭代中,我们移除队列头部的节点并「访问」该节点。在移除了队列中的每个节点之后,我们还将其所有子节点插入到队列中。
如何识别 Tree BFS 模式:
- 如果你被要求以逐层级方式遍历(或按层级顺序遍历)一个树
Tree BFS 模式的问题:
- 二叉树层级顺序遍历(简单)
- 之字型遍历(Zigzag Traversal)(中等)
8.树的深度优先搜索(Tree DFS)
Tree DFS 是基于深度优先搜索(DFS)技术来遍历树。
你可以使用递归(或该迭代方法的技术栈)来在遍历期间保持对所有之前的(父)节点的跟踪。
Tree DFS 模式的工作方式是从树的根部开始,如果这个节点不是一个叶节点,则需要做两件事:
- 1.决定现在是处理当前的节点(pre-order),或是在处理两个子节点之间(in-order),还是在处理两个子节点之后(post-order)
- 2.为当前节点的两个子节点执行两次递归调用以处理它们
如何识别 Tree DFS 模式:
- 如果你被要求用 in-order、pre-order 或 post-order DFS 来遍历一个树
- 如果问题需要搜索其中节点更接近叶节点的东西
Tree DFS 模式的问题:
- 路径数量之和(中等)
- 一个和的所有路径(中等)
9.Two Heaps
在很多问题中,我们要将给定的一组元素分为两部分。
为了求解这个问题,我们感兴趣的是了解一部分的最小元素以及另一部分的最大元素。这一模式是求解这类问题的一种有效方法。
该模式要使用两个堆(heap):一个用于寻找最小元素的 Min Heap 和一个用于寻找最大元素的 Max Heap。
该模式的工作方式是:
先将前一半的数值存储到 Max Heap,这是由于你要寻找前一半中的最大数值。然后再将另一半存储到 Min Heap,因为你要寻找第二半的最小数值。在任何时候,当前数值列表的中间值都可以根据这两个 heap 的顶部元素计算得到。
识别 Two Heaps 模式的方法:
- 在优先级队列、调度等场景中有用
- 如果问题说你需要找到一个集合的最小/最大/中间元素
- 有时候可用于具有二叉树数据结构的问题
Two Heaps 模式的问题:
- 查找一个数值流的中间值(中等)
10.子集
很多编程面试问题都涉及到处理给定元素集合的排列和组合。
子集(Subsets)模式描述了一种用于有效处理所有这些问题的宽度优先搜索(BFS)方法。
该模式看起来是这样:
给定一个集合 [1, 5, 3]
- 1. 从一个空集开始:[[]]
- 2.向所有已有子集添加第一个数 (1),从而创造新的子集:[[], [1]]
- 3.向所有已有子集添加第二个数 (5):[[], [1], [5], [1,5]]
