n8n实战023,公众号文章带图片永久存储,DeepSeek+Puppeteer零成本方案

兄弟们,元旦快乐啊。
这两天认识了很多很多接触研究n8n的兄弟,很多兄弟都对公众号的文章有点执念,一定想要把公众号的文章清爽的保存到本地,因为咱们都知道公众号文章收藏了也不保险,作者一删或者号一炸,你收藏夹里就剩个感叹号。
咱不整虚的,正好借着1月1日给大家开个好头,今天这个工作流,就是干这个的。
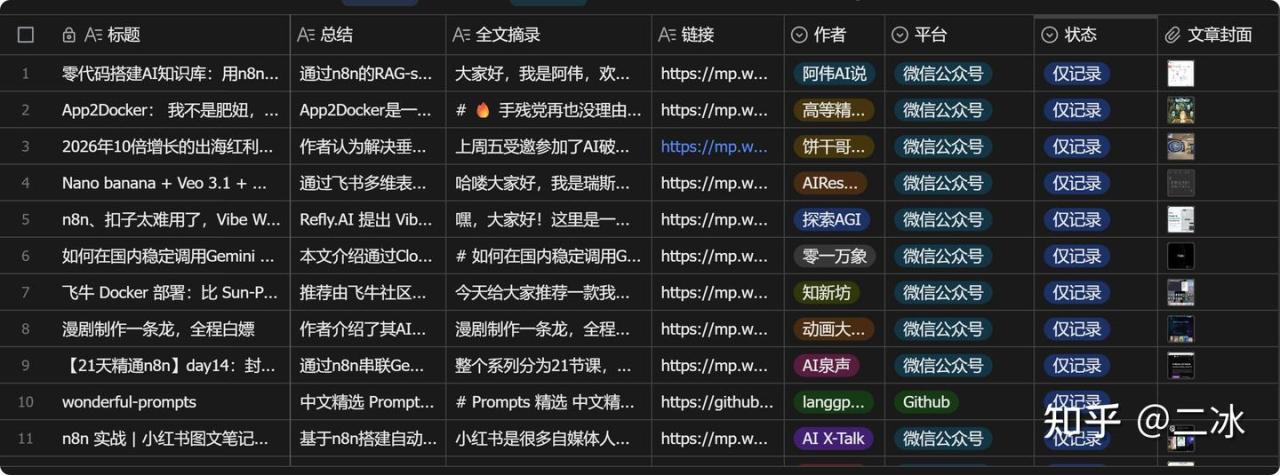
逻辑很简单:
- 1. 监听飞书表格里的链接。
- 2. 用Puppeteer无头浏览器进去把HTML扒下来。
- 3. 扔给DeepSeek(V3.2)进行清洗,去广告、去二维码,转成Markdown。
- 4. (重难点) 把文章里的图片提取出来,下载,上传到你自己的图床/NAS,替换掉原文链接。
- 5. 最后把清洗好的完美文章写回飞书。
废话少说,直接开整。
一、你需要准备什么?
这期稍微有点硬核,涉及到了图片转存和浏览器模拟,工具得备齐:
- • 1. 硅基流动 API Key
(二冰用的大模型都是硅基流动的,大家可以点一下我的邀请链接,咱们一人获得2000万token,绝对够你用好久好久好久 https://cloud.siliconflow.cn/i/ttf52sDl ) - • 2. 飞书自建应用(需开启多维表格权限)
- • 3. 企业微信群机器人 Webhook(可选,用来通知进度)
- • 4. n8n 社区节点:
- •
n8n-nodes-feishu-lite(老朋友了) - •
n8n-nodes-puppeteer(用于模拟浏览器抓取)
- •
- • 5. 一个Browserless服务(Docker部署的无头浏览器,配合Puppeteer节点用)之前将网页截图的时候我们部署过
- • 6. 一个自建的文件上传接口(之前我们也部署过,如果你不需要转存图片,可以把工作流里图片处理那一段删掉)
以上准备工作的详细图文教程(如怎么申请Key、怎么建应用),二冰都整理在飞书文档里了,还没搞定的兄弟先去看文档,搞定再回来接着整:
https://ai.feishu.cn/docx/FjX0dIyw4onA4ZxZUFzcczXrnyd?from=from_copylink
二、这个工作流是怎么跑的?
