把阅读效率提升 10 倍,手把手教你用 AI +RSS搭建全自动AI新闻早报
把繁琐的整理交给 AI,把宝贵的思考时间留给自己
大家好,我是三石。
作为一名产品经理,每天早上醒来的第一件事就是查看AI领域最新新闻资讯,生怕漏掉什么重要的产品更新
但是在海量信息中发掘有价值的内容并不容易,我们可能花费了 90% 的时间在查找新闻,阅读重复的信息或者浏览一些无价值的水文上
与其被算法投喂,不如用 AI 反向收割信息。
在工作之余,利用 AI + Coze + RSS,我为自己搭建了一套“AI新闻早报系统”—— AI早咖啡,实现新闻的自动化获取和推送:
- 定时抓取 高质量信源;
- 清洗掉所有的广告和废话;
- 提炼出带有观点的核心摘要;
- 推送一份清爽的“AI早报”到我的邮箱。
哪怕你没有任何代码基础,跟着我的 SOP,你也能搓出你自己的“超级情报员”。
拒绝空谈,我们直接开干
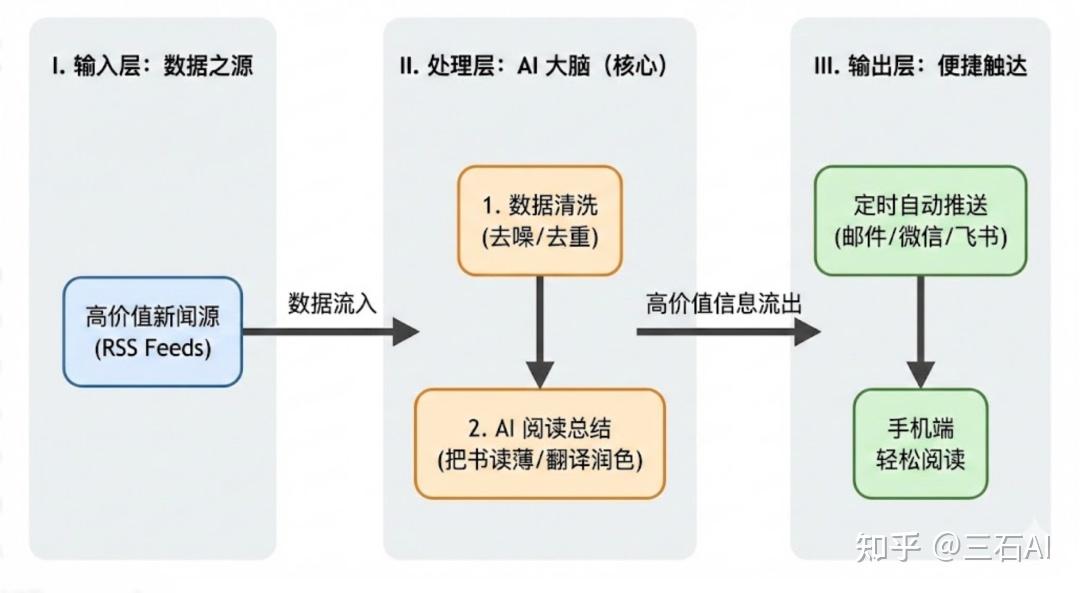
01. 工作思路
动手之前,首先明确我们的需求目标:自动化获取高价值的新闻,对文章内容进行清洗过滤总结,定时推送到我的手机
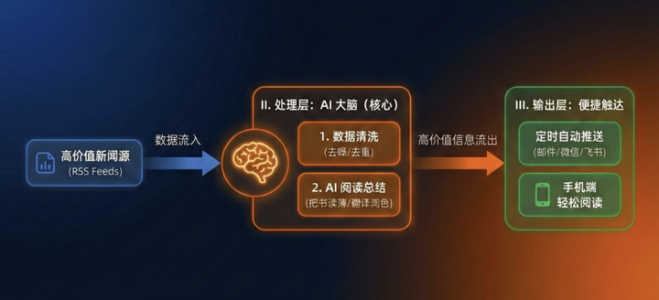
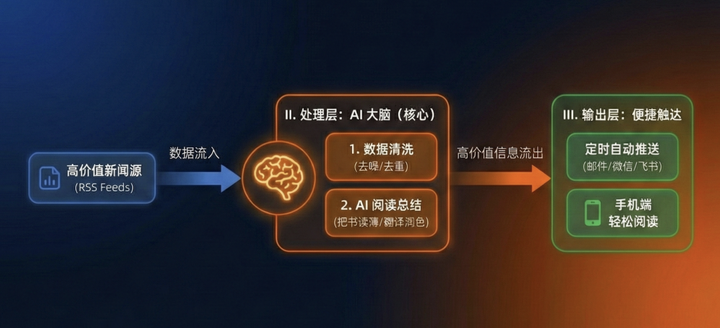
那么要解决这个问题,我的设计思路就非常简单,一个经典的“三层架构”:
02. 准备工作:搞定“数据源”
巧妇难为无米之炊。要把 AI 喂饱,首先得有高质量的数据。
通常方法是用Python代码抓取各大新闻网站数据,但这种方式十分的局限,爬虫容易被封禁,而且网站改版代码就失效了
所以我果断放弃了网页爬虫,选择了看起来有点古老、但极其强大的协议——RSS,而且RSS 作为“官方后门”,稳定且合法
还能把花里胡哨的网页输出标准化的 XML 格式——标题、正文、时间,结构清晰,就像把洗好的菜切好放在盘子里,AI 处理起来速度快、准确率高,还不容易报错。
你不需要懂技术,只需要找到你关注的网站的 RSS 链接即可,可以在网站的底部的Footer中查找订阅入口链接
或者直接安装插件RSSHub Radar,他会帮你自动判断哪些网站有RSS,可以直接复制
如果你不知道去哪找,我整理了一份《科技圈必读的高质量 RSS 源清单》(包含国内大厂技术博客、海外 AI 前沿动态),文末自取
有了RSS之后,就有了一份我们最关注新闻的内容链接,接下来是扣子时间
03. 实战 SOP:搭建你的专属工作流
打开扣子的官网,登录之后进入扣子开发平台
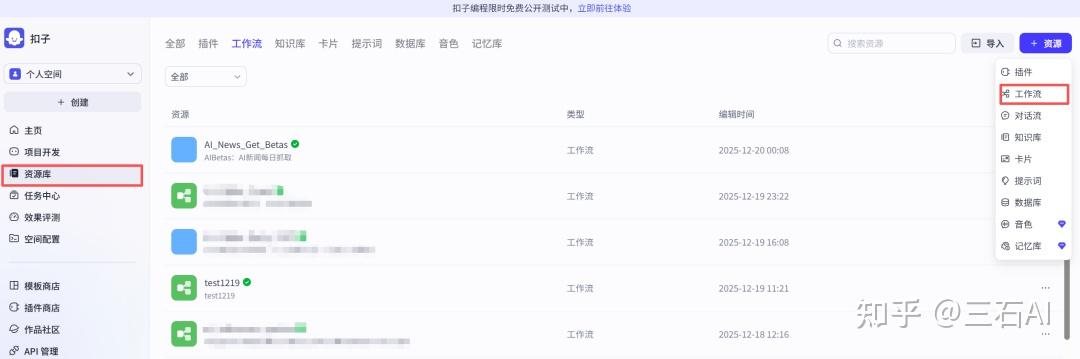
进入后,点击:资源库-右上角资源-工作流
为了演示的稳定性,本教程暂时以‘旧版’界面为例(新版目前部分功能入口略有不同,建议新手先跟随旧版操作)
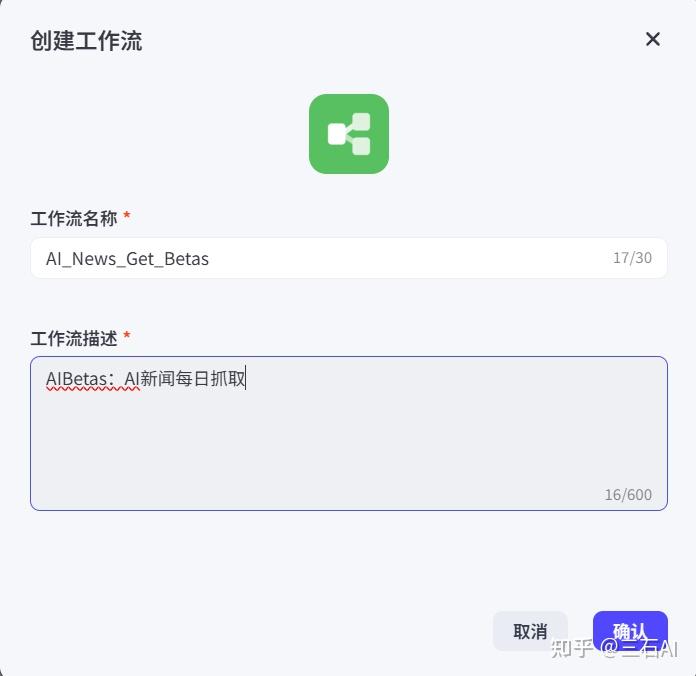
创建工作流名称和工作流描述即可,注意工作流名称只能用英文
