ragflow+ollama 本地知识库搭建

链接:https://zhuanlan.zhihu.com/p/8005251874
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
介绍
ragflow 可以提高RAG 召回率,在创建知识库的时候,在解析的时候有多种解析方式。
使用的AI 原生数据库Infinity.
RAGFlow:采用OCR和深度文档理解结合的新一代 RAG 引擎
可以直接查看解析以及命中,如何解析识别,这个部分比较好。
检索增强生成引擎 RAGFlow 正式开源!仅一天收获上千颗星_生成式 AI_张颖峰_InfoQ精选文章
RAGFlow 在处理文档时,给了不少的选择:Q&A,Resume,Paper,Manual,Table,Book,Law,通用

本地搭建知识库分类:
- RAGFlow
- FastGPT
- Dify.ai
- AnythinLLM
- MaxKB
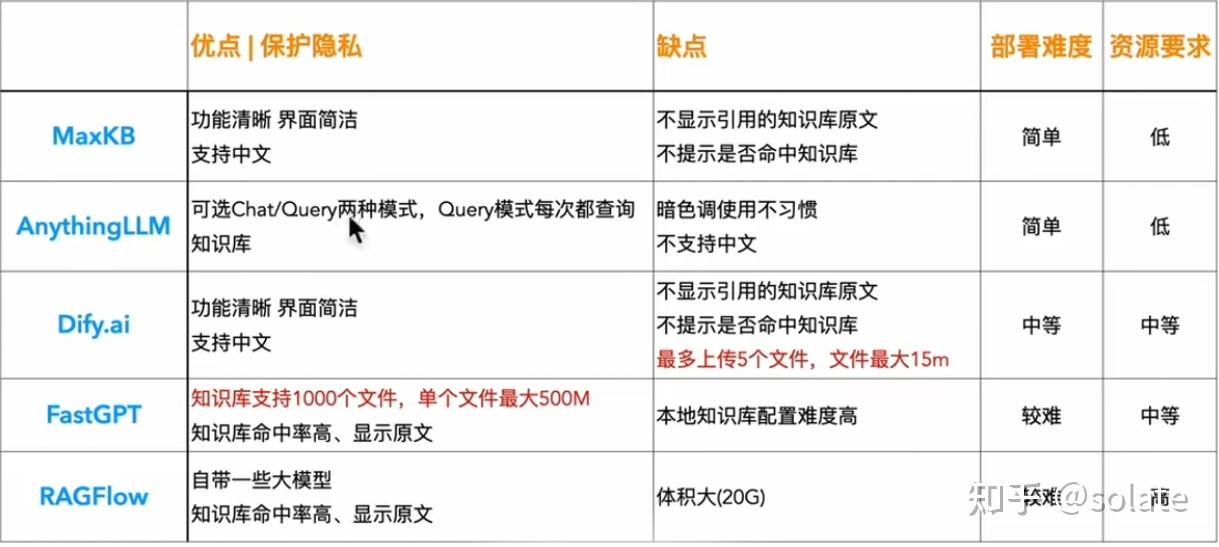
RAGFlow/FastGPT > Dify
dify
dify 可以看这篇
solate:Dify+ollama 工作流,智能体,知识库
准备
- CPU >= 4 核
- RAM >= 16 GB
- Disk >= 50 GB
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
RAGFlow
github: https://github.com/infiniflow/ragflow
demo: https://demo.ragflow.io
中文: ragflow/README_zh.md at main · infiniflow/ragflow
支持 GraphRAG 启发于graphrag和思维导图。
安装
