python爬虫之验证码反爬识别– 图像验证码


有些网站为了避免网站被过度访问,通常会设置验证码反爬:如果访问次数过多就需要输入验证码,甚至说一开始访问的时候就需要输入验证码。这些网站通常是不希望被爬虫过度爬取的,而且有时还会经常更换验证码类型,因此本章对于大部分验证码反爬,我们特地自己搭建了本地网址(HTML文件),里面演示不同的验证码,然后教大家如何应对验证码反爬。
此外,注意有的网站不仅有验证码反爬,还可能有其他反爬手段(例如针对Selenium的这种难以处理的反爬),如果遇到这种情况,单纯的验证码反爬识别就会失效,本章主要还是讨论单纯的验证码反爬如何识别。
1、图像验证码
图像验证码是最常见的验证码反爬手段,图像验证码主要分为中文和英文验证码,中文验证码以简体汉字为主,英文验证码结合了英文字母和数字,二者如下图所示:


识别图像验证码的关键就是图像文字识别,其中Python有开源的库:PyTesseract,但是这个库识别效果很一般,遇到稍微复杂一点的图片就识别不出来;另外百度也提供了文字识别接口(每天可以免费调用一些次数),但是遇到稍微复杂一点的图片也识别不出来。
目前市面上笔者觉得最好的验证码识别平台是超级鹰网站,它是一个收费平台,但是也不贵,1块钱(对应平台的1000积分)可以识别约100次(如果只是练手,可以选择自定义充值1元,或者领取新用户的1000积分:新用户绑定微信也可以免费获取1000积分)。
这里因为超级鹰的识别效果最佳,且实战应用中最为有效,本节主要讲解超级鹰识别验证码的使用方法,在本节的补充知识点也会简单讲解百度文字识别的使用方法,至于PyTesseract库由于安装较为繁琐,虽然免费,但是识别效果很一般,所以本书不予讲解。
(1)超级鹰平台注册
超级鹰是一个专用的验证码识别平台,官方网站为https://www.chaojiying.com/,在网站右上角可以进行注册,超级鹰会为新用户提供数次免费识别的机会(下图左下角)。
注册完账户,并领取好上图右下角赠送的1000题分(题分就是积分)后,便可以在首页的免费测试版块:https://www.chaojiying.com/demo.html进行测试(虽然叫免费测试,但是需要领取完赠送的1000积分才可以测试)。读者可以自行搜索一些图片验证码或者利用本书源代码中提供的源代码进行测试。
(2)超级鹰Python使用
Python的官方文档网址为https://www.chaojiying.com/api-14.html,点击下载按钮下载官方示例,官方提供的代码是基于Python2版本的,需要根据下图的官方提示做些调整,为了方便读者使用,笔者已经将代码进行了调整(因为Python2的print()函数没有括号,所以主要就是print()函数后面加括号,以及把一些不规范的缩进取消再重新Tab缩进下),不愿意自己调整的读者可以直接从本书的源代码文件中下载使用。
解压文件后,里面有如下内容,这个chaojiying.py文件就是示例代码:

代码中主要定义了一个超级鹰的类:Chaojiying_Client(关于以下展示的代码不用深究,实际的使用方法等会会讲,非常简单,不需要理解下面代码的含义),官方是用Python2写的,笔者已经将其做过调整为Python3适用版本,代码如下仅供参考,简单看一眼即可:
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()在实际的使用过程中,我们并不需要管上面这一长串代码,我们只需要将笔者提供的这个调整好的chaojiying.py文件复制到你要编写代码的文件夹即可,如下图所示,其中a.png是我们要识别的图像验证码(这算是一个比较难以识别的图像验证码了),test.py文件是我们用来编写识别图像验证码代码的文件。