- 4.向所有已有子集添加第三个数 (3):[[], [1], [5], [1,5], [3], [1,3], [5,3], [1,5,3]]
下面是这种子集模式的一种视觉表示:
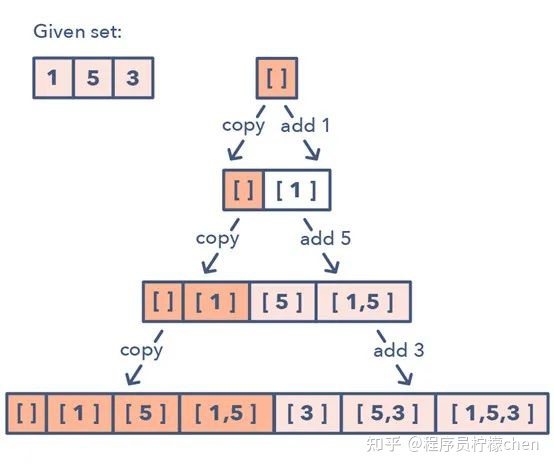
如何识别子集模式:
- 你需要找到给定集合的组合或排列的问题
子集模式的问题:
- 带有重复项的子集(简单)
- 通过改变大小写的字符串排列(中等)
11.经过修改的二叉搜索
只要给定了排序数组、链表或矩阵,并要求寻找一个特定元素,你可以使用的最佳算法就是二叉搜索。
这一模式描述了一种用于处理所有涉及二叉搜索的问题的有效方法。
对于一个升序的集合,该模式看起来是这样的:
- 1.首先,找到起点和终点的中间位置。
寻找中间位置的一种简单方法是:middle = (start + end) / 2。
但这很有可能造成整数溢出,所以推荐你这样表示中间位置:middle = start + (end—start) / 2。 - 2.如果键值(key)等于中间索引处的值,那么返回这个中间位置。
- 3.如果键值不等于中间索引处的值:
- 4.检查 key < arr[middle] 是否成立。如果成立,将搜索约简到 end = middle—1【换行】5.检查 key > arr[middle] 是否成立。如果成立,将搜索约简到 end = middle + 1
下面给出了这种经过修改的二叉搜索模式的视觉表示:
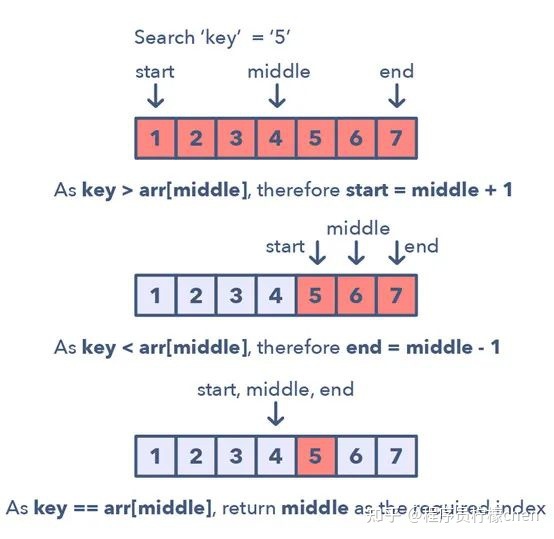
经过修改的二叉搜索模式的问题:
- 与顺序无关的二叉搜索(简单)
- 在经过排序的无限数组中搜索(中等)
12. 前 K 个元素
任何要求我们找到一个给定集合中前面的/最小的/最常出现的 K 的元素的问题都在这一模式的范围内。
跟踪 K 个元素的最佳的数据结构是 Heap。
这一模式会使用 Heap 来求解多个一次性处理一个给定元素集中 K 个元素的问题。
该模式是这样工作的:
- 1.根据问题的不同,将 K 个元素插入到 min-heap 或 max-heap 中
- 2.迭代处理剩余的数,如果你找到一个比 heap 中数更大的数,那么就移除那个数并插入这个更大的数
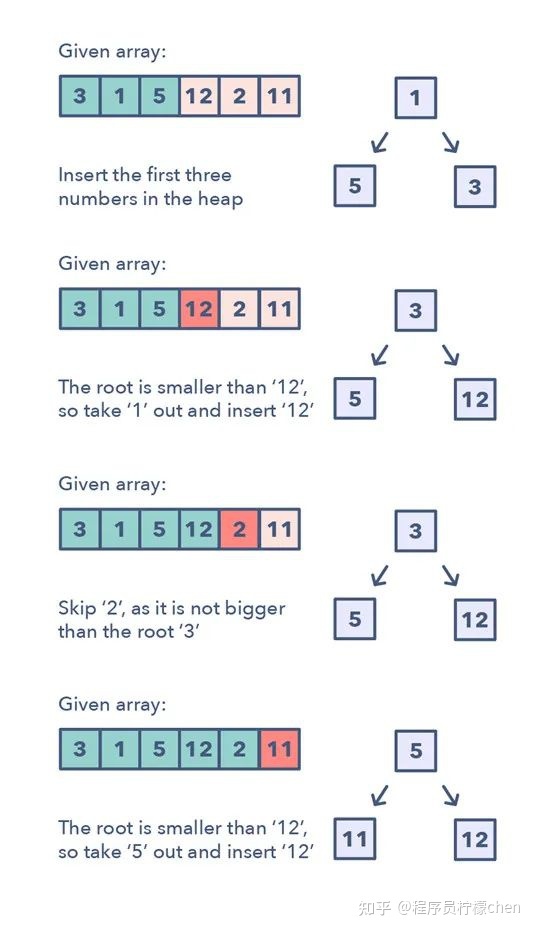
这里无需排序算法,因为 heap 将为你跟踪这些元素。
如何识别前 K 个元素模式:
- 如果你被要求寻找一个给定集合中前面的/最小的/最常出现的 K 的元素
- 如果你被要求对一个数值进行排序以找到一个确定元素
前 K 个元素模式的问题:
- 前面的 K 个数(简单)
- 最常出现的 K 个数(中等)
