AI克隆人声
作者:瑞豪Serein
链接:https://zhuanlan.zhihu.com/p/28888889247
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:https://zhuanlan.zhihu.com/p/28888889247
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
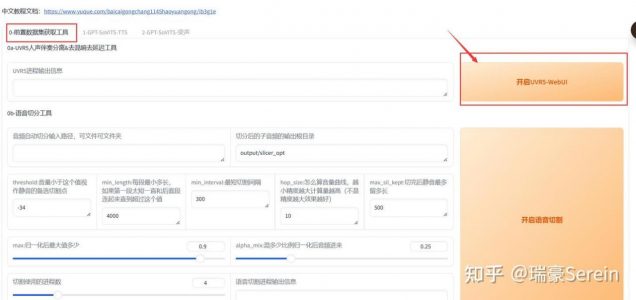
准备:GPT-SoVITS WebUI,还要准备一段30S时长以上的音频。
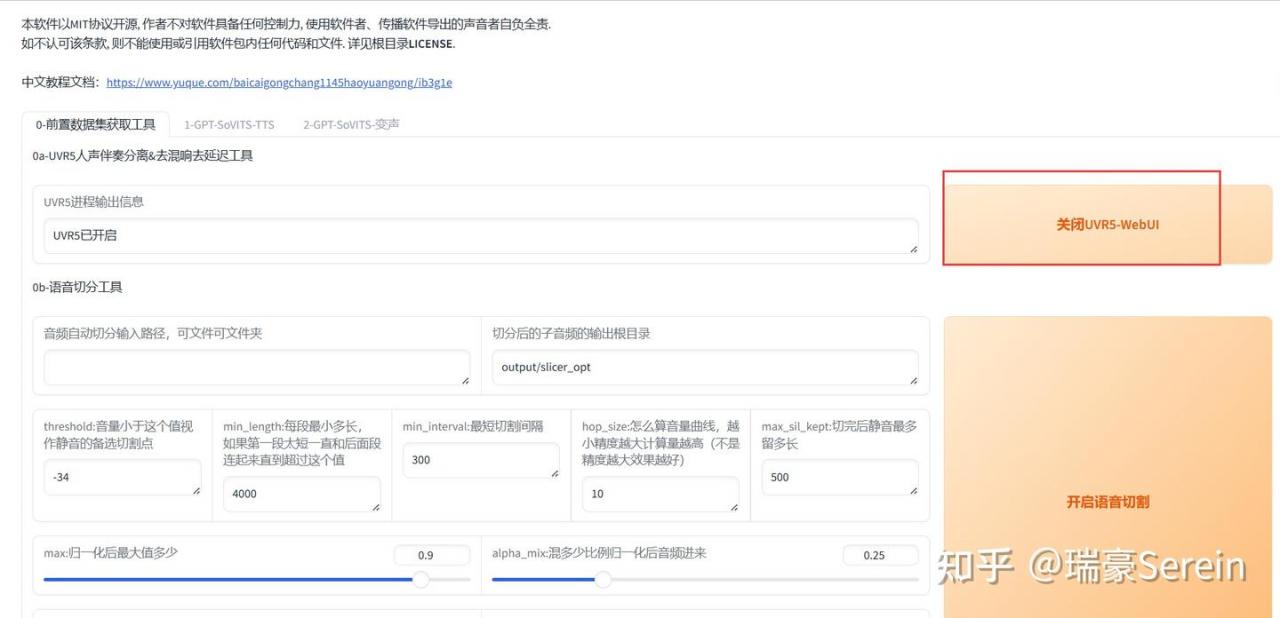
打开这个webui,点击按钮进行背景音乐处理。
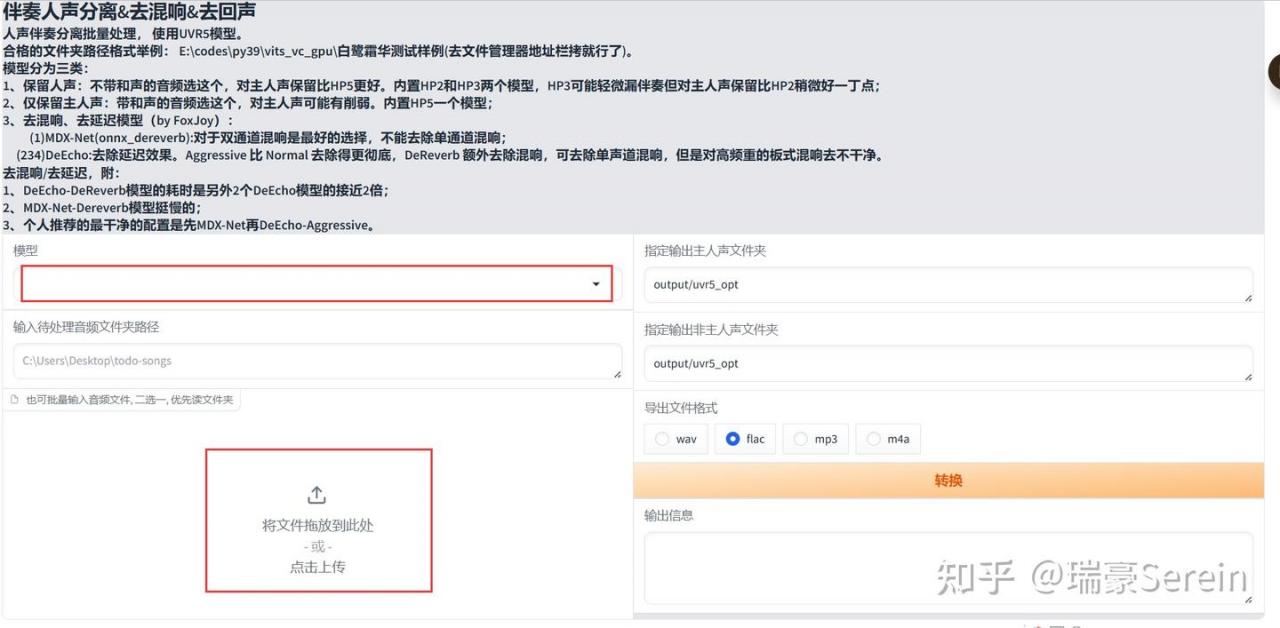
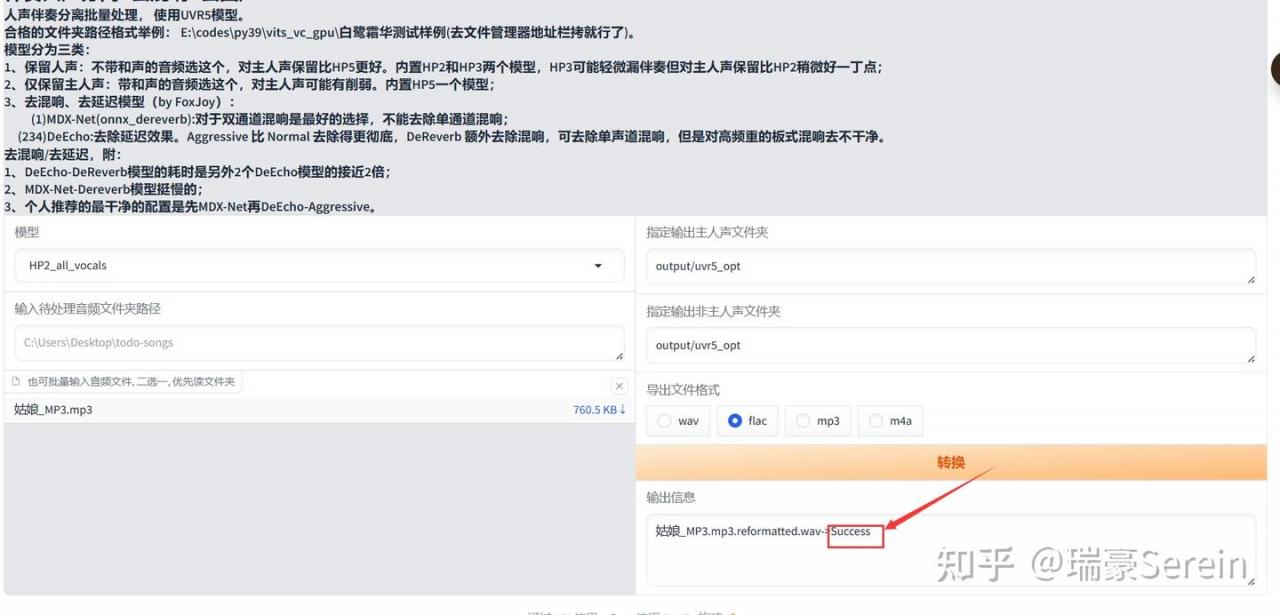
