deepseek-r1本地部署如何开启联网搜索?
链接:https://www.zhihu.com/question/10744824509/answer/94873733292
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
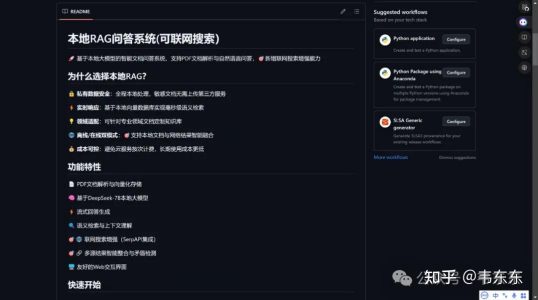
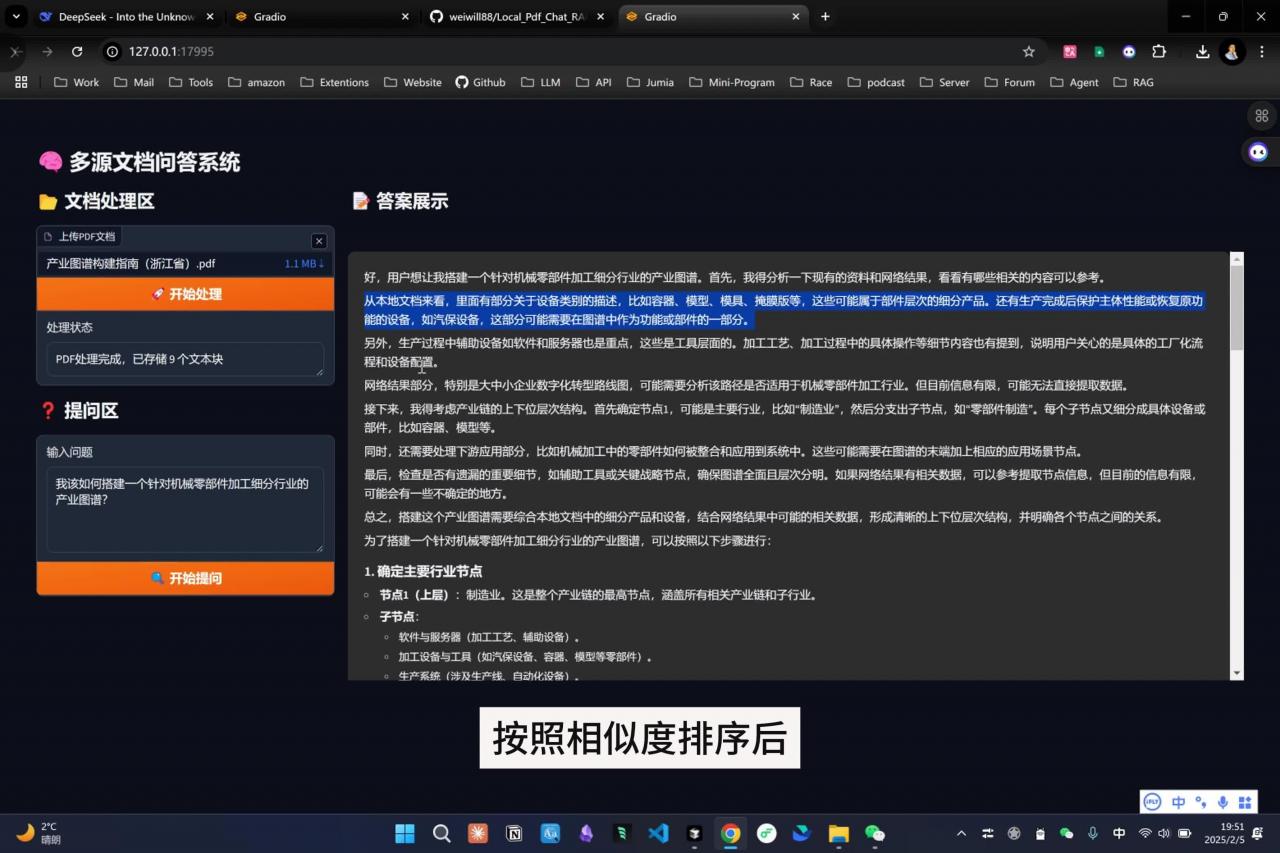
上篇文章《无需联网!DeepSeek-R1+本地化 RAG,打造私有智能文档助手》,收到了很多来自私信和评论的项目迭代的需求,针对其中提到的联网检索功能,花了半天时间通过集成 SerpAPI 的搜索 API 完成了本地 RAG+联网搜索的功能测试,已在Github开源。项目地址 https://http://github.com/weiwill88/Local_Pdf_Chat_RAG/tree/main。
这篇向各位介绍下使用方法,以及其中的工程优化尝试,欢迎评论或私信交流。
1
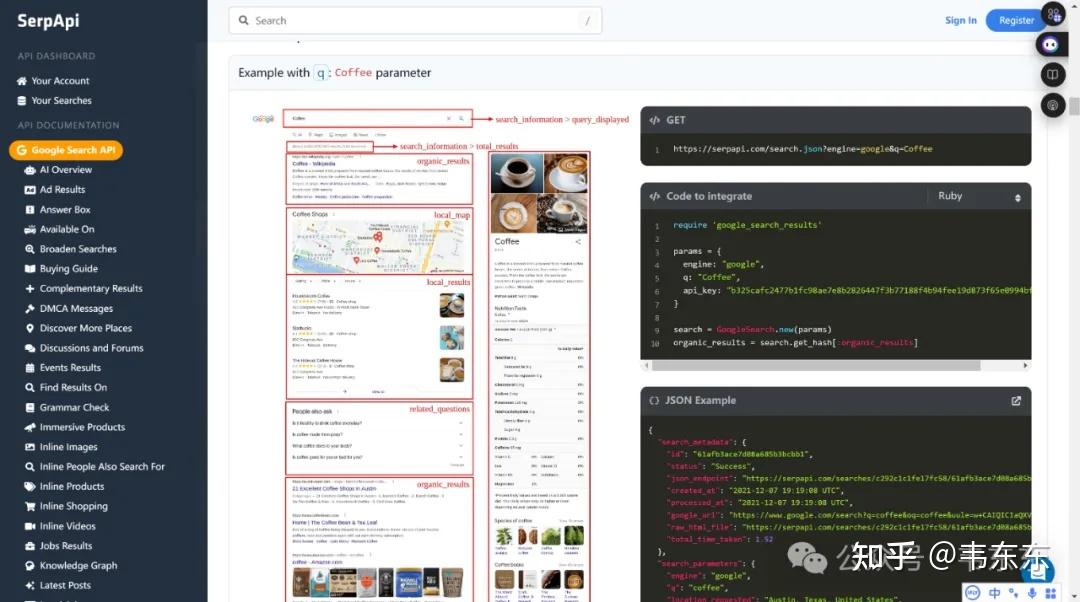
搜索 API 的选择
核心原则:优先选择支持结构化数据返回、高稳定性、低成本或免费层充足的 API。
Google Custom Search JSON API
适合通用搜索,支持过滤和排序,免费层每日 100 次请求。需注意内容版权合规性。
Serper.dev(推荐)
专为 AI 优化的搜索引擎 API,低延迟高性价比($50/10 万次)。
支持 Google/Bing 搜索结果结构化提取。
Bing Search API
微软生态兼容性好,学术场景有免费额度。
NewsAPI/Yahoo Finance(垂直领域)
若需时效性新闻或金融数据可作为补充。
学术论文检索
通过 CrossRef/Semantic Scholar API 获取学术资源。
初步测试下来,选择 SerpAPI 作为演示示例,每个月有 100 次免费查询额度,对于短期测试是完全足够了,后续有需要大家可以自行切换其他服务商。
