网络爬虫是如何爬取网页的?
链接:https://www.zhihu.com/question/434794176/answer/2635226217
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
目标:掌握定向网络数据爬取和网页解析的基本能力
- requests自动爬取HTML页面、自动网络请求提交
- robots.txt网络爬虫排除协议
- Beautiful Soup解析html页面
- Re正则表达式详解,提取页面关键信息
- Scrapy网络爬虫原理介绍、专业爬虫框架介绍
python语言开发工具
该专题中使用四种工具:
- 文本工具类IDE
- IDLE
自带的,简单入门 - Sublime Text
第三方专用编程工具 - 集成工具类
- pycharm
- Anaconda & Spyder
第一周单元1:requests库入门
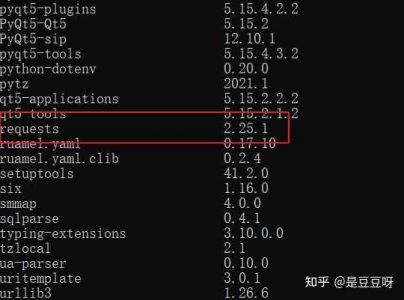
Requests库的安装
安装命令:pip install requests,我检查我的pip list,可以看到已经安装过了,
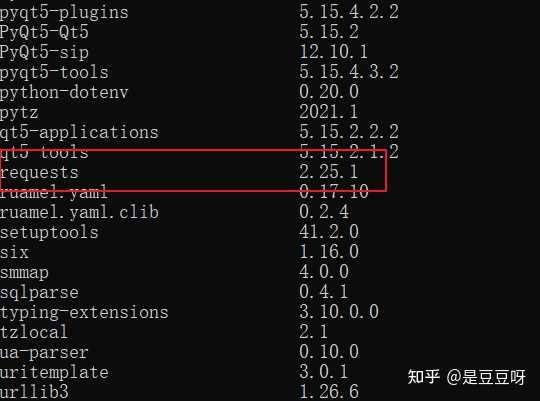
在IDLE中一个例子:
爬取百度网站首页
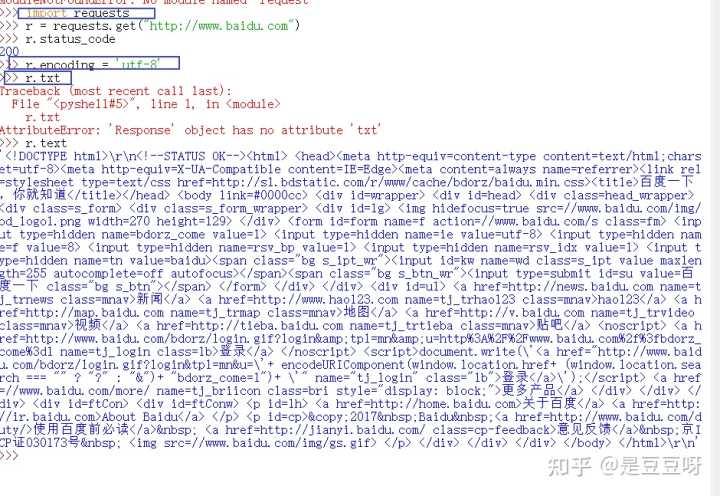
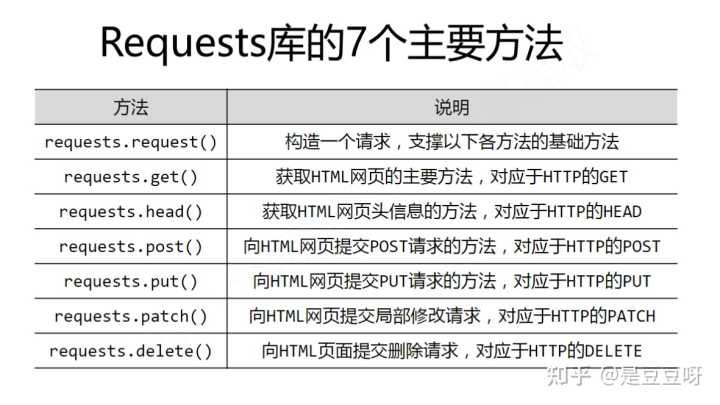
requests库的7个主要方法
可以认为其他六个方式是调用request方法来封装的
get()方法
- 构造一个向服务器请求资源的Request对象
- r返回一个包含服务器资源的Respponse对象
完整的get()3个参数:`requests.get(ur;, params=None, **kwargs)
- url拟获取的页面的url链接
- params:url中的额外参数,字典或者字节流格式,可选
- **kwargs:12个可访问控制的参数
返回的Response对象
包含爬虫返回的网页内容
response对象的属性