其中test.py中代码内容如下,我们通常只需要修改第4行代码的账号和密码。
from chaojiying import Chaojiying_Client
def cjy(): # 使用超级鹰识别
chaojiying = Chaojiying_Client('账号', '密码', '905908')
im = open('a.png', 'rb').read() # 本地图片文件路径,需要为a.png名字
code = chaojiying.PostPic(im, 1902)['pic_str']
return code # code作为函数返回值
result = cjy() # 调用函数,并将返回的结果赋值给result变量
print(result) # 打印识别的结果其中第1行代码是从chaojiying.py这个文件中引入Chaojiying_Client这个类,这个和之前学习的类的引用并无区别(例如from selenium import webdriver),直接照抄即可;
第3行定义了一个cjy()函数,函数具体内容下面将进行讲解;
其中第4行是输入账号、密码和软件ID,账号和密码自己注册即可(记得领取免费的积分),其中软件ID官方说是要去下图所示的用户中心 -> 左下方的软件ID -> 生成一个软件ID,不过笔者测试直接用官方给的96001也是没有问题,不太需要修改,笔者这边改成了自己的软件ID:905908,读者也可以直接使用这个ID,如果出现问题再自己生成一个ID即可。
第5行代码是打开本地图片路径,这里固定的写为a.png,如果有需要可以改成别的路径,此外这里用的是相对路径即代码所在文件夹(相对路径和绝对路径可参考本节补充知识点);
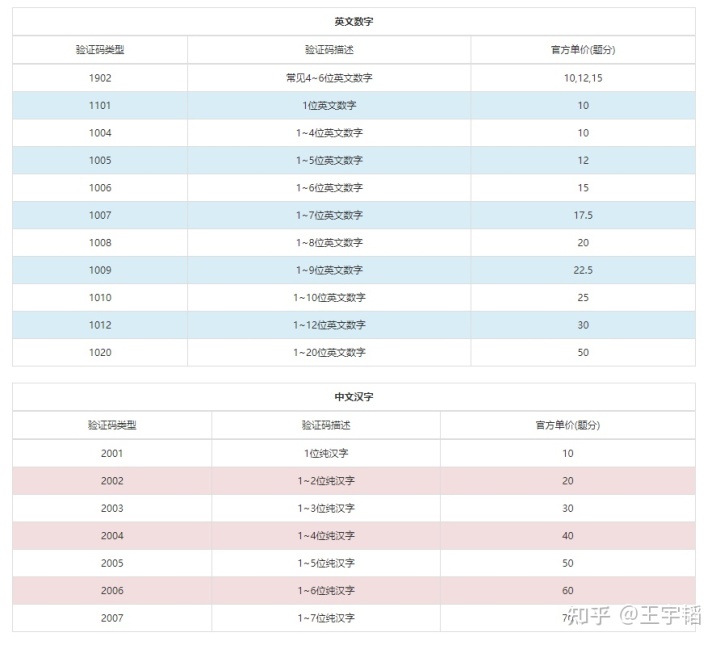
第6行代码调用PostPic()函数进行识别,这里唯一可能需要修改的就是验证码类型编号,这里采用的是1902,可以识别4-6位英文数字,如4位英文数字类型识别收费10题分(积分)。因为PostPic()函数返回的是一个下面所示的字典(其中键pic_str对应的就是识别结果),所以需要通过[‘pic_str’]提取验证码识别结果。
{'err_no': 0, 'err_str': 'OK', 'pic_id': '3109113154429900030', 'pic_str': 'tmmv', 'md5': '01c9211858c13e1f798183d530ec5657'}其他类型可以参考https://www.chaojiying.com/price.html,不同的验证码类型要使用不同的参数,4-6位英文数字官方推荐用1902,速度比1004快;官方价格:1元等于1000积分,能用100次,100元的话,就可以用10000次(官网也可以自定义充值),绰绰有余了。
第9-10行调用刚刚定义cjy()函数识别a.png文件并打印结果,如下所示:
tmmv可以看到识别正确,此外,如果不想复制文件并通过上面第一行代码引用类的方式进行操作,也可以把上面第1行代码换成chaojiying.py中那一大堆代码,下面的内容无需调整。
这里再总结下,其核心代码就是如下5行代码:
def cjy():
chaojiying = Chaojiying_Client('账号', '密码', '905908')
im = open('a.png', 'rb').read() # 本地图片文件路径
code = chaojiying.PostPic(im, 1902)['pic_str'] # 英文数字用1902