- 设置vm.max_map_count (未设置依然可以)
https://github.com/docker/for-mac/issues/7047
windows docker 安装 ES vm.max_map_count [65530]
open powershell
wsl -d docker-desktop
sysctl -w vm.max_map_count=262144
exit2. 下载代码
git clone https://github.com/infiniflow/ragflow.git3. 进入docker 启动
$ cd ragflow/docker
$ docker compose -f docker-compose.yml up -d
# 也可以执行cn这个
docker-compose-CN-oc9.yml4. 服务器启动成功后再次确认服务器状态:
docker logs -f ragflow-server
注册/登录
输入 http://localhost 会跳转到登录界面
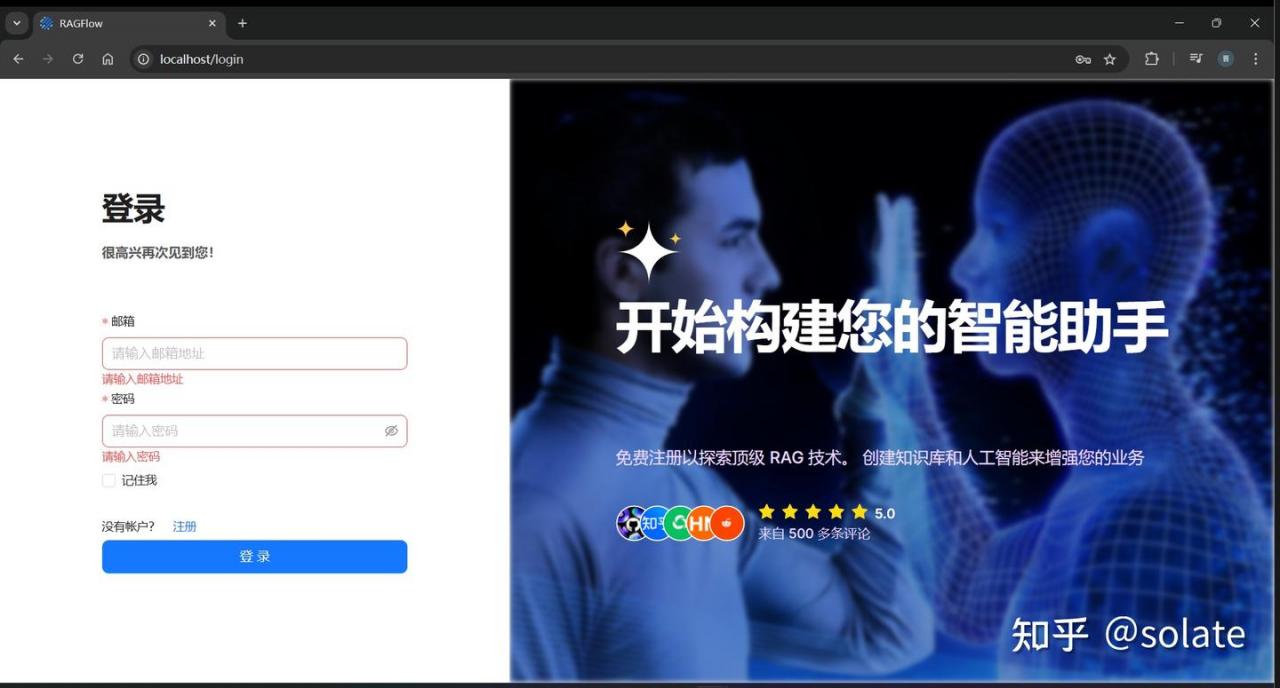
点击注册,可以注册一个账号
admin
admin@123注册后登录,登录后界面如下
右上角可以切换成中文
ollama
今天换一个
- chat: qwen2.5:0.5b
- embedding: herald/dmeta-embedding-zh
ollama run qwen2.5:0.5b
ollama pull herald/dmeta-embedding-zh
模型配置
点击头像,进入设置界面 , 还是和上一篇一样的配置过程
因为是在docker 里 所以写docker 的
http://host.docker.internal:11434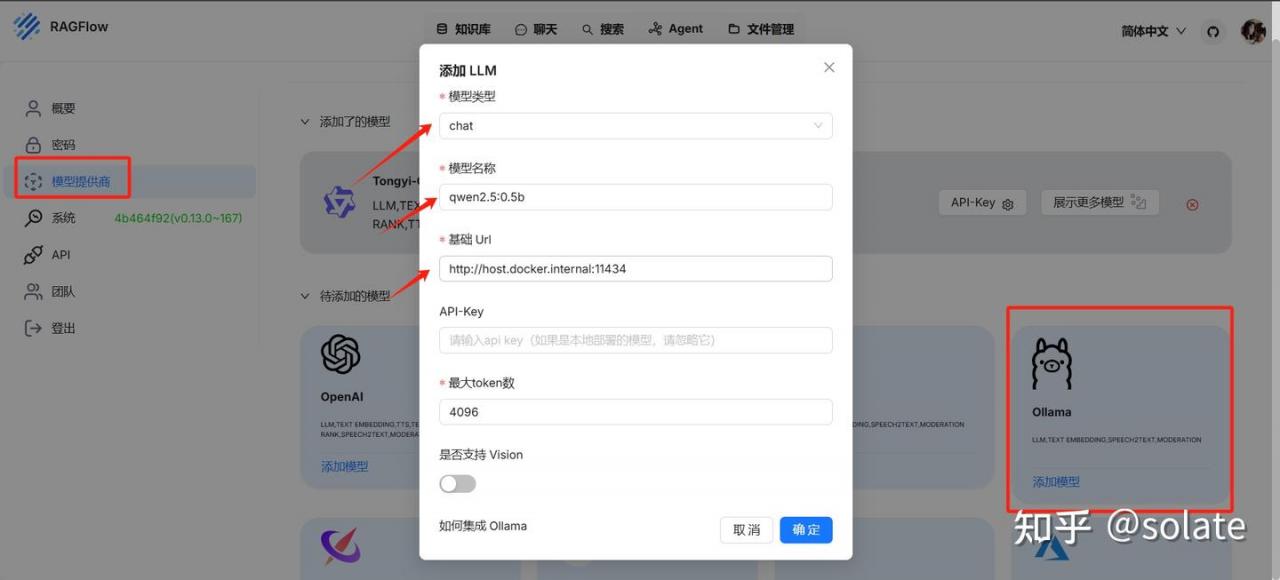