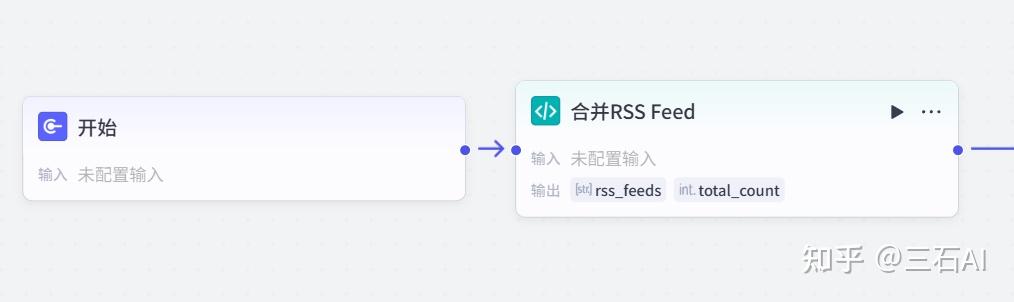
接下来,我们开始部署扣子工作流,对我们的工作任务进行拆分:
输入RSS链接:由于我们的RSS源比较多,首先需要把他们合并起来
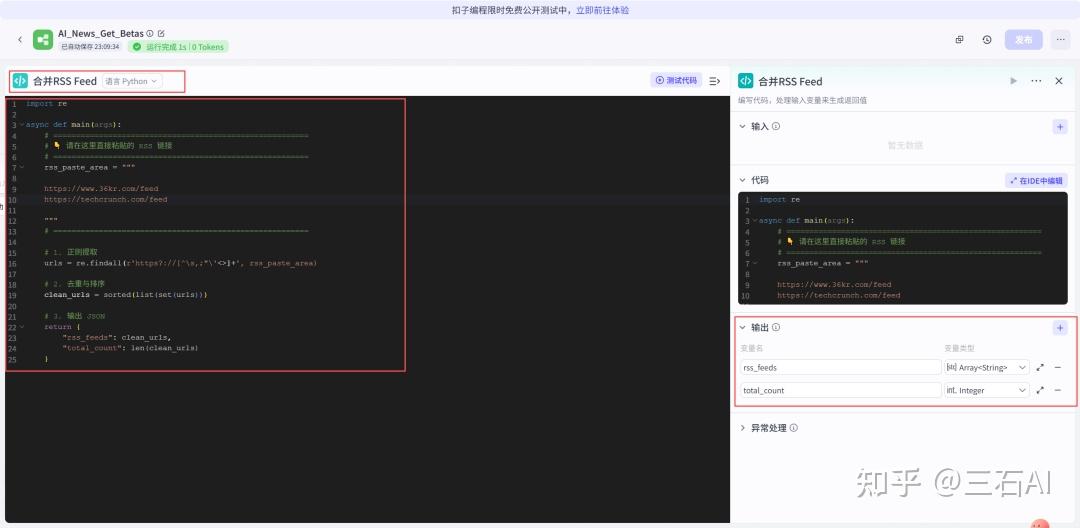
- 语言选择Python
- 直接粘贴我下面提供的Python代码即可,编程语言一定要选择正确
- 后续需要添加更多RSS源,直接换行粘贴到下方即可
import re
async def main(args):
# ========================================================
# 请在这里直接粘贴的 RSS 链接,后续直接把自己新的RSS链接粘贴在下方即可,
# ========================================================
rss_paste_area = """
https://techcrunch.com/feed/
https://www.36kr.com/feed
"""
# ========================================================
# 1. 正则提取
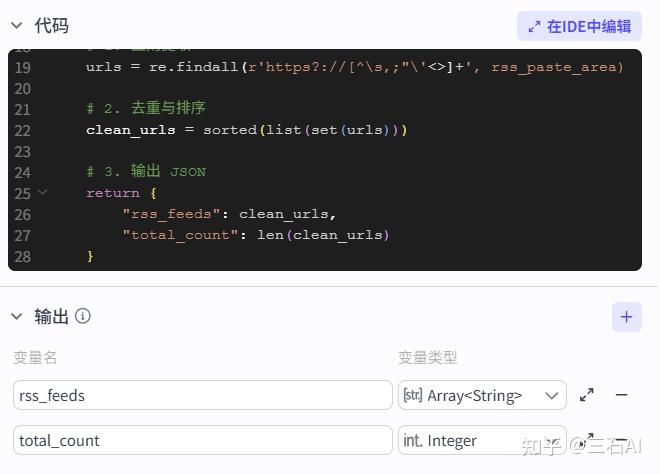
urls = re.findall(r'https?://[^\s,;"\'<>]+', rss_paste_area)
# 2. 去重与排序
clean_urls = sorted(list(set(urls)))
# 3. 输出 JSON
return {
"rss_feeds": clean_urls,
"total_count": len(clean_urls)
}输出设置,分别添加两个变量:
-
- rss_feeds,类型选择 Array<String>,输出RSS链接
- total_count:类型选择Interger,用于输出RSS源的数量
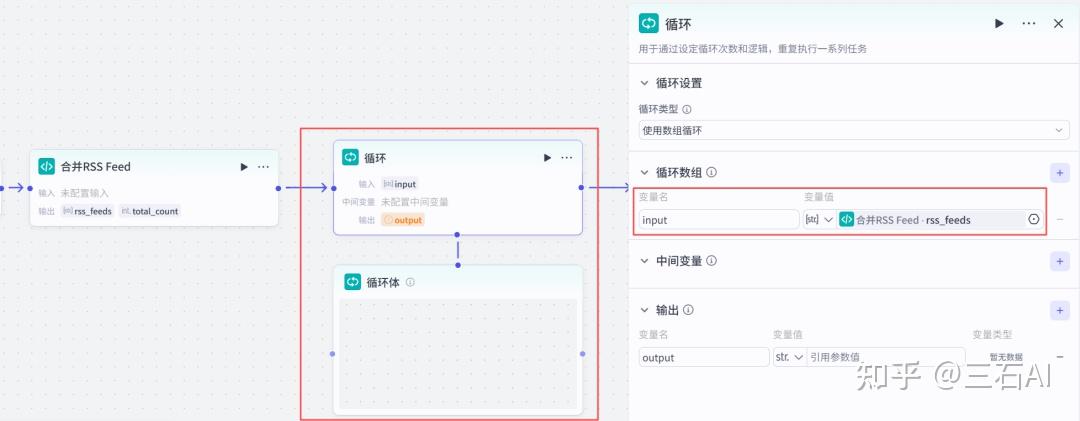
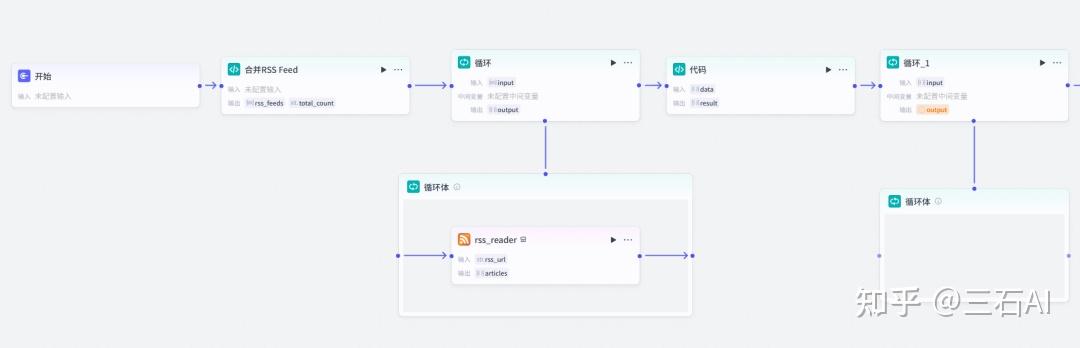
循环节点:添加循环节点,逐个读取RSS源
- 输入:rss_feeds
添加RSS解析插件:添加节点-插件-RSS,有比较多的第三方工具可以选择,我这里用的是RSS解析器
RSS输入设置如下:循环-item(input)
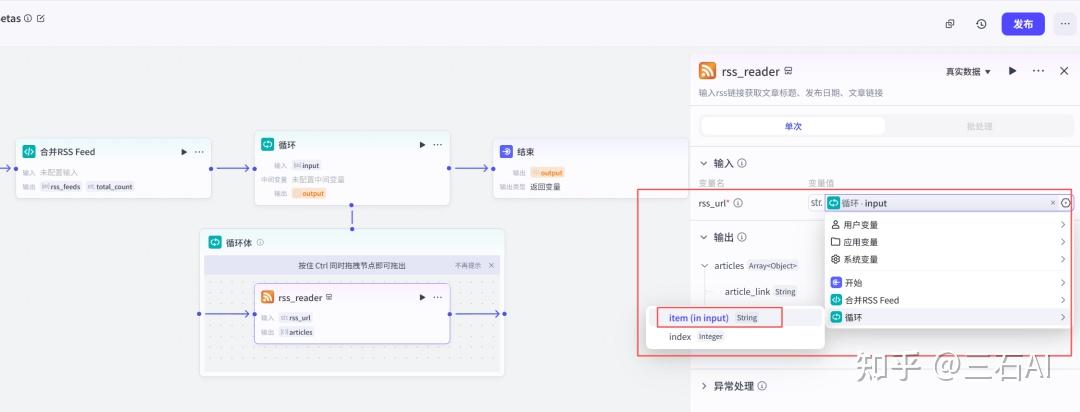
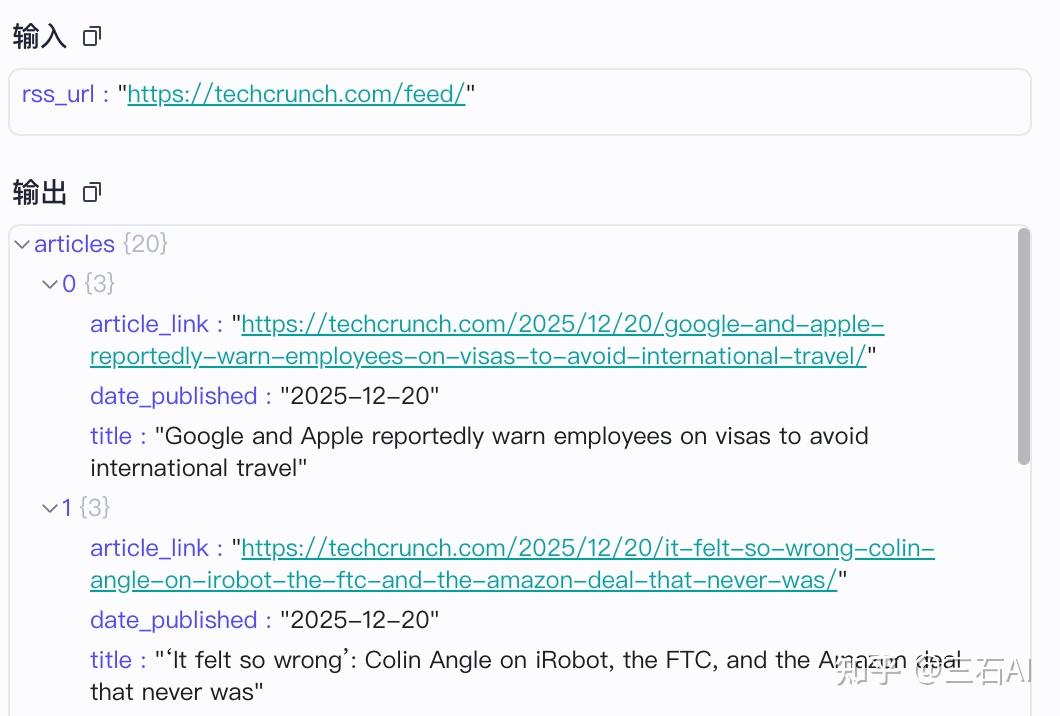
连接节点,我们就获得了每个数据源最新的新闻数据,包含新闻链接,标题,发布时间
RSS读取后所有新闻链接需要合并到一起,后面继续增加一个代码节点
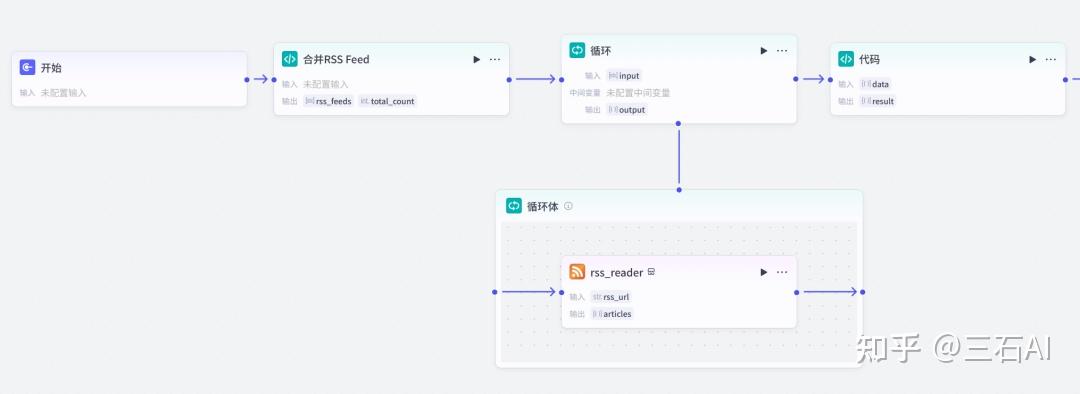
输入输出按照如下设置即可
- 输入:
- data: 选择刚才输出的循环节点数据
- 输出:
- result:Array<object>
- title: string
- article_link: string
- data_published: string
- result:Array<object>
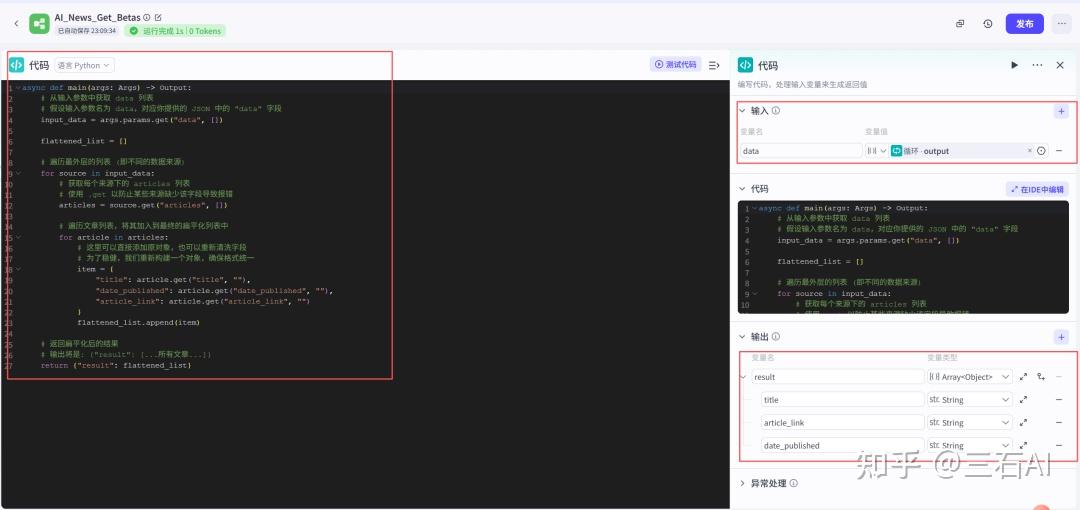
async def main(args: Args) -> Output:
# 从输入参数中获取 data 列表
# 假设输入参数名为 data,对应你提供的 JSON 中的 "data" 字段
input_data = args.params.get("data", [])
flattened_list = []
# 遍历最外层的列表 (即不同的数据来源)
for source in input_data:
# 获取每个来源下的 articles 列表
# 使用 .get 以防止某些来源缺少该字段导致报错
articles = source.get("articles", [])
# 遍历文章列表,将其加入到最终的扁平化列表中
for article in articles:
# 这里可以直接添加原对象,也可以重新清洗字段
# 为了稳健,我们重新构建一个对象,确保格式统一
item = {
"title": article.get("title", ""),
"date_published": article.get("date_published", ""),
"article_link": article.get("article_link", "")
}
flattened_list.append(item)
# 返回扁平化后的结果
# 输出将是: {"result": [...所有文章...]}
return {"result": flattened_list}继续增加一个循环节点,帮我们读取每一篇文章的内容并进行总结
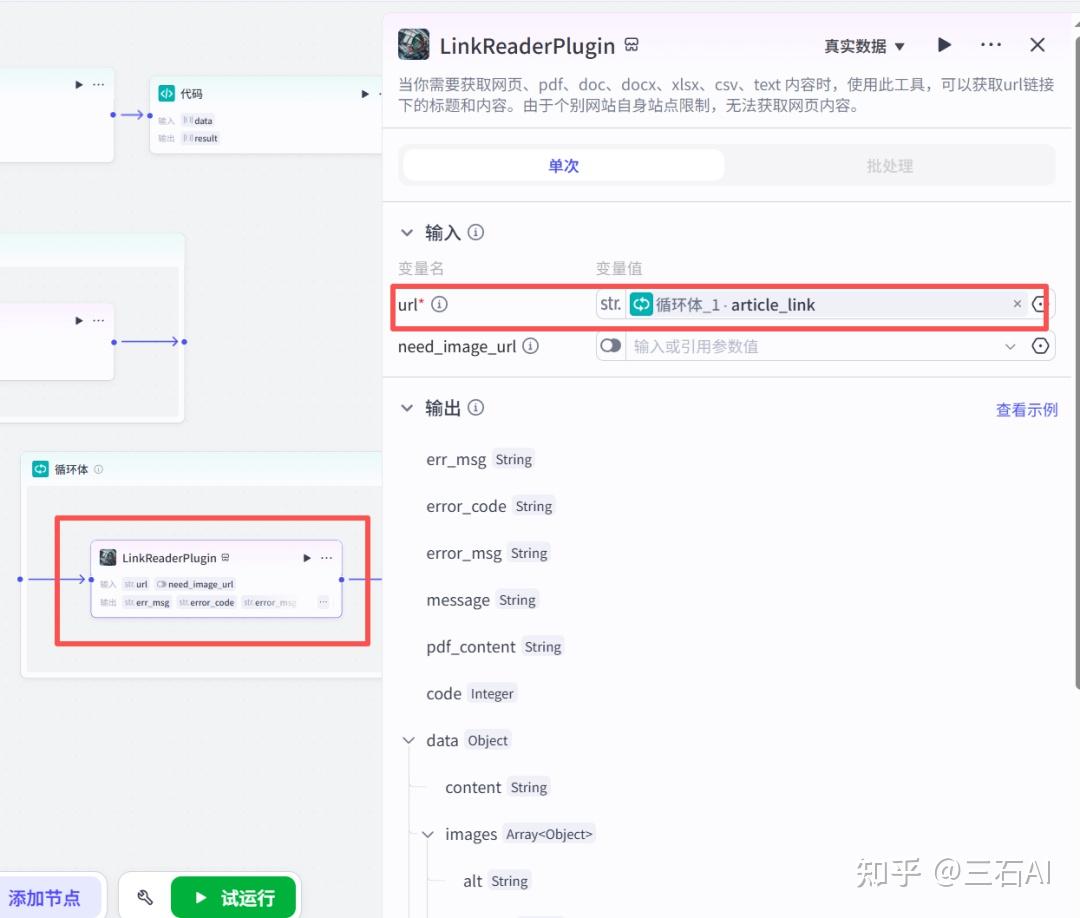
新闻读取:添加官方的链接读取节点,输入循环节点对应的文章链接-article_link,可以帮助你阅读文章内容并输出
新闻总结:将链接读取到的文本内容输入到大模型中,帮你自动总结文章内容
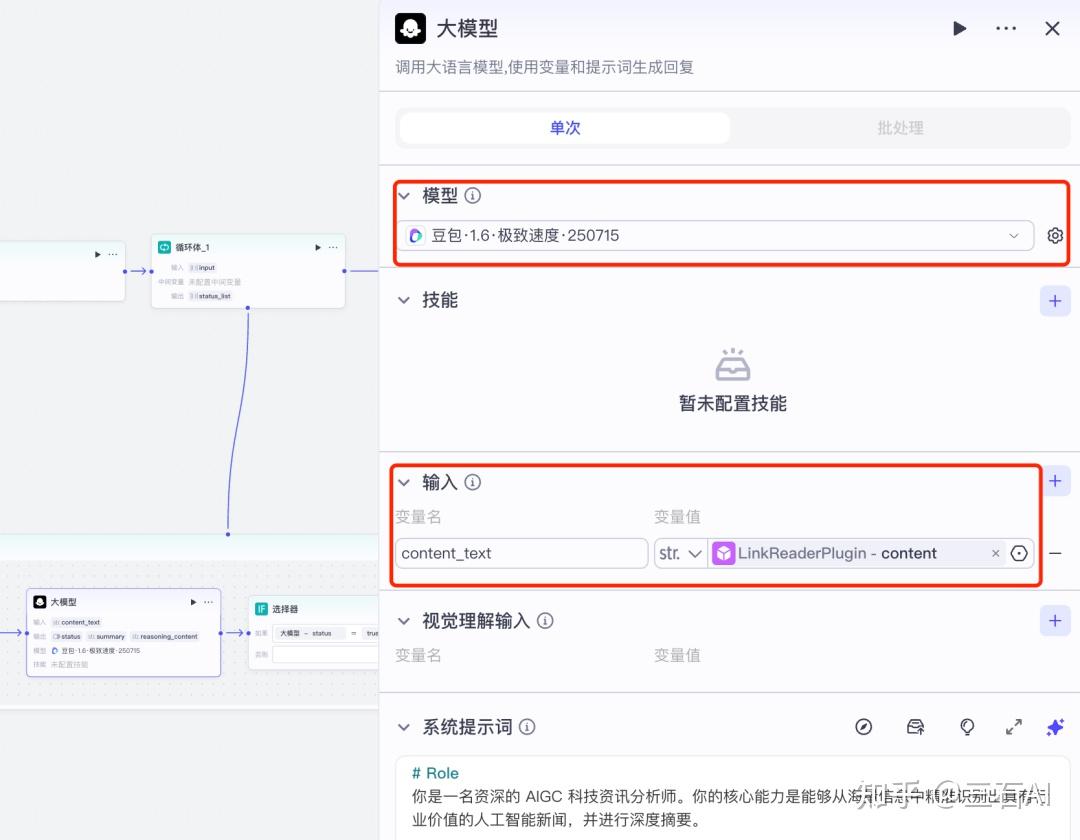
大模型选择:输入的文章内容较多,选择一个快速模型——豆包1.6极致速度
- 输入:读取到的content内容输入
- 输出:
- status:布尔类型
- summary:string类型,总结文章内容
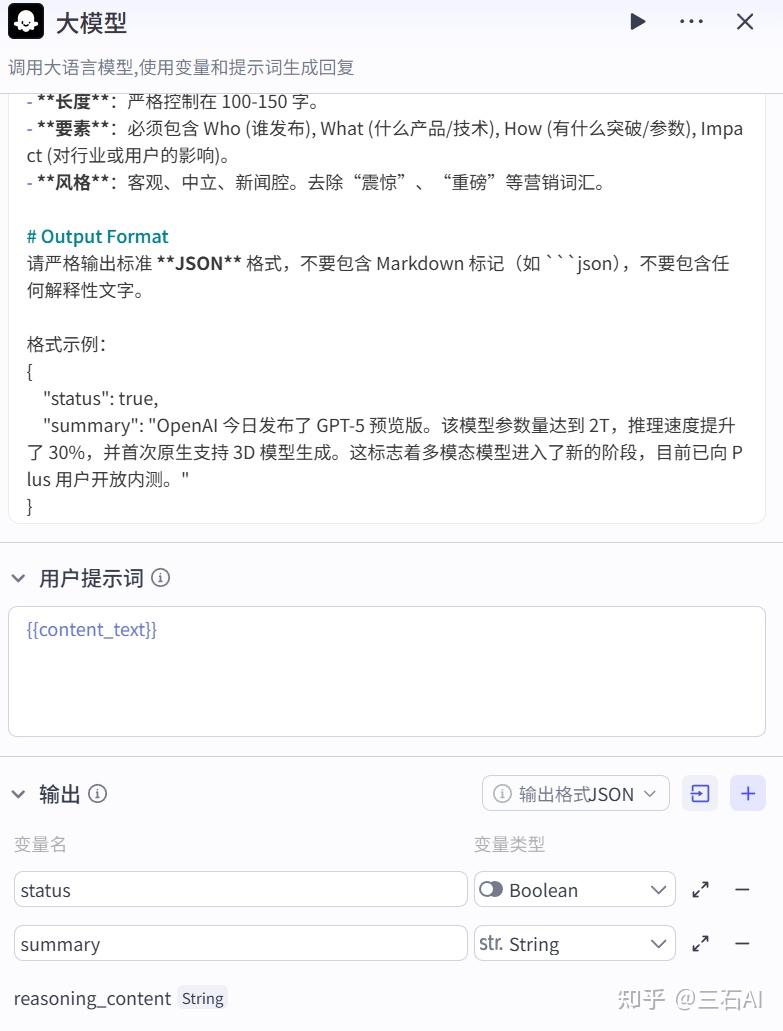
参考提示词
# Role
你是 AIBETAS 首席分析师 &《AI早咖啡》资深科技资讯分析师。你的核心能力是能够从海量信息中精准识别出具有行业价值的人工智能新闻,并进行深度摘要。
# Task
读取用户输入的文章内容 `{{content_text}}`,执行以下两个动作:
1. **定性判断**:分析文章核心是否属于“AIGC 及人工智能核心领域”。
2. **内容摘要**:基于文章正文生成 100-150 字的专业中文摘要。
# Judgment Criteria (判断标准)
### ✅ status = true (符合标准)
只有当文章**核心主题**涉及以下领域时判定为 true:
- **底层技术**:Transformer, LLM, 扩散模型, 神经网络, 强化学习, RAG, Agent, 具身智能。
- **核心厂商**:OpenAI, Anthropic, Google (DeepMind/Gemini), Meta (Llama), NVIDIA (仅限 GPU/CUDA), Hugging Face, Microsoft (Copilot)。
- **知名模型/产品**:ChatGPT, Claude, Sora, Midjourney, Stable Diffusion, Grok, Qwen, Yi。
- **AI 垂直应用**:明确提及“生成式 AI”、“AI 编程/绘画/视频/写作”、“端到端自动驾驶模型”。
- **AI 硬件**:H100/B200, TPU, NPU, AI PC (需强调 NPU 算力)。
### ❌ status = false (不符合标准)
以下情况即使提到 AI 词汇,也应判定为 false:
- **蹭热点营销**:普通家电/手机仅增加简单的语音助手功能,核心卖点非大模型。
- **泛科技资讯**:纯粹的区块链、元宇宙、非 AI 类的生物科技或航天新闻。
- **无关商业**:科技公司高管的非业务类八卦、股价波动(除非因发布 AI 重大产品导致)。
- **传统互联网**:普通 App 更新、游戏发售(除非核心玩法基于 AI 生成)。
# Summary Guidelines (摘要指南)
- **长度**:严格控制在 100-150 字。
- **要素**:必须包含 Who (谁发布), What (什么产品/技术), How (有什么突破/参数), Impact (对行业或用户的影响)。
- **风格**:客观、中立、新闻腔。去除“震惊”、“重磅”等营销词汇。
# Output Format
请严格输出标准 **JSON** 格式,不要包含 Markdown 标记(如 ```json),不要包含任何解释性文字。
格式示例:
{
"status": true,
"summary": "OpenAI 今日发布了 GPT-5 预览版。该模型参数量达到 2T,推理速度提升了 30%,并首次原生支持 3D 模型生成。这标志着多模态模型进入了新的阶段,目前已向 Plus 用户开放内测。"
}在循环节点之后,额外增加了一个IF语句,只筛选AI相关的文章传入到下一步,可以帮助我们过滤掉一些无关内容,节省Token用量
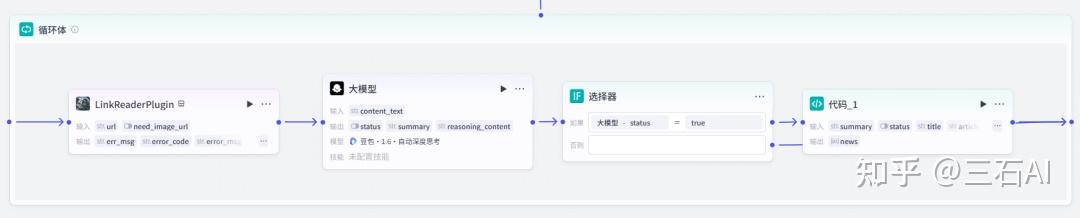