然后来到下面这个界面,把要处理的音频拖入上传,模型按照上方的中文描述选择其中一个模型。
其他的保持默认就行,导出文件格式WAV和FlAC都可以。
点击转换,出现下面的就表示成功了。
转换的音频,可以在output,uvr5_opt文件夹里找到
vocal是纯人声,另一个是背景音乐。
把分离好的人声存放好,放在自己的文件夹里面。
回到开始的界面,关闭这个
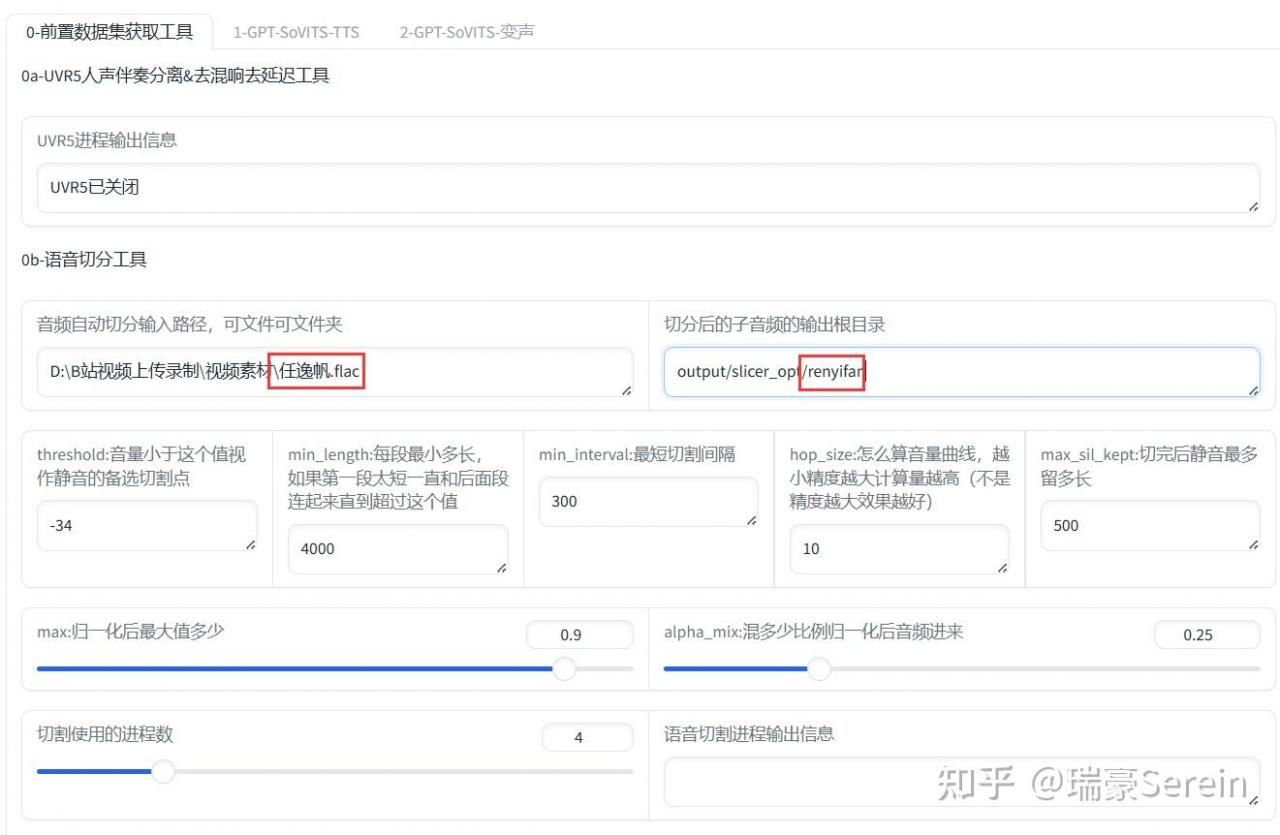
