是否有自动生成字幕的软件?
看到题主的描述,简直就是一年前的我。
当时也是刚接手公司的视频,用剪映,一开始觉得它的字幕功能挺香,点一下就自动生成了。但后来一遇到多人访谈,或者稍微长一点的内部培训视频,直接抓瞎。
所有人的字幕都混在一起,一个颜色,一个格式。我得一句句听,这是老板说的,那是同事A说的,手动拆分,再调整时间轴,工作量瞬间翻倍,跟自己从头打字也差不了多少了。
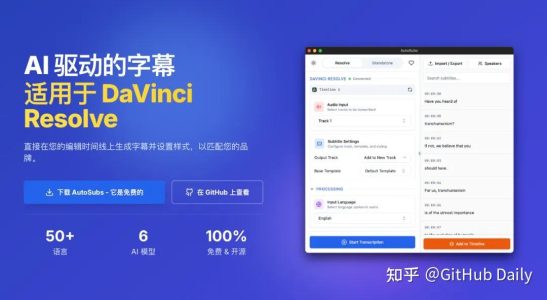
后来折腾了一圈,发现一个开源免费的工具叫 AutoSubs,用到现在,基本成了我的主力字幕工具。
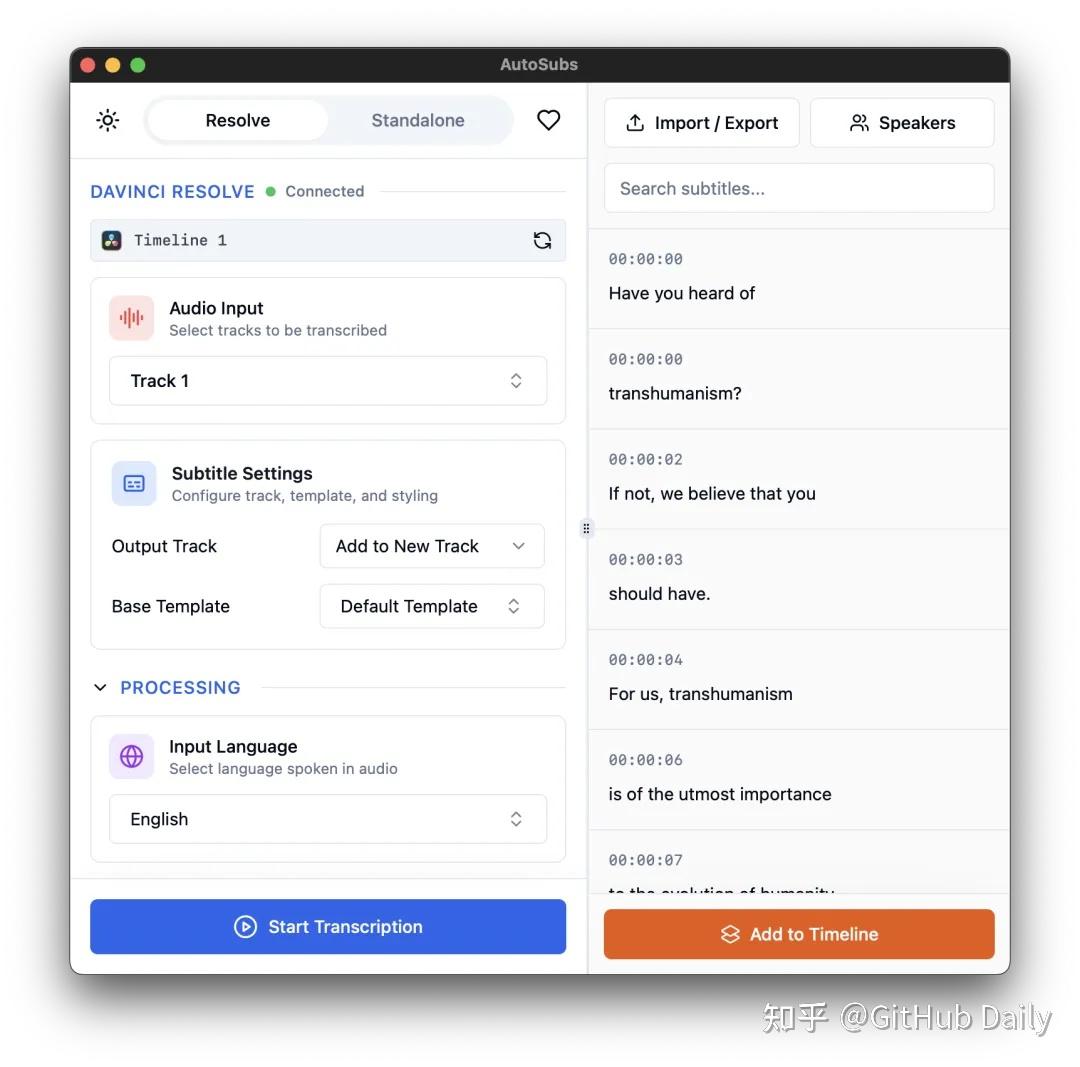
最牛的是,它能分清谁在说话
这是我最推荐它的原因。很多软件能识别语音,但分不清说话人。AutoSubs 能自动识别出视频里有几个人在说话,然后给每个人的字幕标上不同的颜色。
