Python制作网络爬虫爬取 “简书”用户粉丝


引言
最近这段时间一直在沉迷于LOL,有时间都没有Python写过代码了。真是不写不知道一写吓一跳,语法都忘记一大半了。吓得我赶紧打开Python写写代码压压惊。Python 最出色的是什么? 数据爬虫、 大数据、今天就给大家写一个用Python爬取简书用户粉丝的 “数据爬虫“。
网页访问
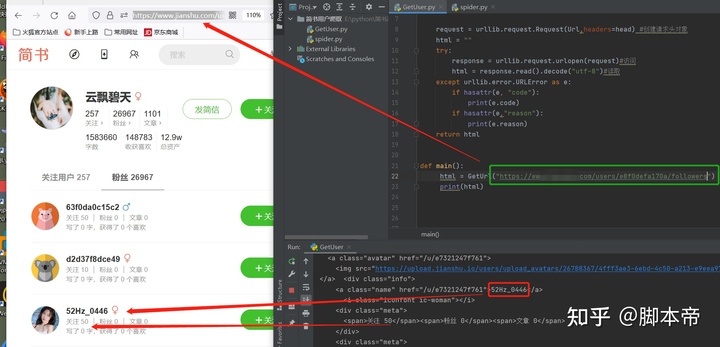
要爬取简书的用户粉丝 那么必然需要访问该用户的粉丝主页, 然后把整个网页给爬取下来。因此需要用到Python的 urllib 模块,在命令行窗口输入 pip install urllib 安装 urllib 模块。然后代码如下:
import urllib.request,urllib.error
def GetUrl(Url):
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0"}
request = urllib.request.Request(Url,headers=head) #创建请求头对象
html = ""
try:
response = urllib.request.urlopen(request)#访问
html = response.read().decode("utf-8")#读取
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
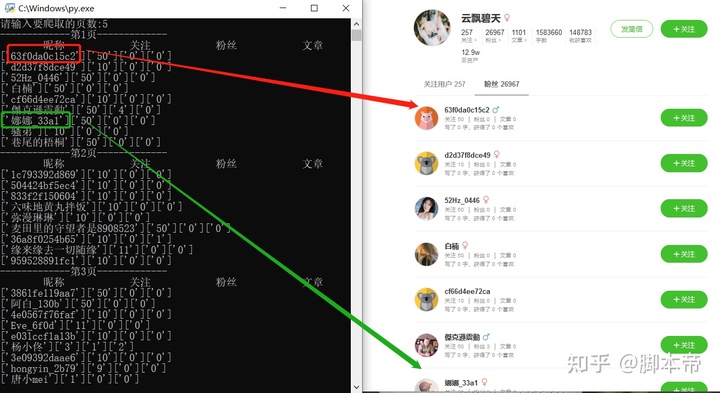
return html代码写好后先复制该用户的粉丝页面链接来测试一下,可以看到这位昵称叫云飘碧天的用户粉丝页面被成功抓取下来了。有些小伙伴就有疑问了,为什么 云飘碧天这位用户的粉丝有26967个,而抓取下来的页面中也不过才几十个粉丝而已。
瀑布流加载
那是因为粉丝数据是以瀑布流方式加载的,也就是说你的鼠标滚轮滑倒哪里 就加载到哪里。并不是一次性把用户数据全部加载出来,因此如果需要访问后面的粉丝数据;需要给访问链接后面加上参数。
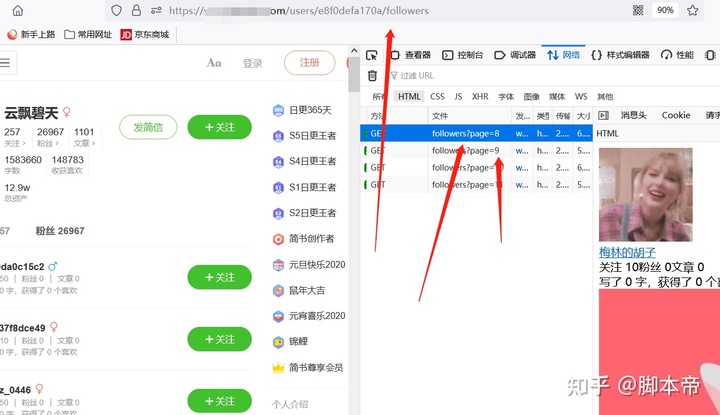
例如:/users/338fd5c49ba0/followers?page=1 后面的 ?page=1 就是代表访问第一页粉丝数据,以此类推如果想访问后面的粉丝数数据; 只需要改变后面的参数即可。代码如下:
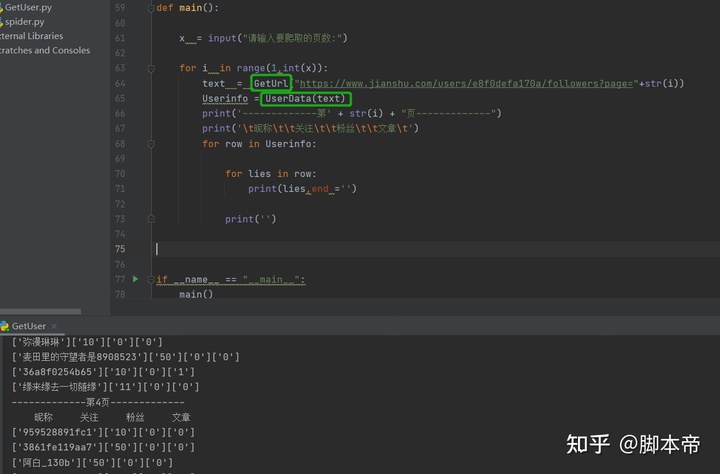
x = input("请输入要爬取的页数:")
for i in range(1,int(x)):
text = GetUrl("https://www.jianshu.com/users/e8f0defa170a/followers?page="+str(i))
print('-------------第' + str(i) + "页-------------")
print(text)
正则匹配
获取到粉丝的网页数据后,接下来就需要提取粉丝数据了,因为只需要粉丝的个人信息,像其它不相干的东西都会被剔除掉。因此需要用到正则匹配 首先导入 re模块,然后根据要提取的内容创建规则,代码如下:
from bs4 import BeautifulSoup
import re
网页中的粉丝数据如下:
'''
<div class="info">
<a class="name" href="/u/f945188c5987">燕小七_99d5</a>
<i class="iconfont ic-woman"></i>
<div class="meta">
<span>关注 10</span><span>粉丝 0</span><span>文章 0</span>
</div>
<div class="meta">
写了 0 字,获得了 0 个喜欢
</div>
</div>
'''
创建正则匹配
reList = []
reList.append(re.compile(r'<a class="name" href="/u/.*?">(.*?)</a>')) #匹配昵称
reList.append(re.compile(r'关注 (\d+)'))#关注
reList.append(re.compile(r'粉丝 (\d+)'))#粉丝
reList.append(re.compile(r'文章 (\d+)'))#文章
创建一个函数
def UserData(html):
UserInfo = []
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="info"):
item = str(item)
row = [];
for i in reList:
info = re.findall(i, item)
row.append(info)
if row[0]:
UserInfo.append(row)
return UserInfo
爬取测试
最后把编写的俩个函数全部组装起来。先用GetUrl函数获取网页的源码,再把获取到得网页源码给UserData函数。经过UserData函数的处理 每一页的用户数据在通过列表形式返回,在通过循环把昵称 关注 粉丝 文章 给打印出来。
爬取这些粉丝数据有什么用?
之前在网上看过一个在抖音爬取精准粉丝,然后再通过软件给这些精准粉丝发送私信。本来粉丝就很精准 只要话术写到好一点,至于是引流还是营销那还不是你说了算。下期文章教你们如何进行用户私信。
双击文章{ 获取文章打包源码或工具 }