13. K 路合并
K 路合并能帮助你求解涉及一组经过排序的数组的问题。
当你被给出了 K 个经过排序的数组时,你可以使用 Heap 来有效地执行所有数组的所有元素的排序遍历。你可以将每个数组的最小元素推送至 Min Heap 以获得整体最小值。
在获得了整体最小值后,将来自同一个数组的下一个元素推送至 heap。
然后,重复这一过程以得到所有元素的排序遍历结果。
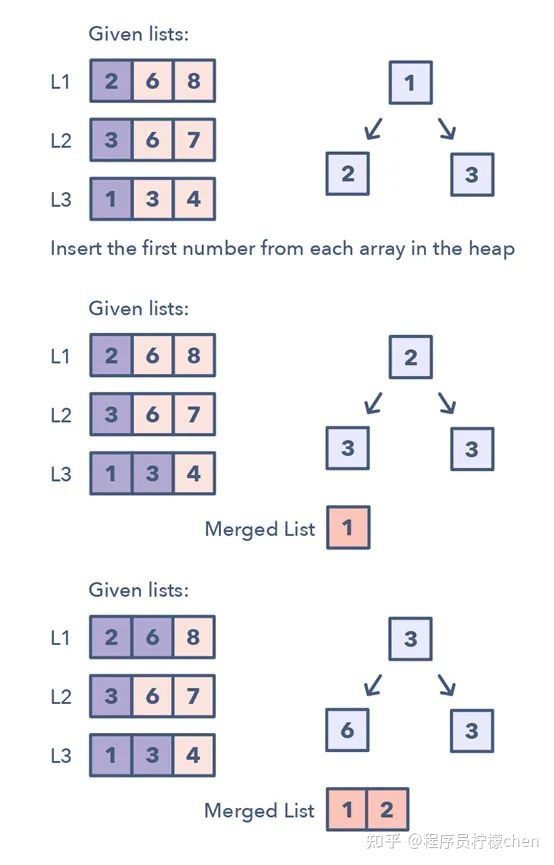
该模式看起来像这样:
- 1.将每个数组的第一个元素插入 Min Heap
- 2.之后,从该 Heap 取出最小(顶部的)元素,将其加入到合并的列表。
- 3.在从 Heap 移除了最小的元素之后,将同一列表的下一个元素插入该 Heap
- 4.重复步骤 2 和 3,以排序的顺序填充合并的列表
如何识别 K 路合并模式:
- 具有排序数组、列表或矩阵的问题
- 如果问题要求你合并排序的列表,找到一个排序列表中的最小元素
K 路合并模式的问题:
- 合并 K 个排序的列表(中等)
- 找到和最大的 K 个配对(困难)
14. 拓扑排序
拓扑排序可用于寻找互相依赖的元素的线性顺序。
比如,如果事件 B 依赖于事件 A,那么 A 在拓扑排序时位于 B 之前。
这个模式定义了一种简单方法来理解执行一组元素的拓扑排序的技术。
该模式看起来是这样的:
- 1.初始化。
a)使用 HashMap 将图(graph)存储到邻接的列表中;
b)为了查找所有源,使用 HashMap 记录 in-degree 的数量 - 2.构建图并找到所有顶点的 in-degree。
a)根据输入构建图并填充 in-degree HashMap - 3.寻找所有的源。
a)所有 in-degree 为 0 的顶点都是源,并会被存入一个队列 - 4.排序。
a)对于每个源,执行以下操作:i)将其加入到排序的列表;
ii)根据图获取其所有子节点;
iii)将每个子节点的 in-degree 减少 1;
iv)如果一个子节点的 in-degree 变为 0,将其加入到源队列。b)重复 (a),直到源队列为空。

如何识别拓扑排序模式:
- 处理无向有环图的问题
- 如果你被要求以排序顺序更新所有对象
- 如果你有一类遵循特定顺序的对象
拓扑排序模式的问题:
- 任务调度(中等)
- 一个树的最小高度
算法刷题笔记和网站
刷题算法还可以参考这篇刷题笔记,我当初在准备各大公司技术笔试的时候刷了大量的算法题,其中就有参考这本谷歌大神的LeetCode刷题笔记,帮我整理了解题思路,归纳了出刷题方法,非常不出错。

笔记我整理在专栏文章中,需要可以自行获取,码字分享不易,拿完别忘了给我点赞哦!