这个工作流一共 17个节点,逻辑非常严密,分三步走:
- 1. 抓取与清洗:监听飞书 -> 模拟浏览器打开网页 -> AI清洗去广告 -> 提取Markdown。
- 2. 图片大挪移(核心):提取图片链接 -> 逐个下载 -> 休息一下(防封) -> 上传到自己服务器 -> 替换原文链接。
- 3. 存档与回写:把处理好的纯净版文章(含新图片链接)写回飞书。
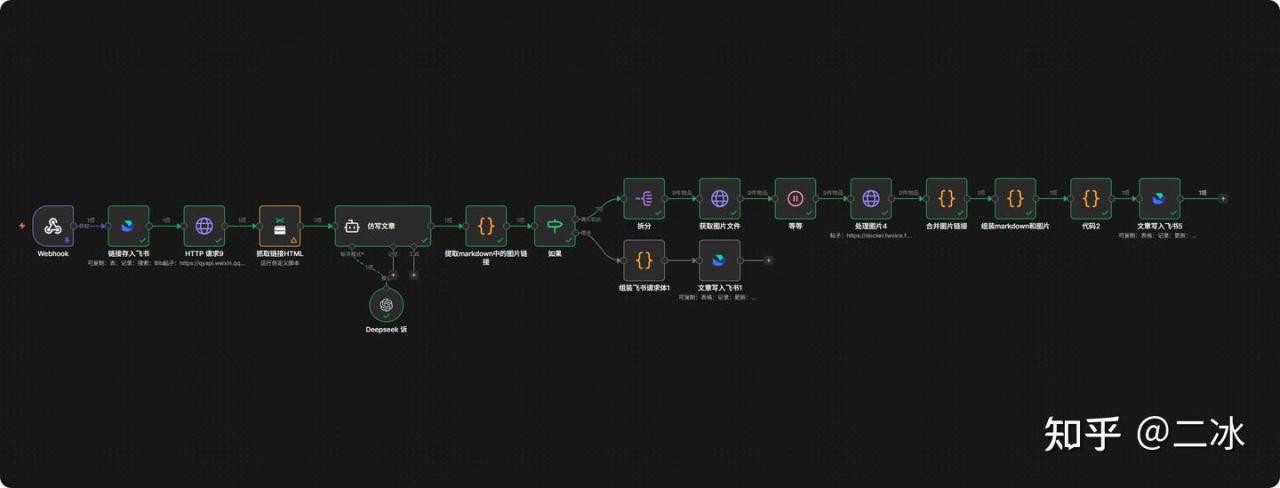
三、节点详细配置(全流程拆解)
咱们按工作流的运行顺序,一个一个来。
1. Webhook 节点(可选触发)
配置webhook触发器,保证飞书多维表格按钮点击即可触发
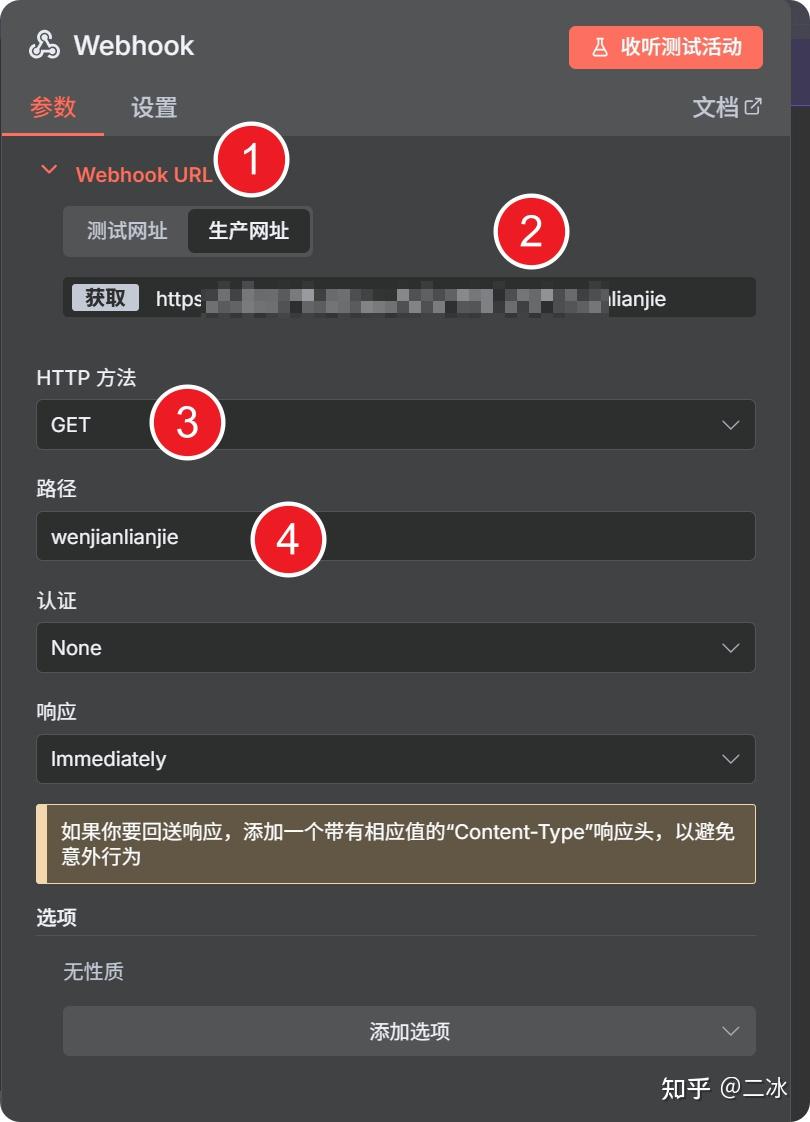
一定要复制生产环境的url,请求方式选择get就行。如果你主要靠手动点运行,这个节点可以忽略。
2. 读取链接 (Feishu Node)
这一步是从飞书表格里把你要抓的公众号链接取出来。
这里使用feishu-lite节点的Search功能。
View ID:建议填一个视图ID,比如你可以建一个视图叫“待处理”。

不知道怎么填参数的,按照我的多维表格链接的图示填写就行

3. HTTP Request (企业微信通知)
这一步是告诉群里一声:“二冰开始干活了,正在抓取XX文章”。
添加节点,按照下图配置企业微信通知节点
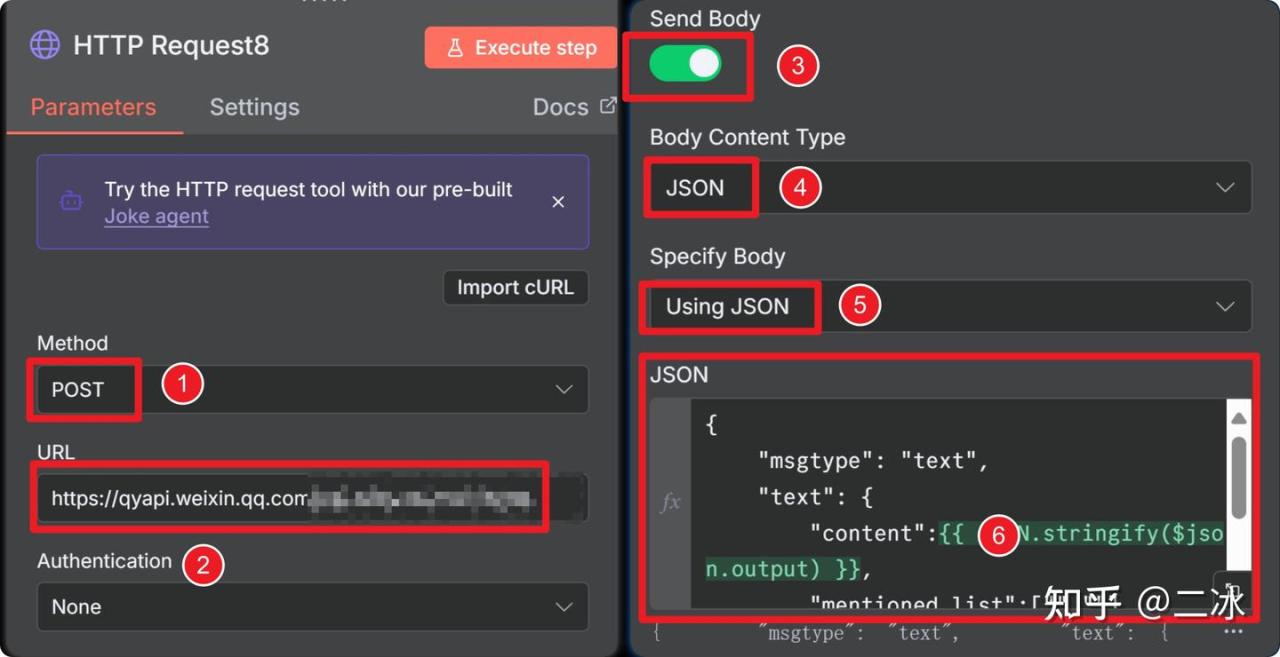
企业微信消息请求体代码在文末n8n实战文档中,有需要的兄弟自取
4. 抓取链接html (Puppeteer)
这是核心节点之一。因为微信公众号有反爬策略,直接用HTTP请求拿不到内容,必须用 Puppeteer 模拟真人浏览器去访问。
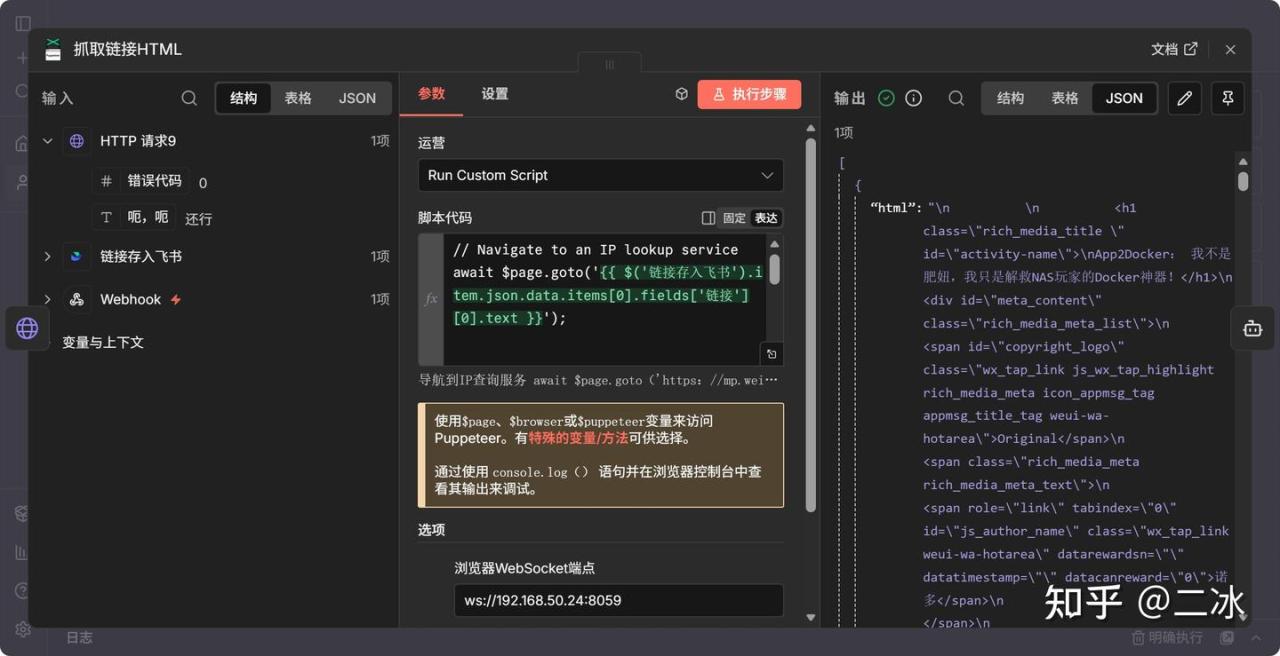
- • Operation: 选择
Run Custom Script。 - • Script Code: 填入提取页面 HTML 的 JS 代码(见文末文档)。
- • Browser WebSocket Endpoint: 填你 Docker 部署的 Browserless 地址,比如
ws://192.168.1.5:3000。
5. 清洗文章 (AI Agent)
拿到 HTML 后全是乱码和广告,这时候交给 AI 清洗。
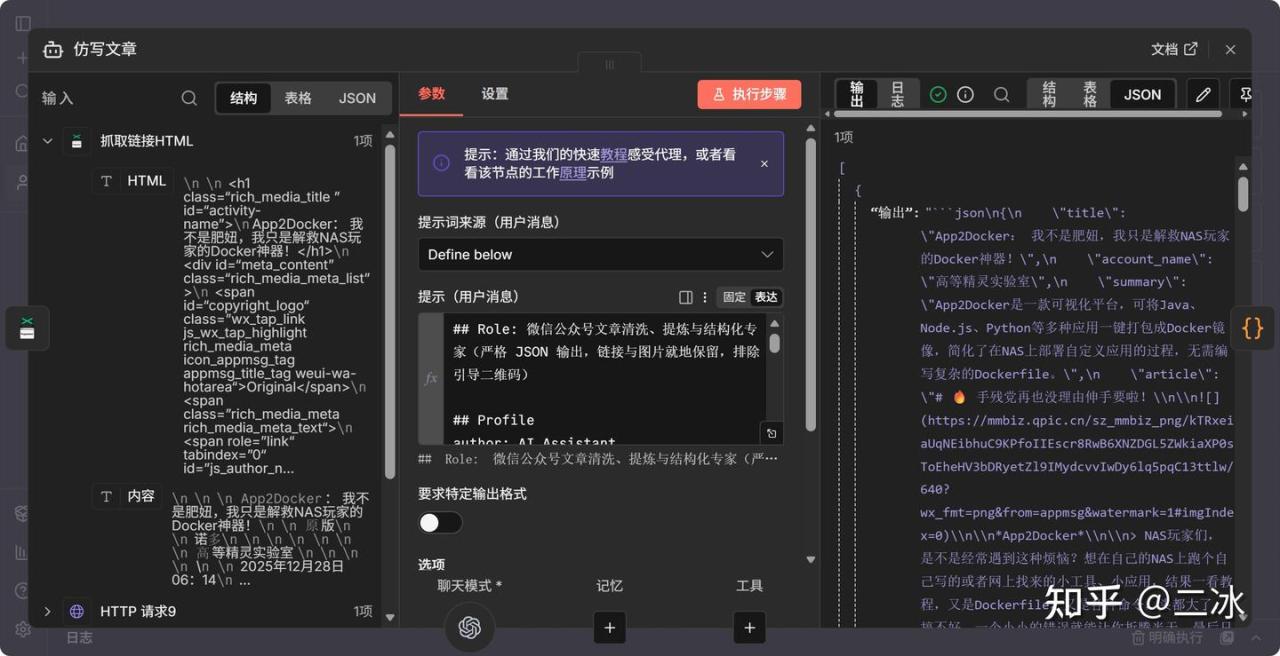
提示词(Prompt)我调教了很久,能把关注二维码、广告卡片全去掉,只留正文,具体代码去文末文档复制。
6. 提取Markdown中的图片链接 (Code Node)
文章清洗完是 Markdown 格式,我们用一段 JS 代码,正则匹配出里面所有的 ![]() 图片链接,准备下一步下载。
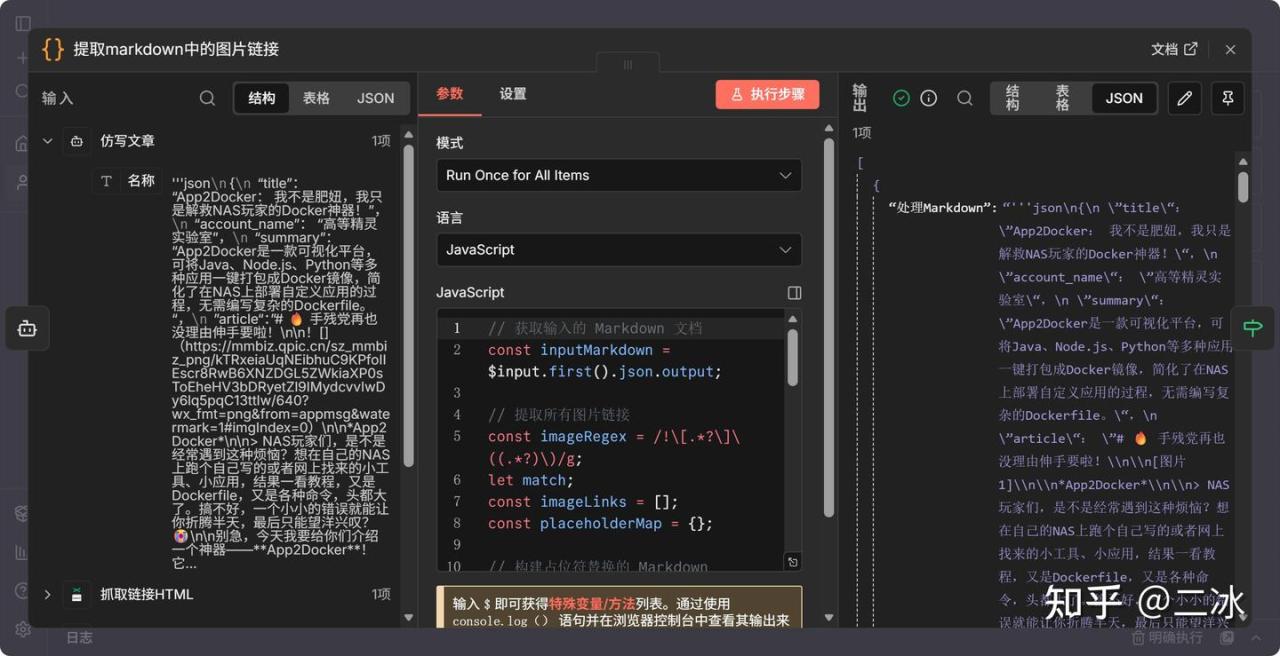
7. If (判断是否有图片)
这里做个逻辑判断:
- • True:文章里有图片 -> 走图片转存流程。
- • False:文章纯文字 -> 直接跳到最后写入飞书。
8. 拆分 (Split Out)
如果有10张图片,AI 给的是一个数组。这个节点把“一捆”链接拆成“一个一个”的,方便后面排队处理。
9. 获取图片文件 (HTTP Request)
