中文最强文本嵌入模型M3E实战:Docker一键部署攻略
中文最强文本嵌入模型M3E实战:Docker一键部署攻略
兄弟们,还在为中文文本处理发愁吗?今天二冰给大家安利一款中文领域最强的开源文本嵌入模型M3E,配合Docker一键部署,轻松搞定文本分类、语义检索!无论是搭建知识库还是优化智能客服,这个神器都能让你的项目起飞!
项目简介
**M3E(Moka Massive Mixed Embedding)**是由MokaAI训练并开源的中文文本嵌入模型,在中文场景下的文本分类和检索任务中,性能甚至超越ChatGPT!目前支持三种规格:
- • m3e-small(轻量级)
- • m3e-base(基础版)
- • m3e-large(旗舰版)
项目地址:https://huggingface.co/moka-ai/m3e-large
五大核心优势
- 1. 中文领域制霸:基于2200w+中文句对训练,中文任务表现SOTA
- 2. 混合检索能手:支持同质文本相似度计算+异质文本检索(如问答对匹配)
- 3. 轻量高性能:基础版仅430MB,普通服务器即可流畅运行
- 4. 零门槛接入:兼容OpenAI接口规范,现有系统无缝对接
- 5. 开发者友好:提供Docker镜像+详细部署文档,小白也能快速上手
手把手Docker部署
准备docker-compose.yml
version: '3'
services:
m3e-large-api:
image: registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
container_name: m3e-large-api
restart: unless-stopped
ports:
- "6008:6008"
# 启用GPU加速(可选)
# deploy:
# resources:
# reservations:
# devices:
# - driver: nvidia
# count: 1
# capabilities: [gpu]Dockge部署三步走
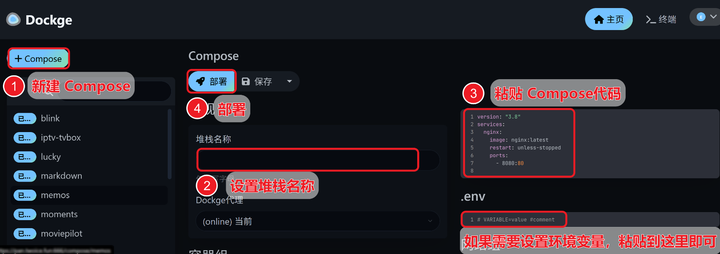
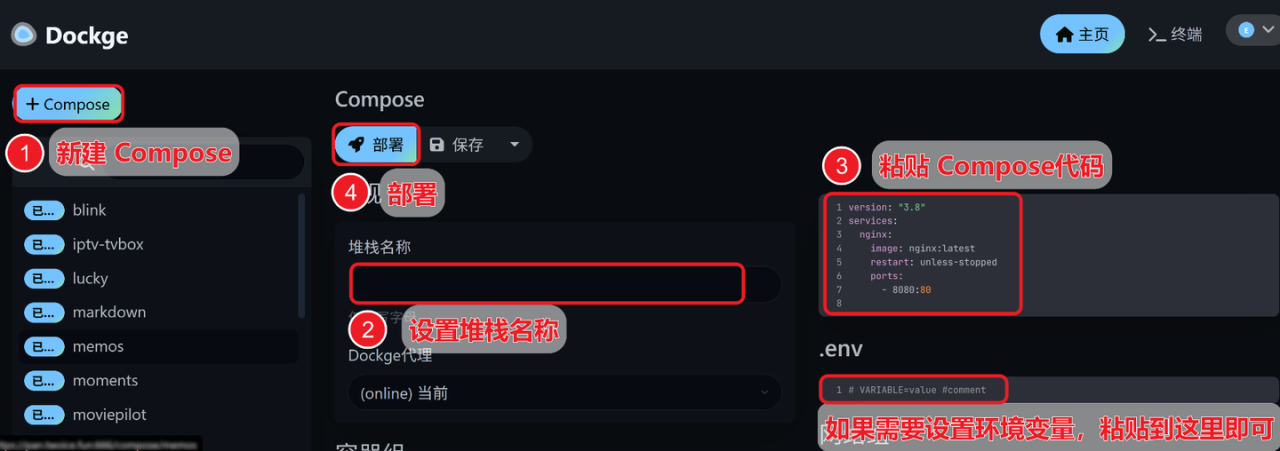
打开Dockge面板 -> 创建堆栈 -> 设置堆栈名称 -> 粘贴compose代码 -> 30秒启动成功!
