顶级OCR开源模型来了:免费、强大、上手就能用
我之前处理过一批扫描版的财务表格。
那种PDF,拍照歪的,表格有合并单元格,还有几行手写备注。
用了三个OCR工具,输出结果要么是乱码,要么把表格结构完全打散,合并单元格识别成空白,手写备注直接不见了。
最后还是手动录入的。
那次之后我就一直有个心结,OCR这个问题,到底有没有真的解决掉。
最近看到一个开源项目,Chandra,全称Chandra OCR 2,datalab-to团队做的。
GitHub上8700多个Star,906个Fork。
我去看了一下基准测试数据,Chandra2基准上跑了85.9%,超过了DeepSeek OCR、Mistral OCR,还有GPT-4o。
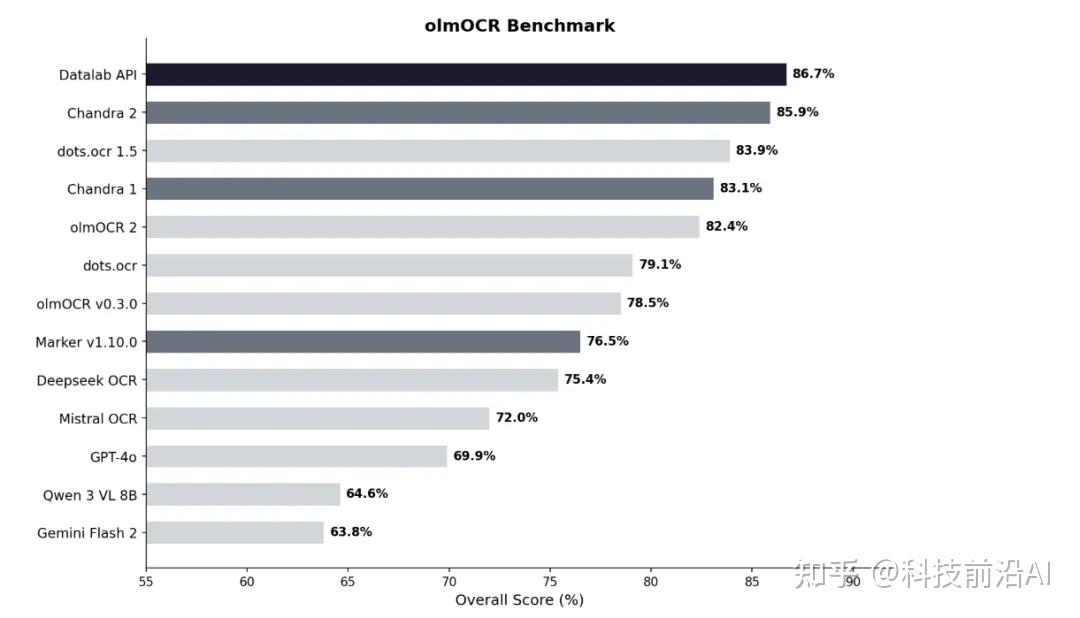
90种语言平均72.7%,Gemini 2.5 Flash是63.8%。
这个数字让我停了一下,因为Gemini 2.5 Flash的多模态能力我是见识过的,不弱。
它和传统OCR最不一样的地方,是「布局感知」。
传统OCR做的事情是认字,你扔进去一张图,它把能认出来的字符吐出来,至于这些字是在表格的哪一格、是不是合并单元格、旁边那个复选框打没打勾,它不管。
