使用python进行网络爬虫(理论篇2)
BeautifulSoup库可以很好地解析通过requests库爬取到的网页内容,并从中提取出有用的信息。
1、安装BeautifulSoup库,运行cmd,执行程序
pip install BeautifulSoup42、一段简单代码测试安装结果
import requests
from bs4 import BeautifulSoup
url = "https://www.baidu.com/"
r = requests.get(url)
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.prettify())这段代码是将百度首页的内容爬取后,并通过引用BeautifulSoup库的prettify函数,将其按照解析后的格式打印出来,这样打印的结果呈现树状格式。
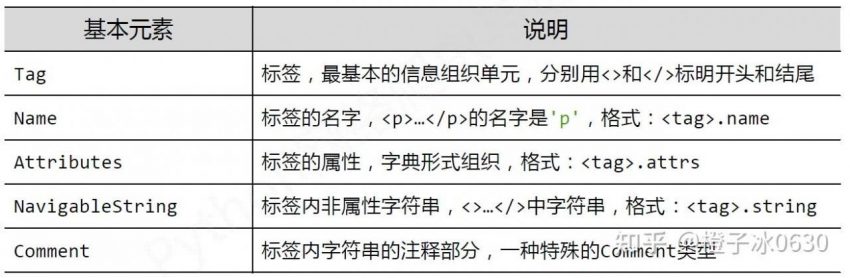
3、html通过预定义的<>…</>标签形式组织不同类型的信息,标签的元素包括:名称、属性、字符串、注释等,相应的,BeautifuSoup类包含的元素如图。

沿用上一段代码的结果,如下代码可获取html文件的标签,标签名称、字符串等,感兴趣的朋友可以自己运行代码查看结果。
soup.a
soup.a.name
soup.a.attrs
soup.a.string直接使用soup.a,返回的是文件中第1个a标签内容。
4、使用BeautifulSoup库提取信息,最常用的是find_all方法,其基本语法如下。
<>.find_all(name, attrs, recursive, string, **kwargs)
- name : 对标签名称的检索字符串
- attrs: 对标签属性值的检索字符串,可标注属性检索
- recursive: 是否对子孙全部检索,默认True
- string: <>…</>中字符串区域的检索字符串
继续沿用上面代码的结果,输入:
soup.find_all('a')结果会输出全部a标签内容,并存储至列表中。若对属性进行筛选,筛选出class = ‘mnav’的,可
soup.find_all('a',class = 'mnav')若需找出string包含”百度”的a标签,可
soup.find_all('a',string = re.compile('百度'))这里用到了正则表达式,下一篇将介绍。
使用BeautifulSoup库可以提取html文件中一切想要的信息,并且代码简洁。有兴趣的朋友可以多加练习来掌握这个类。