然后是语音切分工具,输入路径,包括文件名和后缀名,用斜杠跟前面的路径分隔开。
输出文件也用斜杠分开,后面输入文件名,用来新建文件。
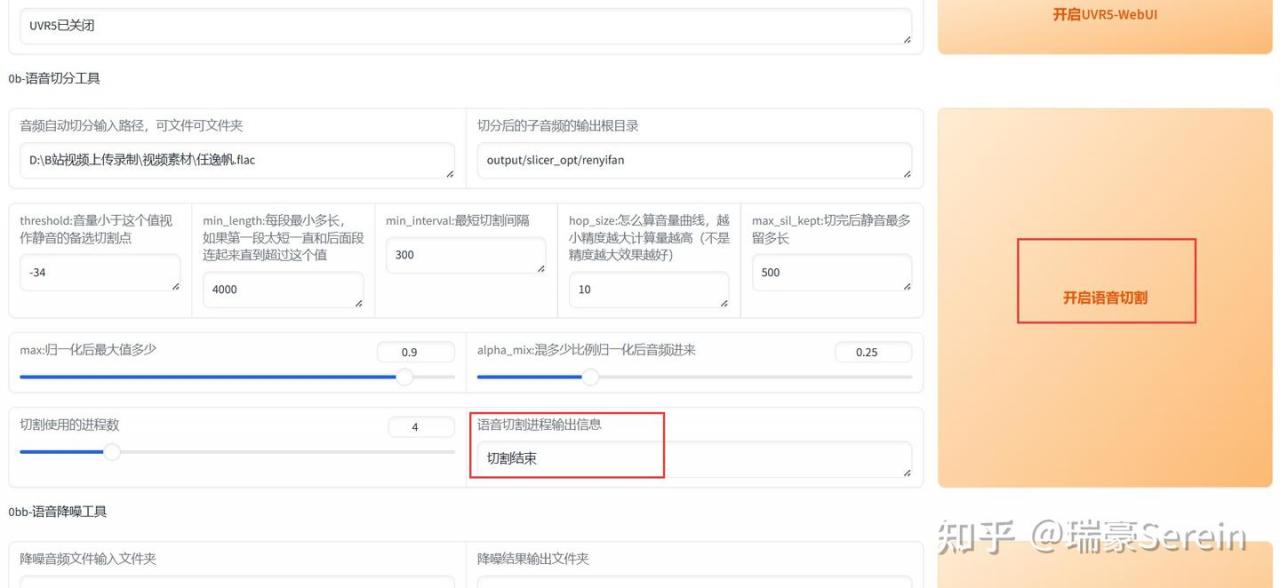
然后开启语音切割,等切割结束。
output\slicer_opt这个文件夹里能找切割后的文件。
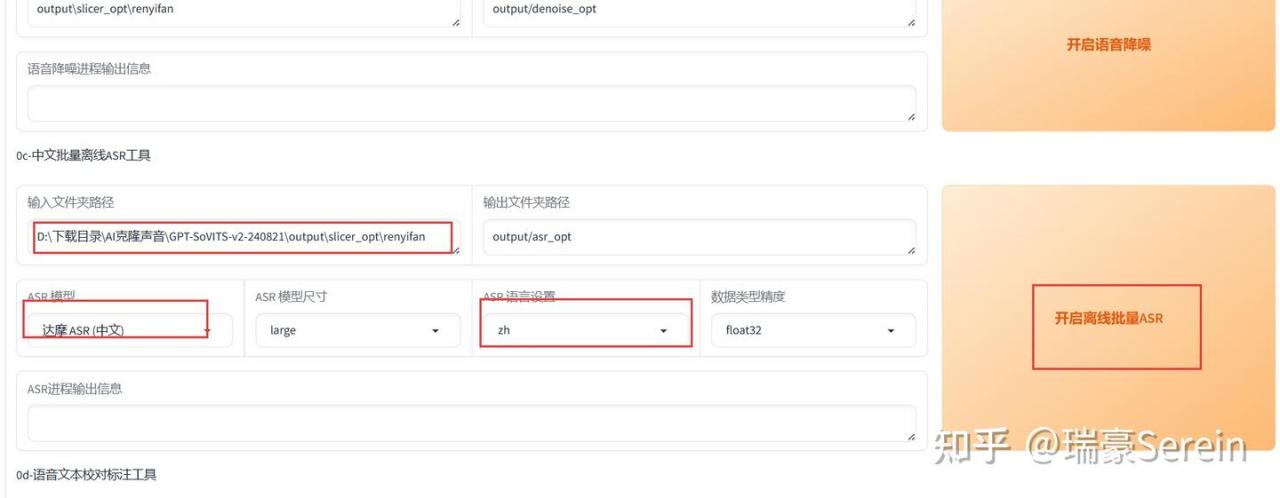
