OCR再升级!RAG精度飙升,让PDF文档解析【零损耗】
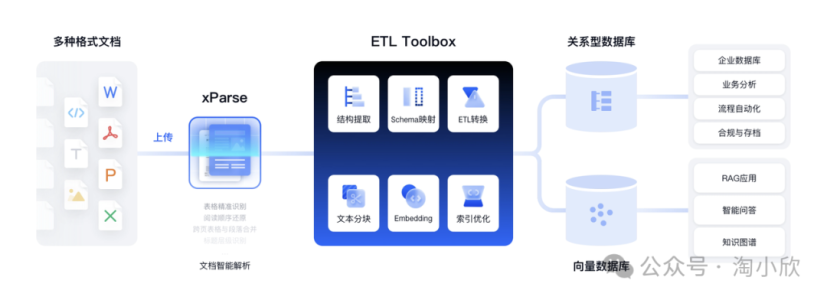
在AI应用极速发展的当下,LLM与RAG系统已成为构建智能问答、知识管理等高阶应用的核心引擎。然而,许多团队在项目落地时遭遇了现实的挑战:模型的实际表现往往难以达到预期。究其根源,是一个常被低估的关键环节:文档解析的质量。
现实中的知识载体——PDF报告、扫描文件、图文结合的技术文档——本质上是高度非结构化的。传统OCR工具就像个“近视的搬运工”,只能机械地把图像上的文字“抠”下来,当缺乏结构、语义断裂的“原料”被直接喂入RAG系统时,后果就是:
-
检索效率低下:系统难以精准定位包含答案的关键片段,在海量碎片中“大海捞针”,耗时费力。 -
答案准确性受损:上下文缺失或错位,导致模型“理解偏差”,生成跑题甚至错误的回答。 -
信息完整性打折:表格数据混乱、跨页信息断裂、图表意义不明,关键细节丢失。
可以说,文档解析的质量,直接决定了RAG系统乃至整个AI应用效果的上限。优质的解析不是简单的文字提取,而是对文档内容进行深度理解与结构化重建的过程。这正是TextIn xParse智能文档解析引擎致力于解决的痛点。
项目介绍
TextIn xParse文档解析是一款大模型友好的解析工具,能够精准还原pdf、word、excel、ppt、图片等十余种格式的非结构化文件,将其快速转换为Markdown或JSON格式返回,同时包含精确的页面元素和坐标信息。
