44.4K Star!告别PDF处理噩梦!这个开源神器让文档转换效率暴涨10倍
链接:https://zhuanlan.zhihu.com/p/1956829099092865768
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
别担心,今天介绍一个超厉害的开源项目来解决这个问题。它包含的功能比较齐全,而且社区还很活跃。绝对会惊掉你的下巴。
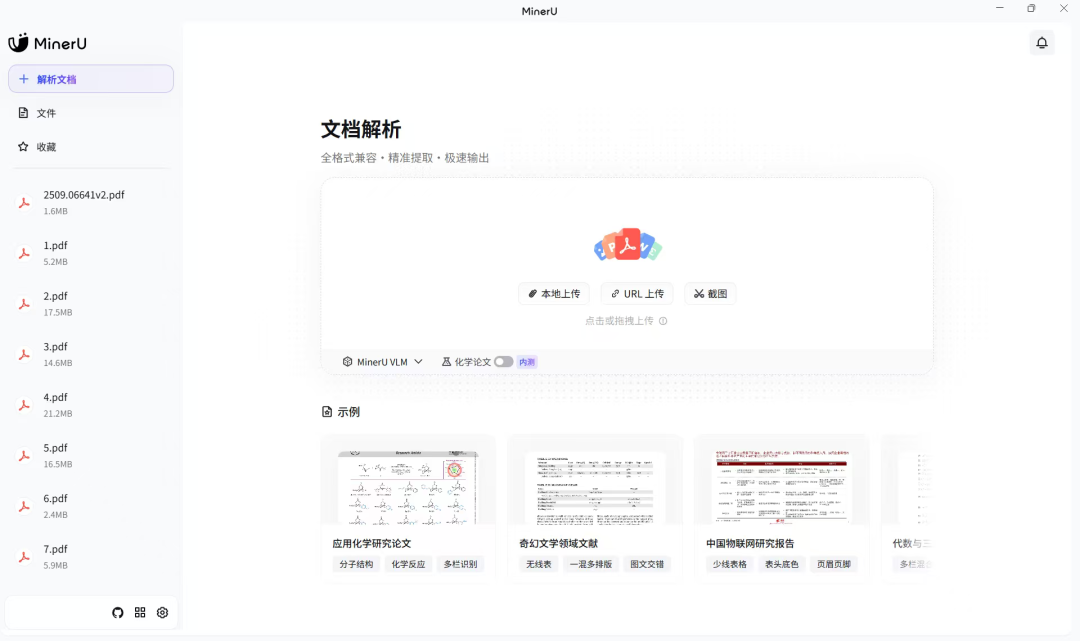
MinerU是一个由OpenDataLab开源的一站式高质量数据提取工具,专注于PDF、网页和电子书的精准解析。支持将PDF转换为Markdown格式,能够完美处理表格、公式、图像等复杂内容,准确率高达95%以上,是目前最强大的PDF处理开源方案之一。
应用特性

-
•支持多种格式转换,PDF转Markdown、网页内容提取、电子书解析一应俱全
-
• 基于先进的AI算法,提供了强大的版面分析能力(表格识别、公式提取、图像处理等)
-
•高精度OCR识别,支持中英文混合文档处理
-
• API接口友好,支持批量处理和自动化集成
-
• 基于深度学习的文档结构理解,能够准确保持原文档的逻辑结构
-
• 配置灵活的输出格式,快速能够得到想要的转换结果
-
• 命令行工具支持
-
• Web服务部署
-
• Docker容器化部署支持
它还支持二次开发,能够很轻松地根据不同的业务场景进行定制,避免了使用昂贵付费工具的麻烦,能帮你节省大量成本和时间。
️ 应用技术

-
•后端架构:使用 Python + FastAPI 框架,processing性能高也稳定。
-
•AI模型:集成多种深度学习模型,支持表格检测、公式识别等。
-
•OCR引擎:采用先进的光学字符识别技术,准确率极高。
-
•接口设计:提供 RESTful API,支持标准的HTTP调用,可以很方便的集成到现有系统中。
部署教程
1、准备环境:需要安装 Python(3.8+)、CUDA(如果使用GPU加速)。
2、拉取项目代码:
gitclonehttps://github.com/opendatalab/mineru.git
cdmineru
3、安装依赖:
pip install -r requirements.txt
4、启动服务:
# 启动API服务
python -m magic_pdf.api.main
# 或者直接使用命令行
python -m magic_pdf.cli --pdf input.pdf --output output.md
Docker部署方式:
# 构建镜像
docker build -t mineru .
# 启动容器
docker run -p 8000:8000 -v /local/data:/app/data mineru
# 批量处理
docker run -v /local/pdfs:/input -v /local/output:/output mineru --batch /input
以上命令执行完毕就可以通过API或命令行开始处理PDF了。整个过程10分钟左右,转换效率比传统工具快10倍以上。
推荐原因
为什么我要强烈推荐这个项目呢?好东西当然要推荐,当然也是因为它太牛B了:
-
•技术含量极高:项目集成了最新的AI技术做文档理解,非常适合学习前沿技术。尤其是对AI感兴趣的开发者,研究一遍收获巨大
-
•开箱即用:常用的PDF处理功能都自带,可以替代昂贵的商业软件。省下的钱买点好吃的不香吗
-
•社区超活跃:GitHub 上44.4K star,社区非常活跃,更新也比较频繁。如果有问题很快就能得到解答
-
•性能强悍:处理速度和准确率都远超同类开源项目,堪比商业级解决方案
无论你是想拿它来做企业级文档处理平台,还是用来学习AI在文档领域的应用,MinerU都是一个不错的选择。
END
往期推荐
-
一键惊呆开发圈!AingDesk开源AI桌面神器:本地部署大模型,适配各种AI模型,开源免费无限制!
-
1秒打开!这款开源图片查看器竟比Windows自带快3倍,GitHub斩获8.9K Star!
-
OCR识别颠覆者!Zerox:一键将PDF/图片转Markdown,复杂表格、手写体精准还原
-
电脑里谁在偷传数据?这个开源监控工具把泄密者抓现行