playwright只需要一句话实现网站爬虫!

最近很多人都在分享playwright,大瑜却很少关注。
直到今天遇到一个很现实的需求:根据关键字去搜索抓取不同网站的博客内容。
这个玩意,要是像之前的爬虫方式,岂不是每个网站都要单独适配规则:接口在哪?数据怎么拿?反爬虫怎么绕过?想着都会被累死。
突然,大瑜想起来了:Playwright 本质就是“会操作浏览器的机器人”,不就是为了解决这个问题吗?
playwright介绍
一句话描述:就是自动化操作浏览器的小助手。
普通爬虫更像是直接拿服务器原始网页解析;
而playwright更像是一个会用浏览器的机器人,等网页真正加载进来,再去点击、填表格、等他加载完。
优点如下:
1、更像真人操作,不容易被机器识别;
2、拿到浏览器真实展示的数据,包含动态加载数据;
3、省事,不用我去查看对应的数据获取接口。
4、Cookie/登录态保留:一键“记住你登录过”。
使用方法也很简单。我们直接打开claudeCode,直接说:帮我安装Playwight mcp工具即可。
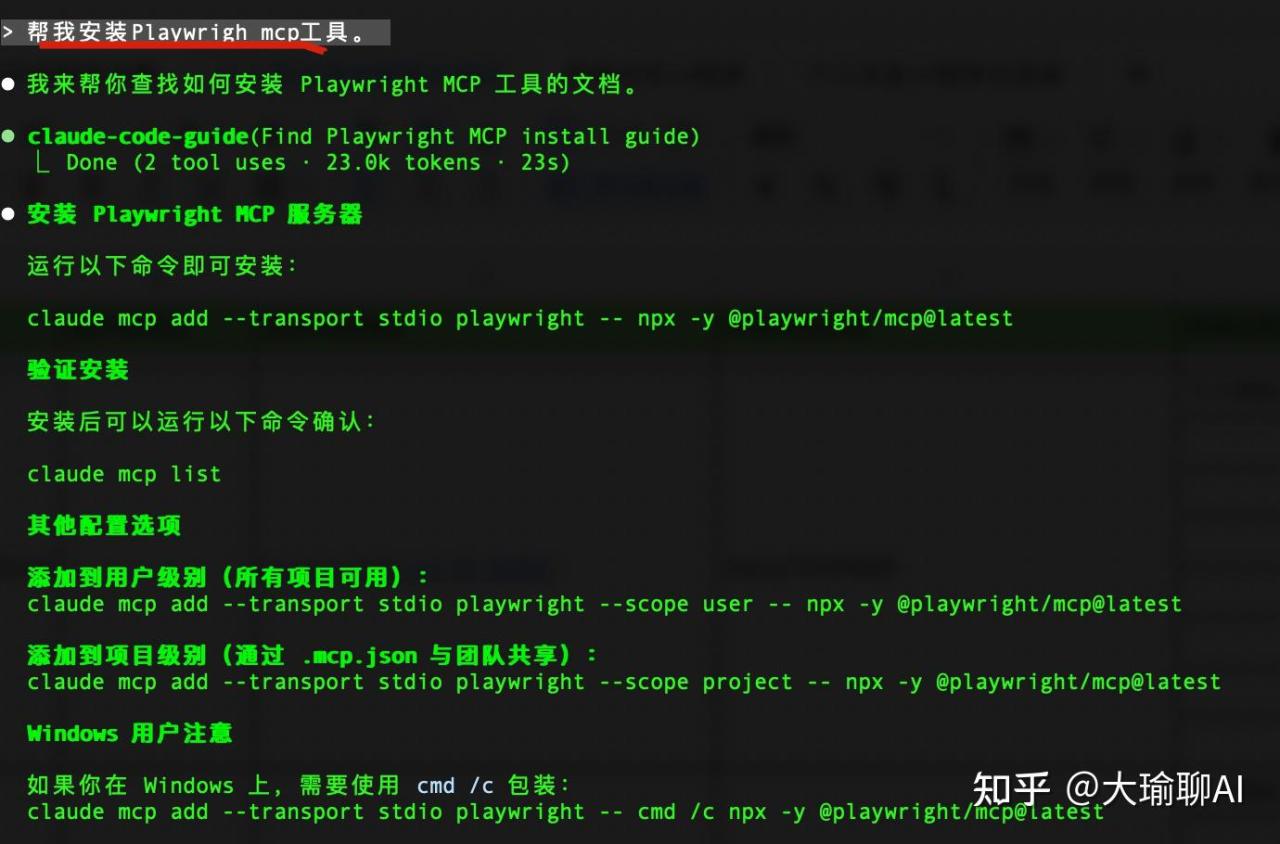
按照要求进行。安装完毕,如果要看是否安装完成,直接输入
claude mcp list如果是下面的界面就代表安装成功。
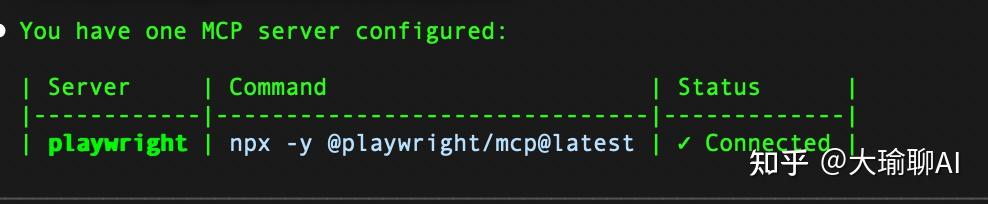
另外要记得安装完毕,要重新登陆cc,不然的话,这个mcp还无法直接调用。
Playwright怎么用?
