模型部署和微调初体验
本文将详细描述第一次如何部署和微调大模型(以千问为例)
1.选定模型
目前开源的大模型大多都能在魔搭社区(国内)和huggingface(国外)上找到,本文以魔搭社区为例,进行qwen的部署和和微调工作
魔搭社区:ModelScope 魔搭社区
2.下载项目代码

魔搭社区项目中会有对应的github链接,需要下载GitHub中的项目代码,详细的部署,微调脚本都在GitHub中有体现
3.根据说明文档中的要求配置环境(配置错误将无法部署)

注意:先下载torch以及对应的cuda
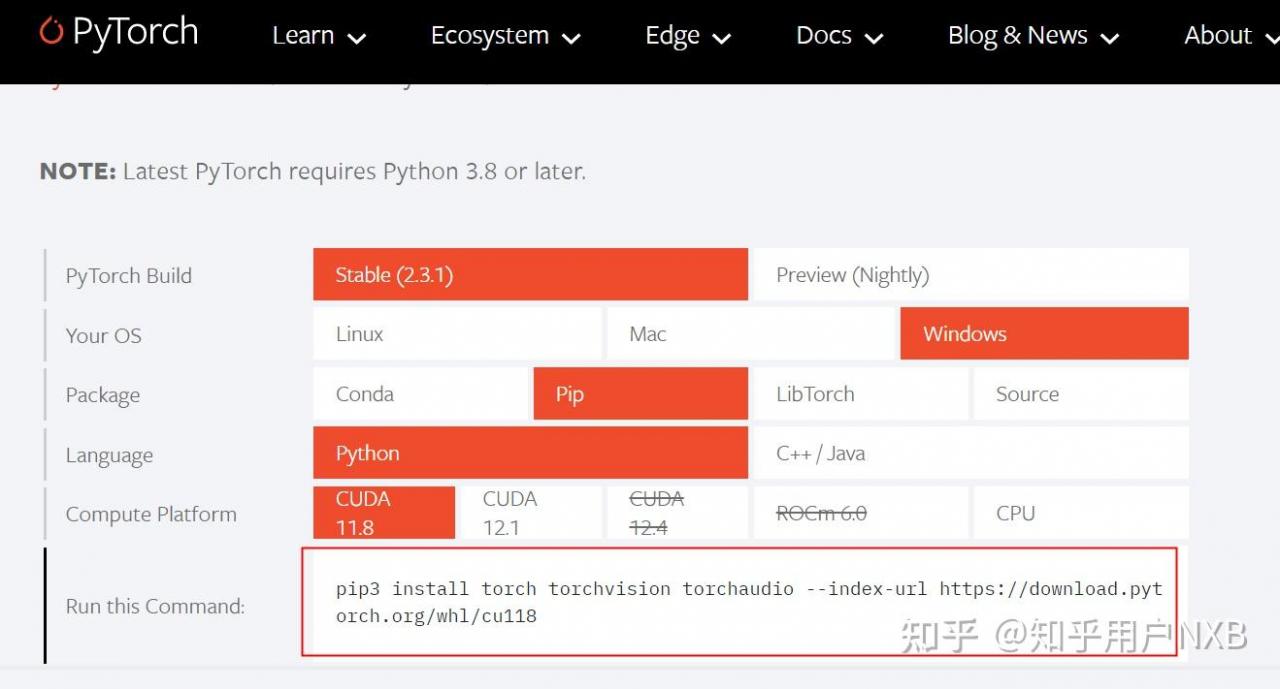
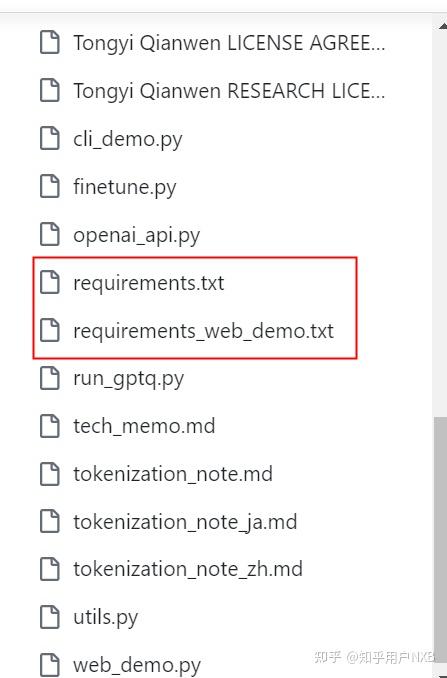
然后,用pip install -r requirement.txt,下载对应版本的报注意,项目中所有的requirement.txt文件都要pip一遍
4.部署模型,进行推理
也可以用项目中的demo
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# 可选的模型包括: "Qwen/Qwen-7B-Chat", "Qwen/Qwen-14B-Chat"
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# 使用CPU进行推理,需要约32GB内存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
# 默认使用自动模式,根据设备自动选择精度
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval()
# 可指定不同的生成长度、top_p等相关超参
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# 第一轮对话
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
# 你好!很高兴为你提供帮助。
# 第二轮对话
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
print(response)
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。
# 第三轮对话
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
print(response)
# 《奋斗创业:一个年轻人的成功之路》
response, _ = model.chat(tokenizer, "你好呀", history=None, system="请用二次元可爱语气和我说话")#支持人格设定
print(response)千问支持人格设定,可以根据输入的要求用不同的口吻回答问题。