Chandra做的是「阅读理解」,它要还原文档的完整结构。
复杂表格,自动识别行列、合并单元格、跨页表格。表单重建,手写表单、复选框、单选框都能识别。手写数学公式,精确转成LaTeX。多语言方面,覆盖90多种语言,在南亚语言比如孟加拉语、泰米尔语上提升很明显。
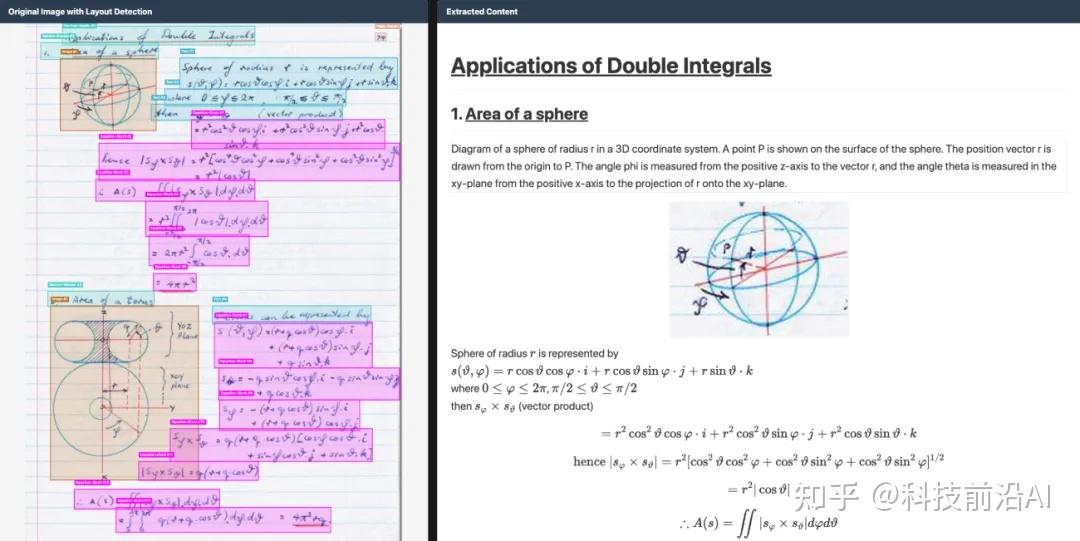
输出格式支持Markdown、HTML、JSON,JSON里还带坐标和元数据,知道每个元素在页面的哪个位置。
官方Playground可以直接去试:
https://www.datalab.to/playground
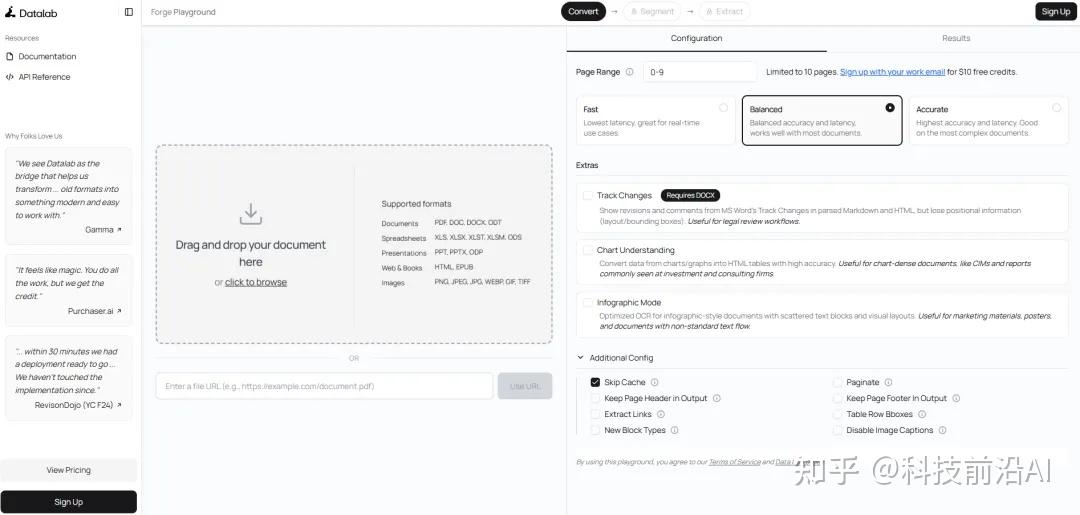
不想在本地折腾的,先去这里玩一下,扔进去一张扫描表格或者手写笔记看看效果。
本地跑起来也不复杂,安装一行命令:
pip install chandra-ocr # 基础安装,推荐vLLMpip install chandra-ocr[hf] # 本地HF模式,含torchpip install chandra-ocr[all] # 全部功能CLI一行处理一个PDF:
chandra input.pdf ./output --method vllm处理整个文件夹,指定页面范围:
chandra ./docs ./output --method hf --page-range "1-5,7-12"输出目录自动生成对应文件。
如果想要Web界面,chandra_app启动Streamlit,chandra_vllm启动vLLM服务。

技术架构上是约4B参数的多模态视觉-语言模型,两种推理后端,vLLM适合高速批量推理、Docker一键部署,Hugging Face本地适合单机测试。
我最感兴趣的应用场景,是历史手稿数字化。
官方案例,手写数学手稿,那种密密麻麻的草书加数学公式,Chandra识别出来直接转成了LaTeX。
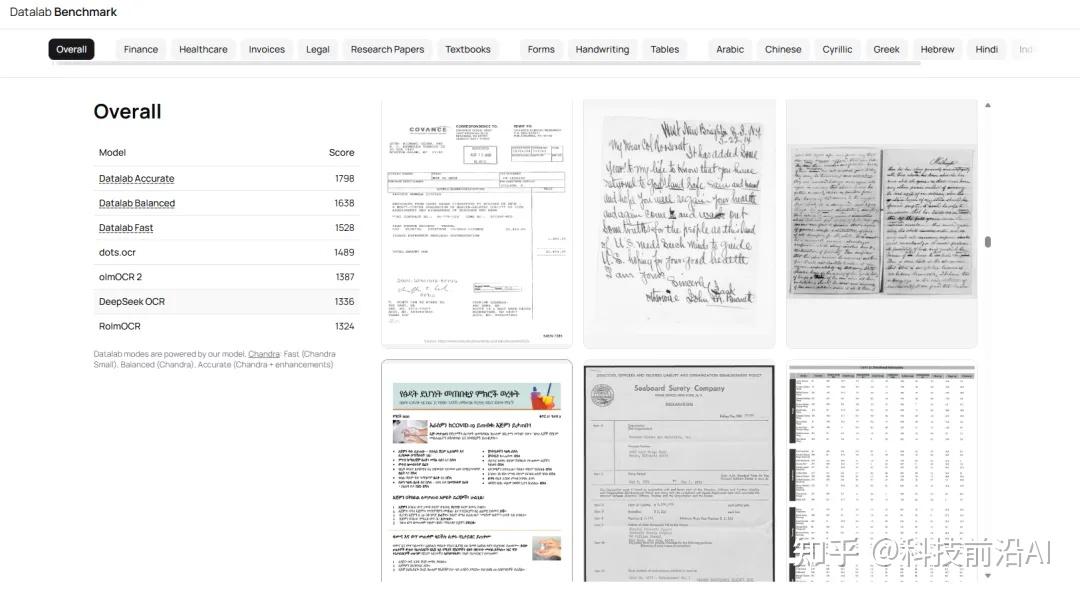
我看到这个结果,想了一下那些还没被数字化的手稿、档案、老教材,稍微有点激动。
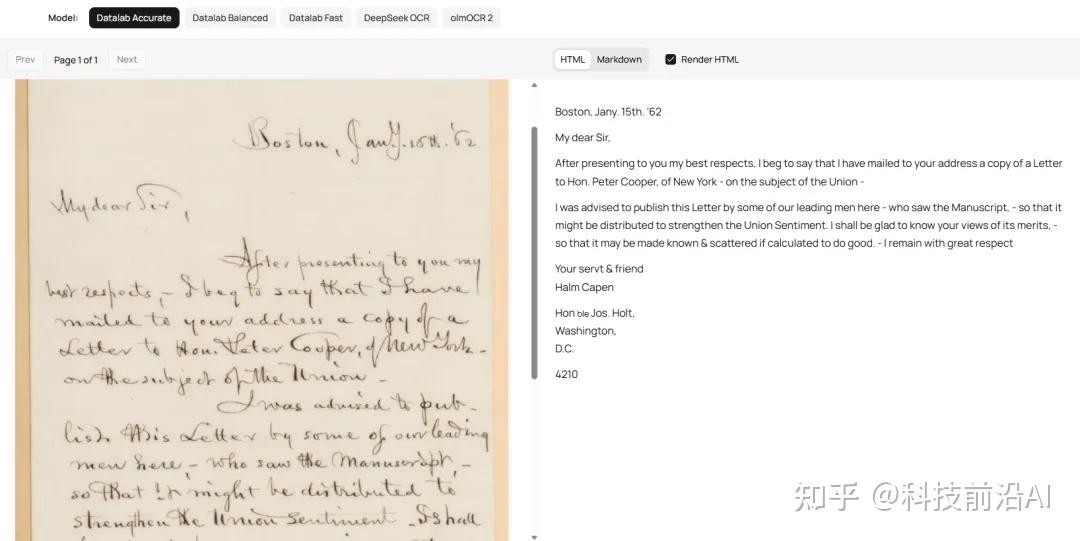
说一句实在话,OCR这个方向做了很多年了,各种工具层出不穷,但大多数在面对「复杂结构」的时候都不太行。
Chandra的基准数据是目前开源里最好的,免费,本地跑,不依赖任何云服务。

如果你手头正好有一批扫描表格、手写文档、历史档案需要处理,这个工具值得认真试一次。