最后,如果你想成为一名基础扎实的计算机软件工程师,我是建议不要局限在C++这一门语言上,眼界要开阔一些,要对整个计算机技术体系有了解,那如何成为一名知识全面的软件工程师呢?无他,也是多看书,多动手,这里也有一份书单:

算法可视化网站,让算法动起来
另外,很多时候算法的抽象是最难理解的部分,幸运的是现在可以借助算法可视化工具来辅助理解,这点比我当初学算法的时候好太多,这些可视化工具也是我最近才发现,并收集起来的,现在全部分享给大家。
作为一个过来人,我初学数据结构与算法直接是啃的大学教材,这样的学习方式不是适合所有人。
尤其是编程基础比较差的同学,后来我找到了「捷径」学习方法,如果算法和数据结构能够以动画的形式呈现,那该多好。
这就是算法可视化,下面就来分享几个关于算法和数据结构可视化的网站和项目。
Data Structure Visualizations
这个网站最大的特点就是对数据结构的展示。你可以直观的查看基础数据结构,比如数组、链表、队列、二叉树等的创建、删除、查找过程,都是以动画的形式展现,并且这个过程可以参与交互的,比如插入一个数字到二叉搜索树,你可以控制输入参数,直观查看各种数据结构的构造和删除过程。
用动画和交互的方式帮助加深对各种数据结构的理解。