我上周刚做了一个三人对谈的视频,用它跑完,直接生成了三种颜色的字幕,谁说了哪句话一目了然。后期我只需要把颜色统一改一下,或者在前面加上“主持人:”、“嘉宾:”就行,省下的时间不是一点半点。
对于做访谈、多人对话、或者会议记录这种视频,这个功能简直是神器,基本就是从加班到准点下班的区别。
完全本地运行,公司视频也能放心用
题主是给公司做视频,这点还挺重要的。
很多在线的字幕工具,都得把视频上传到他们的服务器去处理。公司的视频,尤其是还没发布的,万一泄露了就是个大问题。
AutoSubs 是个本地软件,下载安装到你电脑上用。整个过程视频文件都不会离开你的硬盘,跟用 Word 写文档一样,断网也能用。对于处理公司内部资料,安全感直接拉满。
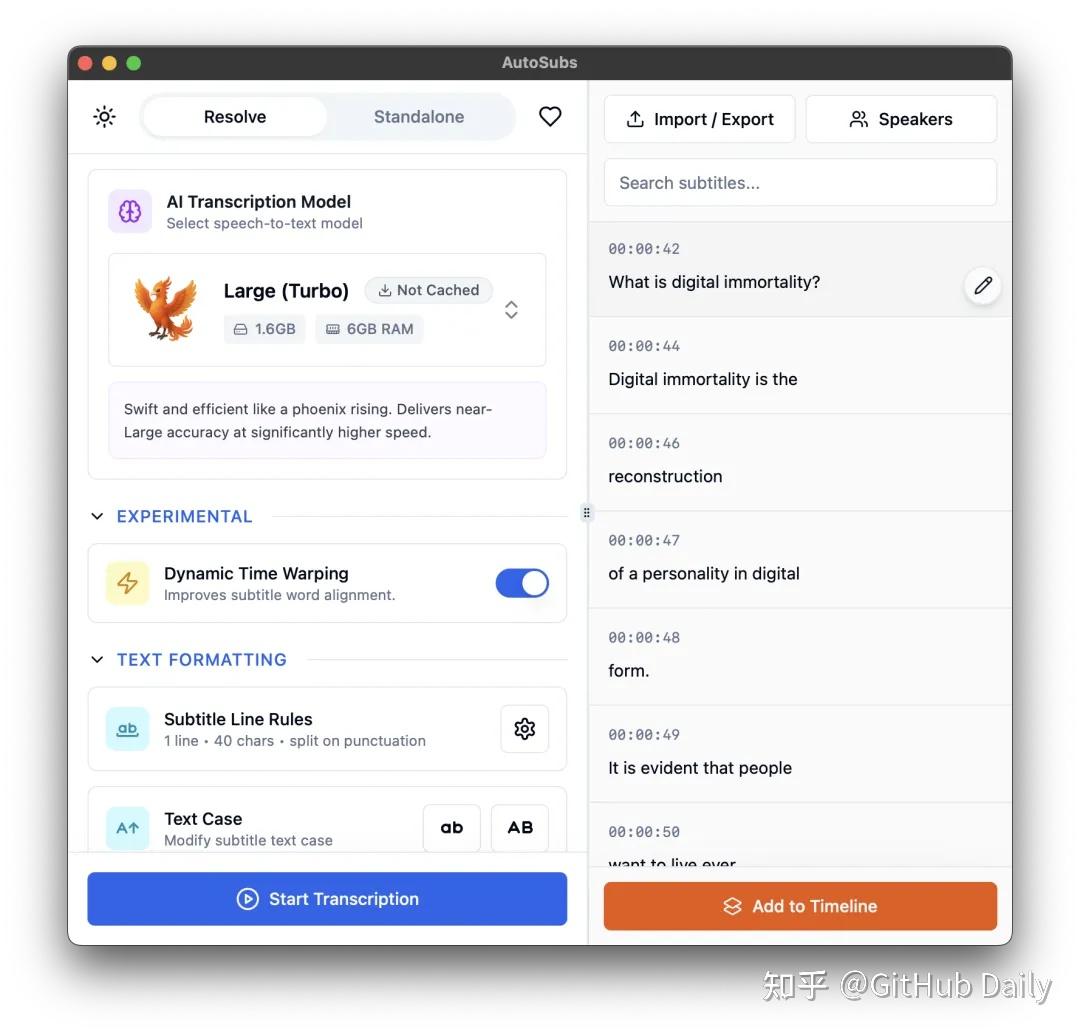
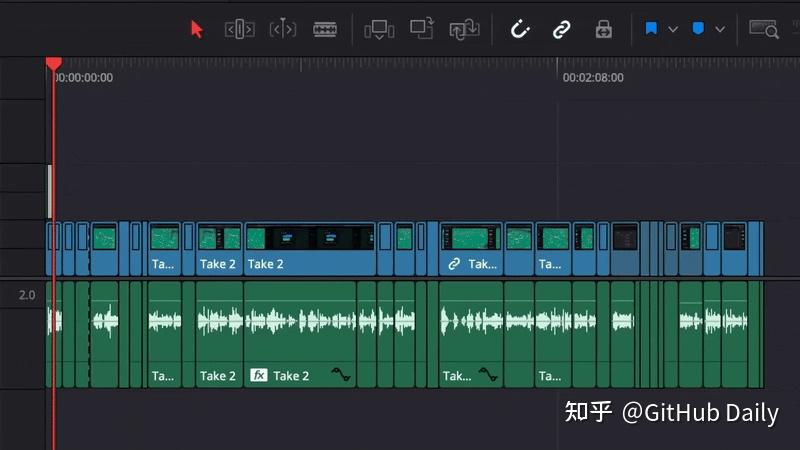
而且识别率也挺高的,因为它用的是 OpenAI 的 Whisper 模型,这玩意儿的准确度是公认的第一梯队。只要你视频的音质不是太差,生成的字幕基本上改改错别字就能用。
它还内置了一个简单的字幕编辑器,识别完了有哪几句不对,可以直接在里面改,不用再导回到剪辑软件里一句句调。
当然,它也有缺点。
它主要解决的是从“无”到“有”快速生成字幕的问题。
但如果你想要什么酷炫的字幕动画、艺术字效果,那还是得靠剪辑软件。
我一般的流程是,用 AutoSubs 生成最基础的 SRT 字幕文件,然后导入到 Final Cut 或者 DaVinci Resolve 里去做样式。
如果你用的是 Windows 或者 Mac,安装很简单,直接下载安装包点两下就行。
总的来说,如果你也像题主一样,被手动打字幕、对时间轴搞得头大,特别是要做访谈或多人对话视频,那这个工具值得一试。
关键是它免费、本地运行,还带说话人识别,这套组合拳下来,效率提升真的非常明显。
项目在 GitHub 上,地址:https://github.com/tmoroney/aut