现在有什么开源的语音识别吗?直达问题

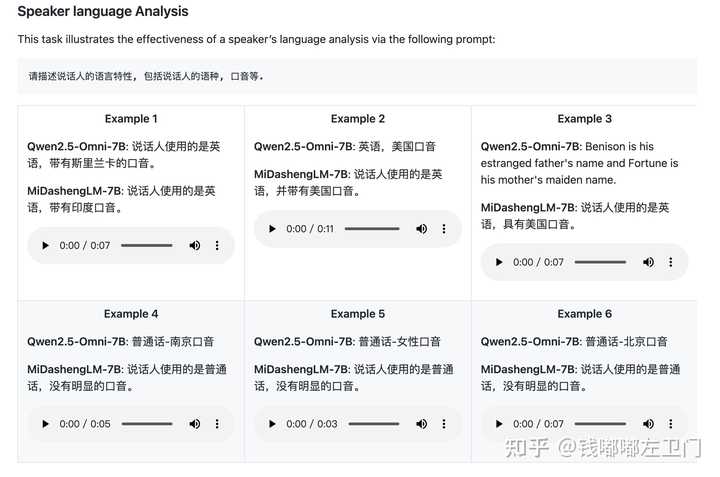
小米最近有开源一个声音理解模型,在AI加持下的语音识别不仅是语音识别,而且是「语音理解」的了,小米开源AI跨场景声音理解大模型 :MiDashengLM 。可以做到更精准的识别,比如识别出语音中说话人的音色特征、识别说话人的语种和口音、识别音频中的乐器等等比较更高级的语音理解功能。

简介:
MiDashengLM 是小米研究院开源的一个高效音频理解项目,定位「声音基座」,可一次性听懂语音、环境声、音乐然后输出自然语言描述。GitHub开源关键字:xiaomi-research/dasheng-lm[1],目前有200+个star⭐。也可以到他们的官方网站[2]查看更多信息以及示例,以及看一下他们的技术报告[3]。huggingface开源关键字mispeech/midashenglm-7b[4]。
畅想一下,可以给所有设备上的小爱同学加上聆听万物的能力?
主要功能:
1. 语音转写与理解:高准确率语音识别 + 语义理解。
2. 环境声事件识别:识别并描述背景声/突发声。
3. 音乐全维理解:节奏、风格、情感、歌词摘要。
4. 跨模态问答:用自然语言对音频提问并回答。
5. 发音/歌唱反馈:实时打分与改进建议。
6. 离线声音编辑:基于自然语言指令剪辑、降噪、增强。
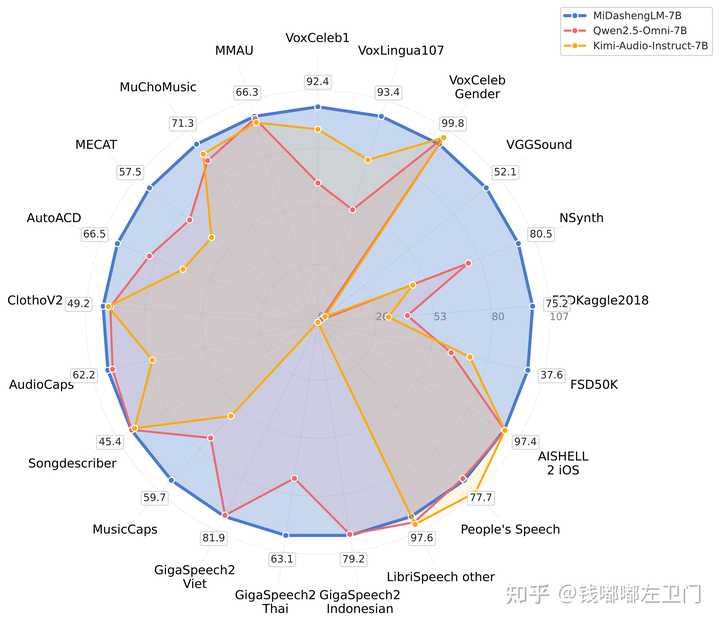
评测对比:
示例: