RAG 知识库建设:数据工程全流程
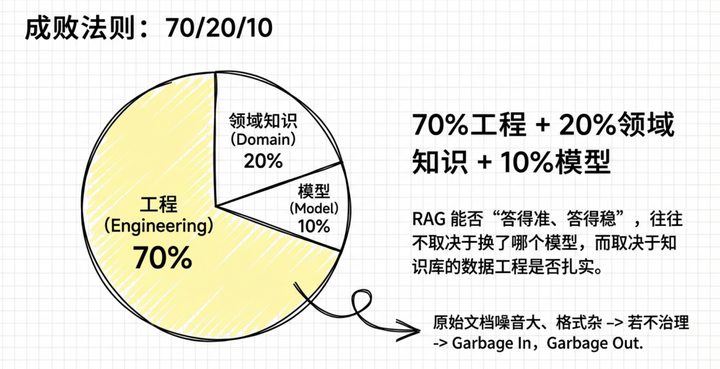
RAG能否“答得准、答得稳”,往往不取决于换了哪个模型,而取决于知识库的数据工程是否扎实。业界常说“70% 工程 + 20% 领域知识 + 10% 模型”,放在 RAG 场景里尤其贴切。原始文档噪音大、格式杂,若不做系统化治理,最终检索召回效果难以保证,生成也很难做到可追溯与可控。
本文以“数据工程视角”拆解 RAG 知识库建设:先给出冷启动与运营的边界,再按端到端流水线逐步讲清楚每一步的目标、关键产物与常见坑。

1. 全局视角:冷启动 vs 知识库运营
RAG 知识库建设通常分为两个阶段:
- 冷启动:把“原始资料”变成“可检索、可追溯、可迭代”的知识资产,核心工作是数据工程。
- 知识库运营:系统上线后持续收集反馈、定位 bad case、修复数据与检索链路,实现长期稳定提升。

2. 数据工程的目标与原则
一个“可用”的 RAG 知识库,至少满足四个工程原则:
- 可检索:既能“搜到”,也能“搜准”,支持多路召回与稳定排序。
- 可追溯:每个检索片段能回到来源文档、章节位置与版本。
- 可控:噪音、权限、敏感信息在入库前被治理,不依赖生成时补救。
- 可运营:问题能被定位到“是数据问题、切分问题、召回问题还是排序问题”,并且可以快速修复与回归验证。

3. 冷启动数据工程:端到端流水线
可以把冷启动理解为一条持续演进的数据流水线:
数据收集 → 数据全景画像与评估 → 噪音识别与清洗 → 脱敏与权限建模 → 去重与版本治理 → 数据结构化

下面逐段展开。
3.1 数据收集
数据是知识库的基石,构建高质量知识库的第一步是全面梳理和汇聚企业内外的知识资产,包括但不限于:
- 企业内部结构化数据:业务系统、业务数据库。
- 企业内部非结构化数据:Word/Excel/PPT/PDF/TXT。
- 外部行业知识:行业报告、白皮书、法律法规与标准、竞品公开材料。

3.2 数据全景画像与评估
正式处理前先做“体检”,目的是把后续成本与风险显性化。
- 格式分布:Markdown/HTML/JSON(易)→ Word/Excel/PPT(中)→ PDF/图片/扫描件(难)。
- 结构分析:标题层级、段落边界、列表/代码块、表格、图片、公式等复杂元素占比。
- 版面噪声:页眉页脚、页码、水印、侧栏导航、广告、重复表头、分栏错序。
- 质量评估:有效性、纯净度、敏感性、重复度。
- 规模统计:文档数、总大小、平均长度。
这一步的输出建议沉淀成一份“数据画像报告”,为清洗规则、解析方案和切分策略提供依据。

3.3 噪音识别与清洗
噪音是检索准确率的“隐形杀手”。清洗策略通常更像工程迭代,而不是一次性写完规则。
推荐使用“LLM 辅助采样 + 规则沉淀 + 回归测试”的闭环:
- 小样本初筛:随机抽取少量文档,先解析出纯文本,让模型辅助标注典型噪音片段与模式。
- 规则沉淀:把模式工程化为正则/关键词过滤/版面规则。
- 扩大验证:覆盖更多目录与格式,重点验证“误删”风险。
- 全量应用:规则收敛后推广到全量,并固化为版本化的规则库。
常见清洗手段可以分层落地:
- 正则表达式:处理模式固定的噪音。
- 关键词过滤:屏蔽明显无效语句。
- 长度/密度过滤:过滤过短行、符号密度过高段落。
- 语义判定:对“正则覆盖不到但常见”的语义噪音做二次判定。
为了避免清洗规则“越写越激进”,建议维护一个黄金测试集:包含已知噪音样本与高价值内容样本,每次更新规则都跑回归,保证稳定性。