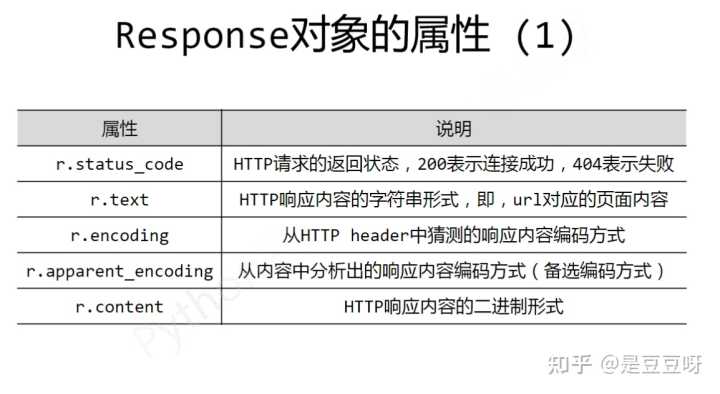
理解Response的编码:

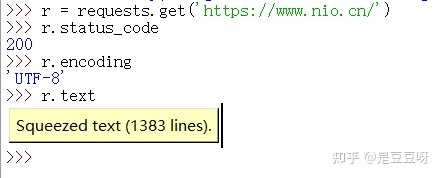
小小的实战一下:爬取蔚来汽车官网
爬取网页的通用代码框架
request库常用的6中连接异常
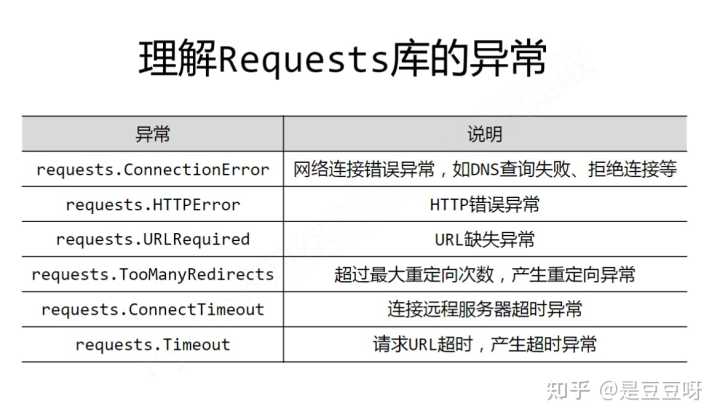
还有一个r.raise_for_status,该方法可判断状态码是否是200,不是200则可以利用try-except进行异常处理
通用代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() #如果不是200,则引发HTTPError异常
r.encoding = r.apparent_encoding
except:
return "产生异常"使用:
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))http协议及requests库的主要方法
HTTP超文本传输协议,基于“请求与响应”模式的、无状态的应用层协议
采用url作为定位网络资源的标识,URL格式如下:http://host[:port][paath],
- host:合法的主机域名或ip地址
- port:端口号,默认80
- patah:请求资源的路径
HTTP URL的理解:URL是HTTP协议存取资源的internet路径,一个URL对应一个数据资源
HTTP对资源的操作
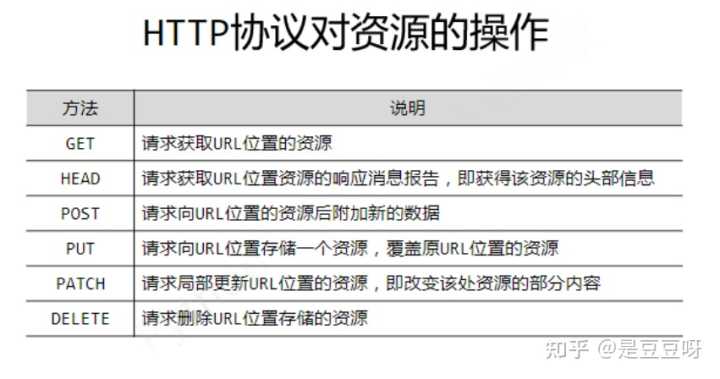
以上方法对应requests库中的方法,其中局部修改patch优点是节省网络带宽
post方法根据用户提交的内容的不同,在服务器上作相关整理,例如提交字典或者键值对,会默认存储到表单form字段下, 若是字符串等,会提交到data字段下,
requests库主要方法
1)requests.request
requests.request(method, url, **kwargs),
method:请求方式
有’GET’、’POST’等等
**kwargs:访问控制参数
- params