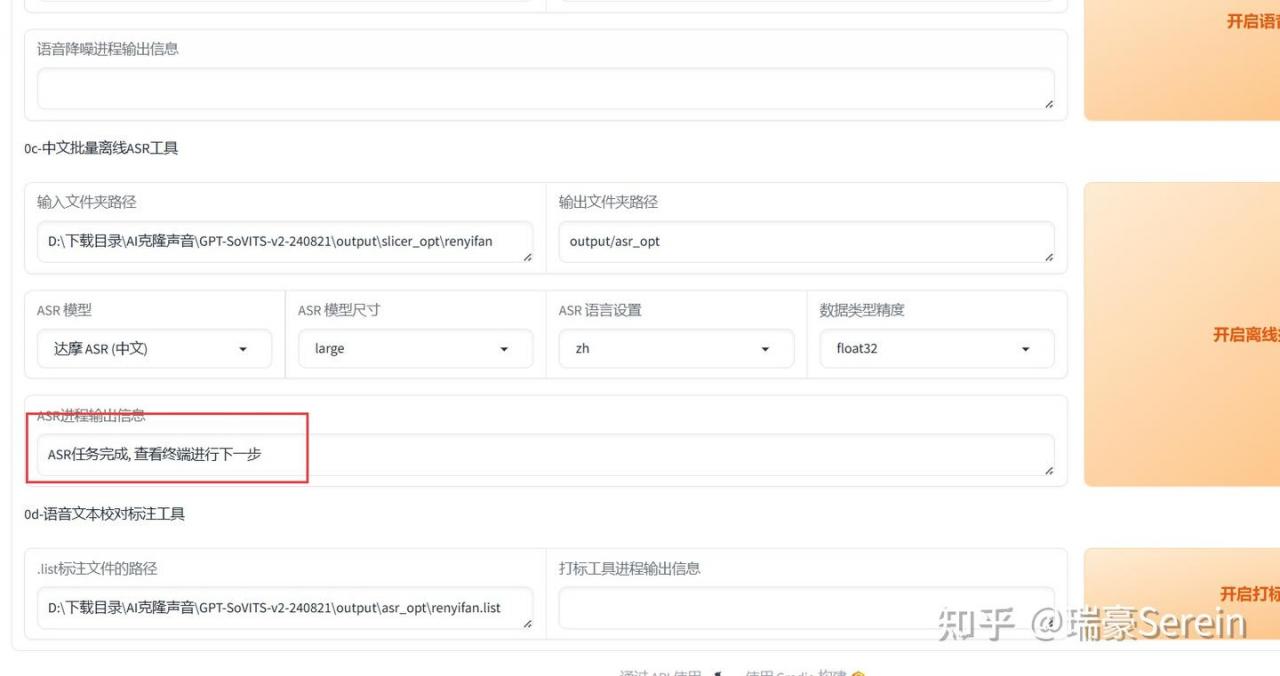
找到中文批量离线ASR工具
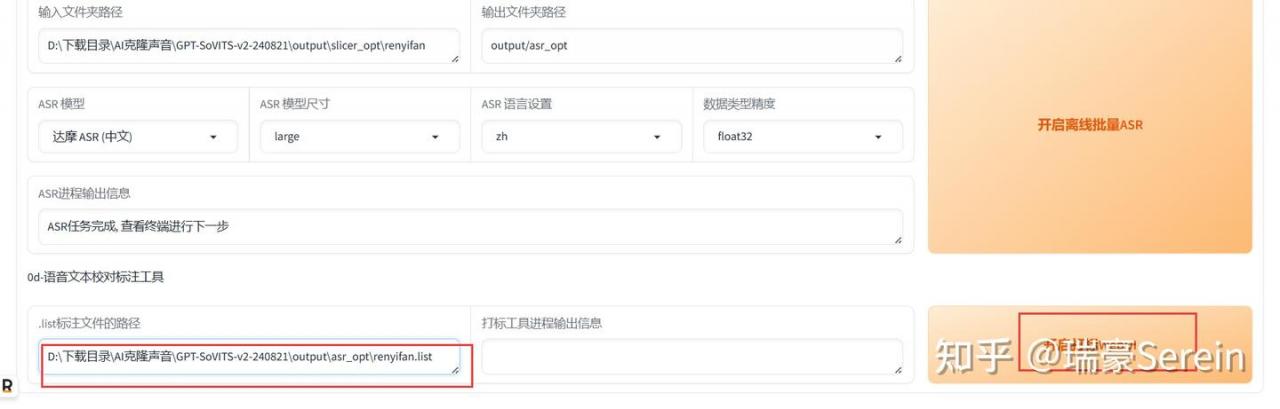
输入文件夹路径,就是刚刚分离的音频文件夹路径,复制过来
ASR 模型,原音频什么语言就选什么语言。
然后点击批量ASR
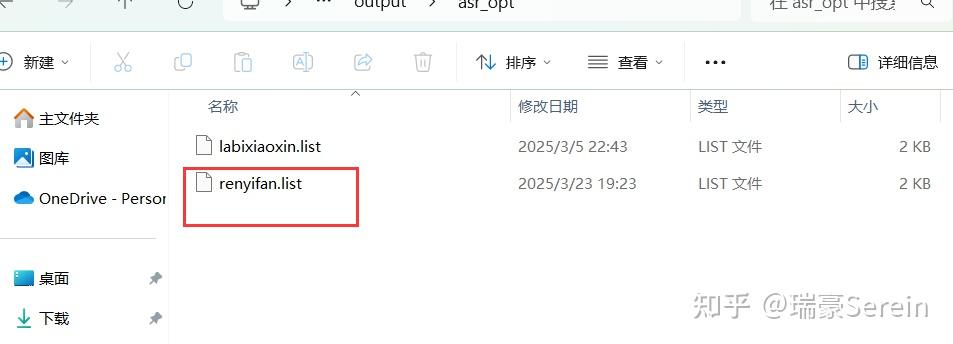
等待成功,能在output/asr_opt的文件夹下找到。