2
联网搜索触发标准
2.1
现有触发条件
目前的触发逻辑是在代码中通过硬编码时间敏感检测实现触发。
需要特别说明的是,这种做法比较粗糙,有优化需求的盆友可以参考下述两种没有在该项目中实现的方法。
time_keywords = {
"时间相关": ["最新","今年","当前","最近","刚刚","日前","近日","近期"],
"年份模式": r"\b(20\d{2}|今年|明年|去年)\b",
"时间副词": ["最近","目前","现阶段","当下","此刻"]
}2.2
基于内容缺失的触发
- RAG 置信度阈值
当本地向量检索结果的相似度分数 < 0.7(需根据实际数据校准)。
- 实体缺失检测
通过 NER 识别问题中的实体,检查是否在本地知识库中存在。
2.3
基于用户意图的触发
- 意图分类模块
训练轻量级分类模型识别是否需要实时信息(如”新闻”、”股票价格”类问题)。
- 显式指令识别
检测类似”搜索网络”、”查看最新资料”等用户指令词。
2.4
混合决策机制
if (rag_confidence < threshold) or
(has_time_critical_keyword) or
(detect_explicit_search_command):
trigger_web_search()3
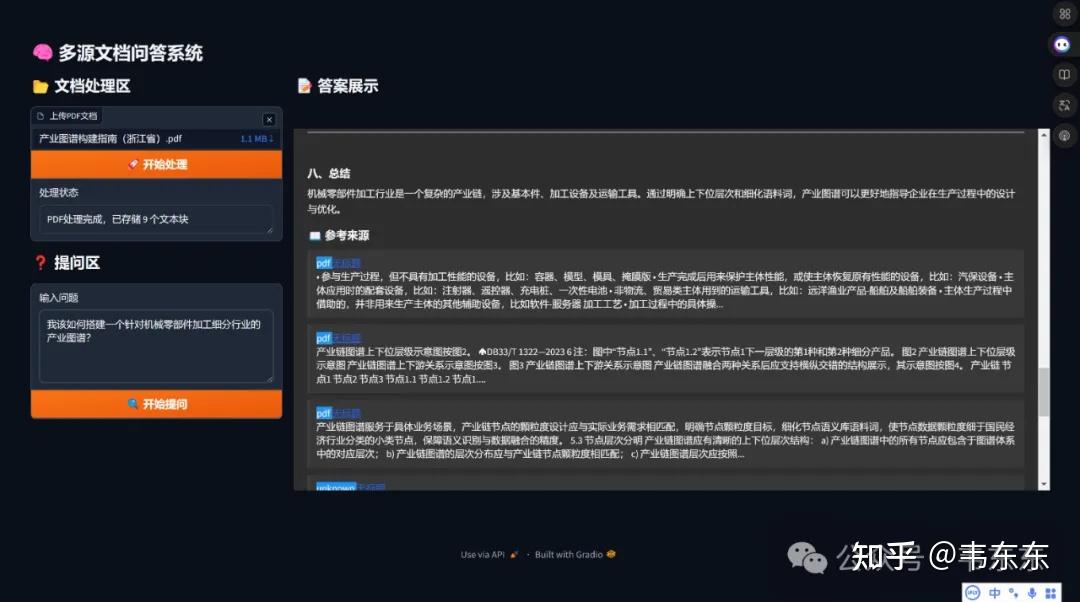
数据整合流程
3.1


双通道处理架构
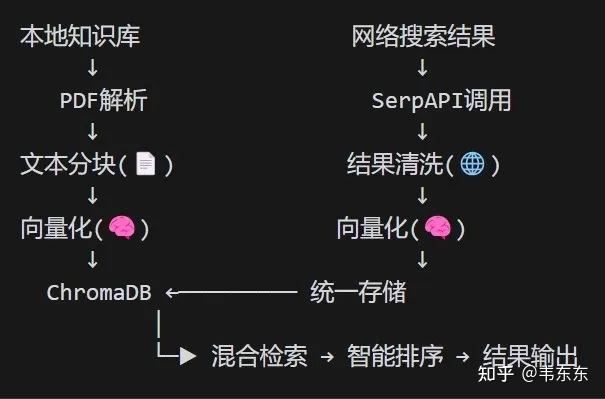
- 检索阶段
对用户查询进行向量化。在 ChromaDB 中同时检索本地知识库和网络结果的向量,按相似度排序。返回 Top-K 结果(如 K=5)。
- 生成阶段:
将检索到的本地和网络结果拼接为上下文。
- 设计提示词模板,例如:
请根据以下本地文档和网络搜索结果回答问题:
[本地文档1]...
[网络结果1]...
[本地文档2]...
[网络结果2]...
