chrome上有哪些厉害的插件?

推荐一个 Web Scraper (谷歌浏览器插件),小白爬虫利器,5 分钟配置一个爬虫。
举个例子,爬取豆瓣穷游天下小组的帖子。
准备工作
首先确保你安装了新版谷歌浏览器和 WebScraper 插件,插件安装教程见:谷歌(Chrome)浏览器插件安装教程
步骤
- 打开豆瓣穷游天下小组 https://www.douban.com/group/qiong/discussion ,右键点击检查,弹出如下页面,然后点击 Web Scraper,开始我们的自动化脚本之路。
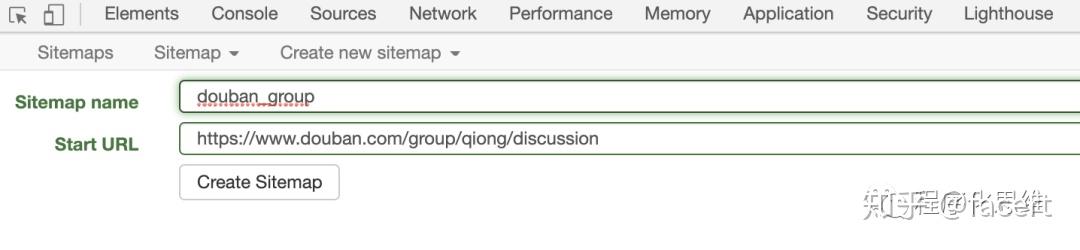
- 创建一个新的 Sitemap

- Start url 是开始爬取的初始页
- 点击 Add new selector
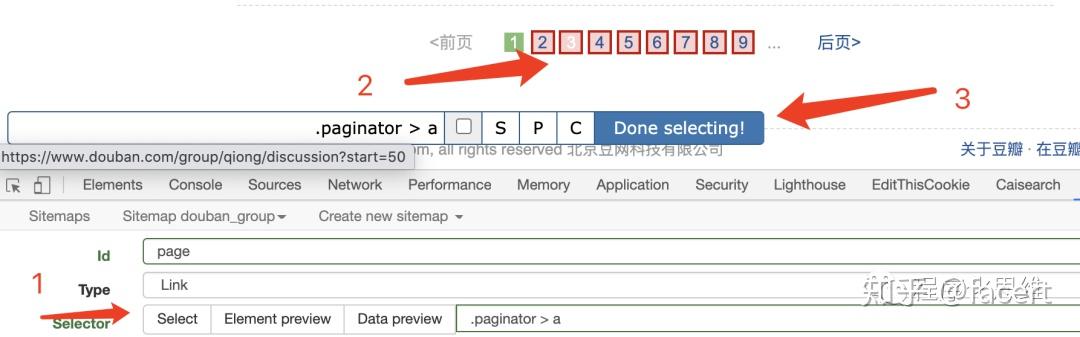
- 新建第一个 Selector, 定义豆瓣小组的页数 ,Id 写 page, Type 为 link ,然后点击 Select,选中图中 2 的位置,让页数都呈现红色选中状态,点击 Done selecting!
