开源神器——分分钟爬取小红书、抖音、微博、知乎了!
推荐阅读
* 戳上方蓝字“牛皮糖不吹牛”关注我
大家好,我是牛皮糖!
最近在给一个做自媒体内容分析的朋友搭系统,他说想抓点小红书、抖音的数据看看趋势。我一听这不是很正常的需求吗?
结果他话锋一转:
“哥,我爬虫刚入门,JS加密看不懂,X-Bogus 不会搞,登录页面还 403,一气之下差点退圈。”
我:别急,MediaCrawler 给你安排得明明白白!
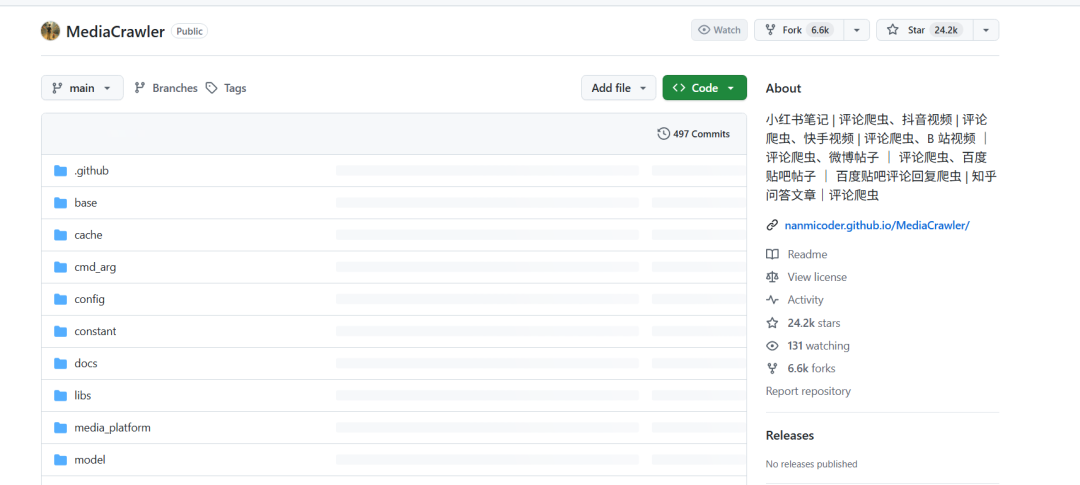
MediaCrawler 是啥?
简单一句话:
一个能帮你一键爬小红书、抖音、快手、微博、B站、知乎、贴吧等平台内容的 Python 项目,不用写前端、不用逆向、不用懂加密!
项目地址: https://github.com/NanmiCoder/MediaCrawler
它到底帮我们干了啥?
示例:只用 1 行代码,爬小红书热搜笔记!
python main.py --platform xhs --type search --keyword "穿搭" --pages 5它就能给你:
• 笔记标题、作者昵称、点赞、评论数
• 完整内容(包括图片/视频链接)
• 输出到本地 JSON / CSV,还支持 MySQL 入库!
重点:它是怎么做到“不被封”的?
很多人一爬就被封 IP、403?MediaCrawler 的做法是:
• ✅ 用 Playwright 自动化浏览器 模拟真实用户;
• ✅ 登录状态保留 Cookie;
• ✅ 页面运行时注入 JS 自动生成签名;
• ✅ 支持代理池,一键配置;
一句话:它就是模拟了一个“真的人”,所以平台难以识别你是爬虫。
开发者惊喜:还有 Pro 版本!
项目作者还开了一个加强版:MediaCrawlerPro
给开发者的一点建议
如果你做的是:
• 自媒体数据收集
• 舆情分析系统
• 多平台热词抓取
• 或者只是想轻松入门爬虫世界
那 MediaCrawler 一定值得收藏!
项目地址(赶紧 Star)
https://github.com/NanmiCoder/MediaCrawler
Pro 高级版: https://github.com/zwdzzs1/MediaCrawler

·················END·················
关于AI工具
Github开源文本转语音神器Spark-TTS开源了,克隆声音仅需3秒?
github开源B站UP主都在用的下载神器!Cobalt让你轻松搬运高清素材!
Github 开源无代码的 Web 数据提取平台,2分钟内训练机器人自动抓取网页数据
每日更新,期待与你一起成长
欢迎围观副业知识星球