利用python AutoScraper五行代码爬取环湖医院招聘网页


各位知友大家好,我是环湖医院的飞时过。这两天和几位大学的朋友聊爬虫,大家满嘴的Request,Beautiful Soup,lxml,Selenium,Scrapy。但都是抱怨代码写的太多,自定义函数码的太高。这可能是初学爬虫的医生最发愁的问题。今天我们就迎难而上,给大家首发一个只用5行python代码就能爬取任意网页文字的python库——AutoScraper。它的github链接是

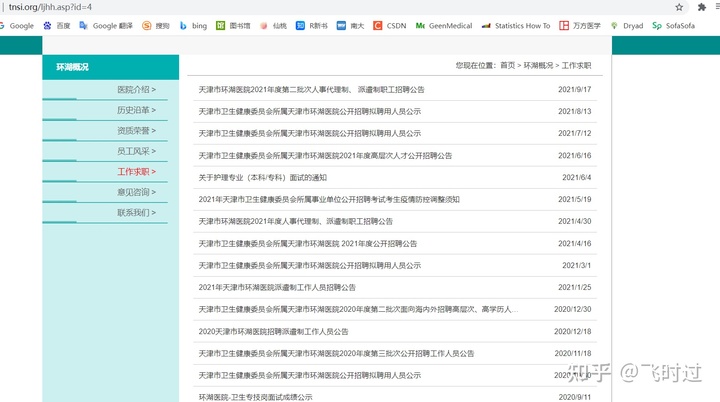
我们以天津市环湖医院的招聘网页给大家举个例子。
from autoscraper import AutoScraper
url = ‘天津市环湖医院欢迎您!‘
wanted_list = [‘天津市环湖医院2021年度第二批次人事代理制、 派遣制职工招聘公告’]
scraper = AutoScraper()
result = scraper(url, wanted_list)
print(result)
就这五行,五行代码以后就可能爬取到所有的招聘内容

python真的是越做越出色,希望大家多多支持。谢谢