graph”>
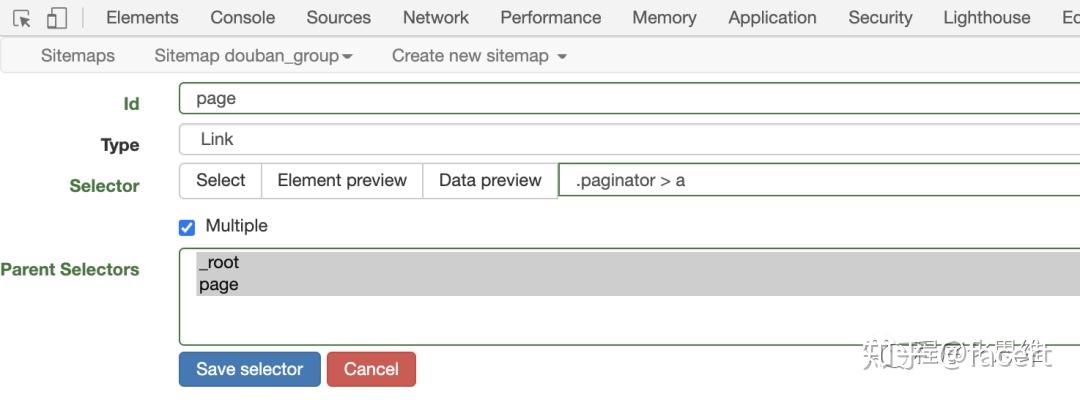
- 接下来勾选 Multiple,意思是这个页面中有多条记录,Parent Selectors 选中 _root 和 page, 点击 Save。
- 我们再新建一个 Selector, 定义一个帖子的页面元素,Id 为 post, Type 选 Element。然后按下图步骤重复操作选择 selector,勾选 Multiple,Parent Selectors 选中 _root 和 page, 点击 Save。
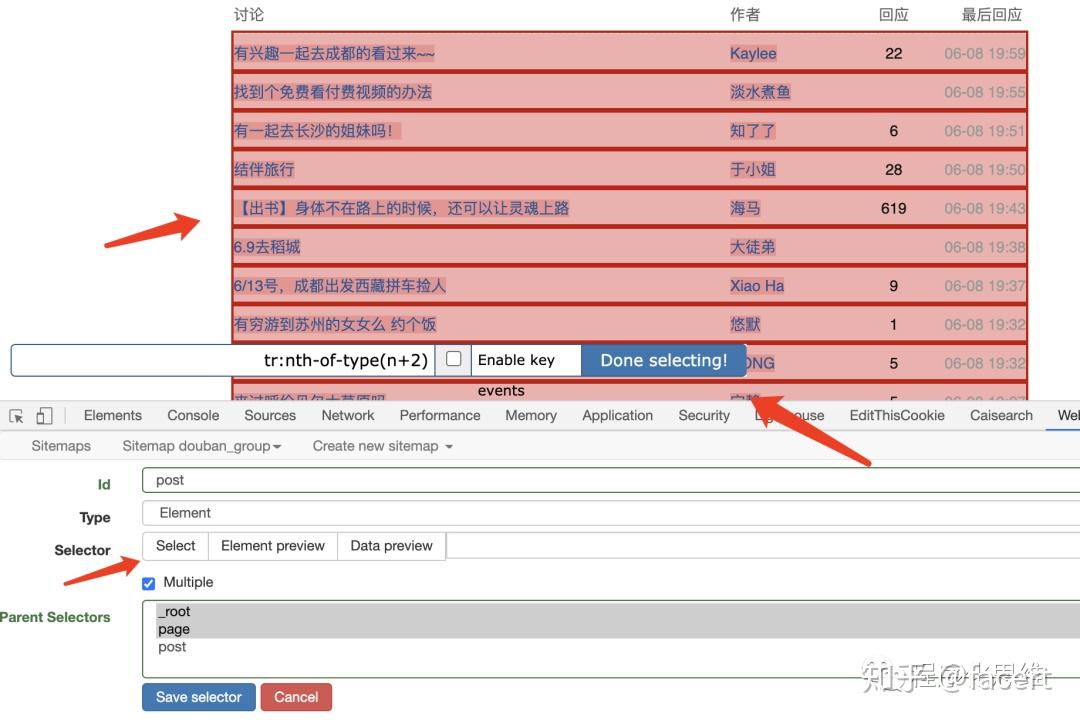