支持识别文本、图像、表格、公式、手写体、表单字段、页眉页脚等各种元素,并支持印章、二维码、条形码等子类型,为LLM推理、训练输入高质量数据,帮助完成数据清洗和文档问答任务,适用于各类AI应用程序,如知识库、RAG、Agent或其他自定义工作流程。
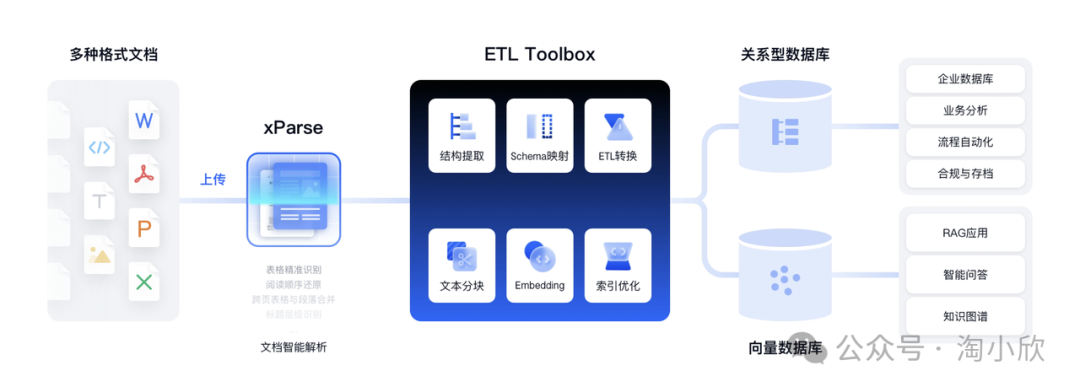
TextIn xParse的核心优势
-
多种版面元素高精度解析:精准识别标题、公式、图表、手写体、印章、页眉页脚、跨页段落,实现高精度坐标还原,并捕捉版面元素间的语义关系,提升大模型应用表现。 -
行业领先的表格识别能力:轻松解决合并单元格、跨页表格、无线表格、密集表格等识别难题。 -
阅读顺序还原准:理解、还原文档结构和元素排列,确保阅读顺序的准确性,支持多栏布局的论文、年报、业务报告等。 -
自研文档树引擎:基于语义提取段落embedding值,预测标题层级关系,通过构造文档树提高检索召回效果。 -
支持多种扫描内容:能良好处理各类图片与扫描文档,包括手机照片、截屏等内容。 -
支持多种语言:支持简体中文/繁体中文/英文/数字/西欧主流语言/东欧主流语言等共50+种语言。 -
集成强大的图像处理能力:文件带水印、图片有弯曲,都能一键解决,排除图像质量干扰。 -