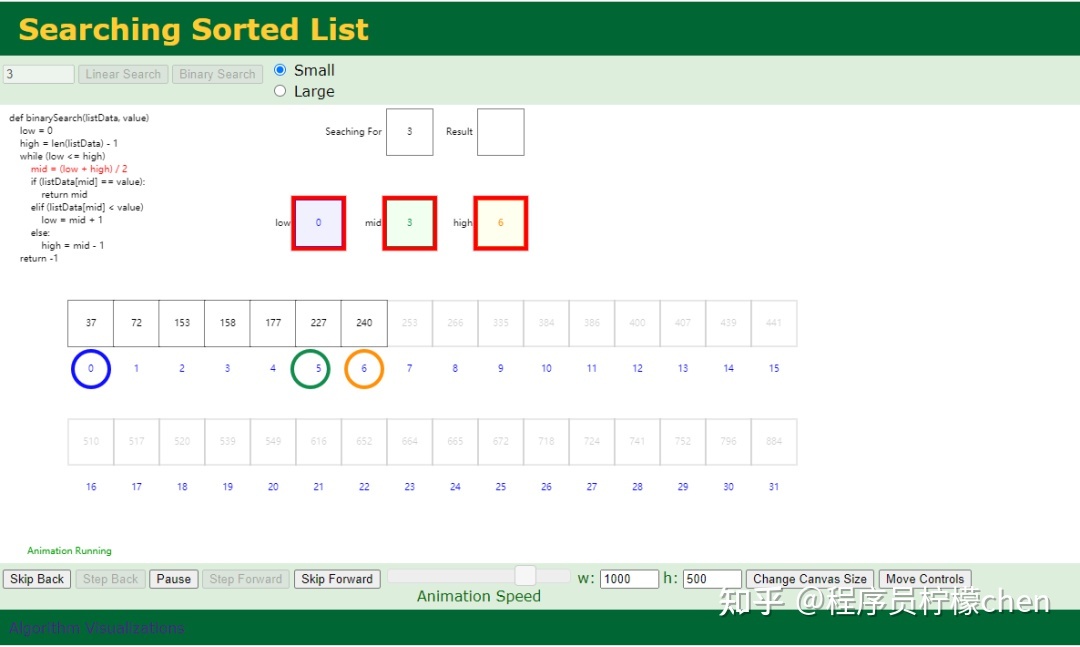
链接:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
visualgo
这也是一个数据结构和算法动态可视化网站,最大的优点是支持中文,并且支持对算法的详细说明和讲解,也可以查看算法的执行过程。
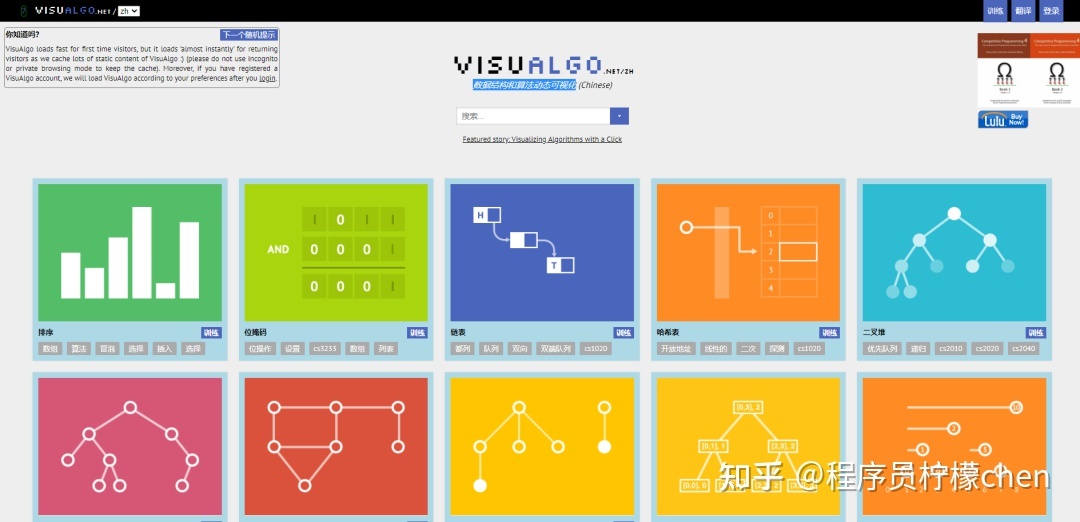
链接:https://visualgo.net/zh
algorithm-visualizer
又一个算法可视化网站,这个网站的特点是界面看起来比前两个清爽,不过不支持中文,这个也不是什么大问题,主要是它提供了算法实现代码,并且可以支持Java、JS、C++等多种语言,并且执行过程和速度可控制,还能暂停播放,在控制台也能看到算法执行输出的中间结果,我感觉用起来还是比较舒服。
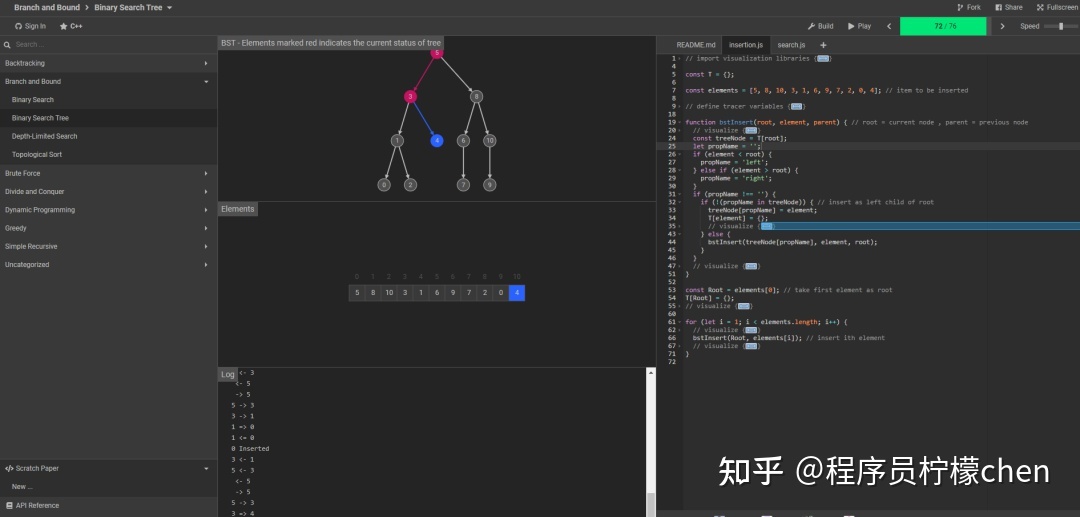
链接:https://algorithm-visualizer.org/
算法动画图解
上面介绍的是一些可视化网站,算法图解还要推荐吴师兄的算法动画开源项目,这个项目致力于动画图解算法,把解法按 LeetCode 题号排序,用动画的形式呈现解题目的思路,目前已经完成了大部分 LeetCode 原题的动画题解展示,动画制作和整理非常用心,如果哪天刷到一道难以理解的题,不妨来这个项目找找灵感,下面是部分题解动画截图展示。