- 点击 post,我们接下来在 post 元素里选择合适的内容

- 新建一个 Selector,定义帖子的标题, Id 为 title, Type 选为 Link,然后按下图步骤重复操作选择 selector, 点击 Save。
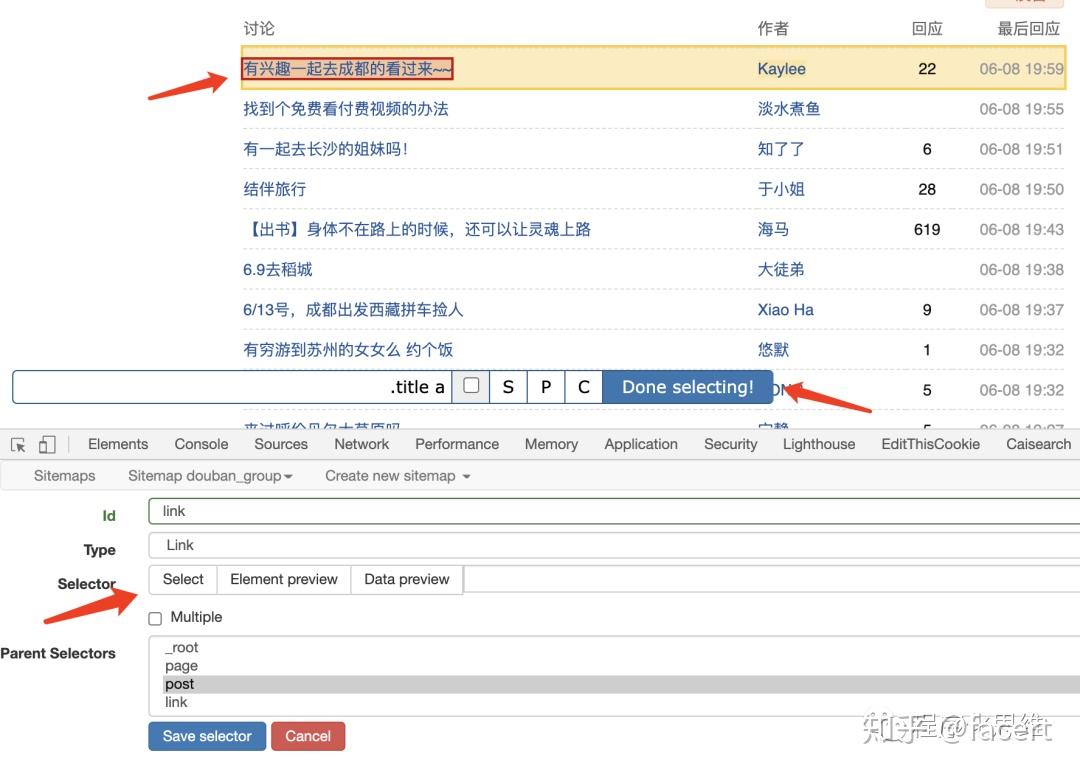
- 再按上面步骤,定义一个 author (作者) 和 updated (最后回应)
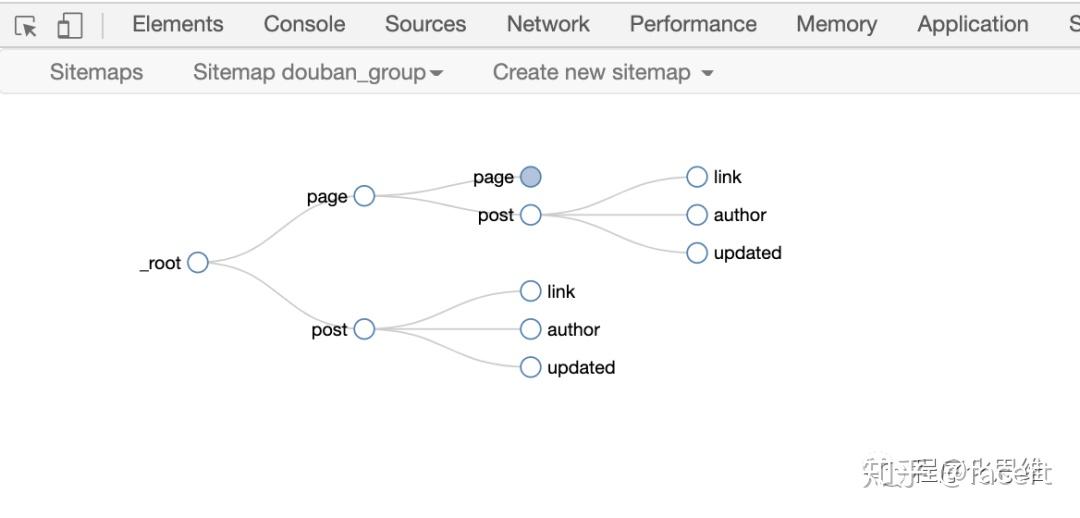
- 点击 selector graph ,可看到爬取路径。
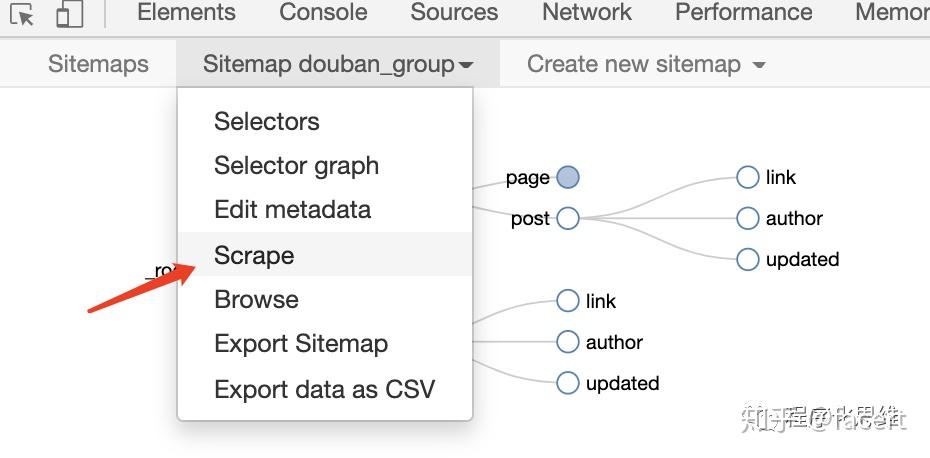