开发者友好:提供清晰的API文档和灵活的集成方式,包括MCP Server、Coze、Dify插件,支持FastGPT、CherryStudio、Cursor等主流平台。
解析效果评测
密集少线表格识别
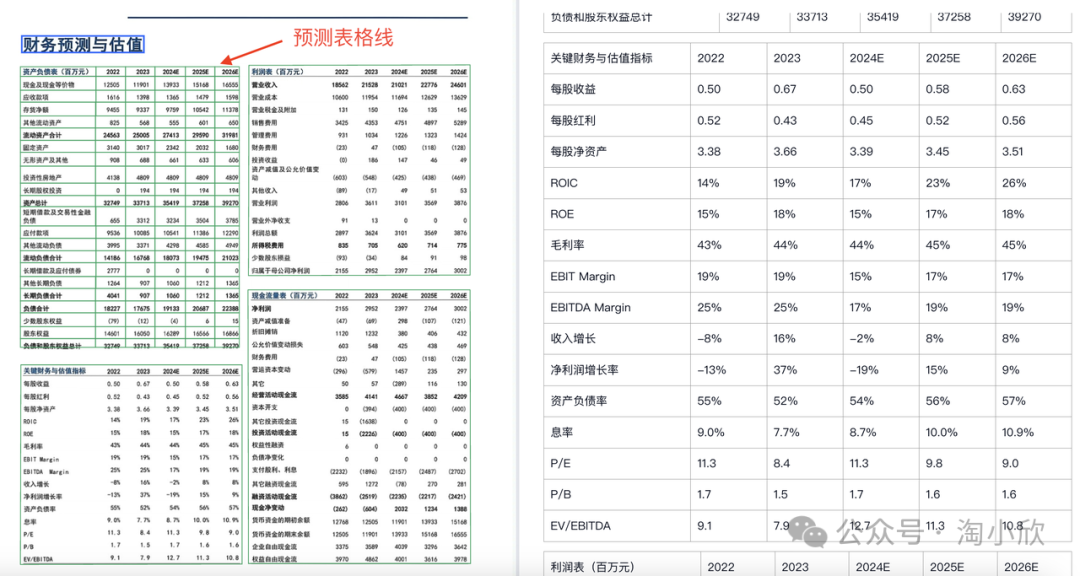
前端支持选中表格并在原图上显示模型预测的单元格,如图中左上表格效果。
跨页表格合并、页眉页脚识别

图表识别
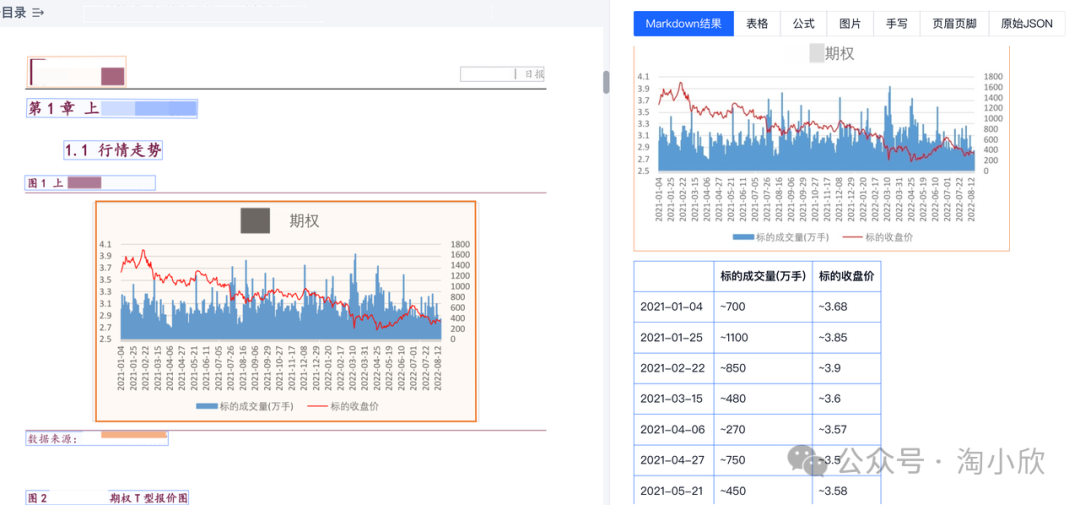
对于肉眼读取困难的图表,TextIn xParse也会通过精确测量给出预估数值,帮助挖掘更多有效数据信息,完成分析及预测工作。
标题层级识别

多栏版式还原阅读顺序

跨页段落内容块合并
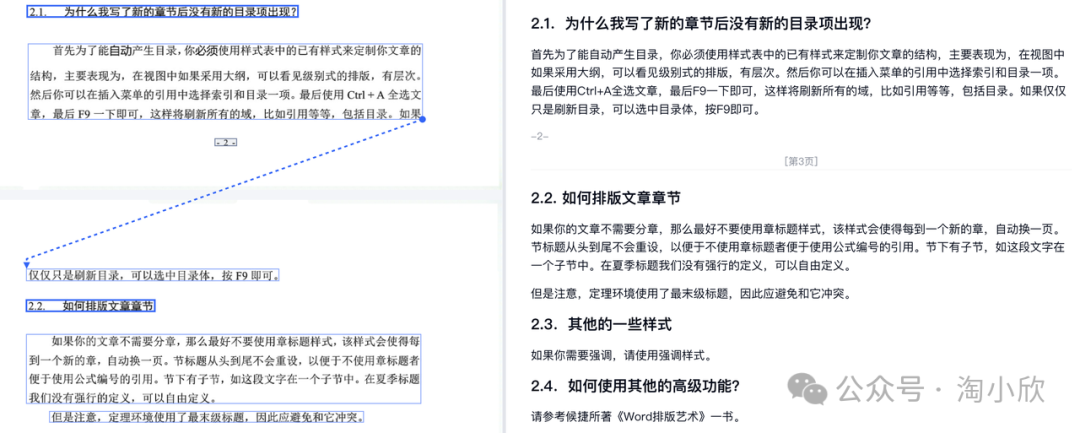
弯折图片识别

快速上手:两种使用方法
访问TextIn官网主页进行注册。
官网地址:https://cc.co/16YSW9
方法一:在线使用
TextIn提供了一个在线的Web平台,可以通过浏览器直接使用,无需编写任何代码即可快速试用API并感受效果。
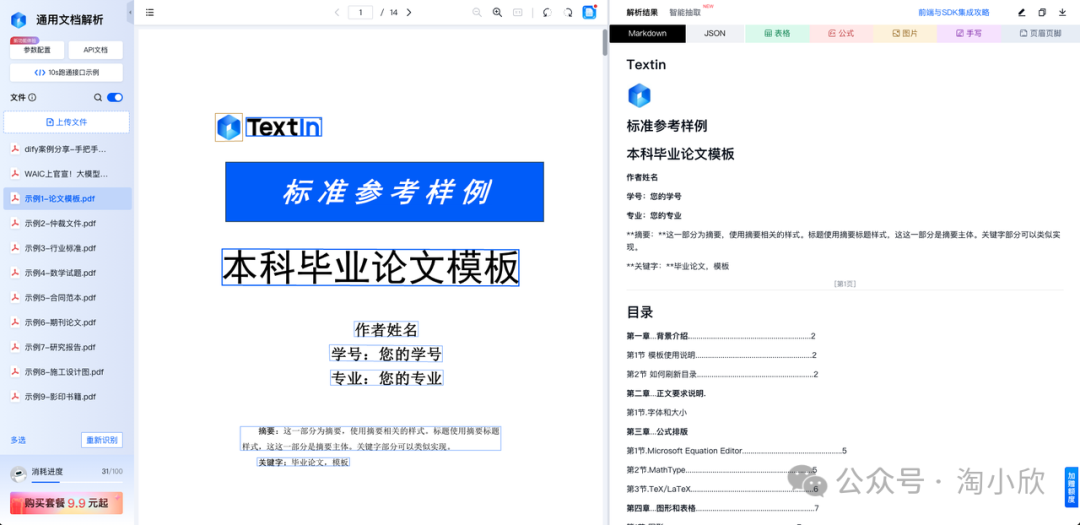