功能实测演示
基础API测试
curl --location --request POST 'http://192.168.1.100:6008/v1/embeddings' \
--header 'Authorization: Bearer sk-aaabbbcccdddeeefffggghhhiiijjjkkk' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "m3e",
"input": ["如何快速搭建私有知识库"]
}'返回结果示例:
{
"object":"list",
"data":[
{"object":"embedding","embedding":[-0.0123,0.0456,...,0.0789],"index":0}
],
"model":"m3e",
"usage":{"prompt_tokens":13,"total_tokens":13}
}接入OneAPI系统
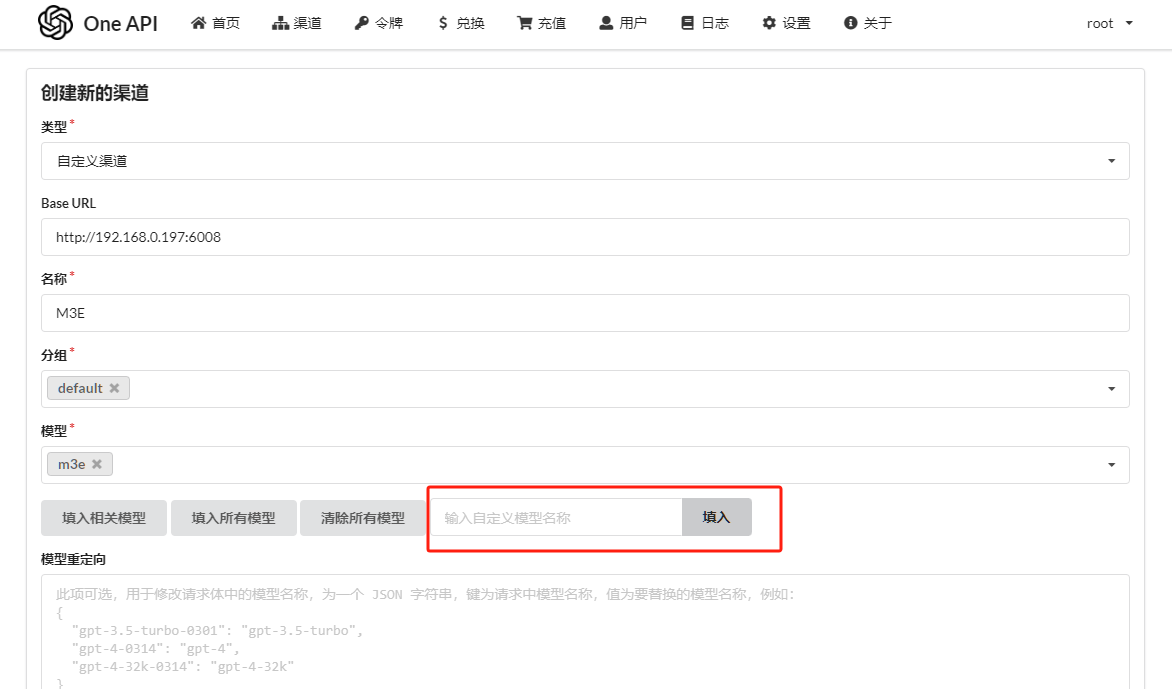
- 1. 登录OneAPI控制台
- 2. 添加新渠道:
- • 类型:自定义渠道
- • Base URL:http://你的IP:6008
- • 模型名称:m3e(自定义)
- • 密钥:sk-aaabbbcccdddeeefffggghhhiiijjjkkk
OneAPI配置截图
实战应用场景
- 1. 智能客服:快速匹配用户问题与标准答案
- 2. 文献检索:实现论文/专利的语义搜索
- 3. 知识图谱:构建基于向量的关联关系
- 4. 内容推荐:通过向量相似度推荐相似文章
- 5. 问答系统:作为RAG系统的核心嵌入组件
避坑指南
- • 国内用户建议使用阿里云镜像加速下载
- • 首次启动需加载模型,约占用3GB内存
- • 若使用GPU加速,需安装NVIDIA容器工具包
- • API密钥建议在正式环境修改默认值
总结
经过实测,M3E在中文场景下的表现确实惊艳!部署简单、接口规范、性能强劲三大优势,让它成为中文NLP项目的首选嵌入模型。无论是个人开发者还是企业级应用,配合Docker容器化部署,都能快速搭建起生产级文本处理服务。
如果觉得这篇教程有帮助,欢迎在评论区交流讨论,别忘了点赞收藏哦!
最后,奉上我的超级无敌至尊docker库,二冰平时玩过的docker都整理到了这个仓库中了,一直在更新中,希望有github账号的兄弟能去给点个star,不知道玩啥的,都去这里面找,都给你们分好类了
仓库链接:https://github.com/TWO-ICE/Awes