return code其实也可以通过如下代码直接使用超级鹰,之所以定义cjy()函数主要是为了之后案例实战的时候使用起来更方便些。
chaojiying = Chaojiying_Client('账号', '密码', '905908')
im = open('a.png', 'rb').read() # 本地图片文件路径
code = chaojiying.PostPic(im, 1902)['pic_str'] # 英文数字用1902
print(code)这里再补充一个有用的小技巧,如果不想每次写代码的时候都需要把chaojiying.py文件复制到代码所在文件夹的话,可将chaojiying.py文件复制到下图所示的Python(也就是第一章所讲的Anaconda)所在文件夹的Lib文件夹中(笔者的位置为:C:\Users\wangyt\Anaconda3\Lib)。当复制到下图所示的Lib文件夹(Lib是libaray(图书馆)的缩写,就是一个所有安装的库所在的文件夹)后,以后就可以像引用其他库一样,直接在代码中输入from chaojiying import Chaojiying_Client即可应用相关内容。
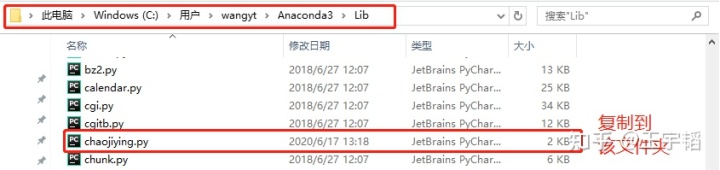
如果忘记自己Python的安装位置,可以通过Win + R键调出运行框,输入cmd后,在弹出框里输入where python查看当初的安装路径,如下图所示。

(3)简单案例实战
上面讲解了如何利用超级鹰来识别一个单独的验证码图片,那么对于实际的网站我们该如何操作呢,这里我们自己构建了一个本地的网页方便大家练习,实际案例实战可以参考上一章最后一节讲解的微博验证码识别登录,这里首先记得把上一节提到的chaojiying.py文件复制到该代码文件夹。
上面讲解了如何利用超级鹰来识别一个单独的验证码图片,那么对于实际的网站我们该如何操作呢,这里我们自己构建了一个本地的网页方便大家练习,在本章最后会提供一个实际的大案例(房天下爬取),这里首先记得把上一节提到的chaojiying.py文件复制到该代码文件夹。

如果不想每次都把chaojiying.py文件复制到代码所在文件夹,可以采用上一小节最后提到的方法,将chaojiying.py文件复制到下图所示的Python(也就是第一章所讲的Anaconda)所在文件夹的Lib文件夹中(笔者的位置为:C:\Users\wangyt\Anaconda3\Lib)
该文件夹中的index.html文件就是搭建的本地网站,打开后为一个网页文件,如下图所示:
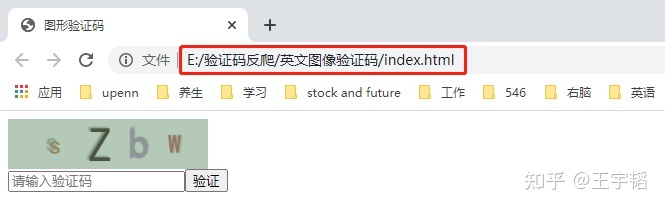
其中这个网址就是这个index.html的文件路径,可以看到这个网站上就是一个验证码图片,以及一个验证码输入框,和验证按钮。
对于实际的网页中的图像验证码,我们的操作步骤通常如下所示:
- 通过Selenium打开网页;
- 通过Selenium的screenshot()函数获取验证码图片;
- 通过cjy()函数识别图像中的内容;
- 通过Selenium模拟输入验证码,并模拟点击验证按钮。
根据上面的步骤,这里首先引入Selenium包,并打开网页:
from selenium import webdriver
browser = webdriver.Chrome()
url = r'E:\验证码反爬\英文图像验证码\index.html'
browser.get(url) # 通过模拟浏览器打开网页这里我们采用的url是绝对路径,注意这里不能使用相对路径(这里还用了r防止反斜杠“\”可能存在的特殊含义,相关知识点请看本节补充知识点),因为直接在浏览器中输入index.html它是不知道是哪个文件路径下的index.html的。