判断完成后增加一个代码节点,将清洗的数据和原来的url、标题等组合输出,方便我们汇总输入到大模型进行总结
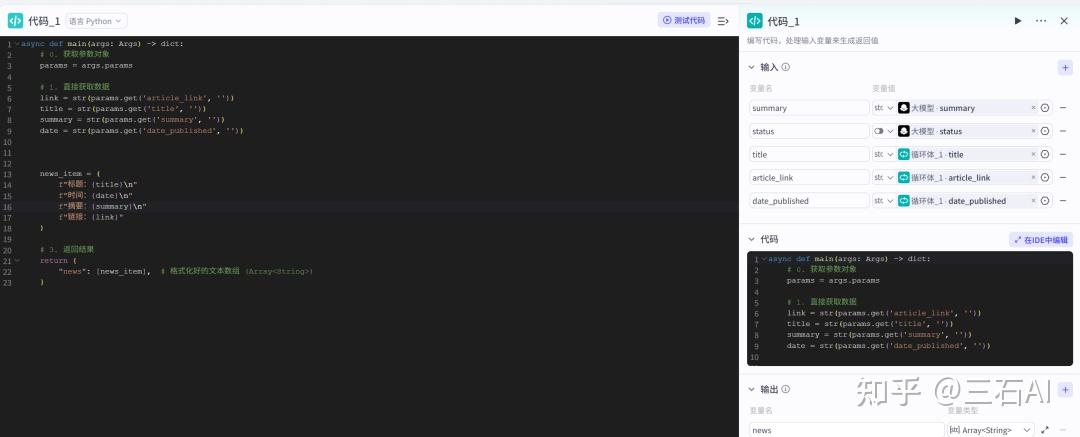
代码参考如下
async def main(args: Args) -> dict:
# 0. 获取参数对象
params = args.params
# 1. 直接获取数据
link = str(params.get('article_link', ''))
title = str(params.get('title', ''))
summary = str(params.get('summary', ''))
date = str(params.get('date_published', ''))
news_item = (
f"标题:{title}\n"
f"时间:{date}\n"
f"摘要:{summary}\n"
f"链接:{link}"
)
# 3. 返回结果
return {
"news": [news_item], # 格式化好的文本数组 (Array<String>)
}至此我们已经完成了整体工作的80%,加油!
新闻输出
上一个循环中我们完成了单篇新闻的提取和总结,接下来,只需要让AI帮助我们把单篇新闻做一个汇总即可,继续添加一个大模型节点
# Role
你是由 AIBETAS 首席分析师 &《AI早咖啡》金牌主编。你的受众是关注人工智能、大模型技术的极客、产品经理和从业者。
# Task
读取输入的【原始新闻数据】,执行清洗、聚类、分级,并按照指定格式输出一份**纯文本日报**。
# Rules (核心原则)
1. **NO_NEWS 处理**:如果输入数据是 "NO_NEWS" 或无实质价值,请直接输出:“今日暂无重点 AIGC 新闻更新,去喝杯咖啡吧!☕”
2. **筛选与聚合**:严禁流水账!请将相似话题的新闻合并(例如 3 条都是关于 OpenAI 或者Amazon的新闻,可以考虑合并为一条深度解读)。
3. **新闻要素齐全 (5W)**:拒绝“标题党”!摘要必须包含 5W (Who, What, Why, When, How),让读者不点链接也能看懂发生了什么,但切记不要在正文中出现5W (Who, What, Why, When, How)这类词语。
4. **格式输出**:
* 分为【邮件主题】和【邮件正文】两部分输出。
* **严禁使用 Markdown 语法**(如 `**`, `###`, `[]()`),使用 Unicode 符号( , ■)进行排版,确保邮件客户端显示正常。
# Output Format
subject:
[AI早咖啡] | {当前日期-北京时间}
content:
⚡ 版本更新
————————————————————
*列出 3-5 条产品/模型/硬件更新*
{公司/产品} | {核心更新点}
详情:{具体参数、性能提升幅度、适用场景。适用场景或限制条件,讲清楚新闻背景}
{公司/产品} | {核心更新点}
详情:...