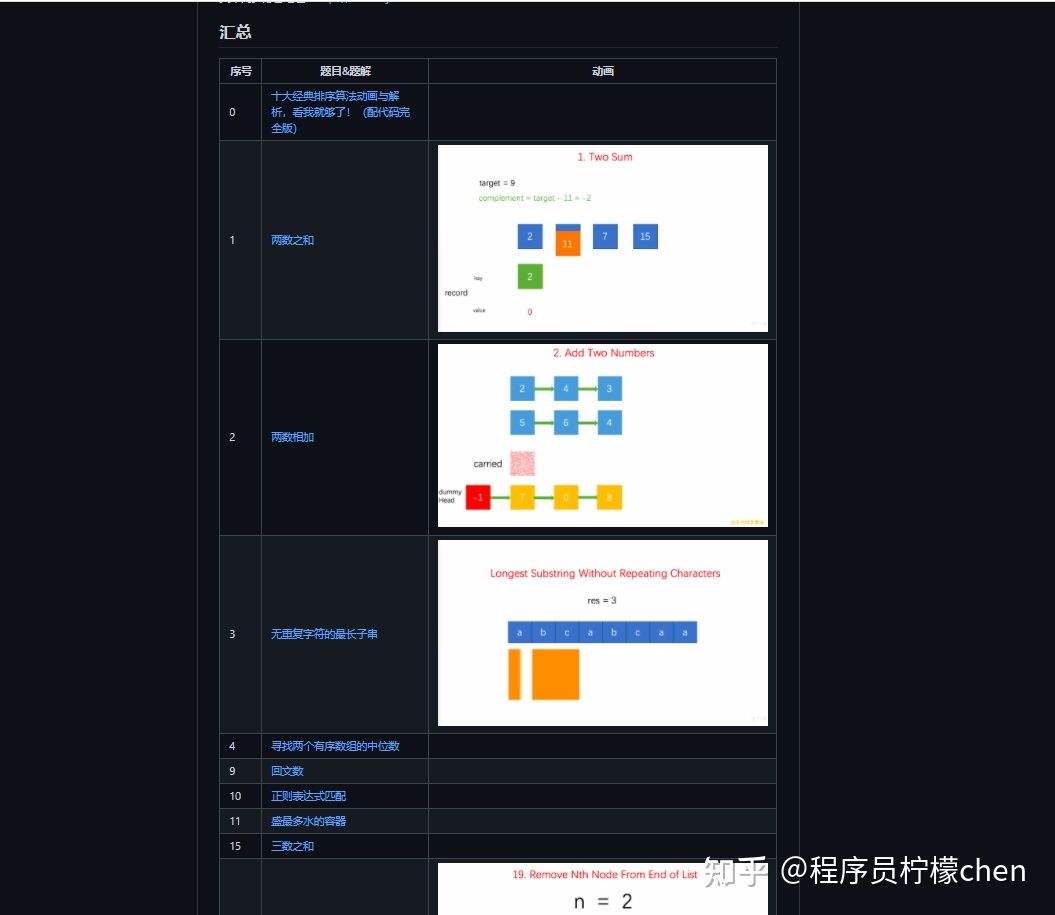
链接:https://github.com/MisterBooo/LeetCodeAnimation
今天分享就这么多,算法可视化,算法不可怕。原文最初发布在我的博客平台,可在下面查看:

磨刀不误砍柴工
本来写到这里差不多是写完了,突然我又想起一件事,是一个刷题插件,虽然不是什么刷题方法,但正所谓磨刀不误砍柴工,挑一件趁手的兵器能提高刷题欲望,就像我会为了多写代码,买一个很贵的机械键盘(并不是)。
经常在 Leetcode 刷算法的同学知道,如果在网站上直接刷题的话,没购买会员是不提供自动补全和语法检查的,这点非常不友好。
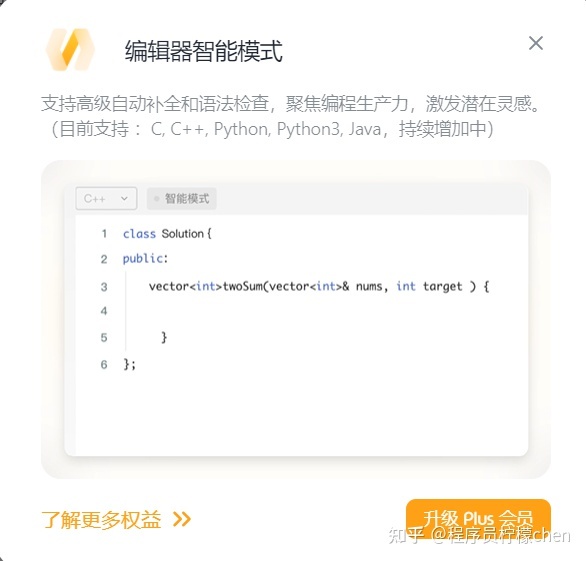
但是,也有办法可以免费体验这些功能,那就是VSCode LeetCode 官方插件。
关注我比较久的同学应该都知道,我是VSCode重度爱好者,曾经写的下面这篇VSCode插件推荐回答,被收藏 2千多次,点赞也接近 1 K,还没体验过得同学,一定要去试试,绝不吃亏!
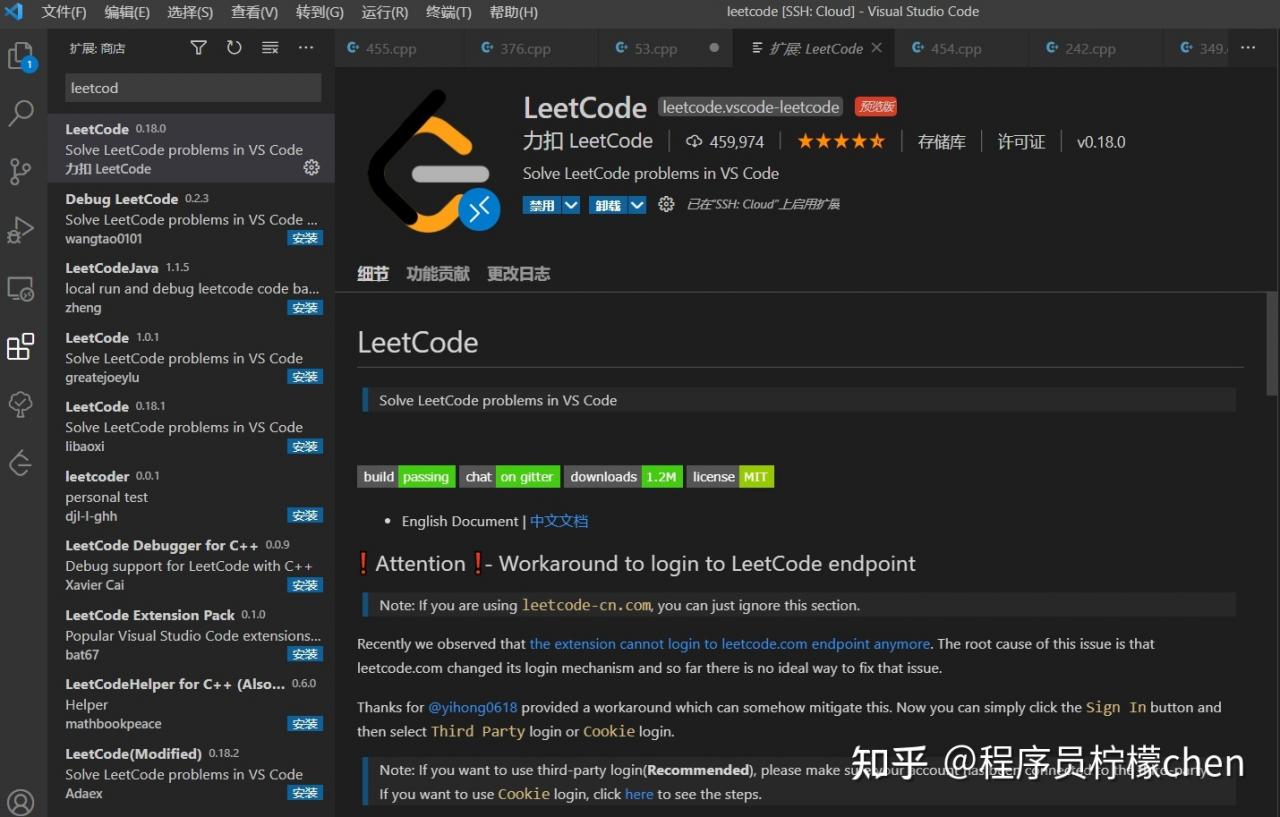
安装下面,这个刷题插件,你就能在VSCode中愉快的刷题了,也就能体验VSCode提供的代码自动补全和语法检查,真是不要太爽,刷题停不下来!
说到刷题,经历过得人都懂,那是一段痛并快乐的经历。坚持不下去的时候,告诉自己今天的坚持,明天会是真金白银的回报,是不是又有动力了呢?
没办法,如今360行,行行都转码,算法这座大山,你务必给我翻过去!
每天进步一点点,慢一点才能更快。
加油!
好了,今天的分享就到这里。洋洋洒洒写了将近一万字,早餐还没来得及去吃。

我是 @程序员柠檬 ,专注分享编程学习知识!
更多干货文章,欢迎关注我的专栏:

如果文章对你有帮助,或是解决了你的问题。
收藏之前帮点个赞同和感谢,或者分享给更多需要的小伙伴呀~

2.22.3.30日23:33更新
最近几天这个回答阅读3.4万人了,每天都有几十个点赞和感谢,评论区也很有意思,有些同学的评论也很有才华:
还有同学应该是被我真情实感的分享所打动,所我是是治愈答主,给你小花花~
承蒙大家厚爱!!!今天必须再来点干货,希望这个答案能帮助到更多初学算法的同学少走弯路。
上干货!