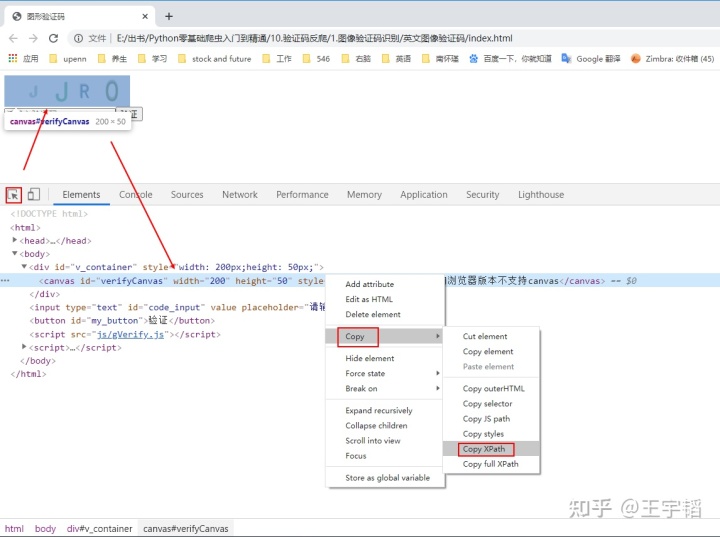
然后根据Xpath定位到验证码位置,然后保存下来为a.png,注意不要修改文件名,因为之后的cjy()函数里写的要识别的内容就是a.png。
browser.find_element_by_xpath('//*[@id="verifyCanvas"]').screenshot('a.png')其中如何利用F12键获取验证码Xpath内容的方法如下图所示:
接下来,我们将图片传给超级鹰函数,其中cjy()函数为上一节定义的内容,如下所示,这里要记得记得把上一节提到的chaojiying.py文件复制到该代码文件夹。
def cjy():
chaojiying = Chaojiying_Client('账号', '密码', '905908')
im = open('a.png', 'rb').read() # 本地图片文件路径
code = chaojiying.PostPic(im, 1902)['pic_str'] # 英文数字用1902
return code有了cjy()函数后,通过如下代码即可获取识别结果:
result = cjy() # 使用超级鹰OCR识别内容获取了识别结果后,就可以通过Selenium模拟键盘鼠标来输入验证码并模拟点击验证按钮了,代码如下:
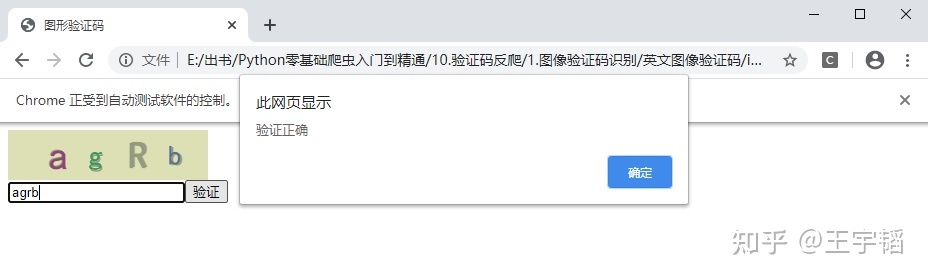
browser.find_element_by_xpath('//*[@id="code_input"]').send_keys(result) # 输入答案
browser.find_element_by_xpath('//*[@id="my_button"]').click() # 点击按钮最终验证成功,如下图所示:
完整代码如下:
from chaojiying import Chaojiying_Client
from selenium import webdriver
def cjy(): # 使用超级鹰识别
chaojiying = Chaojiying_Client('账号', '密码', '905908')
im = open('a.png', 'rb').read() # 本地图片文件路径,需要为a.png名字
code = chaojiying.PostPic(im, 1902)['pic_str']
return code
# 1.访问网址
browser = webdriver.Chrome()
url = r'E:\验证码反爬\英文图像验证码\index.html'
browser.get(url) # 访问网址
# 2.截取验证码图片
browser.find_element_by_xpath('//*[@id="verifyCanvas"]').screenshot('a.png') # 截取验证码图片
# 3.通过超级鹰识别
result = cjy() # 使用超级鹰OCR识别内容
print(result)
# 4.模拟键盘输入内容,并模拟点击确认按钮
browser.find_element_by_xpath('//*[@id="code_input"]').send_keys(result) # 输入答案
browser.find_element_by_xpath('//*[@id="my_button"]').click() # 点击按钮此外,因为每个读者保存的代码位置都不一样,所以上面代码中第12行的网页文件url绝对路径也都不一样,所以如果想让代码更加通用一些,可以通过代码先获取代码所在文件夹路径,然后拼接index.html即可,代码如下:
import os
current_dir = os.path.dirname(os.path.abspath(__file__))
url = current_dir + '/index.html'第1行代码引入os系统操作库;
第2行代码是获取代码所在的文件夹目录的固定写法,照抄即可,其获取的结果就是“E:\验证码反爬\英文图像验证码”,因此需要拼接“\index.html”;
第3行代码进行路径拼接,又因为为了防止反斜杠“\”的特殊含义(例如\n表示换行),通常采用“\\”或者“/”(“/”相当于“\\”),这里使用的是斜杠“/”所以拼接的时候也可以写’\\index.html’,关于斜杠和反斜杠的相关内容可以参考本节补充知识点,此时获取的url就是“E:\验证码反爬\英文图像验证码\index.html”了。
对于中文验证码而言,和英文验证码基本一致,唯一需要修改的就是定义的cjy()函数中的第4行代码,将识别英文的1902接口改成2004(1-4位纯中文用2004,参考网址:https://www.chaojiying.com/price.html)。
def cjy(): # 使用超级鹰识别
chaojiying = Chaojiying_Client('账号', '密码', '905908')
im = open('a.png', 'rb').read() # 本地图片文件路径,需要为a.png名字
code = chaojiying.PostPic(im, 1902)['pic_str']
return code在本书的源代码文件中也提供了中文验证码的index.html文件,也提供了Python破解代码,最终识别效果如下所示,识别成功。

总的来说,超级鹰可以识别大部分图像验证码,而且对于一些网页将网页文字转为图片的反爬方式,也可以通过超级鹰来进行识别,在本章最后,我们还将通过房天下的验证码反爬应对实战来巩固相关知识点。
(4)微博登录验证
这里首先通过Selenium进行模拟登录,然后利用Selenium的get_cookies()函数获取Cookie,如果通过微博账号密码登录话,它会出现一个图像验证码(该验证码会在输入完账号和密码后才会出现),如下所示:
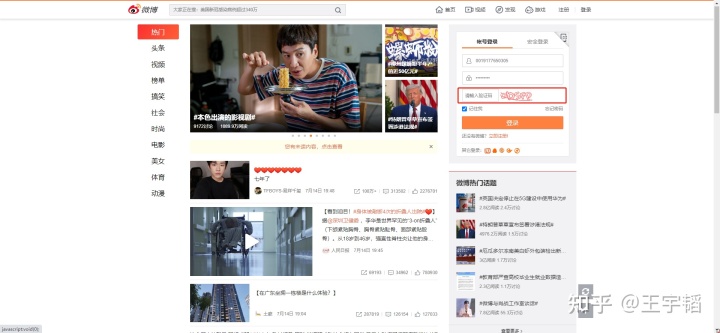
这是一个英文数字的图像验证码,可以通过专业的付费验证码识别库来进行识别(经验证,免费的图像识别库是识别不了这个验证码的),这里我们推荐超级鹰图像识别库(其官网为:https://www.chaojiying.com/,价格为一元1000积分,识别一次约10积分,即0.01元识别一次,初次注册可领免费1000积分),我们将在下一章第10章重点讲解如何使用超级鹰来破解各种验证码(超级鹰官方提供的代码需要修改成Python3版本,在第10章也有详细讲解),这里我们先主要来看下代码,也为下一章的学习做一个预热,如果暂时看不明白的,也可以先像上一节一样手动进行登录,然后获取Cookie。
(1)Selenium模拟访问
通过如下代码可以利用Selenium进行自动模拟登录,并破解其图像验证码,这里为方便大家理解,我们把代码拆开来给大家讲解下,首先引入相关库,并进行模拟访问网址:
from selenium import webdriver
import time
from chaojiying import Chaojiying_Client # 引入破解图片验证码所用到的库
# 1.模拟访问网址
url = "https://weibo.com/"