这里要把 Response Format 改成 File,因为我们要下载二进制文件。
10. Wait (防封限流)
注意细节! 微信图片如果你下载太快,IP 容易被封。加个 Wait 节点,每张图下载完停个 3 秒,稳得一匹。
11. 处理图片 (HTTP Request – Upload)
上传节点。
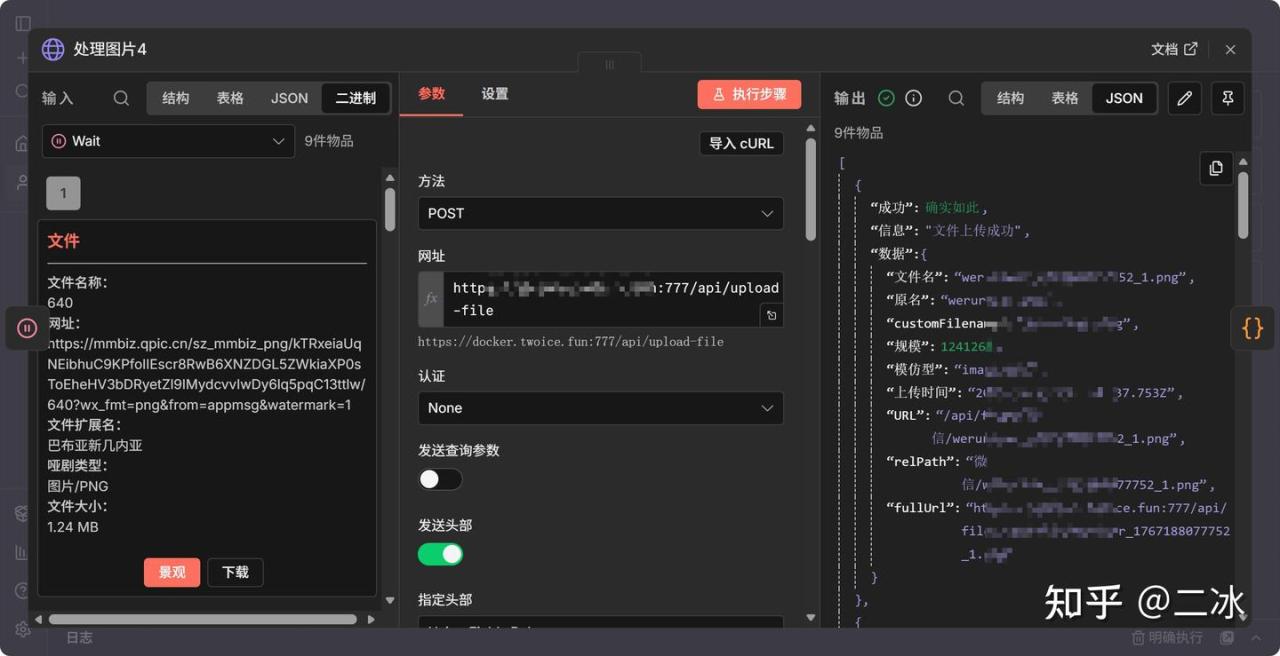
把刚才下载的文件,POST 到你自己的图床。
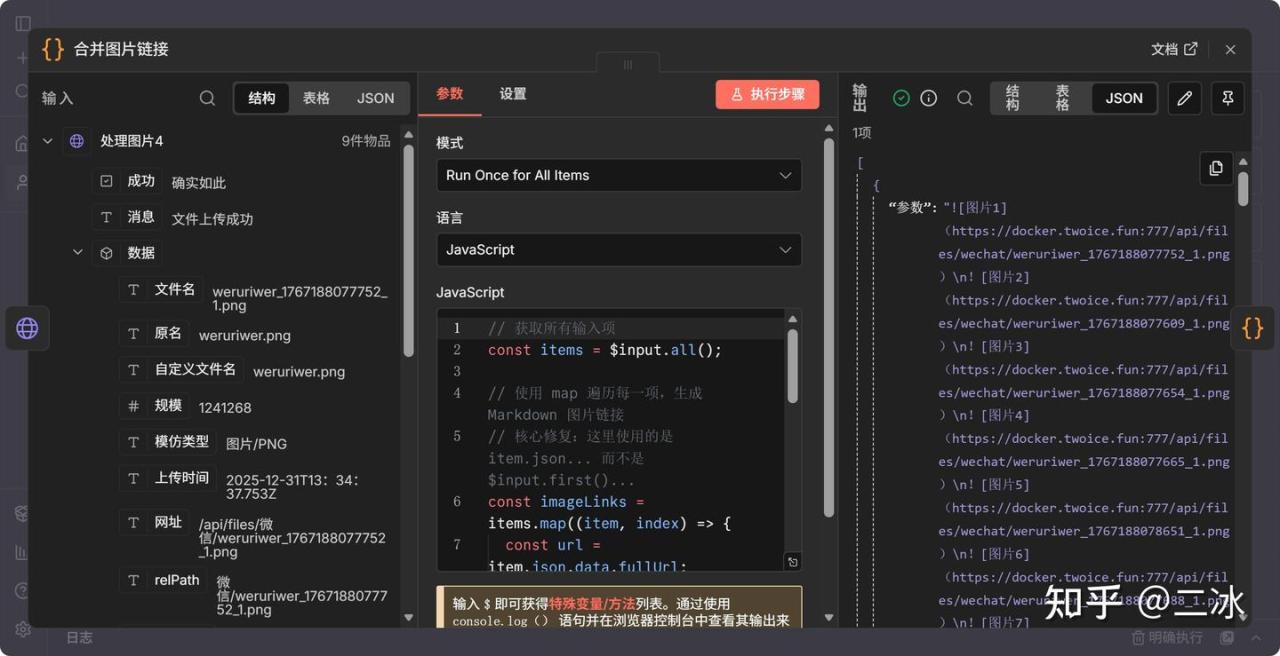
12. 合并图片链接 (Code Node)
图片上传完,会返回一个新的 URL(比如 https://你的域名/image/001.jpg)。这个节点负责把新旧链接对应起来。
13. 组装Markdown和图片 (Code Node)