我直接这样问:
使用playwright去google搜索dayulab的网站,找到文章目录,查询前10条文章标题。
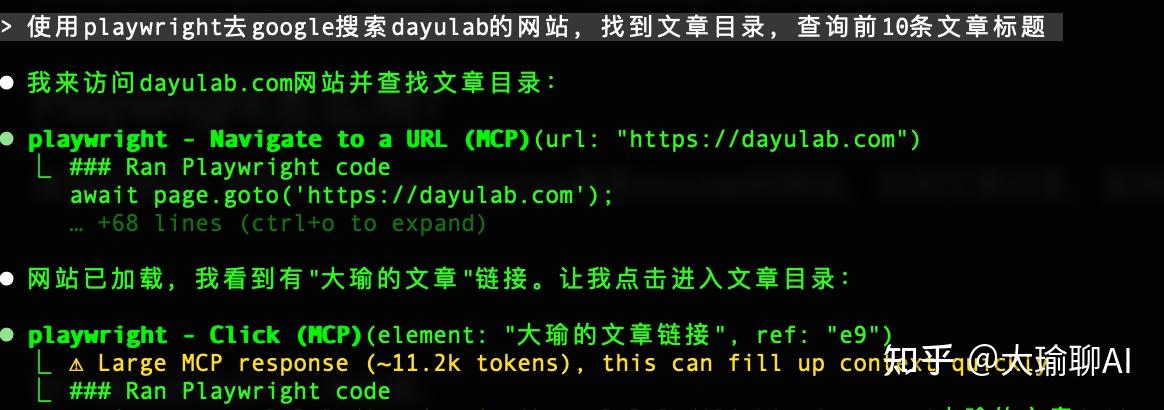
这个是以后就打开了浏览器。搜索并输入:dayulab。
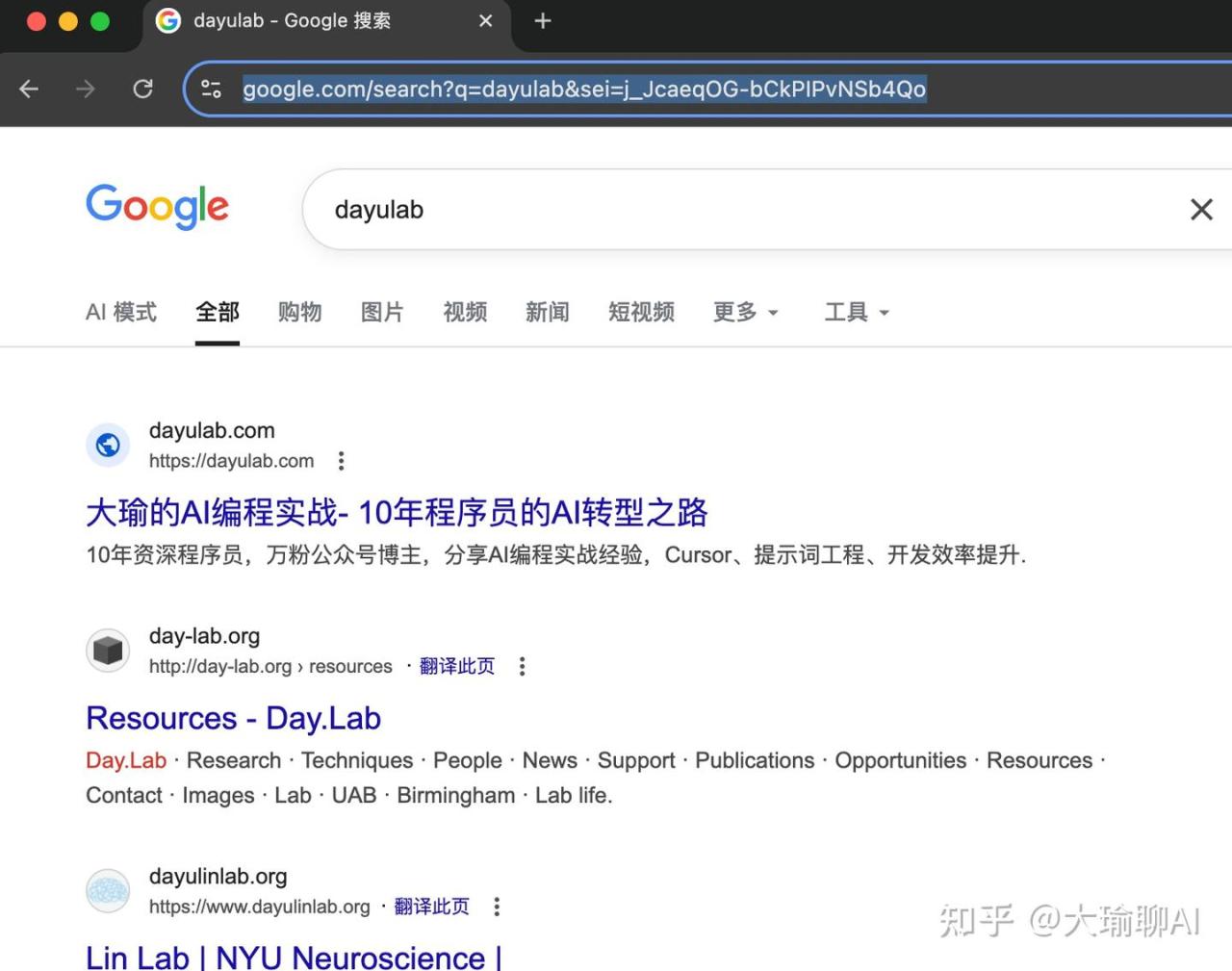
接下来他就会跳转到大瑜的网站。
最终找到了文章列表。

是不是很简单,一句话就能快速获取到大瑜的文章,根本不用像之前爬虫那么费劲。
Playwright + Skills = 电脑替你干活
当然大瑜之前也提到了skills的用法。那么playwright结合skill会爆发出什么样的能力?