github上也有一些优秀的刷题资源,比如我当初刷题也参考了下面这个项目:algorithm-pattern 练习题
对于一些不方便访问github的同学,不用担心,这个项目的说明文档我帮你引用过来,可以看下:
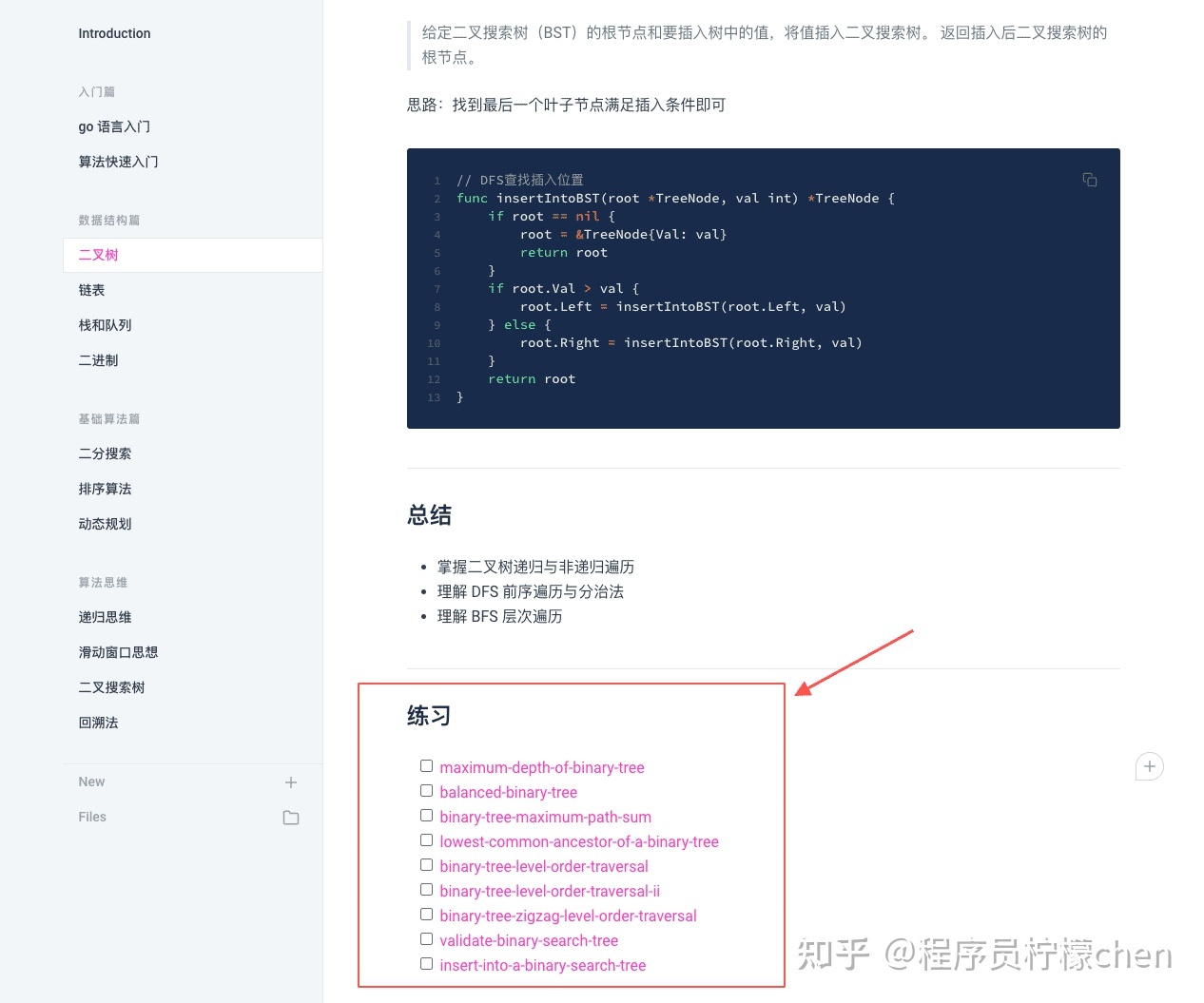
这个项目里面的题目也是是按类型归类,都是一些常见的高频题,很有代表性,大部分都是可以用模板加一点变形做出来,刷完后对大部分题目有基本的认识。
然后刷一遍探索卡片,巩固一下一些基础知识点,总结这些知识点。最后剑指 offer 是大部分公司的出题源头,刷完面试中基本会遇到现题或者变形题,基本刷完这三部分,大部分国内公司的面试题应该就没什么问题了~
2、 LeetCode 卡片
3、 剑指 offer
刷题时间可以合理分配,如果打算准备面试了,建议前面两部分 一个半月 (6 周)时间刷完,最后剑指 offer 半个月刷完,边刷可以边投简历进行面试,遇到不会的不用着急,往模板上套就对了,如果面试官给你提示,那就好好做,不要错过这大好机会~
注意点:如果为了找工作刷题,遇到 hard 的题如果有思路就做,没思路先跳过,先把基础打好,再来刷 hard 可能效果会更好~
今天就补充这些,有新的刷题资源我会补充进来,持续更新~~ 我是
今天你刷题了吗?