同时,官方项目中还有web展示的脚本文件,运行该文件即可在网页端交互。
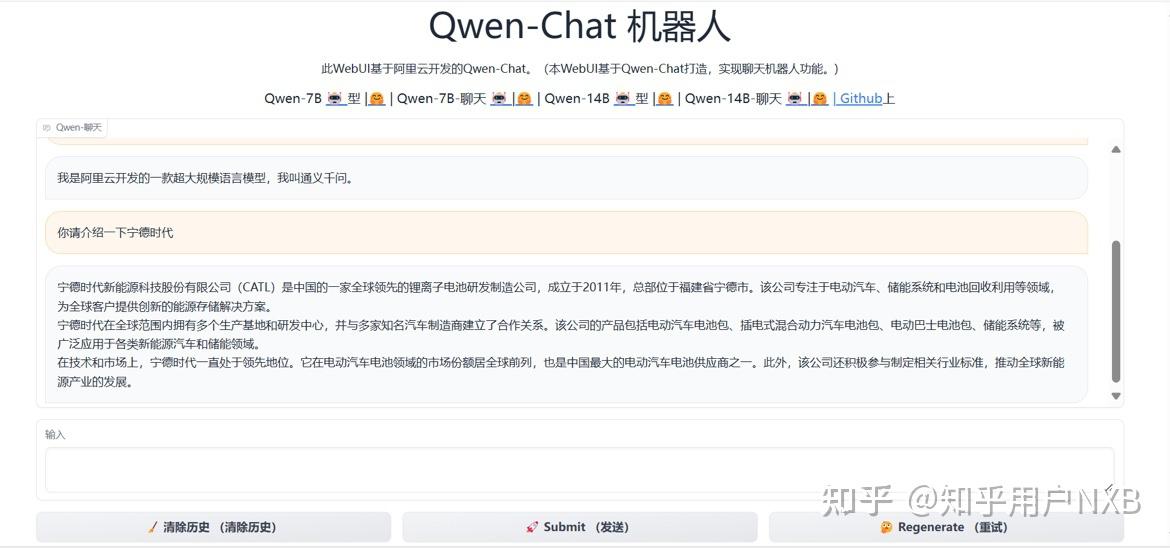
5.微调
根据自己的数据构建微调数据集,以.jason文件形式存储,官方项目中已经提供了单卡,多卡的lora,qlora的脚本,秩序修改微调数据文件,即可实现微调。