字典或字节序列,作为参数增加到url中 - data
字典、字节序列或文件对象,作为Request的内容 - json
json格式数据,作为内容 - headers
字典,HTTP定制头 - files:字典类型,传输文件
fs = {'files': open('data.xls', 'rb')}
r = requests.request('POST', 'http://python123.io/ws', files = fs)- proxies:字典类型,设定访问代理服务器,可增加登录认证,可隐藏用户爬取的源的id信息,防止对爬取的逆追踪
- 等等……
作为爬虫功能最常用使用get,还可以掌握head方法
第一周单元2:网络爬虫的盗亦有道
网络爬虫的尺寸
- 爬取网页,玩转网页:小规模,数据量小爬取速度不敏感,可以使用requests库
- 爬取网站,爬取系列网站:中规模的,数据规模较大爬取速度敏感,可以使用scrapy库,
- 爬取全网:大规模,搜索引擎,爬取速度关键,
网络爬虫的风险
- 对服务器的“骚扰”
- 带来法律问题
- 带来隐私泄露
网络爬虫的限制
- 来源审查:限制user-agent,代理
- 发布公告:robots.txt
Robots协议
全称:Robots Exclusion Standard 网络爬虫排除标准
作用:告知哪些可以爬取,
形式:在网站根目录下的robots.txt文件
例如:新浪的Robots协议,
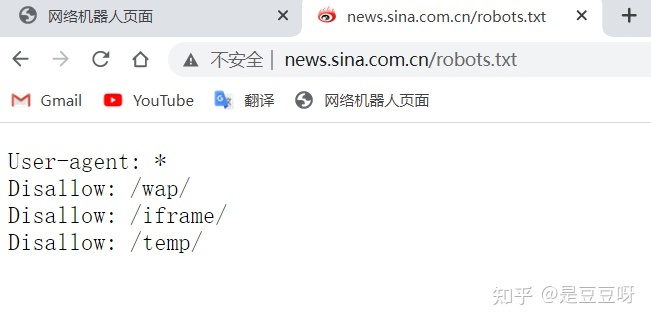
蔚来汽车的robots协议:https://www.nio.cn/robots.txt
语法:User-agent、Disallow
Robots协议的遵守方式
协议使用:
- 网络爬虫:自动或人工识别robots.txt,再进行爬取
- 可以不遵守但又法律风险
第一周单元3:Requests库网络爬取实例
实例1:京东商品页面的爬取
网站:https://item.jd.com/2967929.html
使用IDLE

全代码:
import requests
url = 'https://item.jd.com/2967929.html'
try:
r = requests.get(url)
r.raise_for_status()
r.encoding =r.apparent_encoding
print(r.text[:1000])
except:
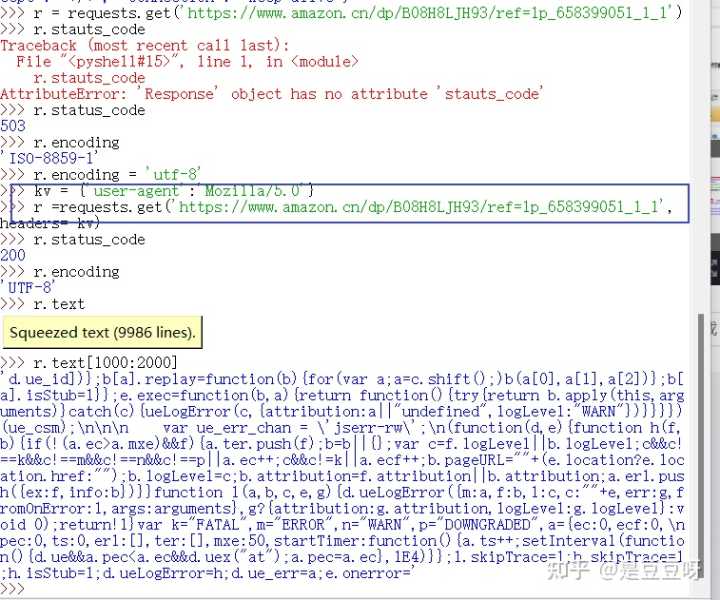
print("爬取失败")实例2:亚马逊商品页面的爬取
网站:https://www.amazon.cn/gp/product/B01M8L5Z3Y
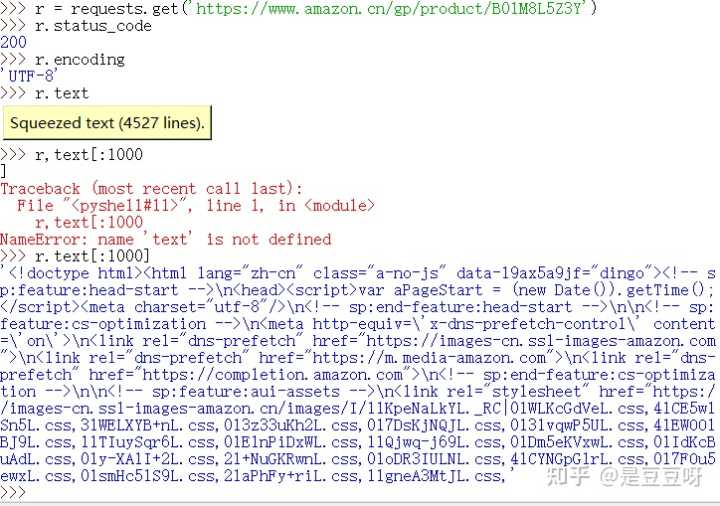
如果请求失败
可以使用r.request.headers查看我们访问的请求头

可以看到User-agent是由python的requests库发送,我们可以通过header字段让代码模拟浏览器向访问的服务器提供请求
全代码
import requests
url = 'https://www.amazon.cn/gp/product/B01M8L5Z3Y'
try:
kv = {'user-agent': 'Mozilla/5.0'}
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[1000:2000])
except:
print('爬取失败')试着试一试另外一款商品:
实例3:百度、360搜索关键词提交
实现用提交关键词并获取到搜索关键词后的结果
看一下两个搜索的关键词提交接口:
http://www.baidu.com/s?wd=keyword
http://www.so.com/s?q=keyword
因此使用requests库构建这样的url即可,使用参数params向url中添加内容,

注意上图中使用response对象中包含的request对象信息来查看实际请求的url是什么
可以查看获取内容的长度:

实例4:网络图片的爬取和存储
网络图片链接的格式:http://www.example.com/picture.jpg,