如果要写自己本机的IP, 使用ipconfig 查看本地IP地址,填写ip地址,要写自己的。
http://192.168.0.101:11434如果不成功, 可以看这个
【RAGFlow】“提示 : 102 Fail to access model(qwen2.5:14b).**ERROR**: [Errno 111] Connection refused” 的解决

这么启动,修改启动host, 反正方法有多样。
OLLAMA_DEBUG=1 OLLAMA_ORIGINS="*" OLLAMA_HOST="0.0.0.0" ollama serve > ~/workspace/ollamawp/server.log 2>&12. 添加embedding 模型
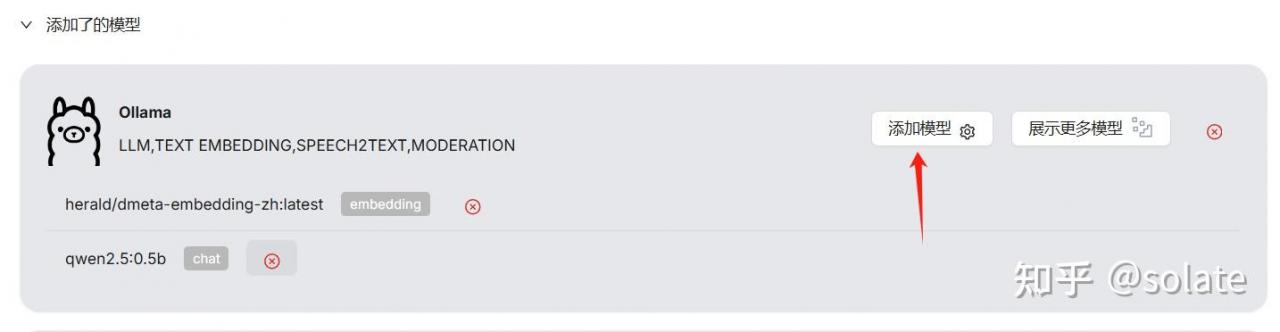
3. 系统模型设置
