“婴儿级”的爬虫教学,没有比这更详细的了!


说到网络爬虫,有一些编程基础的人应该都知道,它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。
因为Python的脚本特性,Python易于配置,对字符的处理也非常灵活,加上Python有丰富的网络抓取模块,所以两者经常联系在一起。
相比与其他静态编程语言,如Java、C#、C++,Python抓取网页文档的接口更简洁;相比其他动态脚本语言,如Perl、shell,Python的urllib2包提供了较为完整的访问网页文档的API。另外,抓取网页有时候需要模拟浏览器的行为,在Python里都有非常优秀的第三方包如Requests、mechanize,可以轻松帮你搞定。
所以今天这篇文章就手把手带你认识网页结构,这个对于后续爬虫定位数据,肯定是有帮助的。

我们知道,查看网页源码有两种方式:
- ① 单击鼠标右键,点击查看网页源代码;
- ② 单击电脑上的F12键;
以实习网为例,网页源代码结构大致就是这样的。
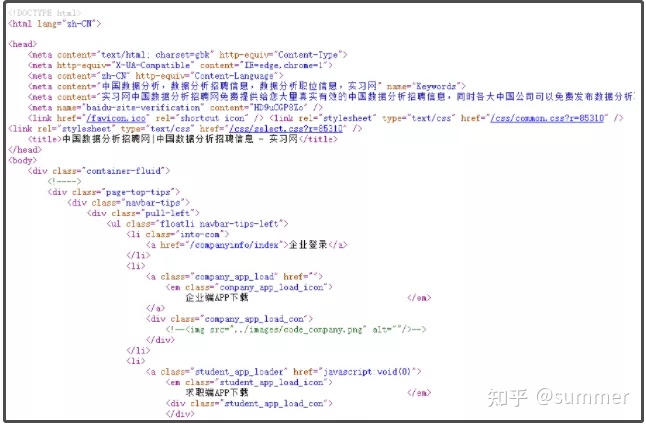
每个网页的源代码,都是由很多不同的标签,嵌套组成的。为了讲解方便,我们利用一个简单的html源代码,给大家讲解网页结构。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8"> #注意这个地方,文章编码都是看这里的,有时候解析源代码乱码,可能就是这里的问题!
<title>网页标题</title>
<meta name="keywords" content="关键字" />
<meta name="description" content="此网页描述" />
</head>
<body>
这里是网页正文内容
</body>
</html> 解释如下:
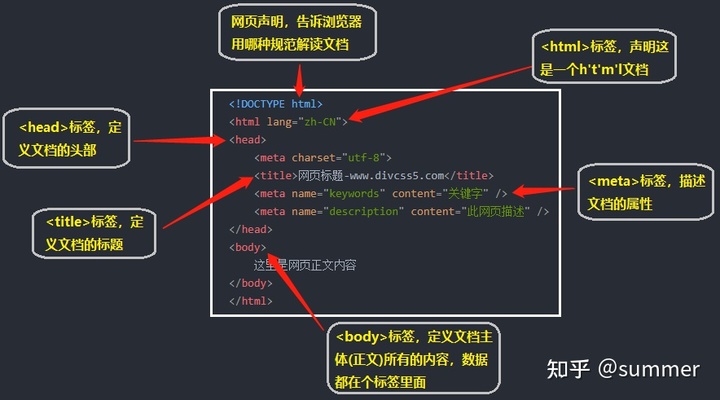
上图是一个最简单的HTMl文档,在上述基础框架上,再添加一些其它的HTML标签,添加一些内容,就可以构成一个丰富的网页了。我们在爬虫过程中,常见的HTMl标签有div、ul、ol、li、h、a、p、span、img等。接下来,我们分别来介绍它。
注意:HTML标签通常是成对出现的(双边标记),比如
<div>和</div>,也有单独呈现的标签(单边标记),如:<br />、<hr />和<img src=“images/1.jpg” />等。
说明:给大家讲述这些标签的目的,是为了让大家清楚每个标签具体指代啥,HTML代码不清楚没关系,你只要记住不同标签实际展示出来的效果是啥!
在讲解之前,我们先用pycharm创建一个.html的文件,方便我们后面做标签的讲解演示。如何在pycharm中创建一个.html的文件呢?
- ① 打开pycharm;
- ② 当出现下图,完成图中操作;
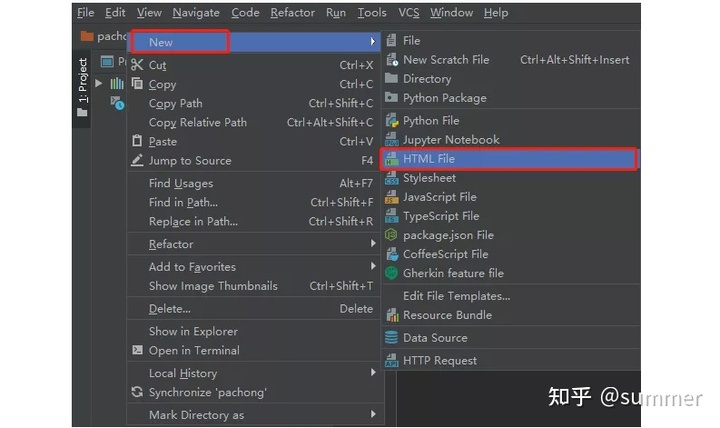
- ③ 当出现下图,任意写一个名称即可;
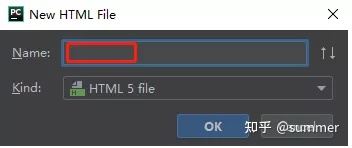
三步我们就创建了一个最基本的HTML网页,结构大致如下:
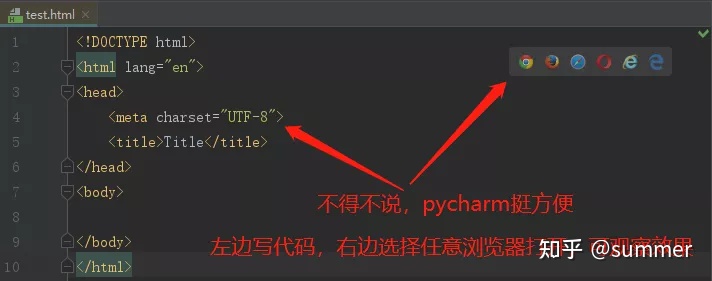
div标签
用于定义一个个不同的区块,表示在网页中划定一块儿区域,用于展示内容。因此我们可以设置该区块儿的高height和宽width。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div style="height:100px;width:500px;border:5px;">定义第一个区块儿</div>
<div style="height:500px;width:500px;border:8px;">定义第二个区块儿</div>
</body>
</html>结果展示:

ul、ol和li标签
ul用于定义一个无序列表,ol用于定义一个有序列表,li可以存在于ul或ol之下,每个li中代码列表中的一条数据。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<ul>
<li>无序列表中的数据①</li>
<li>无序列表中的数据②</li>
<li>无序列表中的数据③</li>
</ul>
<ol>
<li>有序列表中的数据①</li>
<li>有序列表中的数据②</li>
<li>有序列表中的数据③</li>
</ol>
</div>
</body>
</html>结果如下:

h标签
用于定义标题,分别从h1到h6,它们的字体分别由大到小。可以类比word中一级标题、二级标题的概念。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>一级标题</h1>
<div>
<ul>
<li>无序列表中的数据①</li>
<li>无序列表中的数据②</li>
<li>无序列表中的数据③</li>
</ul>
<h2>二级标题</h2>
<ol>
<li>有序列表中的数据①</li>
<li>有序列表中的数据②</li>
<li>有序列表中的数据③</li>
</ol>
</div>
<h3>三级标题</h3>
</body>
</html>结果如下:

a标签
用于定义一个超链接,点击超链接可以直接跳转。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>一级标题</h1>
<div>
<ul>
<li>无序列表中的数据①</li>
<li>无序列表中的数据②</li>
<li>无序列表中的数据③</li>
</ul>
<h2>二级标题</h2>
<a href="https://blog.csdn.net/weixin_41261833">我是一个超链接</a>
<ol>
<li>有序列表中的数据①</li>
<li>有序列表中的数据②</li>
<li>有序列表中的数据③</li>
</ol>
</div>
<h3>三级标题</h3>
</body>
</html>结果如下:

p标签
用于定义一个段落,每个段落占一行。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>一级标题</h1>
<div>
<ul>
<li>无序列表中的数据①</li>
<li>无序列表中的数据②</li>
<li>无序列表中的数据③</li>
</ul>
<h2>二级标题</h2>
<a href="https://blog.csdn.net/weixin_41261833">我是一个超链接</a>
<ol>
<li>有序列表中的数据①</li>
<li>有序列表中的数据②</li>
<li>有序列表中的数据③</li>
</ol>
</div>
<h3>三级标题</h3>
<p>这是定义的第一个段落</p>
<p>这是定义的第二个段落</p>
<p>这是定义的第三个段落</p>
</body>
</html>结果如下:

span标签
用于定义一个行内元素,不同的span标签定义的内容,都显示在一行,方便我们为每个块儿添加不同的格式。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>一级标题</h1>
<div>
<ul>
<li>无序列表中的数据①</li>
<li>无序列表中的数据②</li>
<li>无序列表中的数据③</li>
</ul>
<h2>二级标题</h2>
<a href="https://blog.csdn.net/weixin_41261833">我是一个超链接</a>
<ol>
<li>有序列表中的数据①</li>
<li>有序列表中的数据②</li>
<li>有序列表中的数据③</li>
</ol>
</div>
<h3>三级标题</h3>
<p>这是定义的第一个段落</p>
<p>这是定义的第二个段落</p>
<p>这是定义的第三个段落</p>
<span>这是定义的第一个行内元素。</span>
<span>这是定义的第二个行内元素。</span>
<span>这是定义的第三个行内元素。</span>
</body>
</html>结果如下:

img标签
定义一张图片,有一个src属性用于指定图片的地址。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<img>
<h1>一级标题</h1>
<div>
<ul>
<li>无序列表中的数据①</li>
<li>无序列表中的数据②</li>
<li>无序列表中的数据③</li>
</ul>
<h2>二级标题</h2>
<a href="https://blog.csdn.net/weixin_41261833">我是一个超链接</a>
<ol>
<li>有序列表中的数据①</li>
<li>有序列表中的数据②</li>
<li>有序列表中的数据③</li>
</ol>
</div>
<h3>三级标题</h3>
<p>这是定义的第一个段落</p>
<p>这是定义的第二个段落</p>
<p>这是定义的第三个段落</p>
<span>这是定义的第一个行内元素。</span>
<span>这是定义的第二个行内元素。</span>
<span>这是定义的第三个行内元素。</span>
<img src="https://i.loli.net/2020/05/30/Z5XrPidptFDb2BA.jpg" alt="加载失败">
</body>
</html>结果如下:

好了,本文主要内容就先介绍到这里。希望你看了本文以后,以后再遇到爬虫,每当看到这些标签,你就能大致知道它是什么就行。
爬虫的用途很多,在生活和工作中它都是一个非常便捷的工具,大大节省了我们不必要花费的时间和精力,比如:
1、收集数据
Python爬虫程序可用于收集数据。这也是最直接和最常用的方法。由于爬虫程序是一个程序,程序运行得非常快,不会因为重复的事情而感到疲倦,因此使用爬虫程序获取大量数据变得非常简单和快速。
由于99%以上的网站是基于模板开发的,使用模板可以快速生成大量布局相同、内容不同的页面。因此,只要为一个页面开发了爬虫程序,爬虫程序也可以对基于同一模板生成的不同页面进行爬取内容。
2、调研
比如要调研一家电商公司,想知道他们的商品销售情况。这家公司声称每月销售额达数亿元。如果你使用爬虫来抓取公司网站上所有产品的销售情况,那么你就可以计算出公司的实际总销售额。此外,如果你抓取所有的评论并对其进行分析,你还可以发现网站是否出现了刷单的情况。数据是不会说谎的,特别是海量的数据,人工造假总是会与自然产生的不同。过去,用大量的数据来收集数据是非常困难的,但是现在在爬虫的帮助下,许多欺骗行为会赤裸裸地暴露在阳光下。
3、刷流量和秒杀
刷流量是Python爬虫的自带的功能。当一个爬虫访问一个网站时,如果爬虫隐藏得很好,网站无法识别访问来自爬虫,那么它将被视为正常访问。结果,爬虫“不小心”刷了网站的流量。
除了刷流量外,还可以参与各种秒杀活动,包括但不限于在各种电商网站上抢商品,优惠券,抢机票和火车票。目前,网络上很多人专门使用爬虫来参与各种活动并从中赚钱,这种行为一般称为“薅羊毛”。
在后续还会有很多关于爬虫的详细介绍,如果你对Python网络爬虫感兴趣,并且想进一步学习,这里分享一个Python交流学习群,里面有很多大神分享学习经验好学习方法,也有很多一起学习的人一起交流讨论,学习氛围感很好,更重要的是还有免费的学习资料可以领取,点击下方入口↓↓↓就可直接进入!