例如随便照一张图片并查看属性获取真实地址:https://images-cn.ssl-images-amazon.cn/images/I/71mMZG+V2US.AC_SX679.jpg,以jpg结尾说明是一个图片链接,并且是一个文件,接下来就是自动爬取并保存
首先要告知保存在本机的路径,使用path,获取到之后保存的方法:(图片是二进制格式)
with open(path, 'wb') as f:
f.write(r.content)以上就是打开path路径,并定义为文件标识符f,然后将r.content表示二进制形式写入
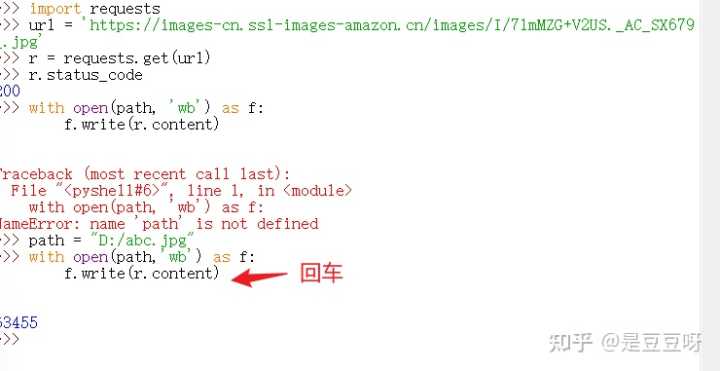
如图爬取到的图片:
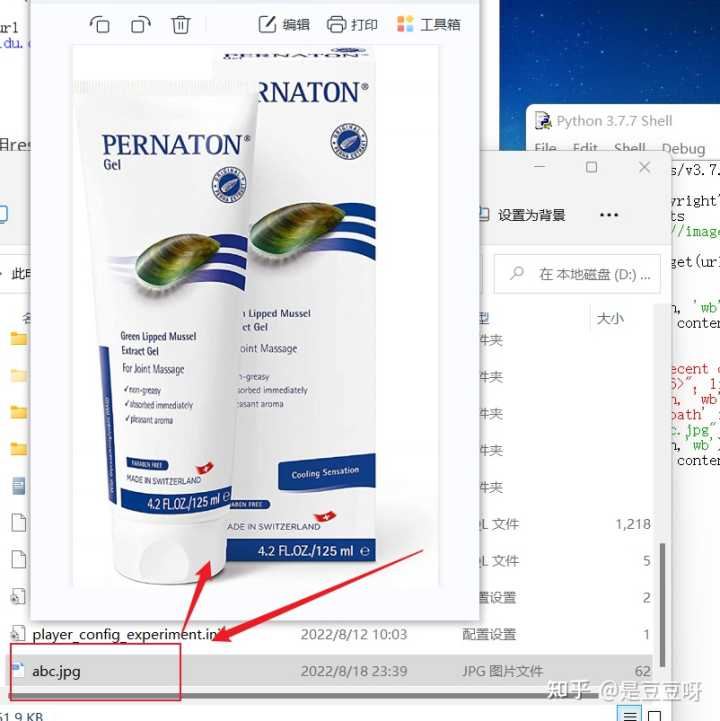
那么想要获取图片后使用图片原来的名字存储到本地,可以使用截取,
下面使用全代码重新试一下:
图片地址:https://images-cn.ssl-images-amazon.cn/images/I/61KRwYQ247L.AC_SY879.jpg
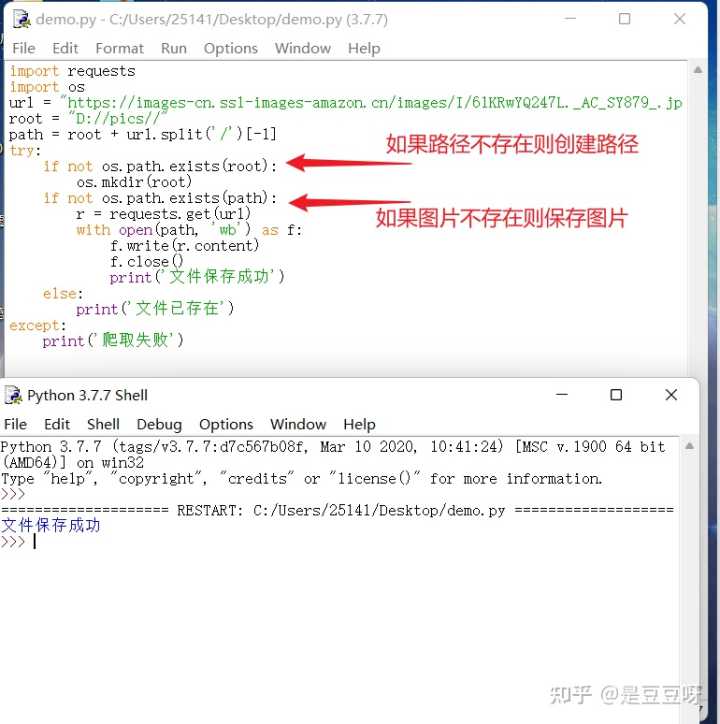
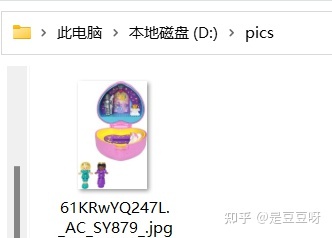
如上图保存成功,可以查看到图片
实例5:ip地址归属地的自动查询
可以使用ip138查询ip归属地
在程序中如何提交ip地址,可以发现提交ip地址的链接形式为http://m.ip138.com/ip.asp?ip=ipaddress
以爬虫角度看待网络内容
第二周单元:4:beautiful soup库入门
Beautiful Soup第三方库,对html xml格式进行解析,
安装Beautiful库
使用管理员权限打开命令行,执行语句pip install beautifulsoup4,
如何使用呢:
from bs4 import BeautifulSoup //导入的Beautiful类
soup = BeautifulSoup('<p>data</p>', 'html.parser') //解析html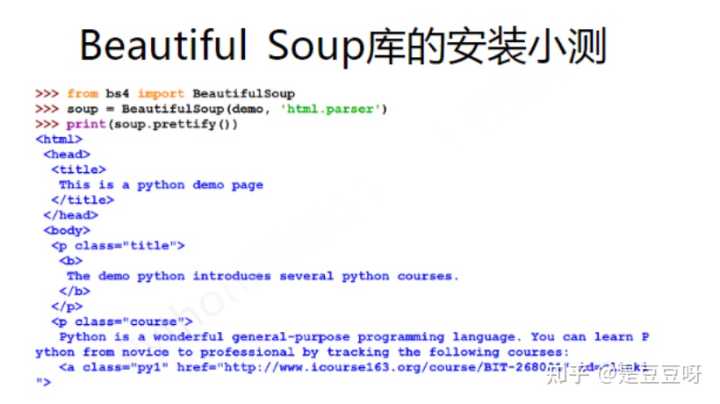
Beautiful库的基本元素