问题:{用户问题}- 调用本地大模型生成最终答案。
3.2
网络数据清洗:
去重:content_hash 校验
结构化:提取标题/摘要/链接
元数据标记:”source”: “web”
3.3
⚖️ 矛盾检测机制:
def detect_conflicts(sources):
key_facts = {}
for item in sources:
facts = extract_facts(item['excerpt'])
# 关键事实对比...3.4
可信度评估:
credibility_scores = {
"gov.cn": 0.9, # 政府网站
"weixin": 0.7, # 微信公众号
"zhihu": 0.6 # 知乎
}3.5
来源标注示例:
<div class="source-item">
<span style="background:#4CAF50"> 网络</span>
<a href="...">可信度83%|2024最新行业报告</a>
<div>...摘要内容...</div>
</div>
<div class="source-item">
<span style="background:#2196F3"> 本地</span>
<div>...本地文档节选...</div>
</div>4
性能优化方向
4.1
系统架构
微服务化可以将不同模块解耦,独立扩展。比如,将嵌入生成、模型推理部署为单独服务,利用负载均衡提高吞吐量。分布式向量数据库能处理更大规模数据,提高查询效率。
4.2
检索效率
向量数据库的查询速度直接影响响应时间。引入混合检索(比如结合 BM25 和语义向量)可以提高召回率,而重排序模型(Reranker)能提升结果的相关性,减少后续处理的数据量。
4.3
网络搜索优化
SerpAPI 的调用延迟可能影响整体性能。引入缓存机制,对常见查询结果进行缓存,减少重复请求。同时,并行处理搜索和本地检索,利用异步编程,可以缩短整体延迟。
https://www.zhihu.com/video/1871182067175411713
(完)