browser = webdriver.Chrome()
browser.get(url) # 访问微博官网
browser.maximize_window() # 需要全屏后才能显示那个登录框
time.sleep(5) # 休息5秒
# 2.自动模拟输入账号密码,也可以把上面休息时间设置为30秒后手动登录
browser.find_element_by_xpath('//*[@id="loginname"]').send_keys('0019177650305') # 输入账号
browser.find_element_by_xpath('//*[@id="pl_login_form"]/div/div[3]/div[2]/div/input').send_keys('syhsye595') # 输入密码
time.sleep(1)上面大部分知识点都在讲解Selenium的时候讲过了,这里需要注意的几点:第3行代码的chaojiying就是超级鹰库,也就是我们之后破解验证码需要用到库,想成功引入这个库较为麻烦,具体请参考本书第10章;第9行代码通过maximize_window()需要将网页全屏,这也才能显示出官网右侧的登录框;然后休息五秒后,通过find_element_by_xpath()定位到账号和密码输入框(在浏览器通过F12定位到Xpath值),然后通过send_keys()函数输入账号和密码。
(2)图像验证码验证
输入完账号密码后,等待1秒后进行验证码的破解,并自动模拟点击登录按钮(也可以设置time.sleep(),然后手动登录,推荐手机扫码登录(方法为:在微博手机端下方功能栏点击”我“->然后点击右上角的”扫码“按钮。)),代码如下:
# 3.破解验证码,详细讲解请参考本书下一章(也可以手动登录)
try:
browser.find_element_by_xpath('//*[@id="pl_login_form"]/div/div[3]/div[3]/a/img').screenshot('weibo.png') # 获取验证码截图
chaojiying = Chaojiying_Client('fgwyt123', 'wyt941025', '96001') # 连接超级鹰远程服务
im = open('weibo.png', 'rb').read() # 打开刚刚保存的图片验证码
code = chaojiying.PostPic(im, 1902)['pic_str'] # 识别图片验证码
print(code) # 打印破解结果
browser.find_element_by_xpath('//*[@id="pl_login_form"]/div/div[3]/div[3]/div/input').send_keys(code) # 在验证码输入框中输入破解的验证码
except:
print('无验证码') # 偶尔会没有验证码,所以写个try except以防万一
# 4.点击登录按钮
time.sleep(1)
browser.find_element_by_xpath('//*[@id="pl_login_form"]/div/div[3]/div[6]/a').click() # 点击登录按钮这里因为微博偶尔有时会没有登录验证码,所以这里写一个try except语句以防万一,然后上面第3-8行,就是超级鹰识别验证码的常规写法,每一行的含义都进行了注释,想了解更多详情可以参考第10章,可以看到程序自动识别出了下图所示的验证码(偶尔会因为网络问题或者识别有误导致验证失败,可以多试几次,或者仿照10.5节进行无限尝试直到成功为止)。
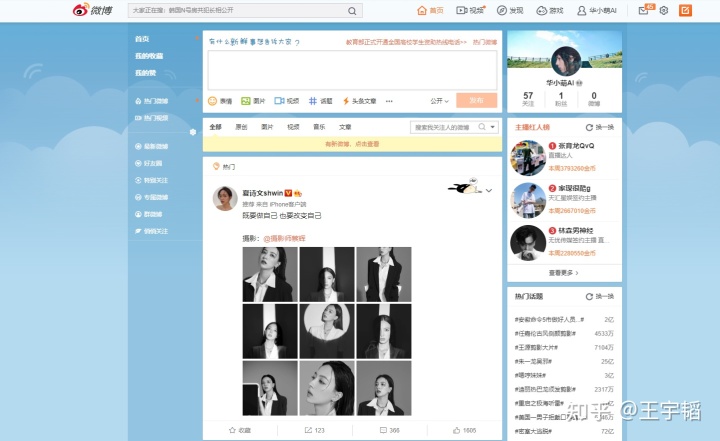