BeautifulSoup库(bs4库)是解析、遍历、维护标签树的功能库
标签里包含多个属性域,
常用引入方式:from bs4 import BeautifulSoup,直接引用import bs4,
可以认为html文档与标签树与BeautifulSoup类是对等的,把Beautiful类当做对应一个HTML或xml文档的全部内容
BeautifulSoup库的解析器
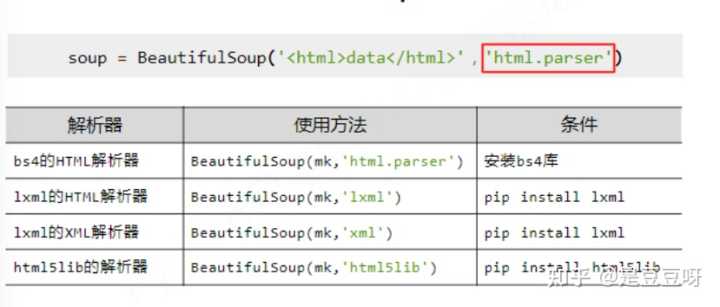
无论哪种,都可以解析html、xml文档,主要使用html解析器,
BeautifulSoup类的基本元素
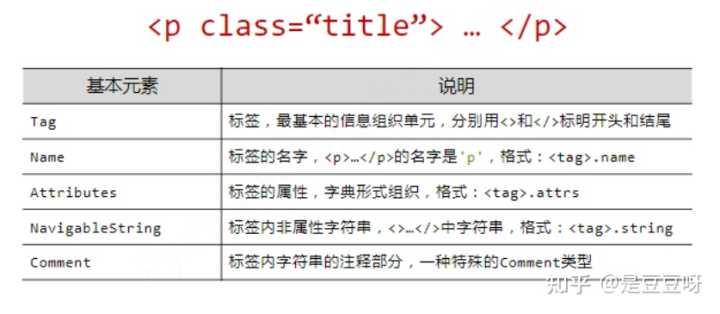
基于bs4库的HTML内容遍历方法
BeautifulSoup库是对标签树的功能的遍历集合,
将所有的遍历功能分为:上行遍历、下行遍历、平行遍历三中方式
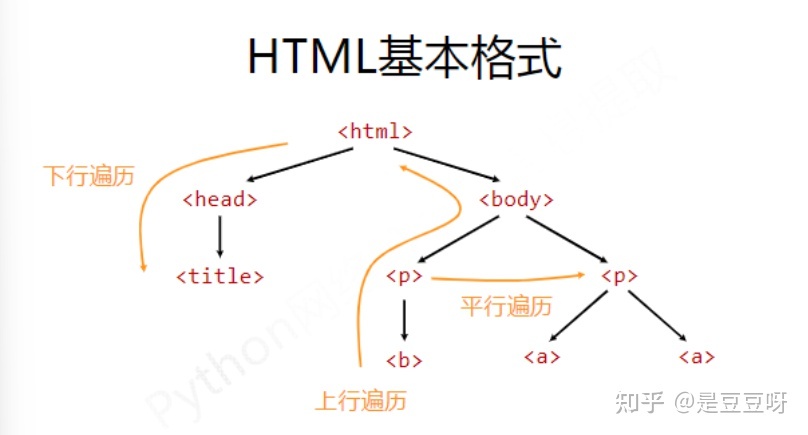
- 下行遍历

- 上行遍历

- 平行遍历

平行遍历发生在同一个父节点下的各节点间
平行遍历的下一个节点不一定是标签类型,
基于bs4库的HTML格式化和编码
如何让html页面更加友好的显示?
例子:地址http://www.robotstxt.org/robotstxt.html

然后赋值为demo,demo = r.text,
以上是将demo定义为soup变量,并使用prettify方法为html文本及内容增加换行符并进行处理
bs库编码默认为’utf-8′
第二周单元5:信息组织与提取方法
信息标记的三种形式
首先信息标记的作用:
- 标记后的信息可形成信息组织结构,增加了信息维度
- 标记的结构与信息一样具有重要价值
- 标记后的信息可用于通信、存储或展示
- 标记后的信息更利于程序理解和运用
例如HTML的信息标记;
那么信息标记的三种形式:
- XML:扩展标记语言,与html接近,先有html,后有xml

- JSON:有类型的键值对的信息表达方式,为key:value,字符串要有引号表示,一个键有多个值可以用[]表示,嵌套使用可以用{}表示,