把 AI 刚开始生成的 Markdown 拿过来,把里面微信的旧链接,全部替换成刚才上传成功的新链接。
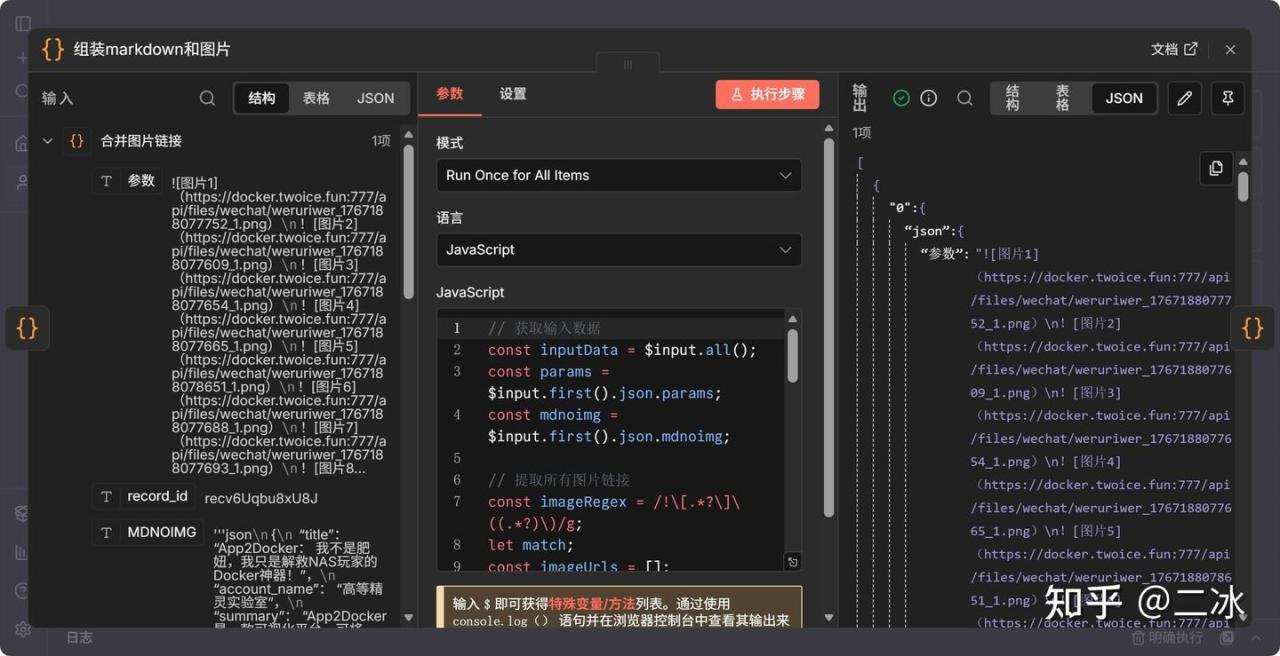
这一步做完,你的文章就彻底“私有化”了。
14. Code (JSON清洗)
AI 输出的数据有时候会带点 ```json 这种格式符号,这个节点专门用来给 AI 擦屁股,确保输出的是标准的 JSON 格式,防止飞书写入报错。
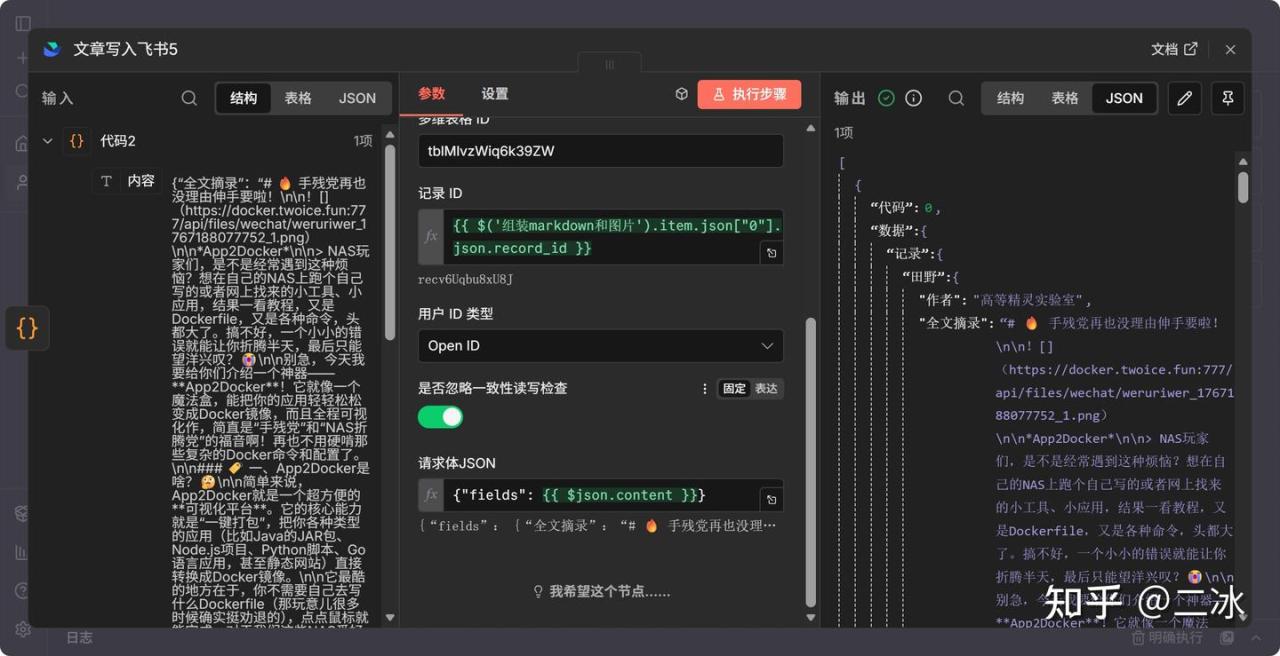
15. 文章写入飞书 (Feishu Update)
最后一步,把清洗好的标题、作者、摘要、正文(新图版)写回去。
用feishu-lite节点的Update操作,把需要写入的变量,写回飞书多维表格。
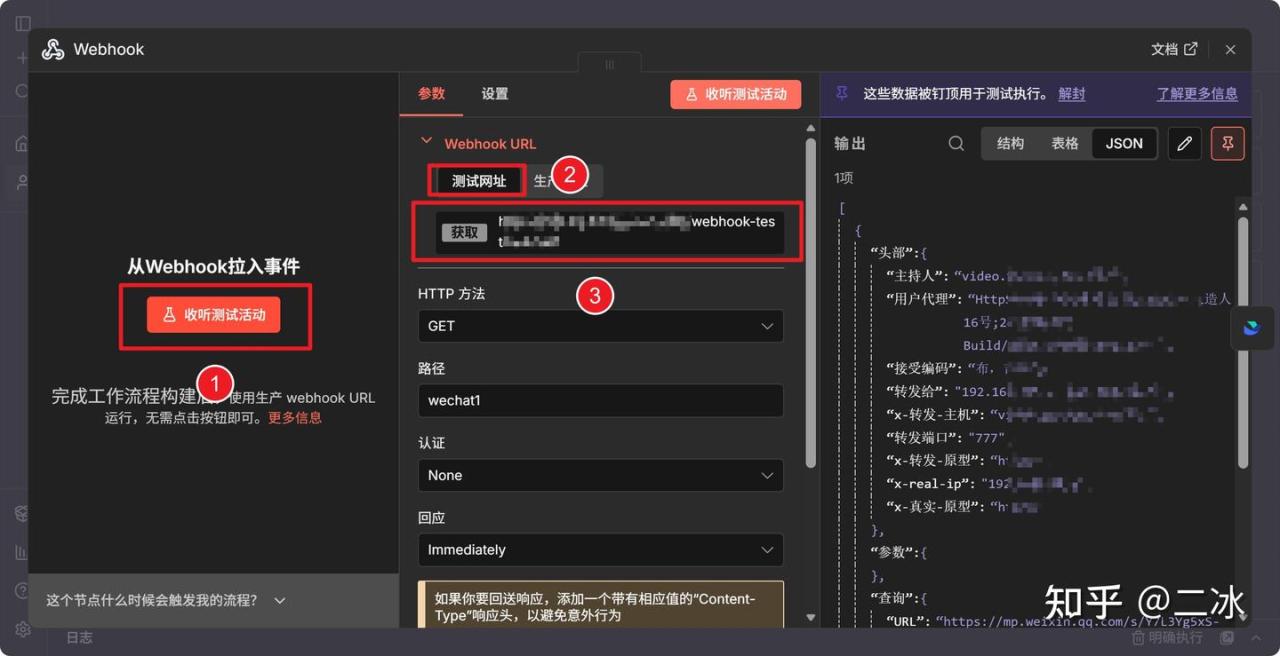
四、运行测试
按如图所示,浏览器打开测试链接,工作流就可以正常启动了
预期效果:
- 1. 飞书表格里显示“处理中”(如果你配置了状态字段)。
- 2. 企业微信收到“开始抓取”的通知。
- 3. 等个一分钟左右(取决于图片数量),飞书表格里的标题、正文被填满。
- 4. 打开正文,检查图片链接,已经变成了你自己的域名,搞定!
五、源码与后续
今天的项目有时间也会放到我们自己开发的n8n托管平台上跑,挨个对接确实很费精力
因为跑的是我们几个人自己的nas,担心被别人乱用,所以设置了积分,每天可以领点积分,反正基本就够你跑几次了,试跑看效果绝对够用了
兄弟们用着好用可以给宣传宣传
本期实战涉及到的http请求接口详细参数、代码节点详细代码、提示词等已更新到飞书文档,兄弟们自行移步查看: