交互式标注工具:Fastlabel
作者:周舒畅
链接:https://zhuanlan.zhihu.com/p/1990421029080810568
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


链接:https://zhuanlan.zhihu.com/p/1990421029080810568
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Fastlabel 是一个生产级工具。起源于
在旷视的一个项目。核心是利用人的并行视觉能力,即”审查比标注快的多的多“,实现图像二分类的超快标注。
两个核心理念是:
- 边标边训自动打标模型。
- 所有图片都需要经人类标注或者审阅。
今天我们靠 gemini 完成概念复现。
。。。
嗐,没什么好写的,就是迭代两次 spec,塞给 gemini。
放几页截图吧。
直接命令行启动,然后 localhost:8008 看 demo。
python3 app.py一开始,可以用一句话作为初始自动标注,底下是一个 600MB 的 CLIP。
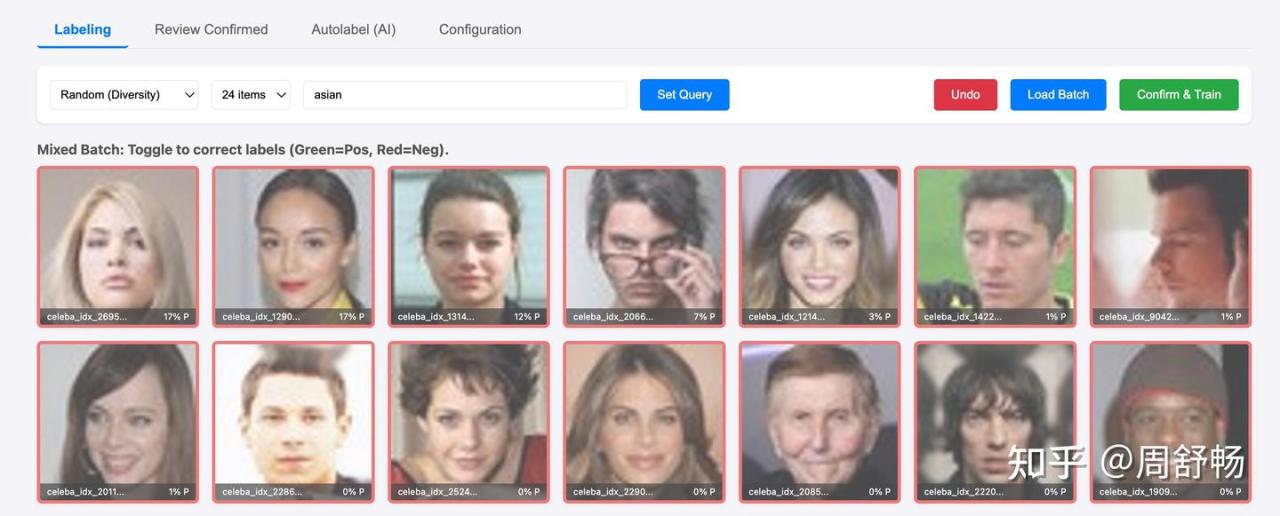
我们选用“asian” 来在 CelebA 里找东亚人。