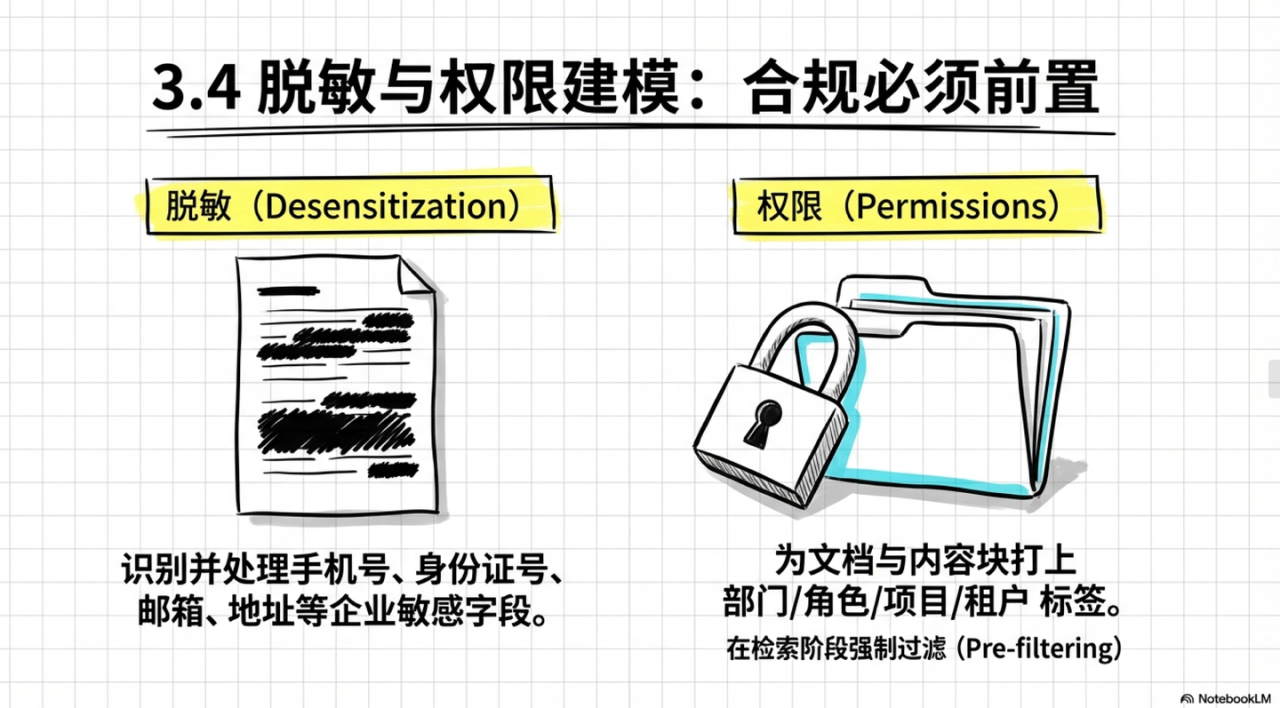
3.4 脱敏与权限建模
RAG 的数据工程必须把合规前置:越晚处理,线上风险越大。
- 脱敏:识别并处理手机号、身份证号、邮箱、地址等企业敏感字段。
- 权限:为文档与内容块打上部门/角色/项目/租户,并在检索阶段强制过滤。
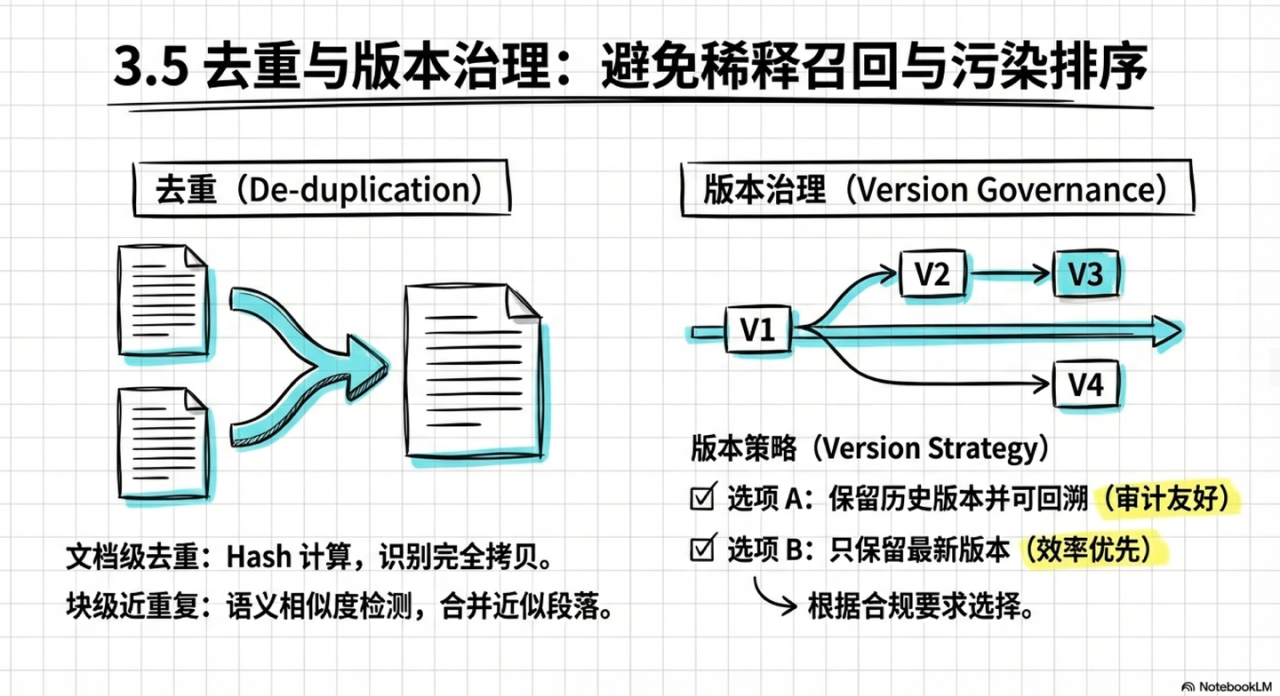
3.5 去重与版本治理
重复内容会直接稀释召回、污染排序,甚至让模型“看似引用很多、其实都一样”。
建议分两级去重:
- 文档级去重:对正文做归一化后计算 hash,识别同文档多份拷贝。
- 段落/块级近重复:对内容块做相似度检测,合并近似段落或只保留最新版本。