- 配置完成后,点击 Scrape 开始爬取。
- 爬取结束后,点击 Refresh 刷新,即可看到数据
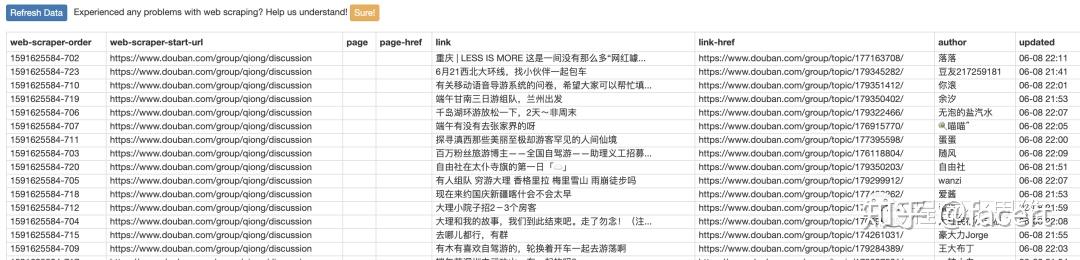
- 最后 Export data as csv ,导出数据。
最后 Web Scraper 还可以对于动态渲染的页面进行爬取,比如下拉刷新,点击 Load More 按钮这种。总的来说,掌握基本方法后,可以非常轻松的 5 分钟配置一个爬虫。
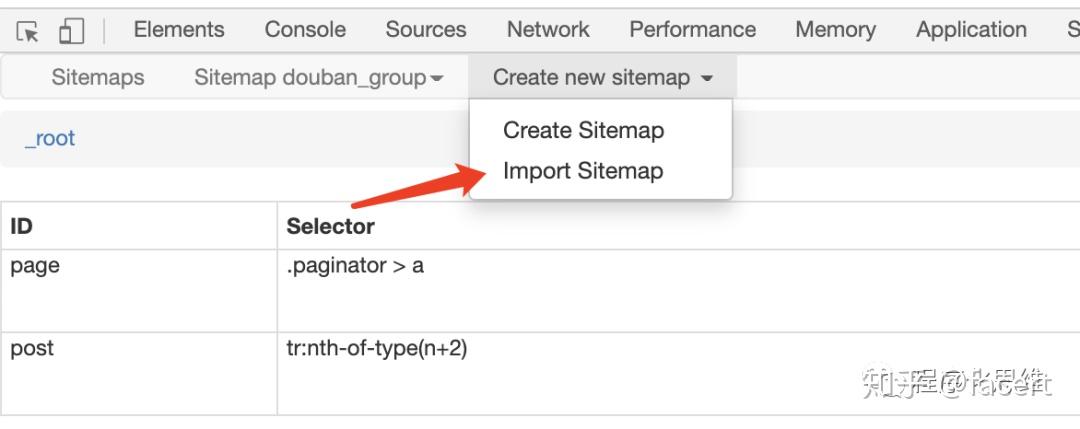
如果不想从头配置,导入 sitemap 也可直接爬取。
大家觉得好记得点赞哦,不要光收藏 ღ( ´・ᴗ・` )比心