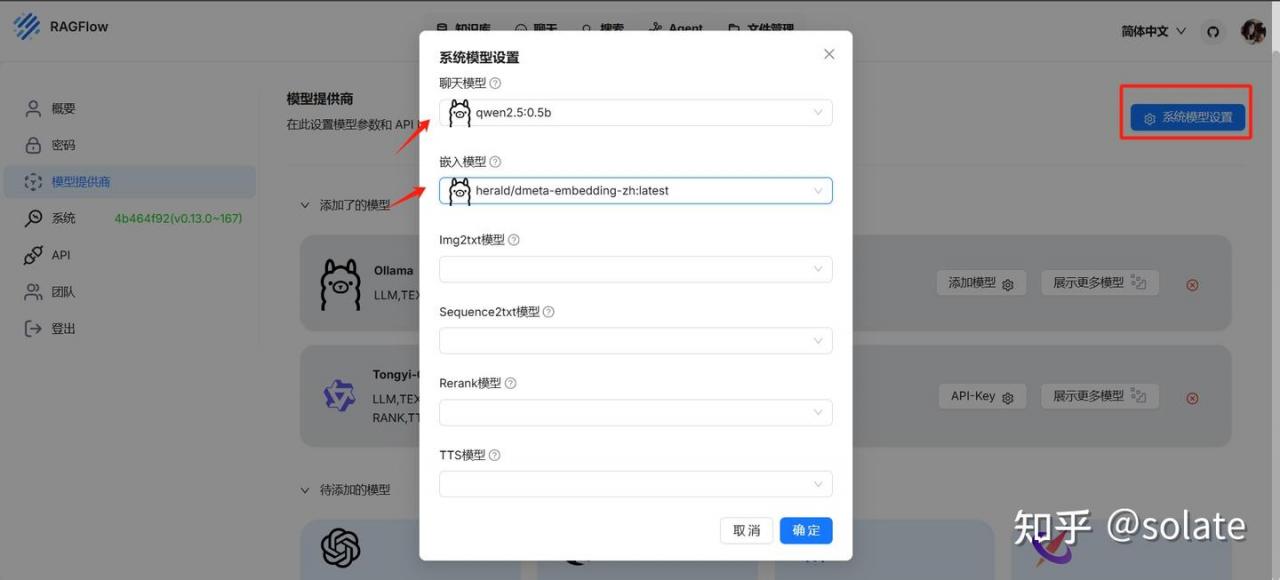
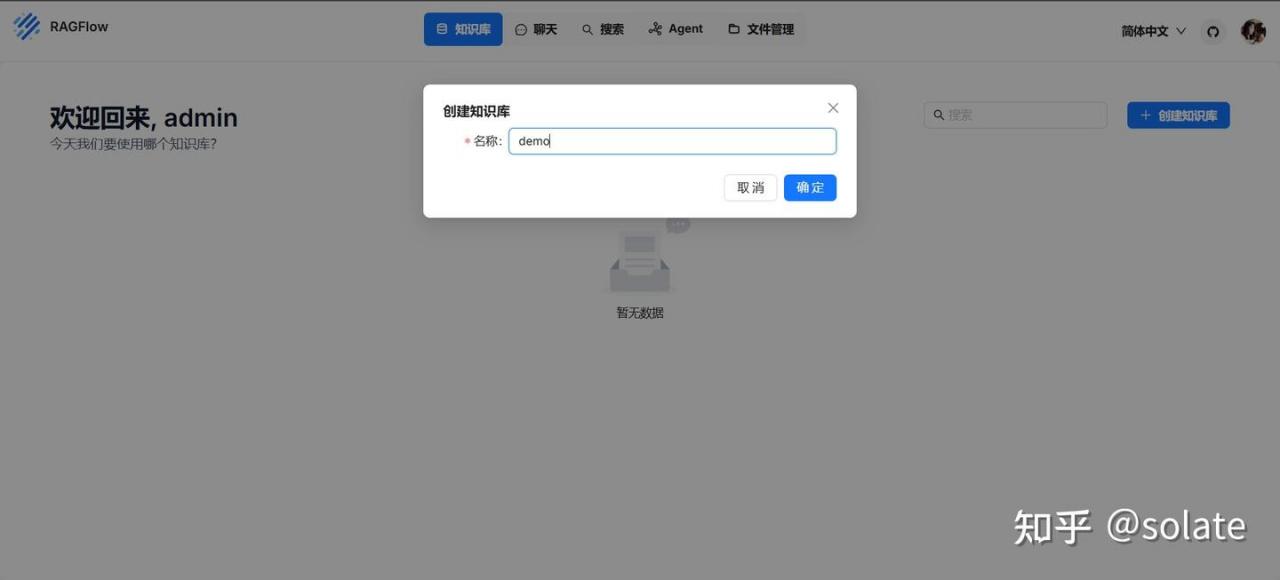
创建知识库
返回首页知识库,点击创建知识库。
解析方法
创建后进来, 还是添加劳动法
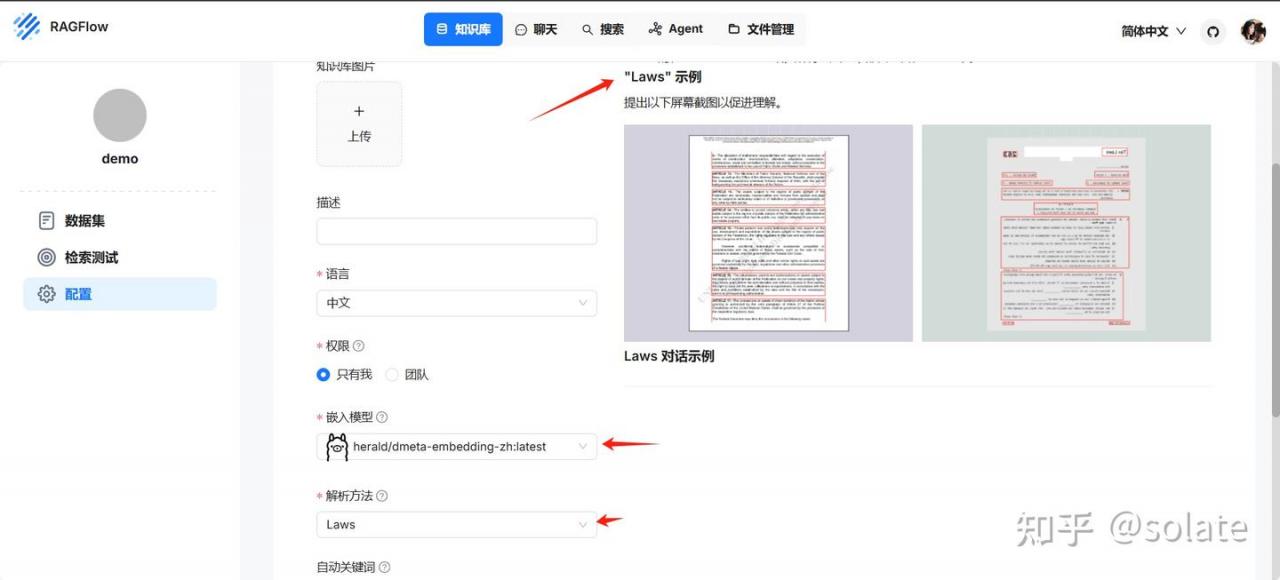
配置这里设置解析方法,这里有示例, 这次选的是laws 法律文件, 解析方法不同会有不同的示例。

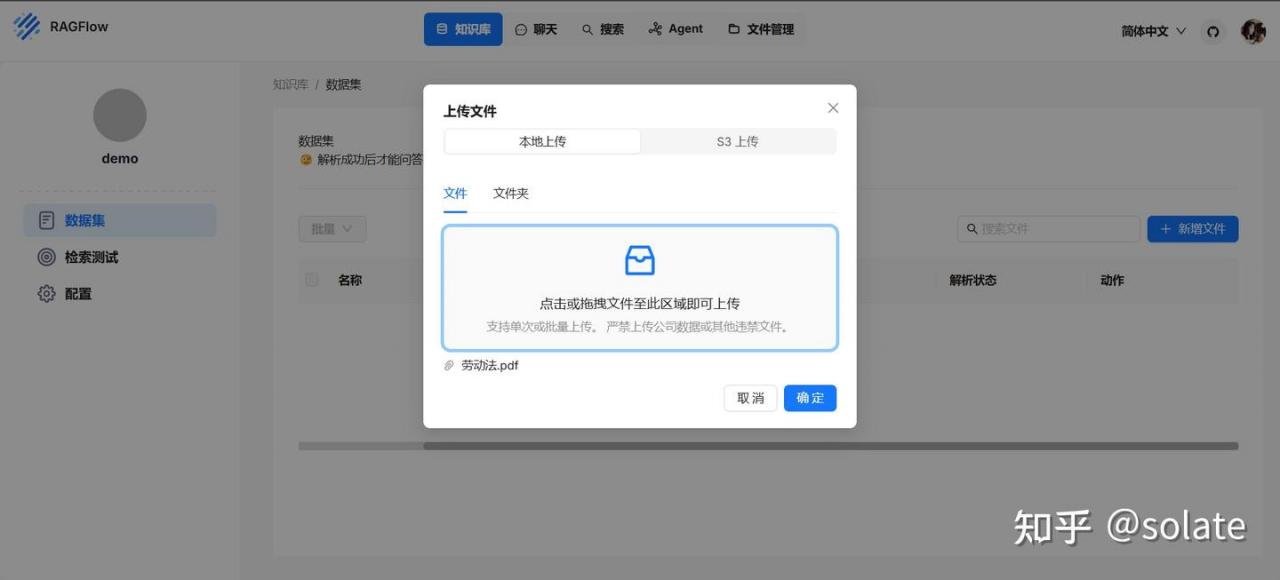
上传文件
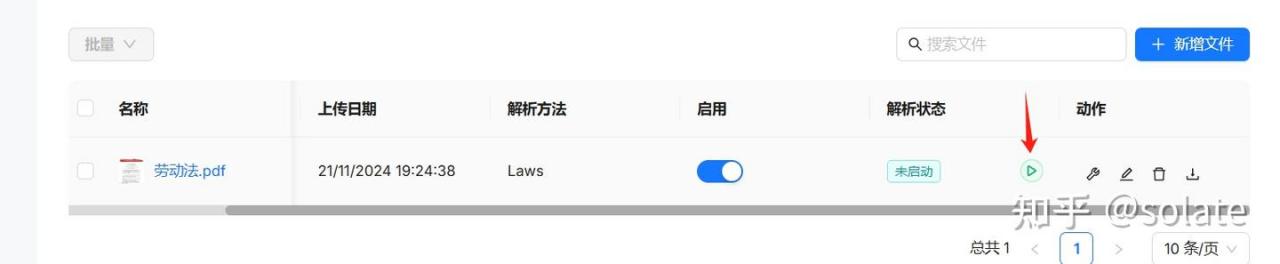
点击开始解析


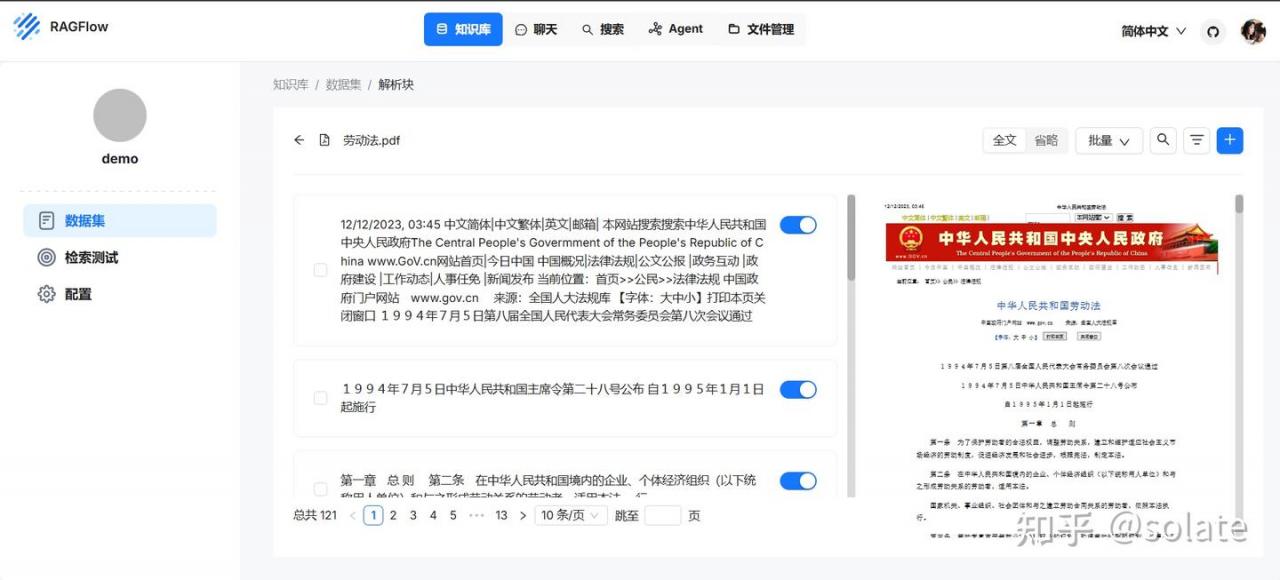
解析完成以后可以看解析的结果
聊天-使用RAG
- 新建助理, 名字随意
2. 然后就可以对话了
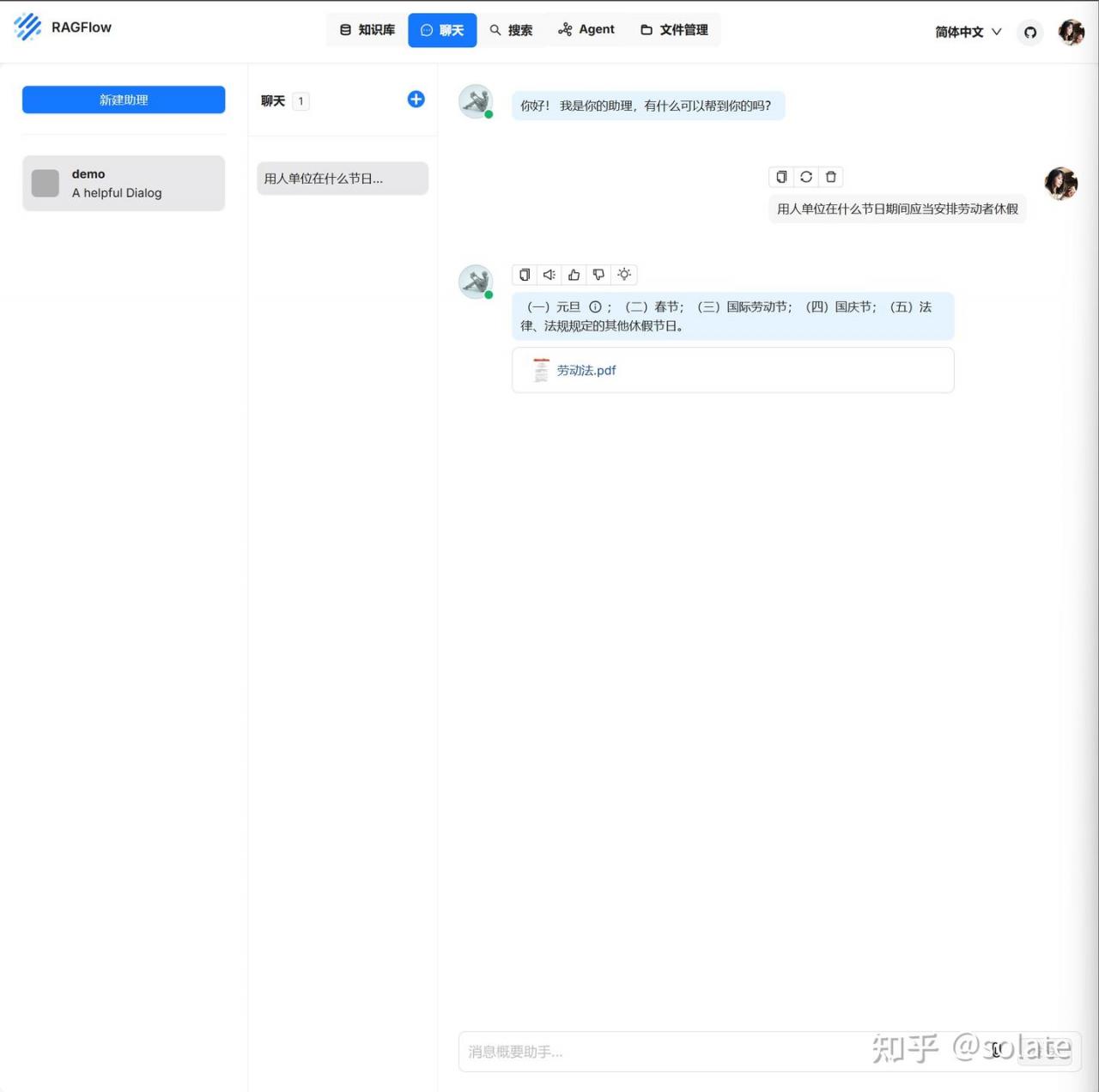