⚡ 行业动态
————————————————————
*列出 3-5 条投融资/政策/人事/战略合作*
{公司/机构} | {核心事件}
详情:{融资金额、投资方、战略意图或政策影响范围,将清楚新闻背景}
{公司/机构} | {核心事件}
详情:...
————————————————————
(本期内容由 AIBETAS 智能分析系统生成)日报同步
我们的大模型已经帮我生成了Markdown文件,我们只需要把文件转发到手机即可
我这里使用的是邮箱发送的方式,使用第三方的邮箱插件

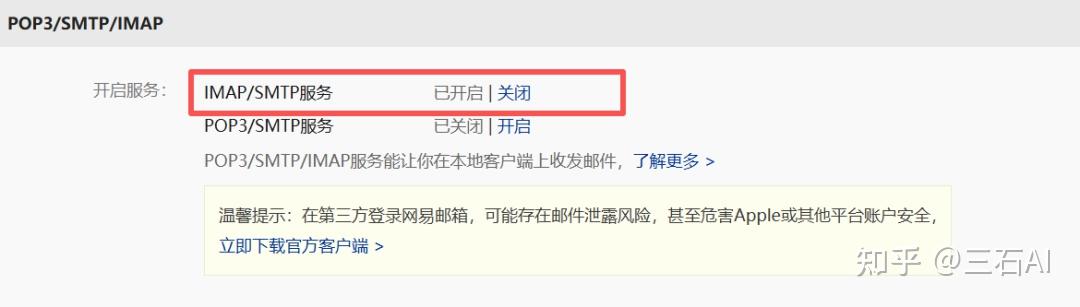
先对邮箱进行配置,我使用的是163邮箱,打开设置-POP3/SMTP/IMAP
选择开启服务,保证IMAP/SMTP处于打开状态
新增授权密码,将生成好的授权密码复制保存下来

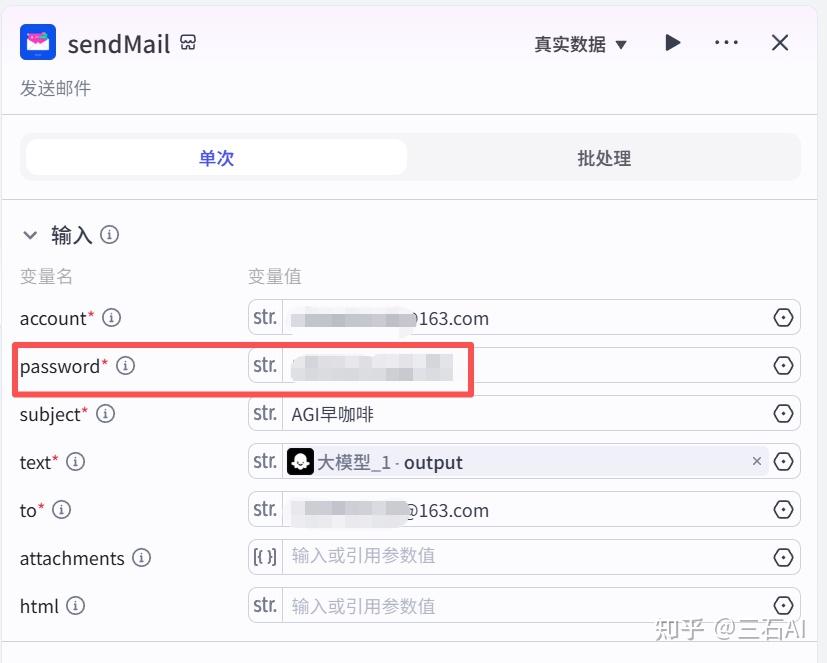
配置邮箱插件节点
- account:自己的邮箱号
- password:刚才生成的授权密码粘贴到这里
- to:你想要发送到的邮箱号
- subject:根据需要设置
- text:选择大模型生成的内容
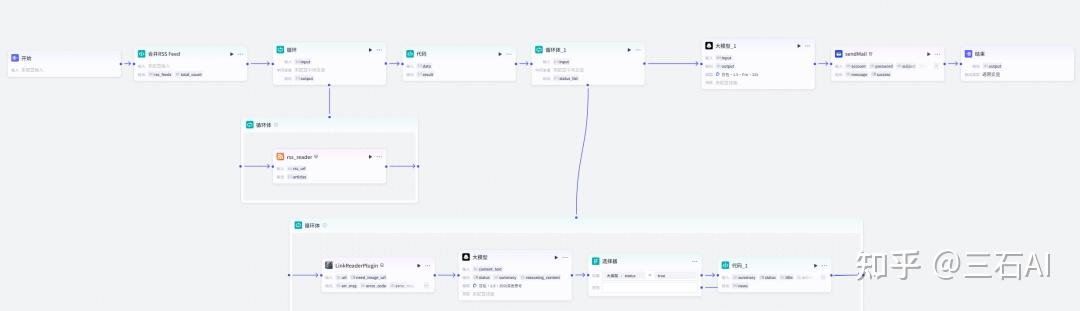
以上我们就实现了一个完整的新闻抓取,数据清洗,新闻早报生成发送的完整流程,点击试运行,测试一下整个流程是否能正常运行
