如何使用AI自动化简历筛选过程?

作者:钱嘟嘟左卫门
链接:https://www.zhihu.com/question/950909881/answer/1974051375278216586
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

链接:https://www.zhihu.com/question/950909881/answer/1974051375278216586
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
AI自动化筛选简历的第一步就是需要自动解析,把形形色色、不同格式的简历全部都解析并格式化成需要的。利用大模型能力做OCR的识别已经是比较成熟的了,最近阿里开源了一个使用大模型来批量简历解析的工具,据说,阿里巴巴内部的HR招聘已经使用上了这一套。
简介:
SmartResume 是阿里巴巴于开源的AI智能简历解析系统,将PDF、图片、Word等12种格式的非结构化简历,秒级转换为结构化数据(如姓名、电话、工作经历等)。主要解决了企业招聘中简历格式复杂、手动处理效率低的问题。
GitHub开源关键字:alibaba/SmartResume[1],目前已经有200+个star⭐️。可以去arxiv[2]看一下技术报告有更详细的介绍。
主要功能特点:
1. 多格式支持:支持解析 PDF、图像文件以及常见的 Office 文档格式(如 DOCX)。
2. 高精度解析:整体信息提取准确率高达 93.1%。
3. 布局检测:具备高精度的布局检测能力,能够重建正确的阅读顺序。
4. 防幻觉机制:后处理模块验证提取的每个字段是否真实存在于原文本中,防止LLM”编造”信息。
5. 高性能:单页处理时间仅需 1.22 秒。
6. 支持多语言。
7. 部署模式:支持本地部署、vLLM加速、远程API调用。
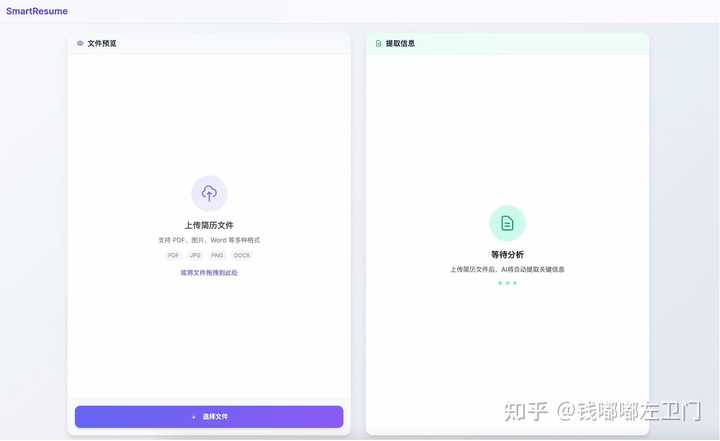
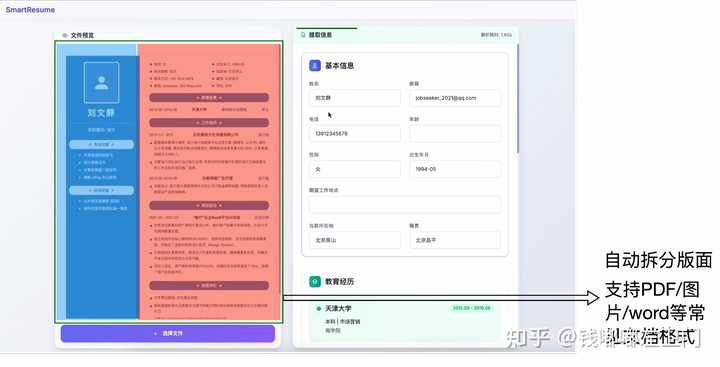
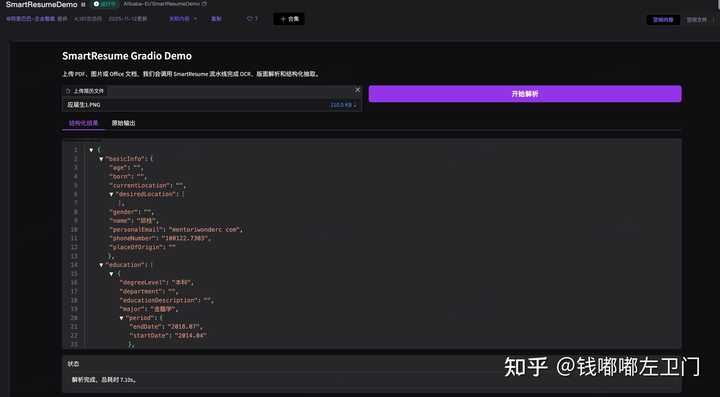
示例截图:
试用一下:
阿里在modelscope上面搭建了一个试用页面,我随便上传了一个图片格式的示例简历,基本都提取出来格式化的JSON数据了。
环境要求:
– Python >= 3.9
– CUDA >= 11.0 (可选,用于GPU加速)
– 内存 >= 8GB
– 存储 >= 10GB
本地模型部署额外要求:
– GPU: 推荐 NVIDIA GPU,6GB+ VRAM(用于本地模型推理)
– 内存: 推荐 16GB+(本地模型需要更多内存)
– 存储: 每个模型需要 2-10GB 存储空间
参考
- ^alibaba/SmartResume https://github.com/alibaba/SmartResume
- ^Layout-Aware Parsing Meets Efficient LLMs: A Unified, Scalable Framework for Resume Information Extraction and Evaluation https://arxiv.org/abs/2510.09722