- YAML:无类型键值对,用缩进形式表示所属关系,和python类似,用-号表达并列关系,用|表示整块数据

三种信息标记形式的比较
- XML:可扩展性好,但是较繁琐
- JSON:有类型信息,适合程序处理,较XML简洁,无法提现注释
- YAML:无类型,文本信息比例最高,可读性好,有注释
信息提取的一般方法
从标记后的信息中提取内容,其一般方法:
- 完整解析信息的标记形式,再提取关键信息
- 无视标记形式,直接搜索关键信息,利用查找函数查找,缺乏准确性
融合方法:结合形式解析与搜索,需要标记解析器、文本查找函数
实例:要求提取HTML中的URL链接,
我们可以:先搜索到所有a标签,再解析,然后提取链接内容
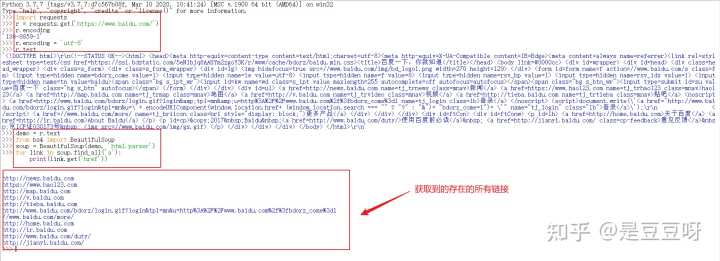
基于bs4库的html内容查找方法
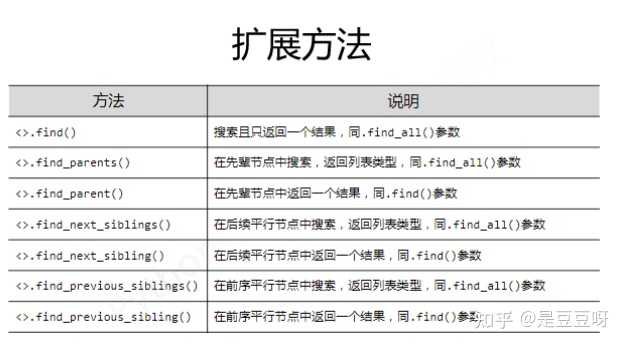
find_all(name, attrs, recursive, string, **kwargs),该方法可查找相关信息,

re为正则表达式库的含义;
简略表达

还有一些扩展方法
第二周单元6:实例1:中国大学排名爬虫
介绍:
写一个程序:实现输入为大学排名的url链接,输出为排名信息的输出,包括排名、名称、总分,
先看是否是html中存在的数据,而不是动态生成的,
链接:https://www.shanghairanking.cn/rankings/bcur/202211
可以看到是以tr等存放在页面中的,因此可以定向爬取,
再看robots协议,
可以爬取,可行性可以
那么思考一下程序的结构设计:
- 先爬取对应网页内容 ——》getHTMLText()
- 提取信息到合适的数据结构——》fillUnivList()
- 利用数据结构展示并输出——》printUnivList()
可以采取二维数据
实例编写
按照上述分析并编写函数及主函数,然后完善函数内容,
分析网页源码,可以发现tbody中包含tr标签,每个tr包含了每一个学校的信息,td包含相关信息,使用遍历及查找方法获得,
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