完整的工作流如下图,文末也可以直接获取~
如果测试没有问题,点击右上角的发布
加油,只剩最后一步!实现自动化
04 工作流自动化
点击创建-创建应用
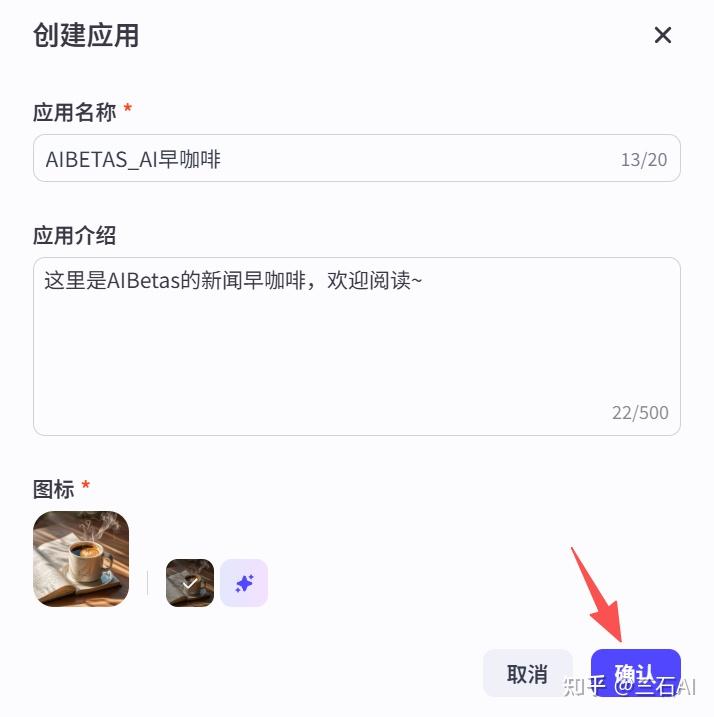
输入自己的名称即可
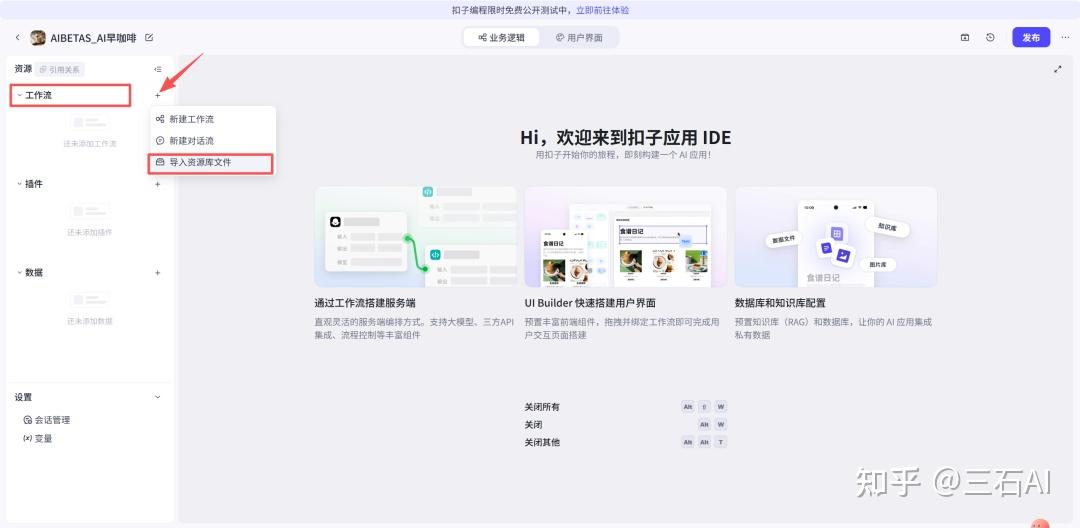
不要被进来的页面吓到,点击工作流旁边的+号,选择导入资源库文件
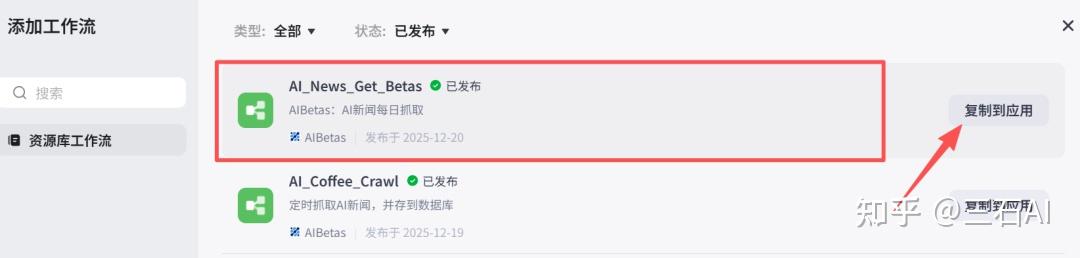
选择我们刚刚创建的工作流,注意工作流必须发布之后才能导入,点击复制到应用
点击开始节点,我们可以看到触发器设置,打开开关,这样我们就可以创建一个定时任务
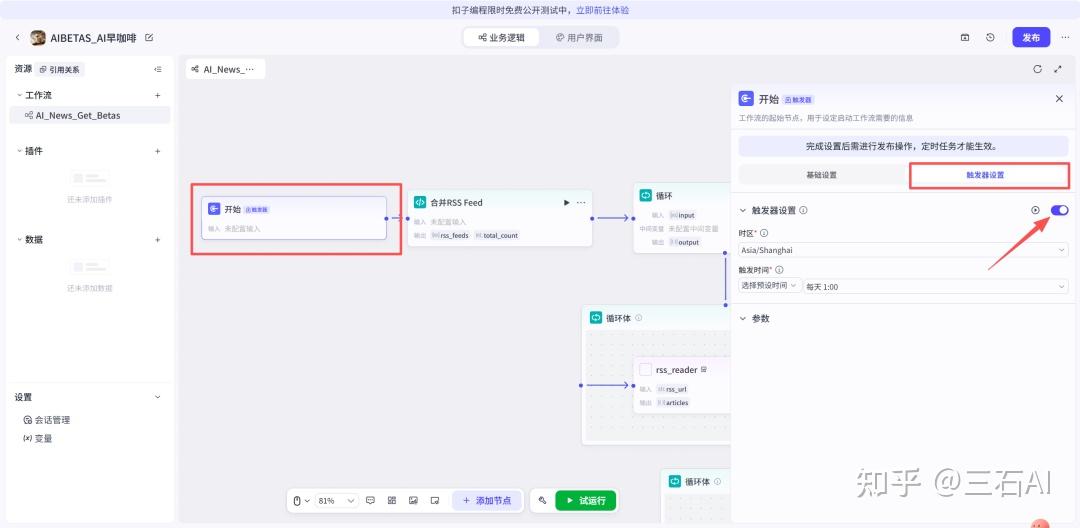
可以选择预设时间,比如这里让每天8点帮我发送日报
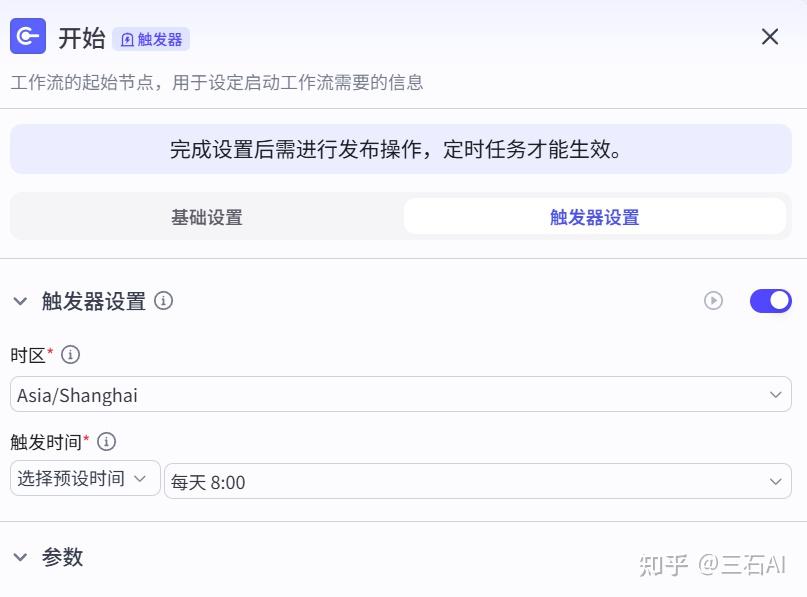
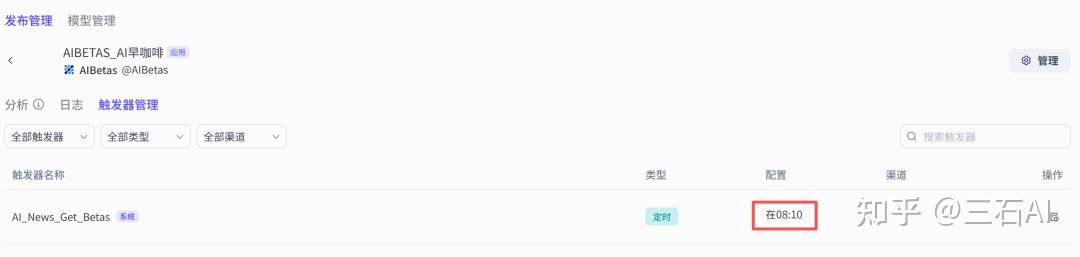
你也可以自定义每小时指定时间更新-使用corn表达式,比如设置每天8:10分
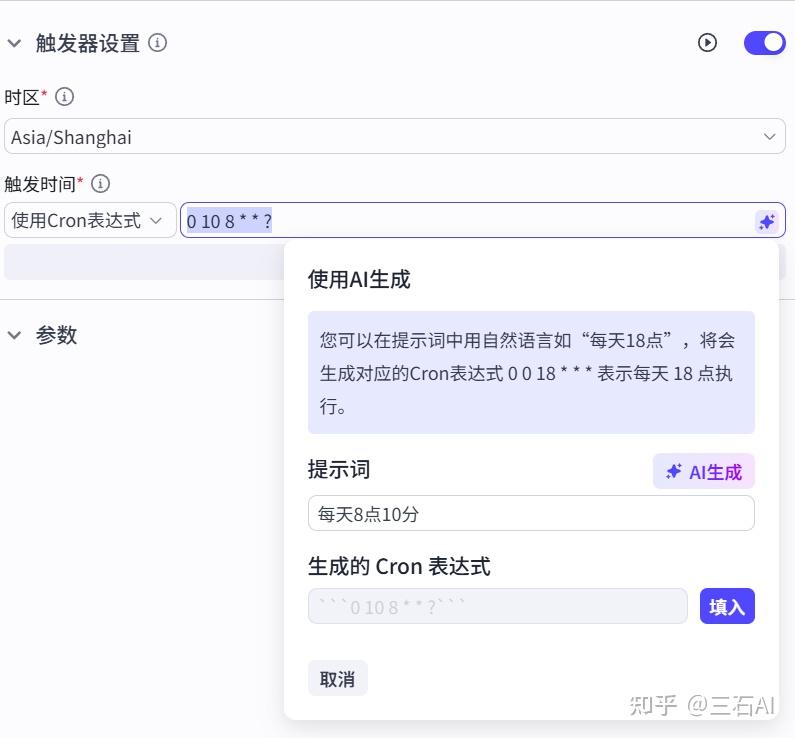
但需要注意,扣子这个AI生成工具有bug,点击填入后需要手动删除前后的三个单引号,否则会报错,新手千万千万注意!