识别成功后,休息1秒后,模拟点击登录按钮,进入微博个人界面,如下图所示。注意如果登录成功的话,可以看到右上角是显示用户的昵称的,比如笔者这边设置的“华小萌AI”。
补充知识点1:文件路径的常用概念
(1) 文件夹路径通常写两个反斜杠:“\”,这是因为反斜杠在Python里其实有特殊意义,比如说‘\n’表示换行,用两个反斜杠‘\\’可以取消单个反斜杠的特殊含义。比如在E盘创建一个叫作“验证码识别”的文件夹,然后可以把文件路径写成:E:\\验证码识别\\a.png。
虽然在这个例子里,并没有什么特殊的类似\n的内容,所以也可以直接写:E:\验证码识别\a.png,但用两个反斜杠是写文件夹路径的一个好的编程习惯。
(2) 如果使用斜杠符号“/”则相当于两个反斜杠“\\”。
(3) 除了用两个反斜杠来取消一个反斜杠的特殊意义外,还可以在文件路径这个字符串前面加一个r,这样字符串里的反斜杠也不再具有特殊含义,代码如下:
r'E:\验证码识别\a.png'(4) 如果只写一个文件名的话,比如直接写“a.png”,这个便是相对路径(之前的路径叫作绝对路径),就是代码所在文件夹里的a.png图片文件。
补充知识点2:基于百度接口的Python图片文字识别(OCR)
这里简单讲一下如何利用百度接口来进行图片文字识别,其效果虽然不如超级鹰好,但是优点是目前每天可以免费调用50000次通用文字识别接口,对于比较清晰简单的图像文字识别还是可以使用的,如果是稍微复杂的图像验证码,还是推荐使用超级鹰。
(1)前期账号注册及准备
在进行正式使用Python接口之前,我们得先做一些准备工作:
1.首先进入百度文字识别官网(http://ai.baidu.com/tech/ocr),点击页面中间的立即使用
然后在弹出界面中登录百度账号(没有就注册一个)。
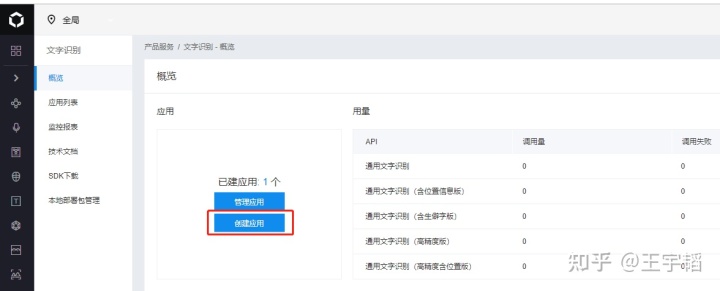
2.点击弹出界面中的创建应用
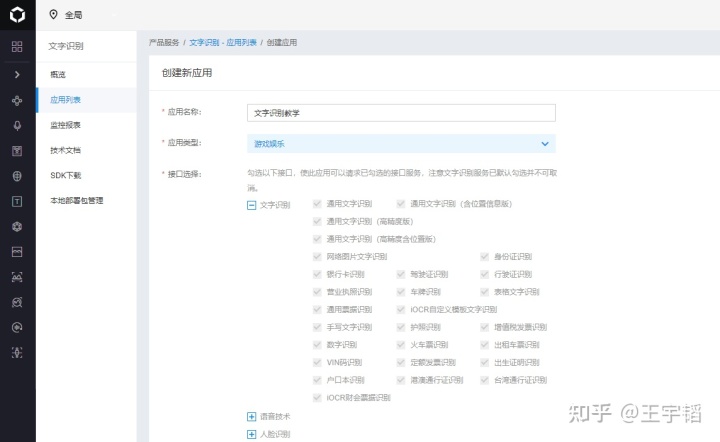
3.创建应用(随意填,填完点击最下方的“立即创建”按钮)
4.点击概览中的管理应用
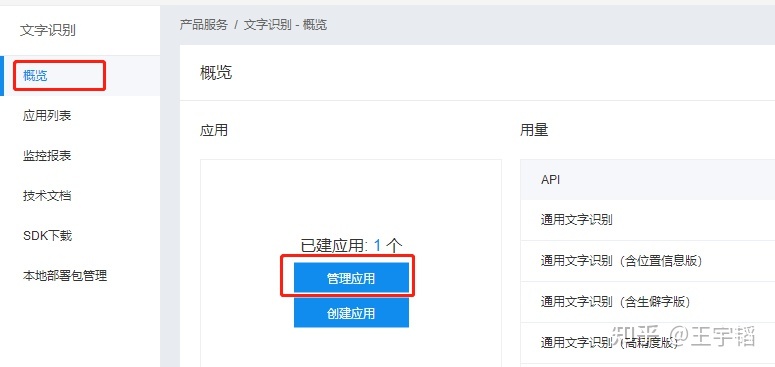
5.就能看到AppID,API Key以及Secret Key,这些在调用API时需要使用的
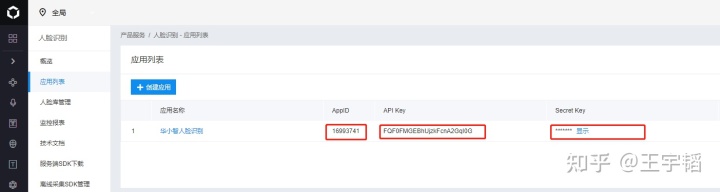
这边给大家提供一组专门用于测试学习的账号密码:
| 测试学习账号密码 | |
| AppID | 16995553 |
| API Key | clSu82UhwRTGKs60R0Lk0G1m |
| Secret Key | 16MZkmrG4ODxfToLsROuNpQGO7KXeVVi |
之后如果还想访问上面的界面,可以通过该网站http://ai.baidu.com/tech/ocr的“立即使用”按钮进入相关管理界面。该接口目前是每天可以免费调用50000次,可以供大家学习使用。
(2) Python接口调用
1.baidu-aip库安装
在通过Python调用图像识别的接口前,注意得首先安装baidu-aip这个库,可以直接使用pip下载:pip install baidu-aip,对于Windows系统,Windows + R键,调出运行框,输入cmd后,按Enter回车键,如下图所示:
然后在弹出框中输入:pip install baidu-aip,然后按Enter回车键等待安装结束即可:
2.调用接口,进行图像识别和打分
通过如下代码,即可实现图像识别及打分了,代码如下,在自己测试的时候,只要改4行代码即可,即4-6行的账号信息,及第12行的图片地址即可。
