python爬虫 可以跳过登录界面,成功爬取淘宝商品信息,就这么简单!!!
修改request的headers属性,可以跳过登录界面,成功爬取淘宝商品信息
备注:先安装Python3.X以上开发环境,在执行下面步骤 (百度有很多安装环境文章)
功能描述:目标:获取淘宝搜索页面信息,提取其中商品的名称、价格、图片链接、商品地址、付款人数生成csv格式导出数据
技术路线:Requests-Re
接口描述:
搜索接口:https://s.taobao.com/search?q=短裙
翻页接口:第二页 https://s.taobao.com/search?q=短裙&s=44×2
第三页 https://s.taobao.com/search?q=短裙&s=44×3
程序结构设计:
步骤1:提交商品请求,循环获取页面
步骤2:对于每一个页面,提取其中商品的名称、价格、图片链接、商品地址、付款人数
步骤3:将数据信息输出到csv文件
代码实现:
用爬虫爬淘宝,得到的页面是登录页面,需要“假登录”,获取头部headers信息,作为参数传给requests.get(url,headers = header),获取方法如下
详细步骤:以Google浏览器为例
1.登录淘宝,进入搜索页,F12
2.选择Network,刷新一下,找到最上方以search?开头的文件,鼠标右键
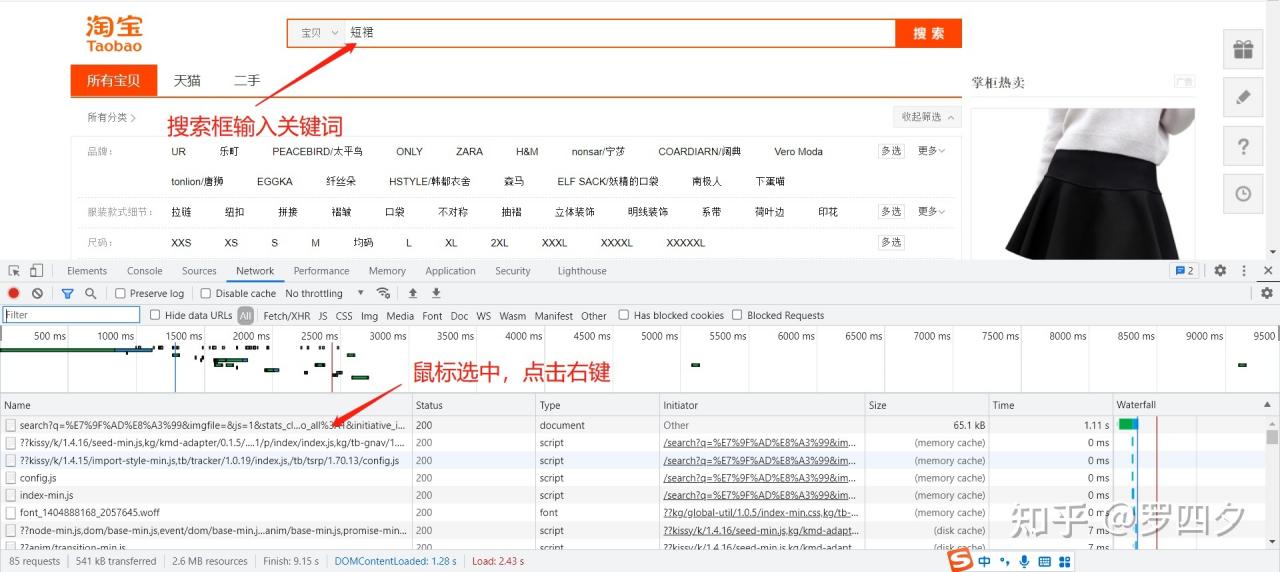
3.选择copy,copy as cURL(bush)
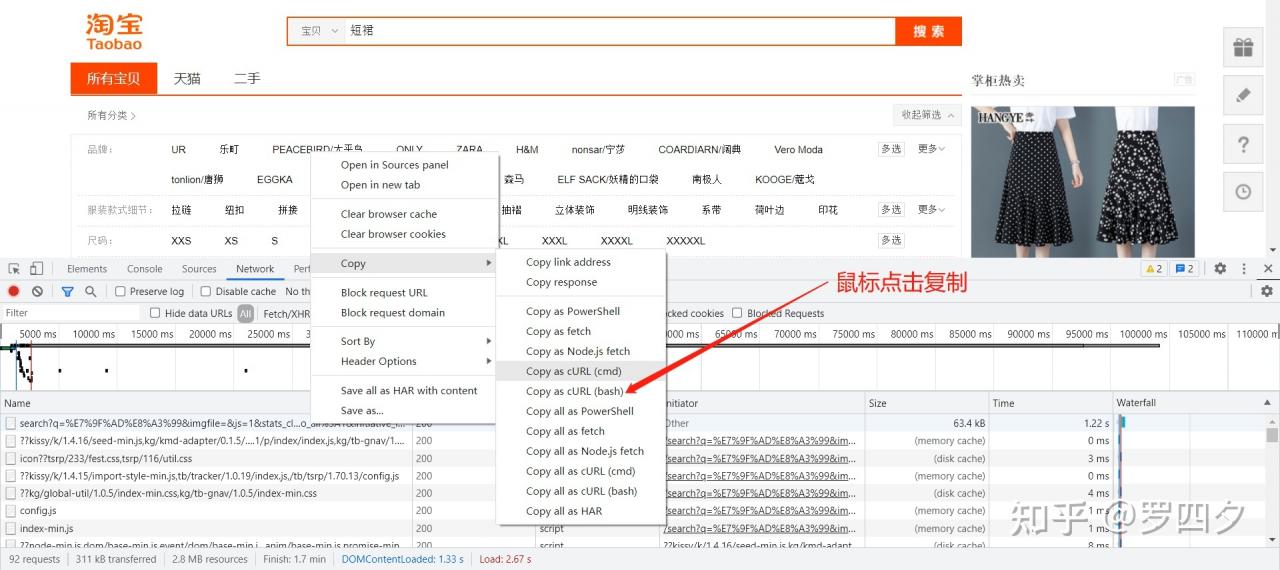
4.在https://curl.trillworks.com/,将上一步复制的内容粘贴到curl command窗口
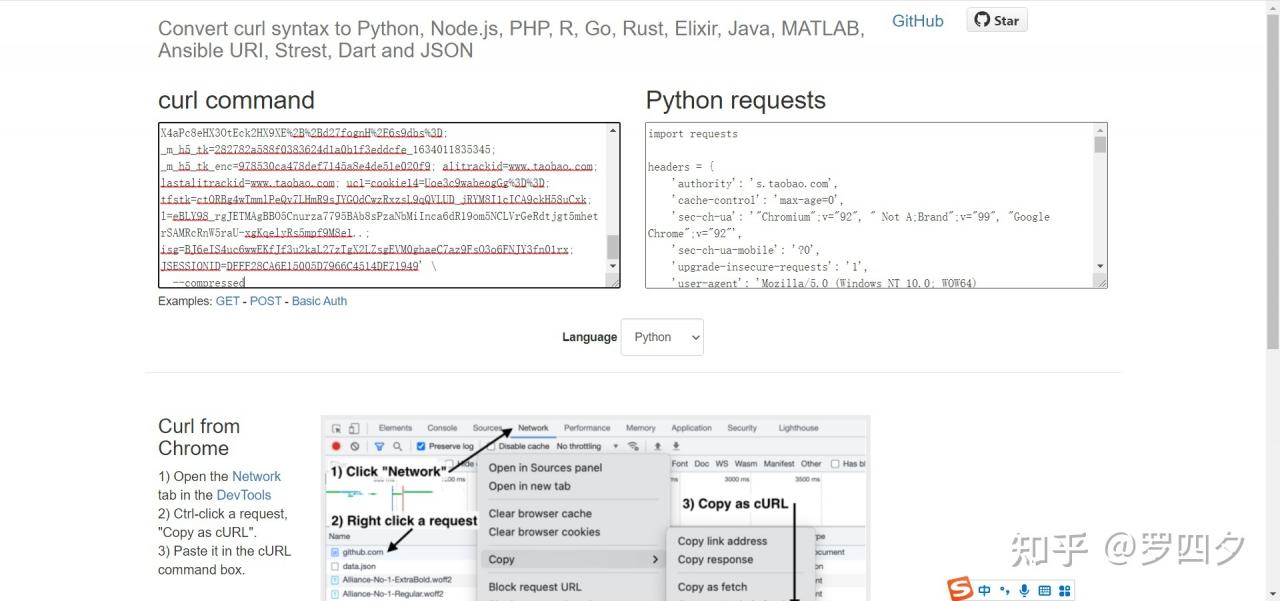
5.复制右侧的headers内容,在程序中用以变量header保存,作为参数传给requests.get(url,headers=header)
关键部分上代码:
#获取淘宝商品信息
import requests
import csv
import os
import pandas as pd
import time
import re
def getHtmlText(url):
try:
header = {
‘authority’: ‘s.taobao.com‘,
‘cache-control’: ‘max-age=0’,
‘sec-ch-ua’: ‘”Chromium”;v=”92″, ” Not A;Brand”;v=”99″, “Google Chrome”;v=”92″‘,
‘sec-ch-ua-mobile’: ‘?0’,
‘upgrade-insecure-requests’: ‘1’,
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36’,
‘accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9’,
‘sec-fetch-site’: ‘same-origin’,
‘sec-fetch-mode’: ‘navigate’,
‘sec-fetch-user’: ‘?1’,
‘sec-fetch-dest’: ‘document’,
‘referer’: ,
‘accept-language’: ‘zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7’,
‘cookie’: ,
}#隐去了cookie信息和referer信息,你可以登陆淘宝账号获取方法在文章代码实现步骤4
param = (
(‘q’, ‘\u77ED\u88D9’),
(‘imgfile’, ”),
(‘js’, ‘1’),
(‘stats_click’, ‘search_radio_all:1’),
(‘initiative_id’, ‘staobaoz_20211012’),
(‘ie’, ‘utf8’),
)
r = requests.get(url, headers = header, params = param)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print(“爬取失败”)
return “”
def parsePage(ilist,html):
try:
plt = re.findall(r’\”view_price\”:\”\d+\.\d*\”‘,html)
tlt = re.findall(r’\”raw_title\”:\”.*?\”‘,html)
loc = re.findall(r’\”item_loc\”\:\”.*?\”‘,html)
sale = re.findall(r’\”view_sales\”\:\”[\d\.]*.*?\”‘,html)
img = re.findall(r’\”pic_url\”\:\”.*?\”‘, html)
# imgd = re.findall(r’\”detail_url\”\:\”.*?\”‘, html)
# print(img)
# print(len(plt))
for i in range(len(plt)):
price = eval(plt[i].split(‘\”‘)[3])
title = tlt[i].split(‘\”‘)[3]
location = eval(loc[i].split(‘:’)[1])
sales = eval(sale[i].split(‘:’)[1])
image = img[i].split(“:”)[1]
# imaged = imgd[i].split(“:”)[1]
ilist.append([title,price,image,location,sales])
# print(ilist)
except:
print(“解析出错”)
def printGoodsList(ilist,num,goods,depth):
tplt = “{0:<3}\t{1:<30}\t{2:>6}”
print(tplt.format(“序号”,”商品名称”,”价格”))
count = 0
# 二维数组首位添加元素
ilist.insert(0,[“商品名称”,”价格”,”图片URL”,”地址”,”付款数”])
# 数据导出
for i in range(len(ilist)):
f = open(str(goods)+str(depth)+’.csv’, ‘a+’,newline=”)
writer = csv.writer(f)
writer.writerow(ilist[i])
f.close()
print(“写入成功”)
def main():
goods = “连衣裙”
depth = 2
start_url = “https://s.taobao.com/search?q=“+goods
infoList = []
num = 20
for i in range(depth):
try:
url = start_url + ‘&S=’ + str(44*i)
html = getHtmlText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList,num,goods,depth)
main()
得出数据如图:
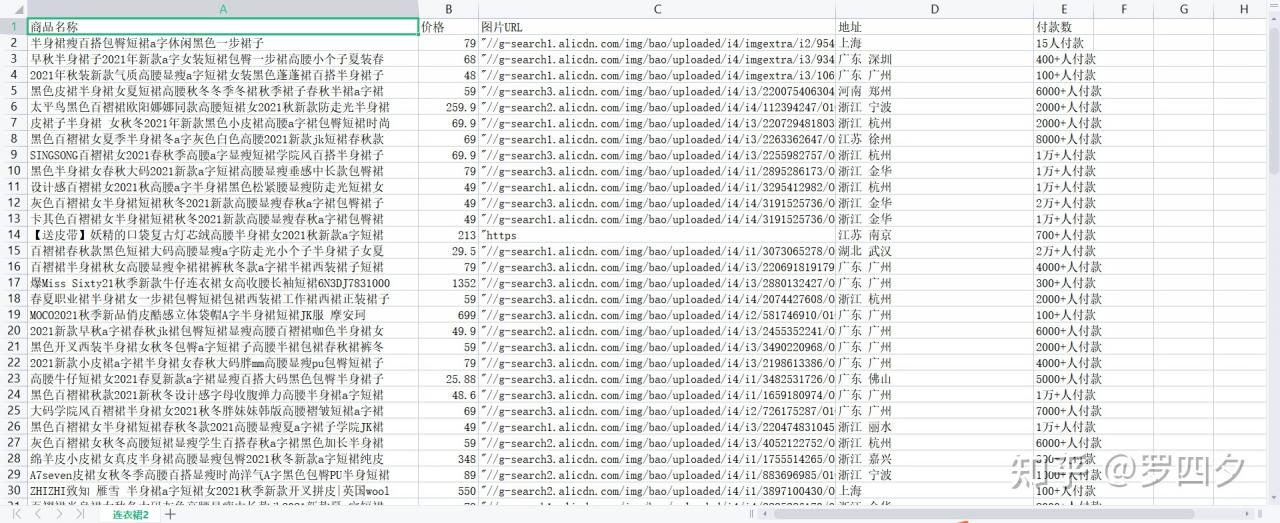
备注:要配只好本地开发环境哦