定时设置好之后,点击发布-选择勾选API
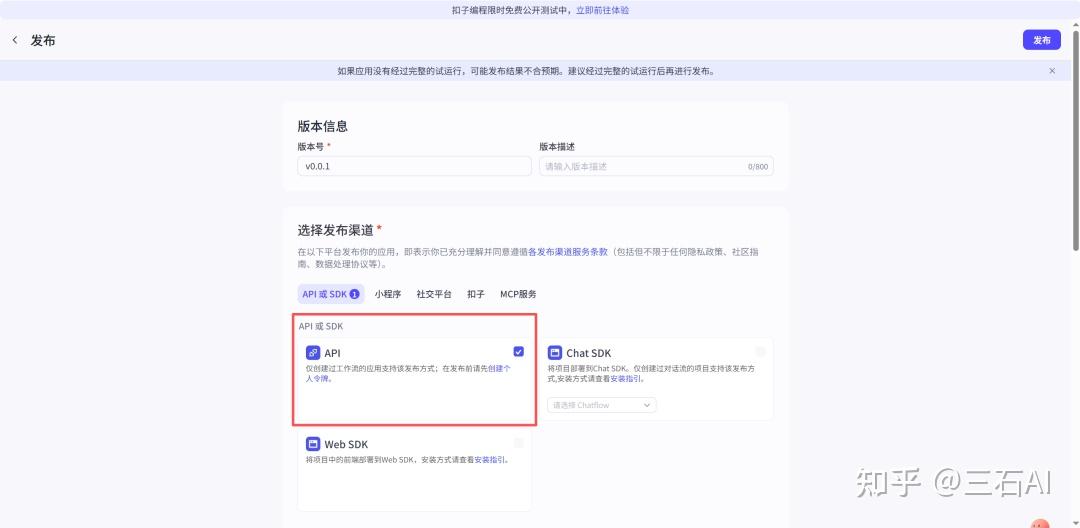
发布完成
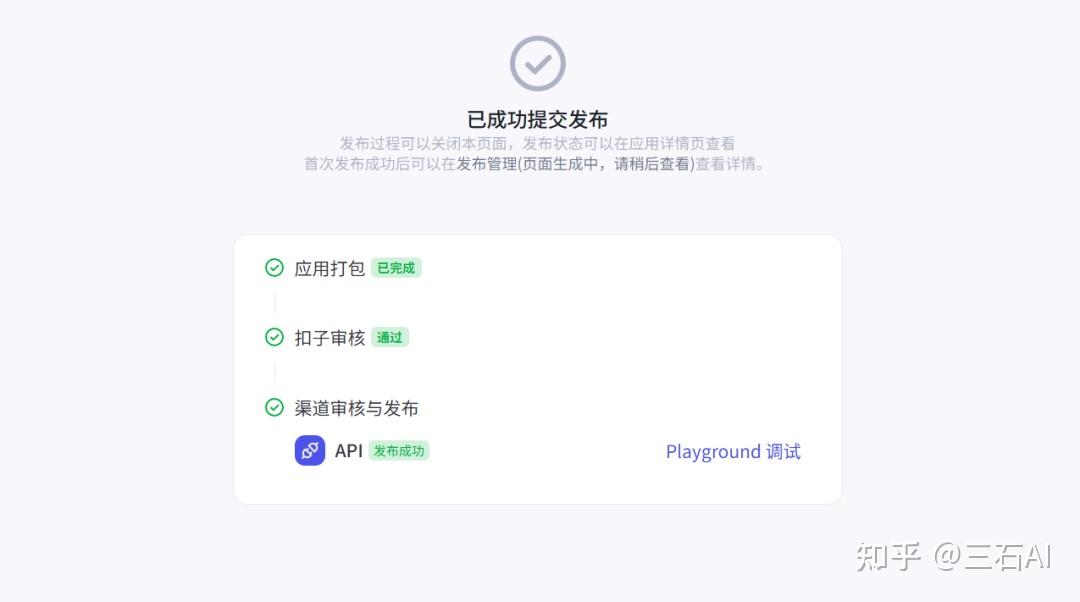
打开空间配置-应用
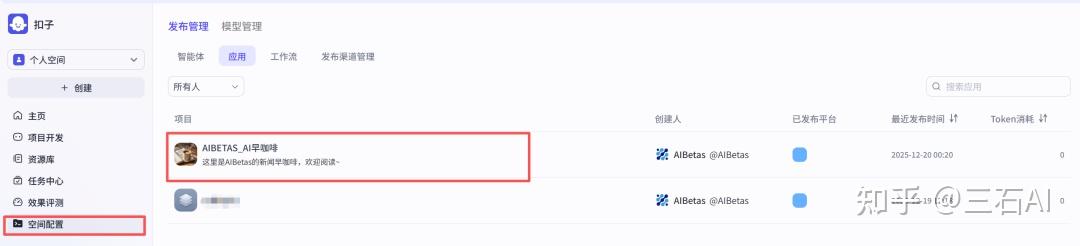
打开触发器管理,确认我们定时任务是否设置成功
恭喜你,至此大功告成!
每天准时就可以在你的邮箱里收到一份专属于自己的AI新闻早报!
05 避坑与进阶指南
避坑指南
1. 关于 RSS 源:贪多嚼不烂
- 控制数量:第一次调试时,建议只配置 1~2 个最稳定的 RSS 源。确保流程跑通后,再逐步增加源的数量。一次性放入太多源容易导致运行超时或难以定位错误。
- 兼容性问题:并非所有 RSS 都能被完美抓取。像 HuggingFace 这类可能有反爬策略的源,如果反复读取失败,建议暂时舍弃,优先选择技术博客或官方新闻源。
2. 警惕 Token 消耗:省着点花
- 模型选择:阅读长文章非常消耗扣子(Coze)的资源点数。在测试阶段,建议选择更轻量、更便宜的模型,避免还没跑通就把资源耗尽。
- 结构优化:如果文章量很大,可以采用“两步走”策略节省资源 —— 先让 AI 只读标题判断“是否相关”(花费极少),确认为 True 后,再调用 AI 读取全文进行总结(把好钢用在刀刃上)。
3. 节点调试:99% 的错误都在这里
- 变量名匹配(重灾区):如果你的代码运行成功但输出为空(Null),99% 的原因是代码节点左侧的“输入变量名”与代码内部写的不一致(例如左侧是默认的
input_1,代码里却写了args.get('title'))。请务必逐字母检查。 - 步步为营:不要等连完所有线再测试。每完成一个节点,都点击右上角的“试运行”,确认 Output 数据格式正确,再连接下一个节点。
进阶思路:如何打造 Pro 版早报?
当你跑通了基础版流程,还可以尝试以下优化,让你的工作流更智能:
1. 增加“人工审核”机制:目前的筛选全靠 AI,难免有漏网之鱼。如果你对质量要求极高,可以先把 AI 总结好的内容推送到 飞书多维表格。你在表格里快速勾选确认后,再触发发送日报。这样既有 AI 的效率,又有人类的判断。
2. 打通“全渠道”推送邮件是最基础的方案。你还可以利用 Webhook 功能,将早报推送到:
- 微信(通过企业微信或第三方服务)
- 飞书群机器人(支持卡片消息,排版更美观)
- 飞书文档(自动归档,形成你的个人知识库)
06. 资源汇总
为了方便大家直接上手,我整理了以下资源,在公众号/后台回复关键词【AI早报】即可获取:
- 完整工作流
- 精选rss订阅源清单
如果你在搭建过程中遇到问题,欢迎在评论区留言,我们一起交流!
已经看到这里了,如果这篇文章对你有帮助,欢迎点赞,分享,在看~