可以明显感觉这个在文本拆分和回答上比昨天的dify要准确。
API Key
其他应用,可以通过API Key 来进行访问。嵌入其他应用中。通过http 或 python 来使用。
Acquire a RAGFlow API key | RAGFlow
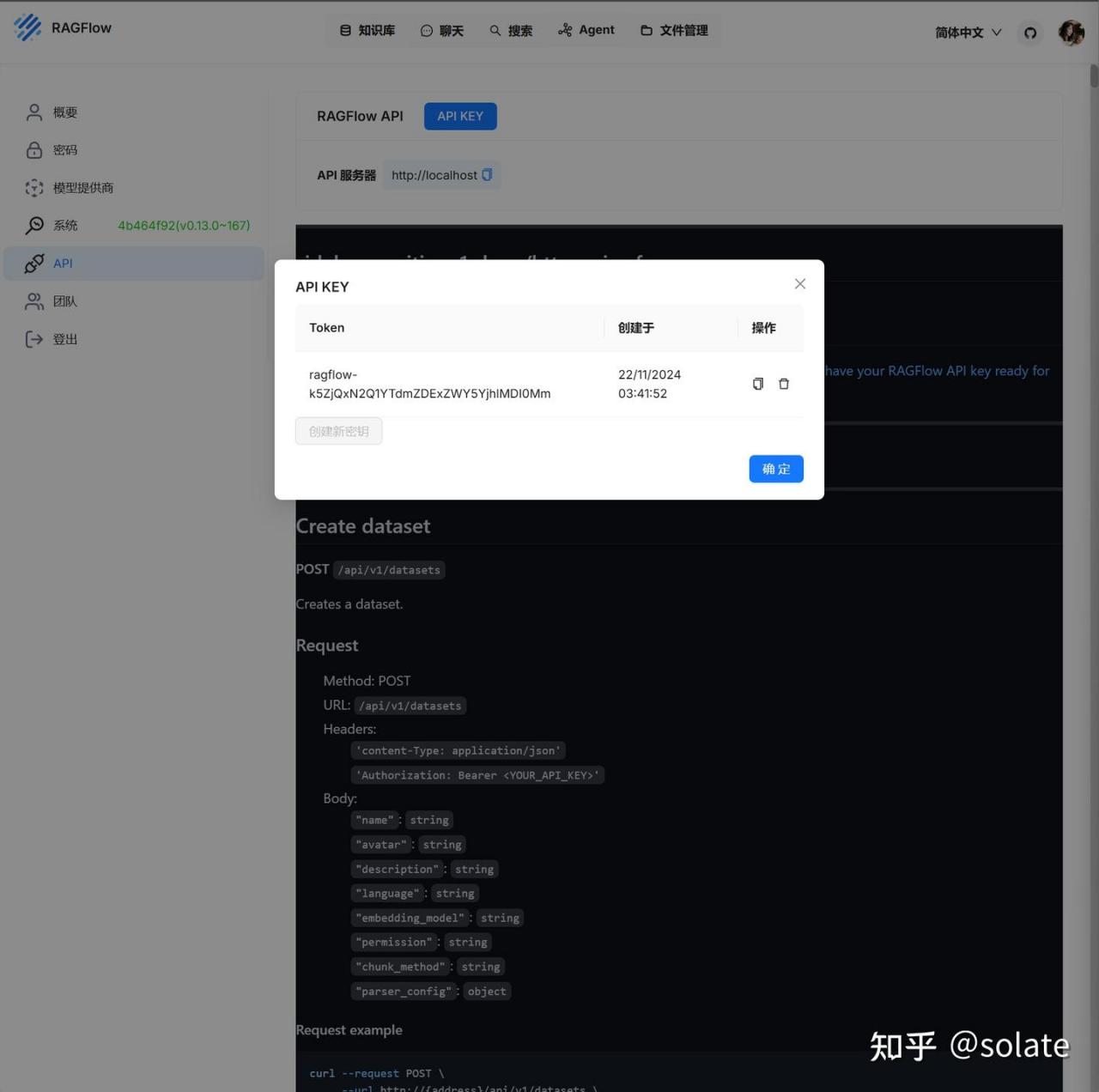
官方demo
curl --request POST \
--url http://{address}/api/v1/datasets \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <YOUR_API_KEY>' \
--data '{
"name": "test_1"
}'改为对应的,使用http 访问
curl --request POST \