# 爬取内容并返回
try:
r = requests.get(url, timeout = 30)
r.raise_for_status() # 判断并产生异常信息
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
# 提取关键内容数据,并添加到列表中
soup = BeautifulSoup(html, 'html.parser')
for tr in soup.find('tbody').children:
# 每个tr就是一所大学对应的信息
# 过滤掉非标签类型的其他信息
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string,tds[2].string, tds[3].string])
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名", "学校名称", "总分"))
for i in range(num):
u = ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[2],u[3]))
def main():
uinfo = [] # 大学信息
url = 'https://www.shanghairanking.cn/rankings/bcur/202211'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 先列出20所学校第三周单元7:Re
正则表达式的概念
是用来简洁表达一组字符串的表达式,可以表达一组字符串特征,也可用来判断某字符串的特征归属,主要使用在字符串匹配中
正则表达式的使用
编译:将符合正则表达式语法的字符串转换成正则表达式特征,编译后的特征与一组字符串对应,编译前的正则表达式只是一个符合表达式的字符串
正则表达式的语法(注重)
由字符和操作符构成
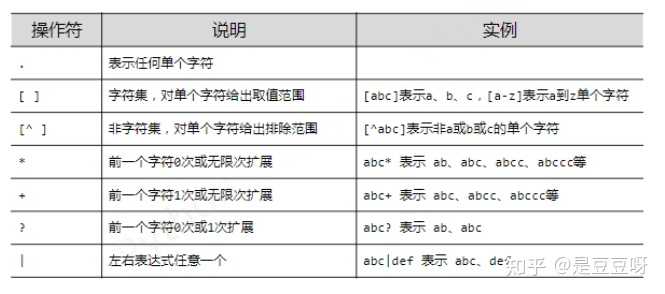
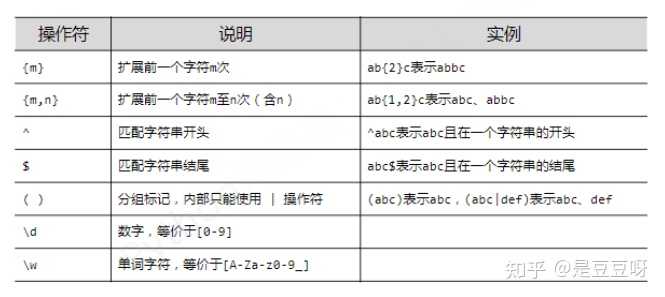
经典正则表达式实例