点 “Set Query” 后,再点 Load Batch。
第一轮结果中返回的都红色框,确实里面没有 Asian。直接 Confirm& Train。
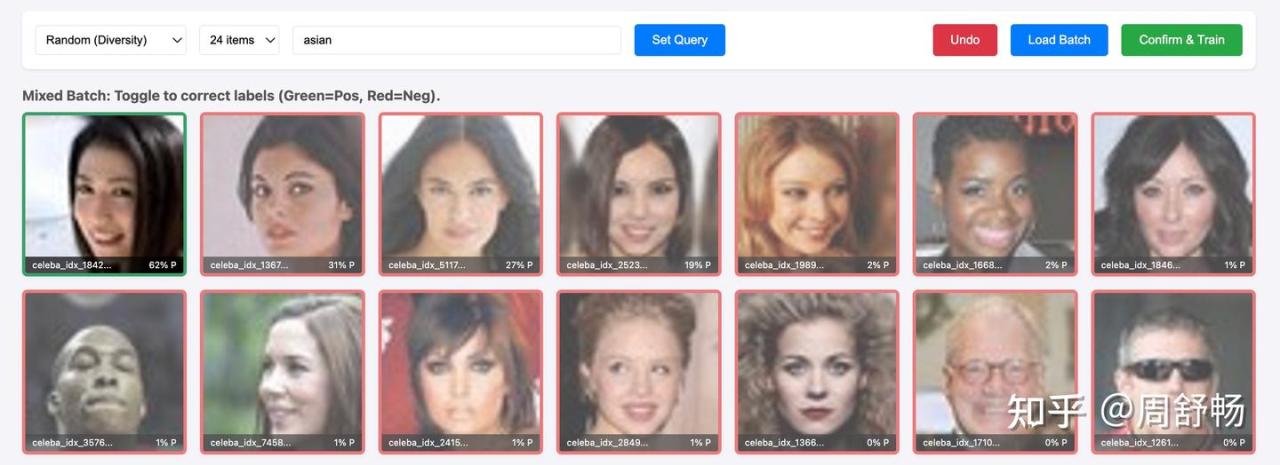
这一轮绿色这个算对。Hmm,第一行最后一个也算吧。点一下把她 toggle 成绿色,然后 Confirm&Train。
出现男生了,不错。不会训成 “asian woman”分类了。
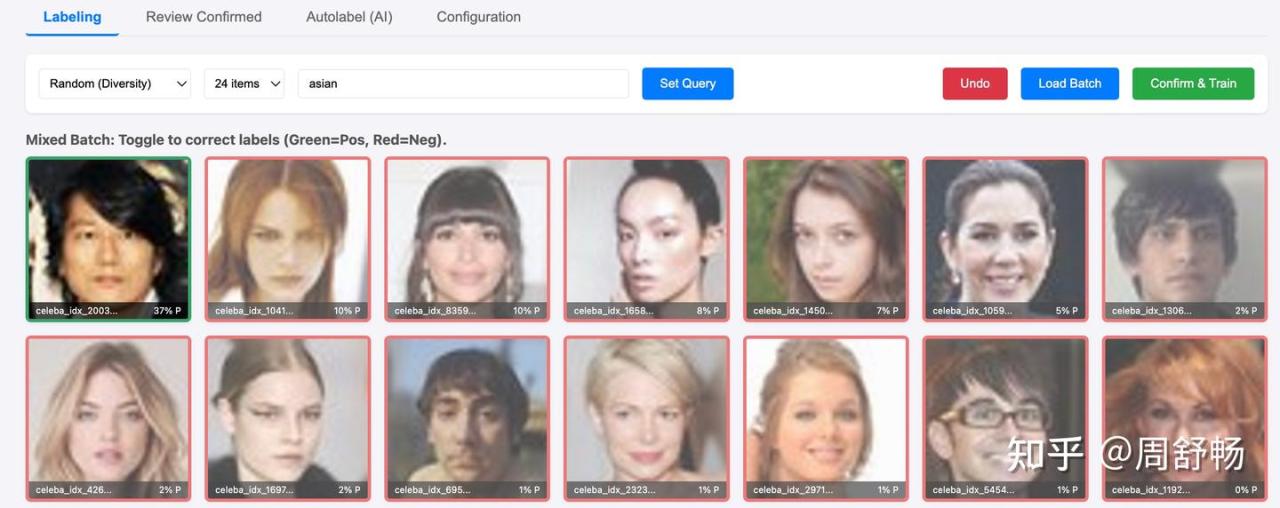
感觉挺准的了。
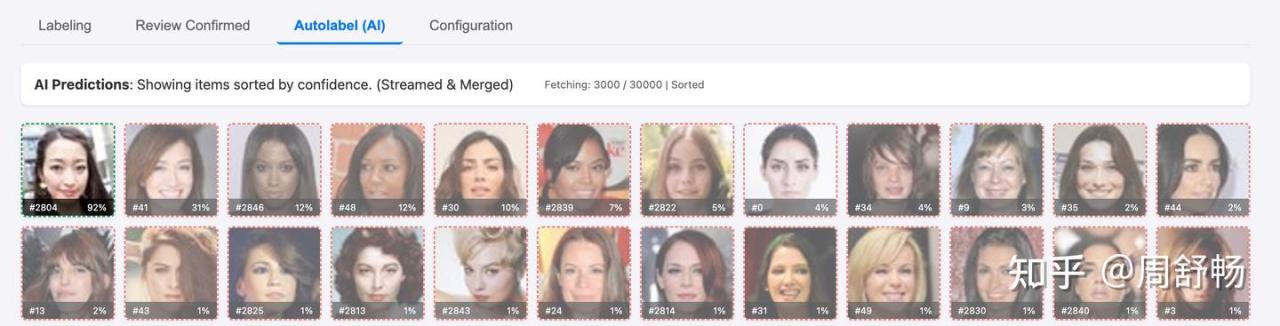
接下来因为自动标注大都是对的,可以把 “24 Items” 那个改大些。
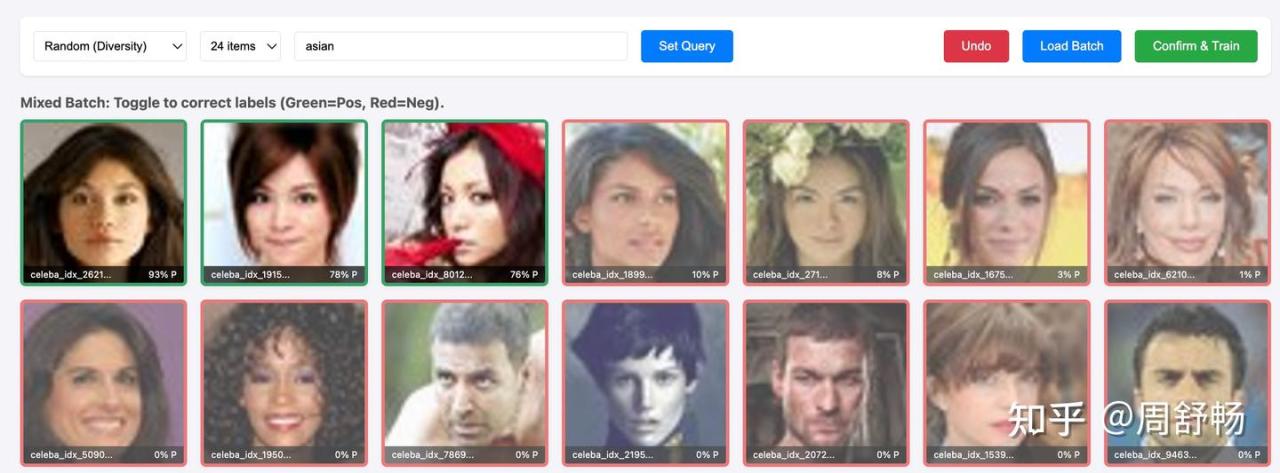
点到 Autolable 页,Hmm,模型怕是以为黑发就是 asian。得再训训。
以上是在 Macbook 上跑的,用了 M1 Apple Silicon 的机器学习能力。所以速度相当不错。
最后在 Review Confirmed 这个 tab,可以导出标注结果。
还有一点,除了是一个很好的标注工具外,也是一个很好的数据集理解工具。标的时候经常会发出惊叹:“还有这样的数据!”。