我们可以点击预存的示例文档,也可以自行上传文档(如发票、表格或报告等)在右侧快速查看解析结果并与原文档进行对照;右上栏切换查看JSON格式输出以及特定元素解析结果,同时也支持对解析结果进行编辑、复制、导出等操作;点击左侧“参数配置”可自定义参数。
方法二:API调用
首先前往“账号与开发者信息”,获取 x-ti-app-id 和 x-ti-secret-code。
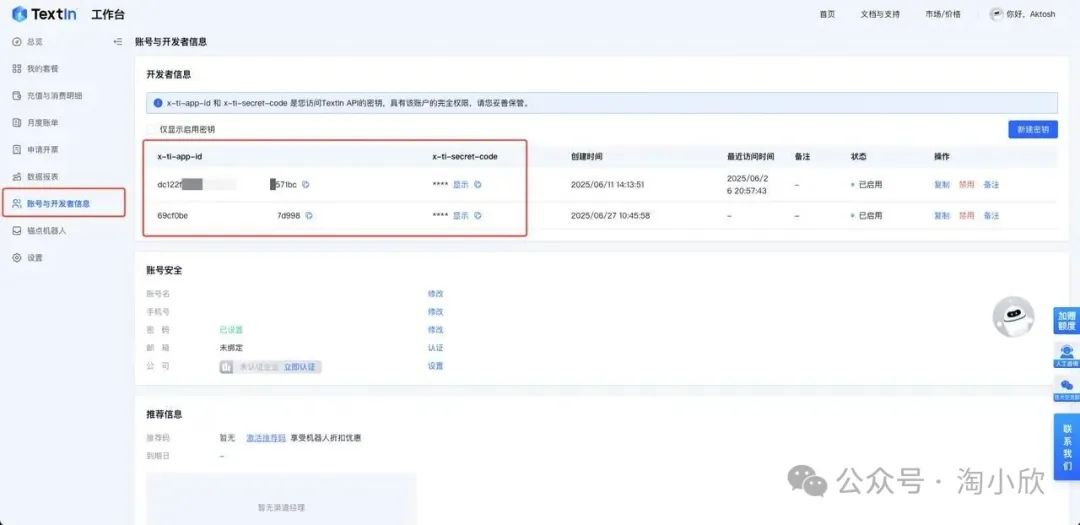
前置准备
后续步骤可根据实际使用场景在main函数中插入代码。
解析单个本地文件并保存结果
解析多个本地文件并保存结果至指定目录
更多应用示例详见产品文档:https://docs.textin.com/xparse/overview
集成使用
TextIn xParse可以在扣子平台快捷调用。
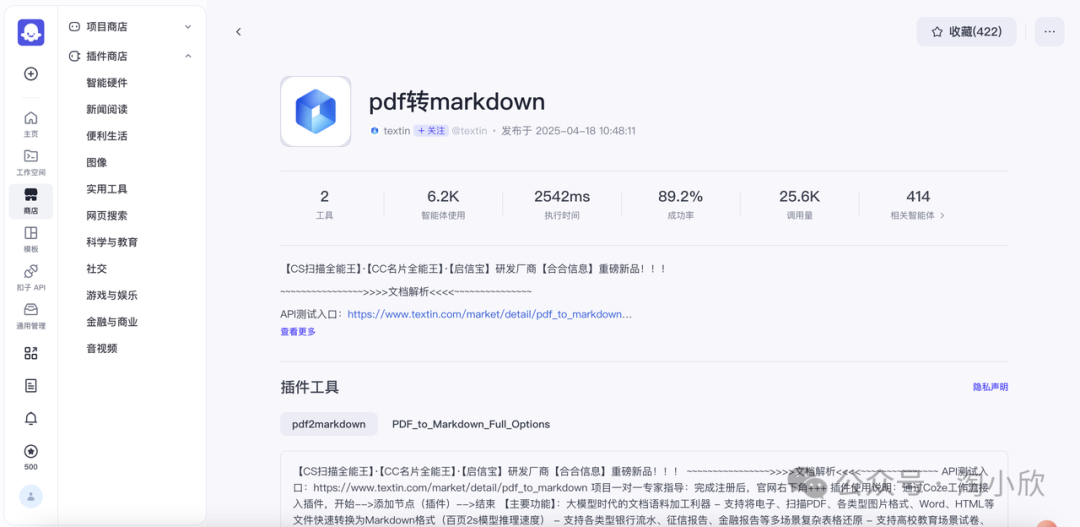
插件也已上架Dify商城。
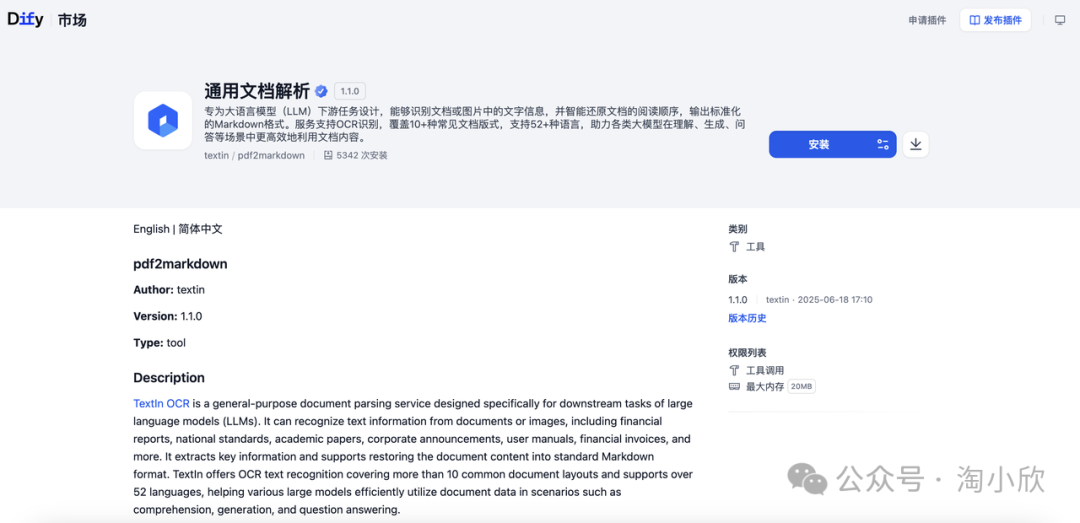
支持在Cherry Studio、Cursor等平台直接调用MCP Server。
总结
在LLM与RAG系统日益成为智能应用核心的今天,文档解析是决定AI效能上限的关键预处理基石。TextIn xParse通过其深度结构化解析能力为RAG系统提供了高质量输入,从根本上解决了检索不准、生成偏差、信息缺失等瓶颈问题。