就像今天的需求:
1、通过google搜索,获取关键字对应网站;
2、找到对应的网站blog内容
3、将每一篇blog保存成markdownn文件。
那么我们就可以实现一个skill来一步进行这些功能的操作。
这里有一个小技巧:将我们的需求发送给claude客户端,让他帮我们生成skill。
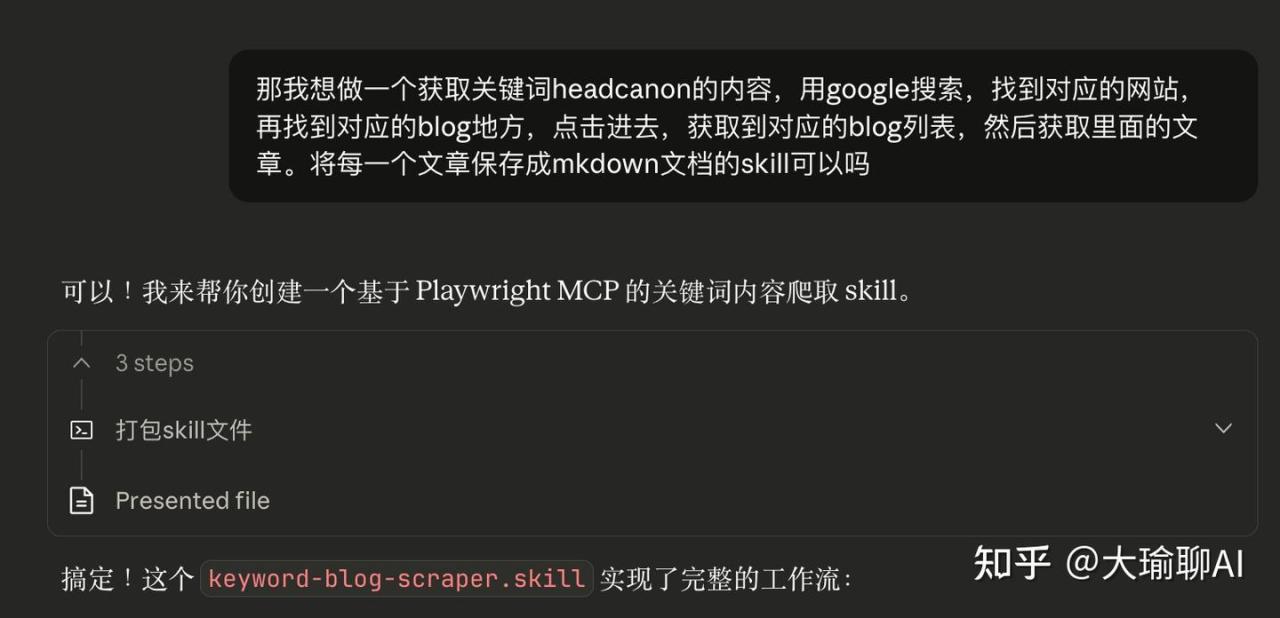
然后就是等待生成了。最后放到对应的位置后,喝喝茶,内容就生成了。
写在后面的话:我今年的转变
今天大瑜发了一条朋友圈:
之前大瑜搞ai编程的思路是拿着锤子找钉子:研究大量的类似mcp、ai编程rules,其实用户转发的多,真正接收的很少!
现在我彻底明确了另一种模式:
先明确问题,再选择适合的工具;先出结果,再谈高级玩法。
所以,转变模式很香!也快速能看到成果。
这就是我今年最想坚持的:更快看到成果、更快跑通商业化。
如果你也想跟着我一起做项目、复盘、把“能做出来”变成“能赚到钱”,找到我吧。