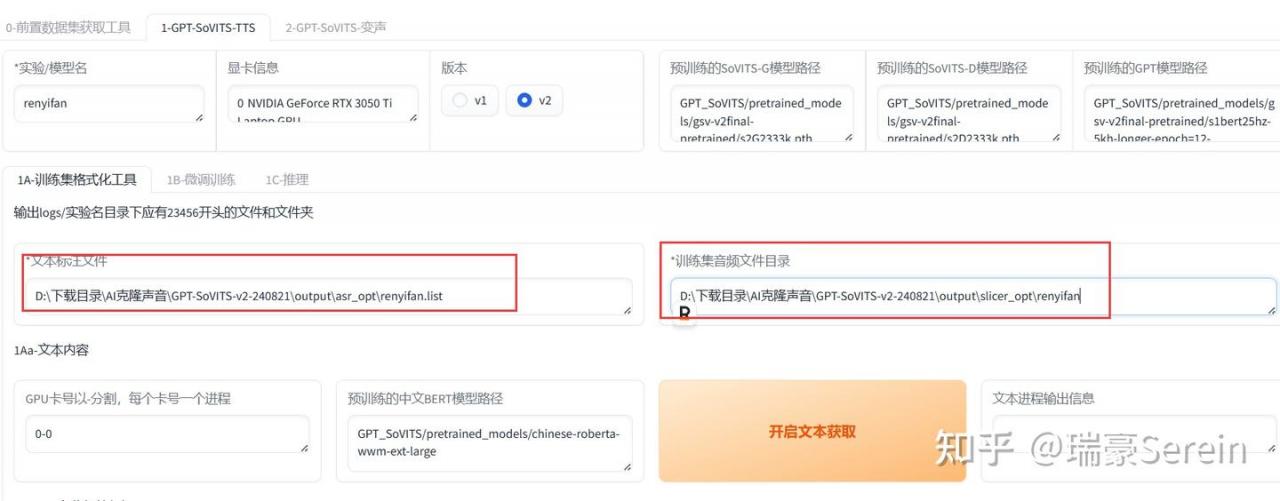
把list文件路径复制过来,打上斜杠把文件名和后缀都加上。
如果字没问题,点击保存,关闭页面。
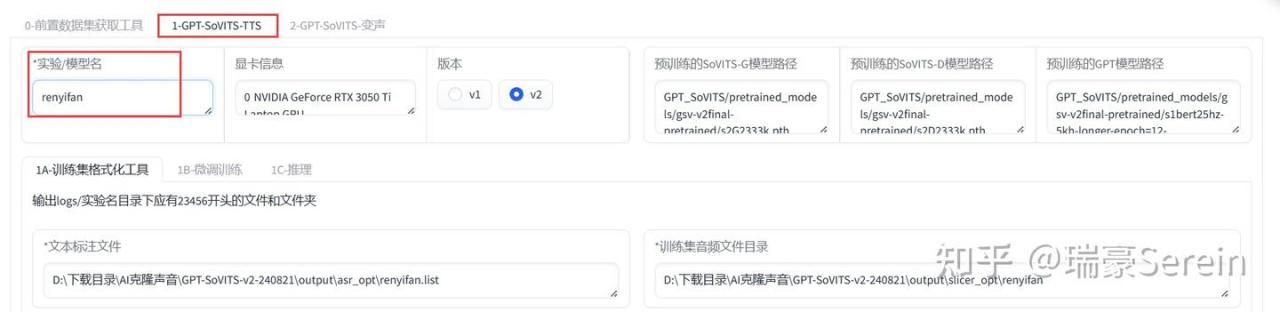
找到下面这个,给模型取个名字。
*训练集音频文件目录,就是切割后的音频文件目录
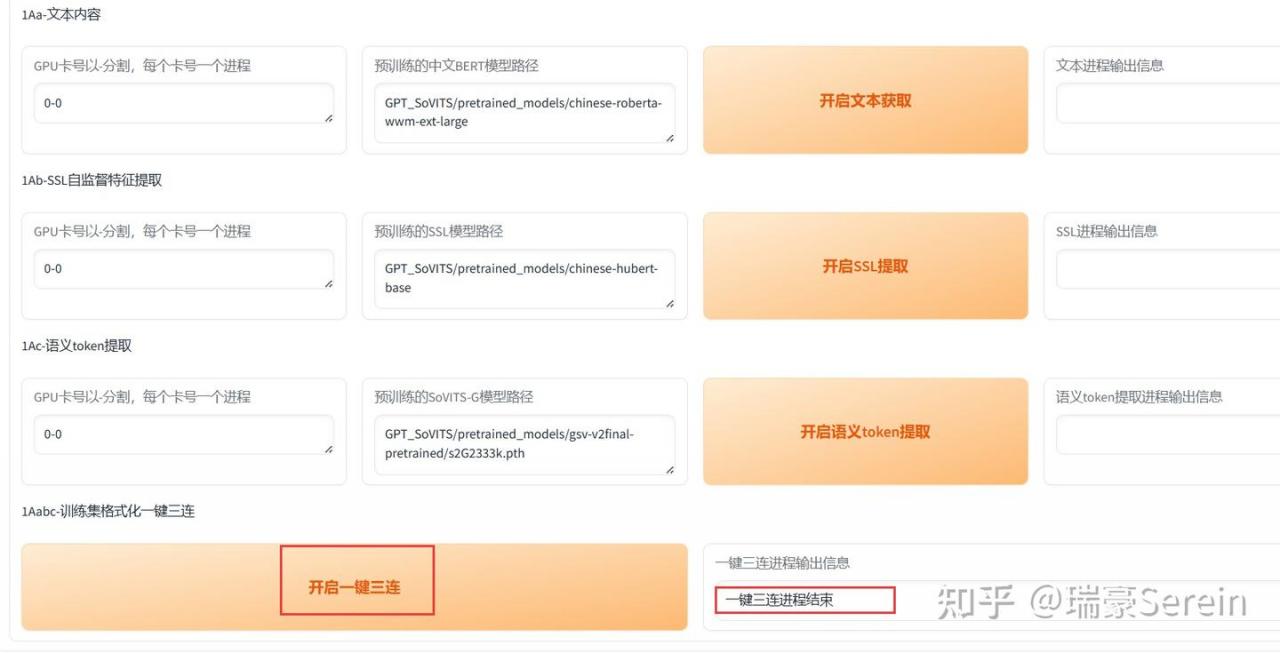
开启一键三连,等待结束。
D:\下载目录\AI克隆声音\GPT-SoVITS-v2-240821\logs\renyifan
上面这个就是一键三连生成的文件,放置的路径。
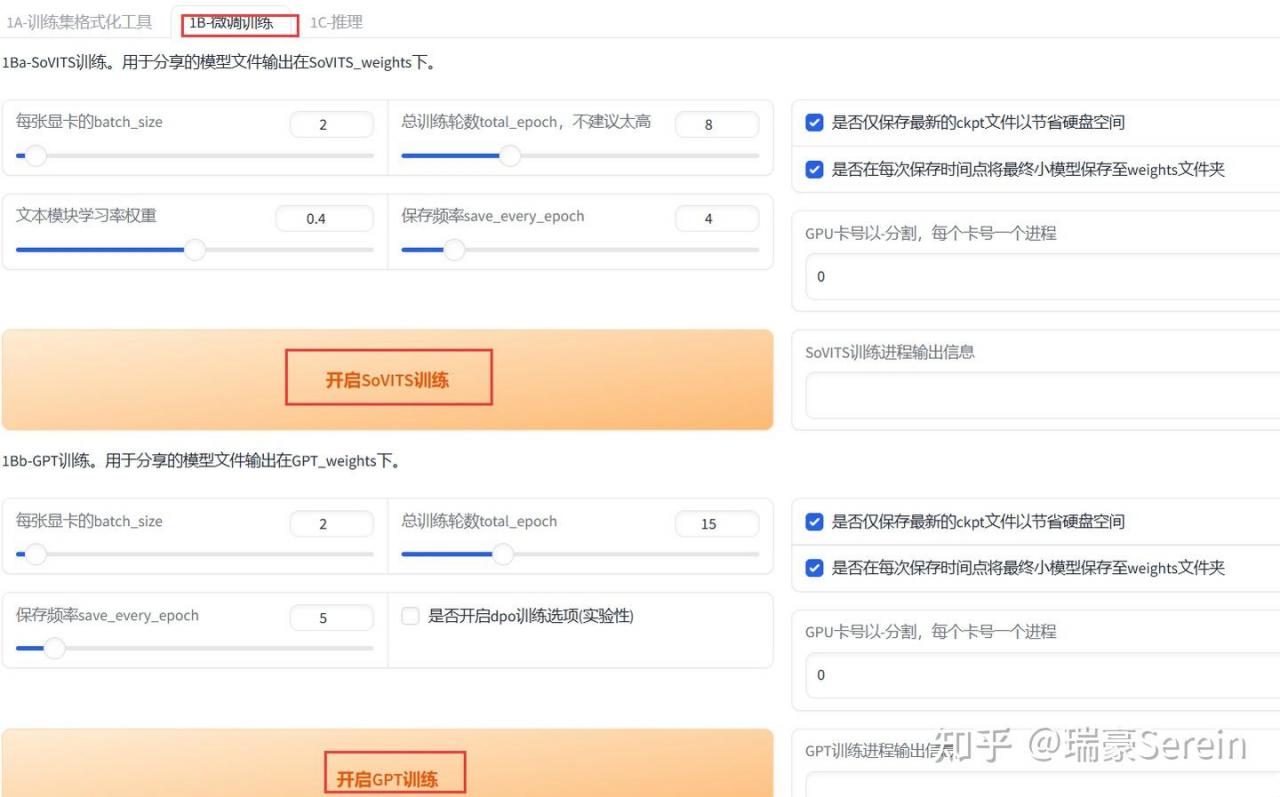
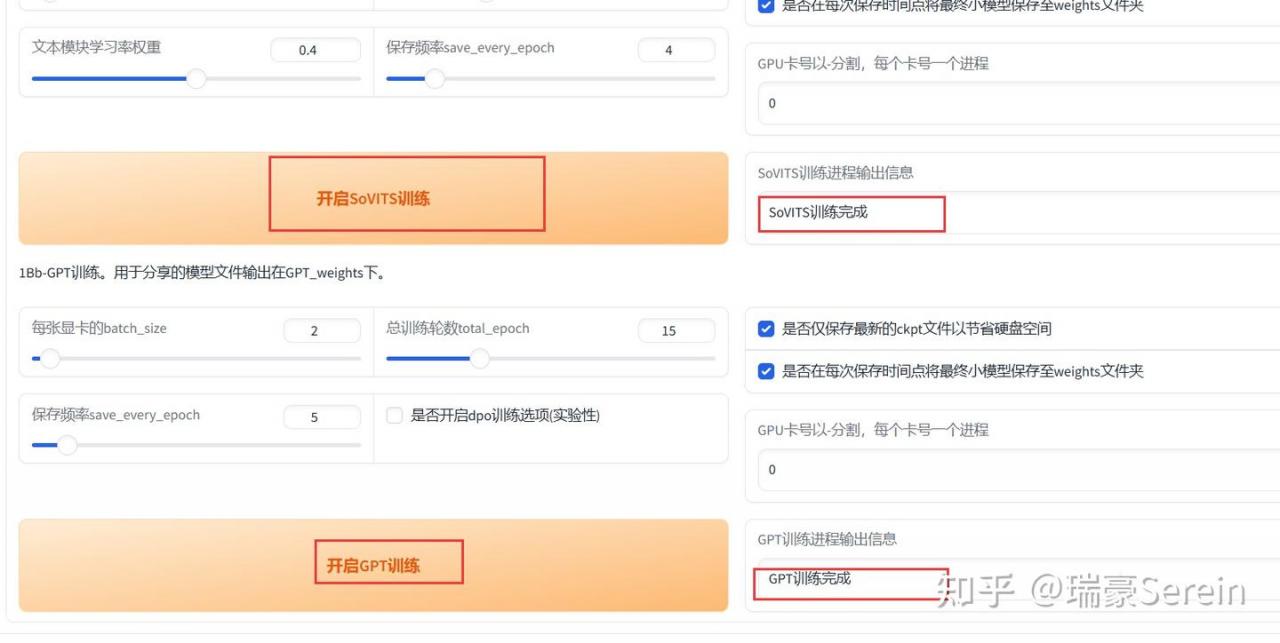
然后找到我微调训练。
依次点击训练。
训练完成
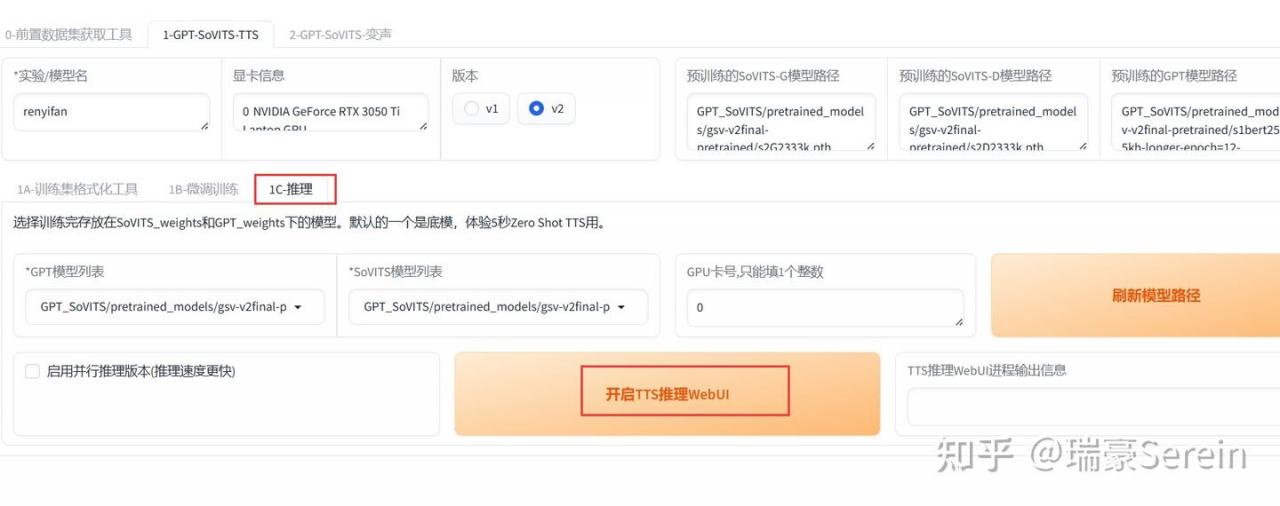
找到1c-推理
点击后来到新界面,先刷新一下路径。
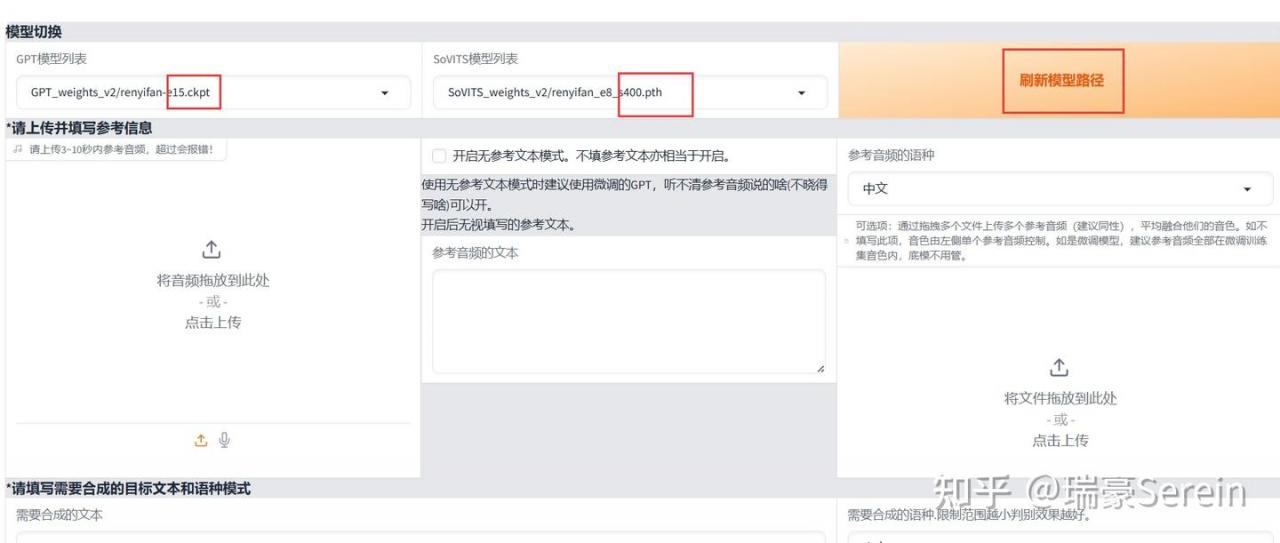
两个模型都选数字最大的
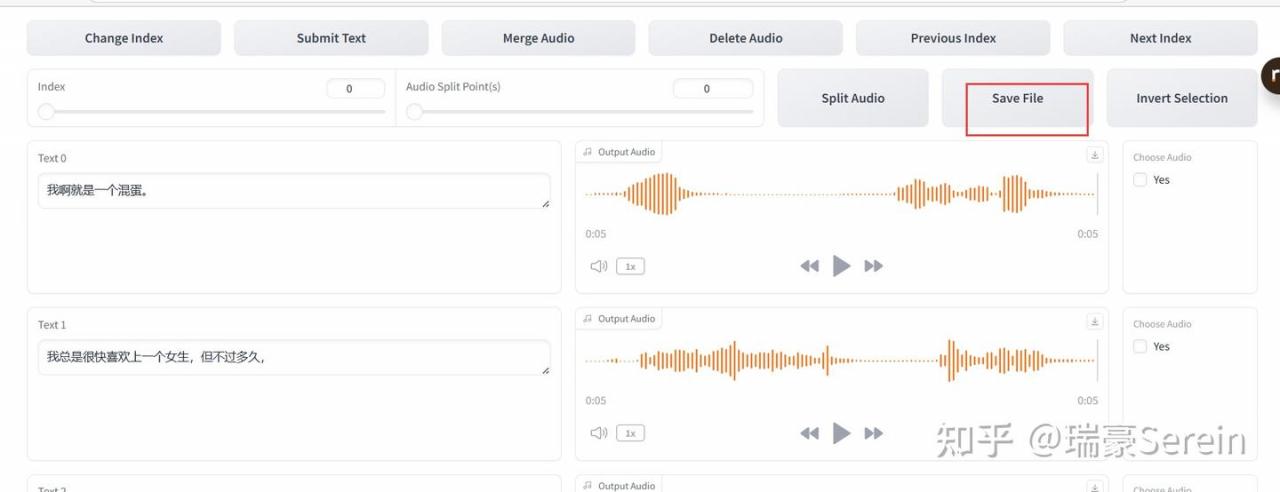
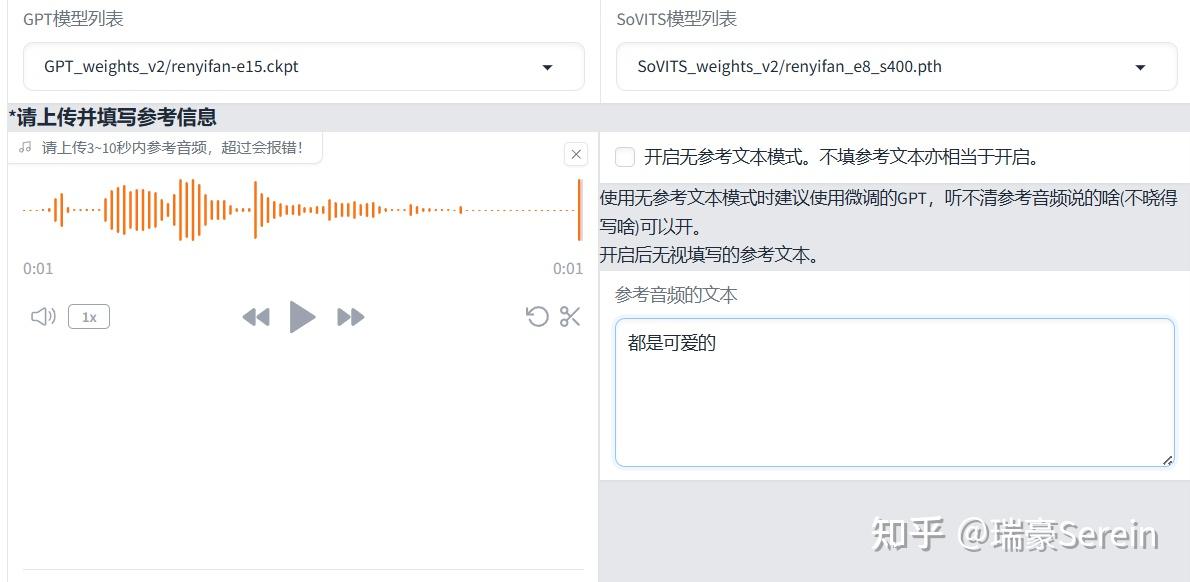
然后上传之前切分的音频,输入对应文本。
然后就可以合成自己想要的了
太长的段落可能效果不好,最好切分一下