GitHub 3.5k Star 的 AI 视频转文档神器

大家好,我是太阳鸟!
刷 B 站、看 YouTube 的时候经常遇到一个问题:视频内容很好,但想记笔记太费劲了。有的视频干货很多,手动整理一遍要花大半天,而且很容易漏掉关键信息。
在 GitHub 上发现了一个神器 AI-Media2Doc,3.5k Star,一键就能把视频/音频转成各种风格的文档。

它能干什么?
简单来说:给它一个视频链接或音频文件,AI 帮你直接输出一篇排好版的文章。
支持的输出风格:
- 小红书风格 — 自动生成小红书图文笔记
- 公众号风格 — 直接输出公众号排版文章
- 知识笔记 — 结构化的学习笔记
- 思维导图 — 梳理视频逻辑结构
- 视频字幕 — 一键导出字幕文件
- 内容总结 — 快速提取核心要点
来看看首页长什么样:

亮点功能
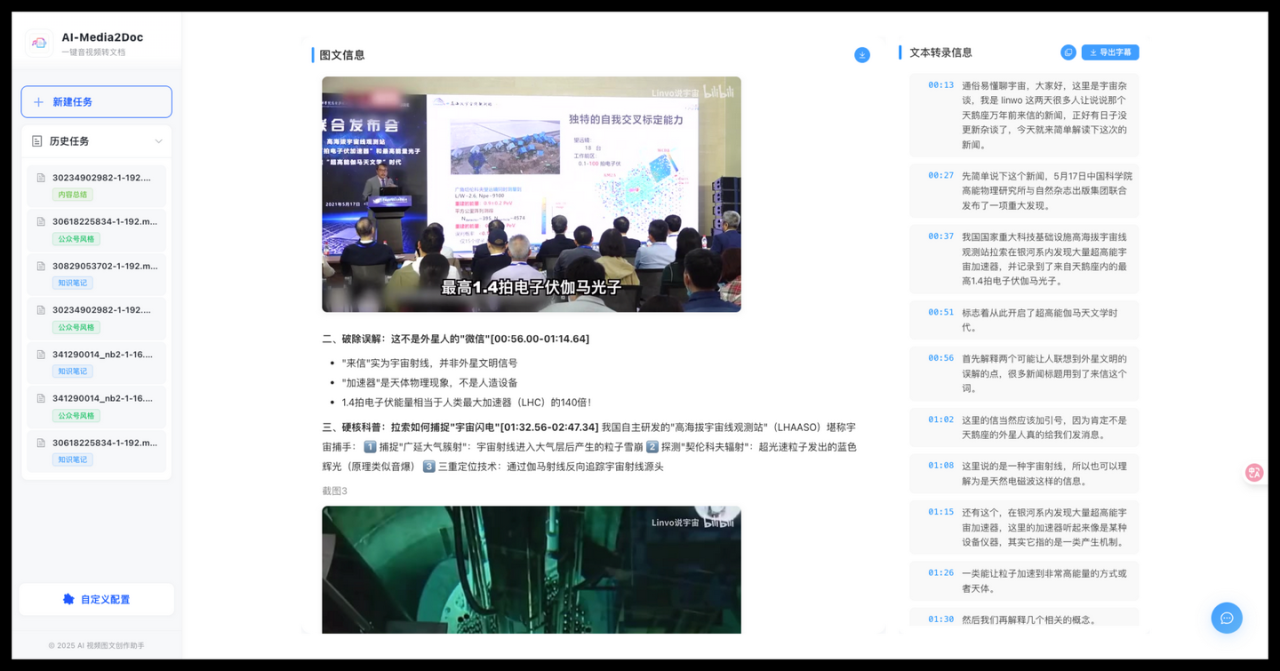
1、智能截图
这个功能是真的绝。它能根据字幕内容,自动在视频对应位置截图,然后插入到文章里——不需要任何视觉大模型,零成本实现图文并茂。
你想想,看了一个 30 分钟的技术教程,它帮你自动截图 + 整理成图文笔记,这效率直接起飞。
2、AI 二次问答
转完文档之后,还能针对视频内容进行 AI 对话。比如:
“这个视频里提到的那个算法,能再详细解释一下吗?”
相当于给视频配了一个专属 AI 助手。
结果页设计得也很清爽,支持一键导出字幕:

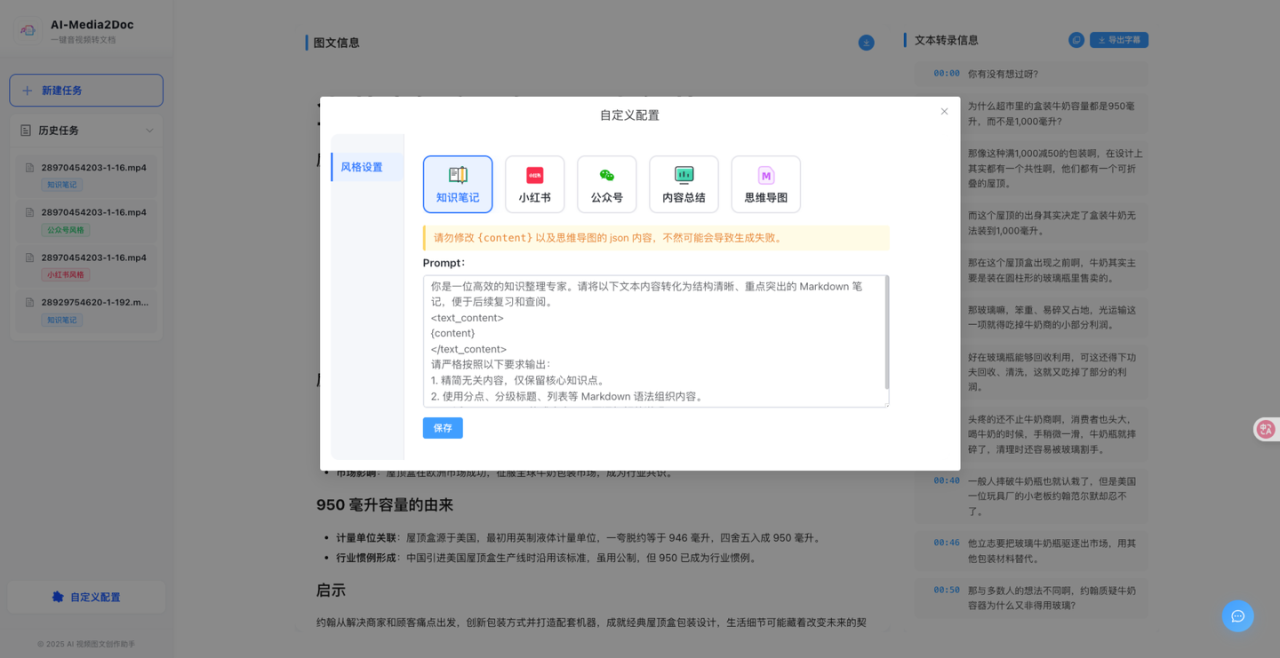
3、自定义 Prompt
不满意默认的输出风格?可以在前端直接自定义 Prompt,想要什么风格就调什么风格。写公众号的、做小红书的、写技术博客的,各取所需。
4、隐私友好
不需要登录注册,任务记录保存在本地,不上传到第三方平台。用 ffmpeg wasm 技术在前端处理音频,甚至不需要本地安装 ffmpeg。
处理流程
整个架构设计得很清晰,来看一下处理流程图:
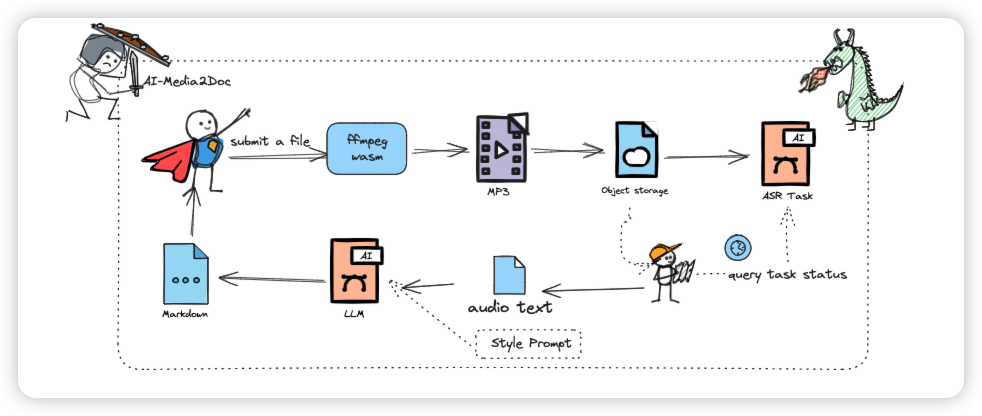
技术栈
- 前端: Vue
- 后端: Python
- 音频处理: ffmpeg wasm(前端直接处理)
- AI 模型: 支持接入各种大模型(ChatGPT、豆包等)
- 部署: Docker 一键部署
怎么用?
最简单的方式就是 Docker 一键部署:
docker-compose -f docker-compose.yaml up -d
三步走:
- 安装 Docker
- 下载
docker-compose.yaml和配置好variables.env
- 运行上面那条命令,完事儿
适合谁?
- 自媒体创作者 — 看完视频直接转成公众号文章/小红书笔记,效率翻倍
- 学生党 — 网课视频直接变学习笔记,期末复习利器
- 知识工作者 — 播客、会议录音秒变结构化文档
- 内容搬运 — 视频内容转文字二次创作(注意版权哈)
源码
项目前后端完全开源,MIT 协议,可以自由使用和修改。前端 Vue,后端 Python,代码结构清晰,有能力的同学可以自己加功能。
开源项目地址: