用Python模拟登录学校的系统
解析思路:我们知道登录时发起的http请求是post请求,我们先用浏览器开发者工具抓取登录时的post请求做一下分析:
在登录页面随便瞎输入一个学号和密码,点击登录,在开发者工具里找到post请求,在请求行中我们找到了请求的链接,请求体中发现请求参数如图所示:
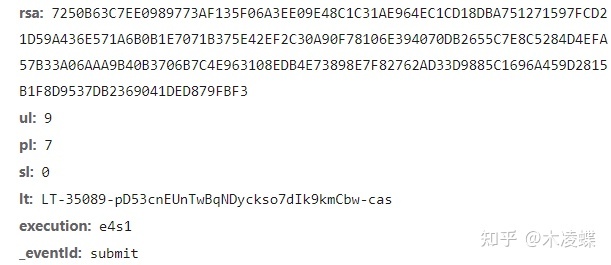
可以看出rsa是加密算法,且只有一个,说明学号和密码是混合在一起加密的,ul,pl字段是什么意思呢?通过反复瞎输入不同的学号和密码进行尝试,发现ul是学号字符串长度,pl是密码字符串长度,硬看也能猜出来他们分别是username length和password length的简写。通过反复瞎输入不同的学号和密码进行尝试还能发现sl字段和_eventid字段的值一直都是0和submit,是不变的,而lt字段和execution字段是改变的,下面我们来分析一下lt字段和execution字段是怎么来的。
在开发工具里的搜索框里输入lt,得出很多结果,最终在登录界面的HTML页面里找到了一个含有lt的标签,是一个input标签,如图:

该input标签的type属性为hidden,怪不得在登录页面里看不见,我们看到该标签的value值正是我们要找的lt字段所对应的值,并发现每次刷新网页后该值是变化的,应该是服务器每次生成不一样的值发过来的(类似于不重数机制?)。
同理图中也可得出execution也存在于一个input标签中,且也随刷新网页而变化。
最后还剩rsa字段,每次输入学号和密码后,JavaScript会在本地加密,之后把密文送入请求参数中,我们关键是找到JavaScript中的加密算法,在js文件夹下有一个des的js文件引起了我们的注意(des是一种数据加密标准):
打开之后果然是加密算法:
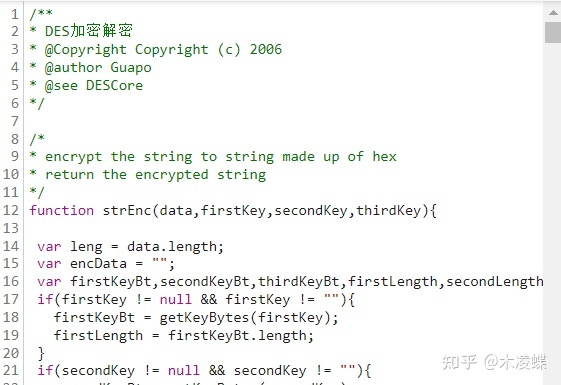
往下翻可以可以看出函数strEnc即为加密用的函数,返回值是加密后的值,参数有4个,第一个当然是需要加密的数据,第二三四个暂时先不知道,我们在开发者工具里搜索rsa试试有没有什么新发现:

发现在login6这个js文件中找到了该加密函数,打开该文件:

发现果然有一个负责登录的函数,我们可以看到他在strEnc函数要加密的数据是学号、密码和lt值拼接在一起的字符串(从搜索结果也能看出来),剩下三个实参是数字123,我们把刚才的加密算法des.js保存到本地,用Python的execjs库调用该JavaScript脚本,即可得到密文了。
至此post请求参数的分析全部完成,终于可以写代码模拟登陆了(代码里就不放链接了哈):
import requests
from bs4 import BeautifulSoup
import execjs
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43'}
s = requests.session() #用于自动保存cookie
r = s.get("https://xxxxxxxxxxx", headers=headers)
soup = BeautifulSoup(r.text, "html.parser")
ltbq = soup.find_all("input", attrs={"id":"lt", "name":"lt"})
lt = str(ltbq[0].get("value")) #提取出了lt字段值
executionbq = soup.find_all("input", attrs={"name":"execution"})
execution = str(executionbq[0].get("value")) #提取出了execution字段值
un = input("请输入学号:")
pw = input("请输入密码:")
fp = open("des.js", "r", encoding="utf-8")
jscode = fp.read()
fp.close()
context = execjs.compile(jscode)
rsa = context.call("strEnc", un + pw + lt, "1", "2", "3") #密码加密完成
url = "https://xxxxxxxxxxxxx"
data = {
"none": "on",
"rsa": rsa,
"ul": str(len(un)),
"pl": str(len(pw)),
"sl": "0",
"lt": lt,
"execution": execution,
"_eventId": "submit"
}
s.post(url, data=data, headers=headers) #发起post请求
r = s.get("https://xxxxxxxx")
f = open("校.html", "w", encoding="utf-8")
f.write(r.text)
f.close() #将登录后的页面保存到本地
print("登录成功")最后用浏览器打开保存在本地的登录后的HTML页面,登录成功了(出现了自己的姓名),或者在登录日志里也可找到记录。另外程序运行结束后登陆状态也会立马消失,因为程序中的cookie消失了。
目前来看也仅仅是登录了而已,啥也干不了,后续可能会有新招,过一段时间这种方式也可能就失效了,因为服务器那边可能会变。
其实,selenium库用无头浏览器模拟登陆更简单,但配置较麻烦,且手机Python环境不支持。