Python 爬虫如何获取 JS 生成的 URL 和网页内容?
不到万不得已,不推荐使用 selenium,该案例很简单,ajax 加载的数据基本解决思路一致:
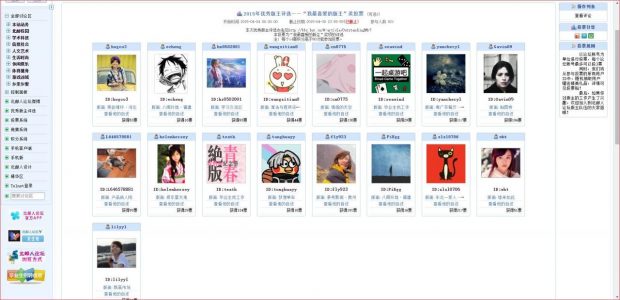
其他部分需要登录才能查看,这里只能对以下部分进行分析:
该论坛优秀版主评选链接:北邮人论坛-北邮人的温馨家园
内容接口链接:https://bbs.byr.cn/bmvote/view/3?_uid=guest

直接检查网页源代码,即可看到 html 页面的原始文档,可以看到并不存在各版主相关信息,能够知道这些数据都是通过 ajax 加载的:

F12 打开开发者人员工具或者通过 Fiddler 进行抓包,这里更推荐第二种,以下即抓包到了完整的版主信息响应内容,该网站没什么反爬,直接访问该接口链接即可提取到数据:


代码演示:
import requests
from lxml import etree
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"x-requested-with": "XMLHttpRequest"
}
url = "https://bbs.byr.cn/bmvote/view/3"
params = {
"_uid": "guest"
}
response = requests.get(url, headers=headers, params=params).text
html = etree.HTML(response)
# 获取每个优秀版主的 ID
info_id = html.xpath('//*[@id="widget_bm"]/div/div/span/a/text()')
print(response)
for i in range(len(info_id)):
print('%s 为优秀版主' % info_id[i])以上是用 xpath 获取了所有优秀版主的 ID,用正则或是其他亦可 ~
所以获取该类型的网页数据,主要是得找到数据加载的接口位置 ~
欢迎关注 K 哥爬虫公众号,我会分享一些 JS 逆向知识,比较适合新手 ~