from aip import AipOcr
# 下面3行内容为自己的APP_ID,API_KEY,SECRET_KEY
APP_ID = '11352343'
API_KEY = 'Nd5Z1NkGoLDvHwBnD2bFLpCE'
SECRET_KEY = 'A9FsnnPj1Ys2Gof70SNgYo23hKOIK8Os'
# 把上面输入的账号信息传入接口
aipOcr = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 自己图片的地址,其他地方就不用改了
filePath = r'诗.jpg'
# 定义打开文件的函数
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 定义参数变量
options = {
'detect_direction': 'true',
'language_type': 'CHN_ENG',
}
# 调用通用文字识别接口并打印结果
result = aipOcr.basicGeneral(get_file_content(filePath), options)
print(result)
# 打印具体内容
words_result = result['words_result']
for i in range(len(words_result)):
print(words_result[i]['words'])这里我们用一首诗的图片来看看图片文字识别的效果:

运行结果如下:

这里简单讲下如下几行代码,这几行代码就是打印每一行的内容:
words_result = result['words_result']
for i in range(len(words_result)):
print(words_result[i]['words'])最开始的获得result是一个字典和列表嵌套的内容,所以要提取其中的内容,就得利用
(1)字典名[‘键名’](例如result[‘words_result’]中的’words_result’就是result这个字典的键名,其对应的内容是一个大的列表,里面有2个字典,分别对应的是两句话);
(2)列表名[‘序号’](words_result[i]中的i就是words_result这个列表的序号,其获取的是一个字典,例如{‘words’:’你来人间走一趟,你要看看太阳’},所以需要在words_result[i]后面利用[‘words’]这个键来提取具体文本内容)的方式来进行获取所需的内容。
我们再换一个数字验证码的图片来看看识别效果,图片如下:

运行上面的代码,识别效果如下所示,可以看到对于这种较为清晰的验证码,百度OCR的识别效果还是不错的 。

该接口目前每天可以使用一定次数,可以供大家学习使用。
总的来说,超级鹰适合商业实战,百度OCR适合简单的验证码识别,读者可以根据自己的需要选择相应的内容。
2、课程相关资源
笔者获取方式:微信号获取
添加如下微信:huaxz001 。
笔者网站:华小智首页
王宇韬相关课程可通过:
京东链接:[https://search.jd.com/Search?keyword=王宇韬],搜索“王宇韬”,在淘宝、当当也可购买。加入学习交流群,可以添加如下微信:huaxz001(请注明缘由)。

《零基础学Python网络爬虫案例实战全流程详解(入门与提高篇)》(王宇韬,吴子湛,等)【摘要 书评 试读】- 京东图书 (jd.com)

《零基础学Python网络爬虫案例实战全流程详解(高级进阶篇)》(王宇韬,吴子湛,史靖涵)【摘要 书评 试读】- 京东图书 (jd.com)