同时要定义版本策略:是“保留历史版本并可回溯”,还是“只保留最新版本”。不同合规/审计要求会影响选择。
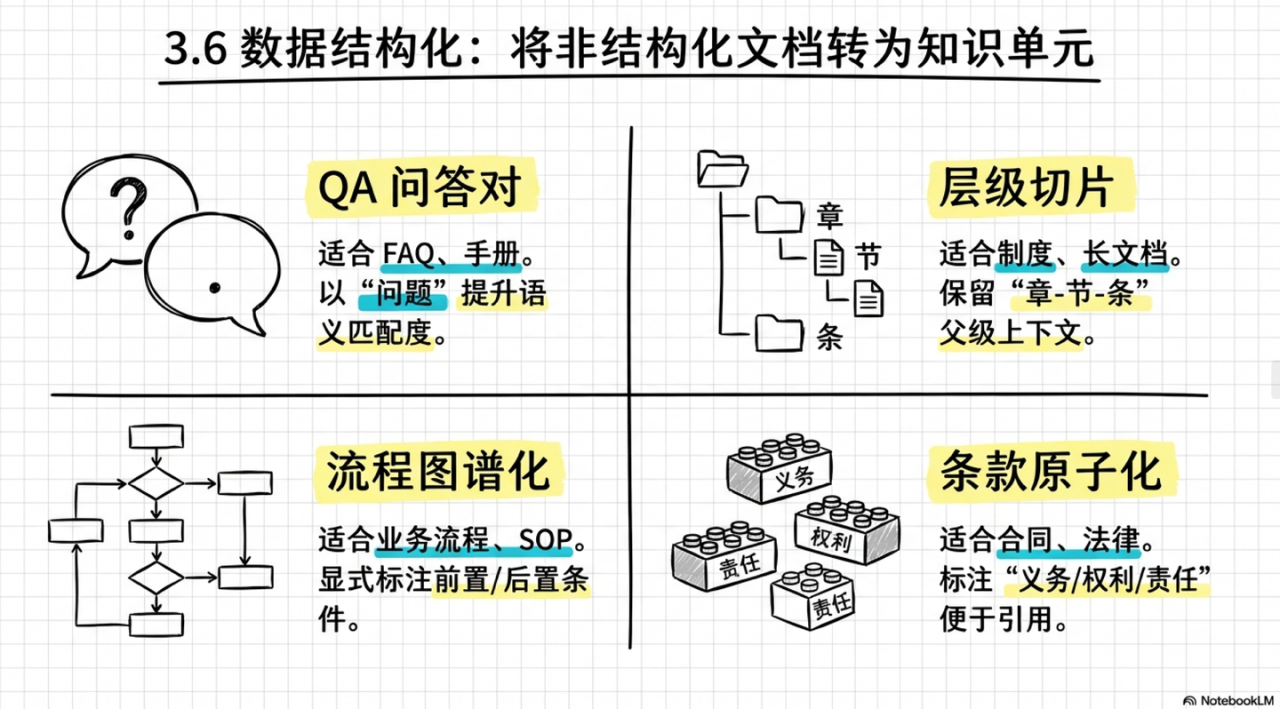
3.6 数据结构化
数据结构化把非结构化文档转为可检索的知识单元,决定检索颗粒度与命中率。
常见策略:
- QA 问答对:适合 FAQ、操作手册;以“问题”作为检索键,以“答案”作为生成素材,提升语义匹配度。
- 层级切片:适合制度、长文档;保留“章-节-条”等父级路径元数据,命中子块时自动携带父级上下文。
- 流程图谱化:适合业务流程、SOP;拆成“步骤节点”,显式标注前置/后置条件,避免流程顺序混淆。
- 条款原子化:适合合同、法律法规;拆成原子规则,并标注“义务”“权利”“违约责任”等标签,便于过滤与精确引用。