目前,开源社区也拥有不少文档解析工具,与之相比,TextIn xParse在工程化落地层面具备显著优势:
-
高效迭代与性能保障:闭源模型持续优化,解析准确率与复杂文档处理能力超越主流开源方案,显著降低调试与适配成本。 -
灵活部署,安全可控: -
轻量级在线使用:提供完善的前端交互界面,支持用户即时上传解析、结果可视化预览与导出。 -
企业级私有化部署:满足金融、政务等高敏感场景对数据不出域、全链路安全的严苛要求。
-
-
无缝集成与批量化处理:提供标准化API接口及SDK,可轻松嵌入自动化流水线,支持海量文档并发解析,赋能智能客服、知识库构建、合规审查等规模化场景。
TextIn xParse的价值不仅在于技术领先性,更在于其以用户为中心的产品设计:
-
开箱即用的在线平台:降低非技术用户的体验门槛,快速验证解析效果。 -
开发者友好的API生态:标准化JSON输出、详尽的文档与代码示例,大幅缩短集成周期。 -
企业级服务保障:私有化版本提供定制化适配、性能优化与专属技术支持,确保关键业务稳定运行。
TextIn xParse可以为AI系统构建一条可靠、高效、安全的数据供应链,它不仅是OCR的工具升级,更是企业释放RAG潜力、打造下一阶段智能应用的战略基础设施。
欢迎扫码加入我们的交流群,或点击阅读原文链接,在线免费试用处理1000页的文档,与我们共同探索高效的文档智能未来。