--url http://localhost/api/v1/datasets \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer ragflow-k5ZjQxN2Q1YTdmZDExZWY5YjhlMDI0Mm' \
--data '{
"name": "test_1"
}'使用git bash 来敲入命令
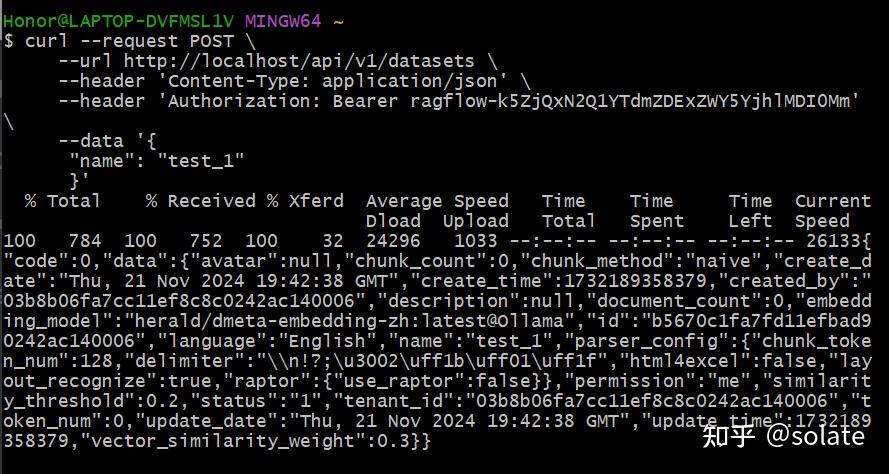
这样通过API 来实现调用控制,其他的参考文档给出的示例。下面图就可以看到了
还有接口需要使用聊天ID, 聊天ID 从下面这里获取。
这里点击聊天ID, 可以根据这个使用API 来进行
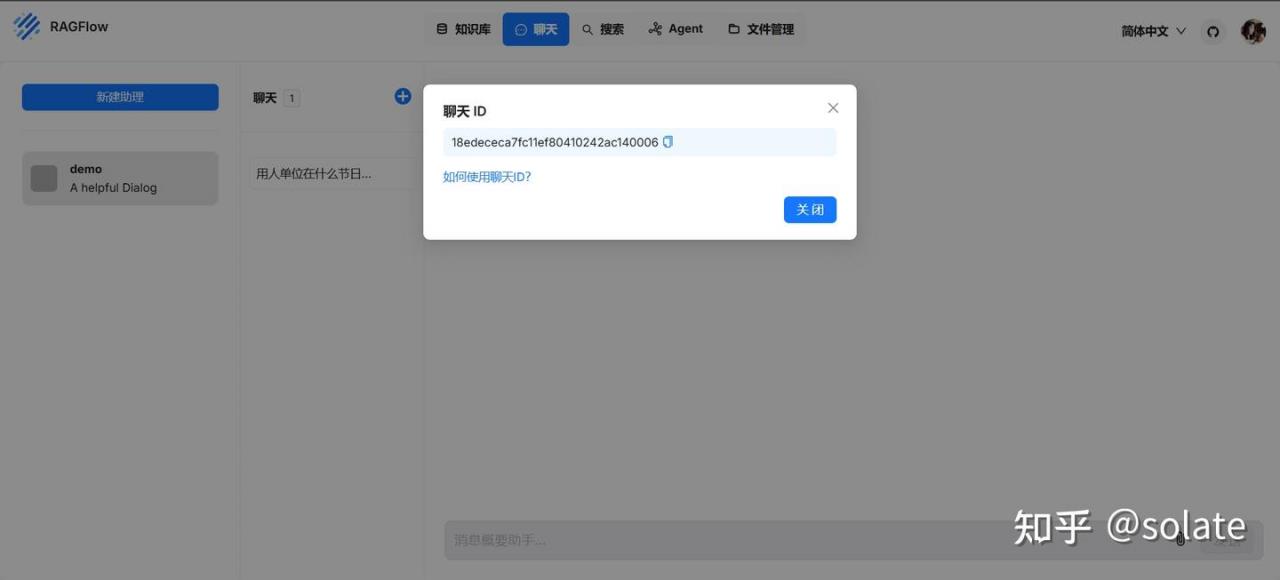
Agent
可以创建自己的流程, 这个工作流就很一般了。 一般不用这个搭建Agent.
下面是给的web search 模板
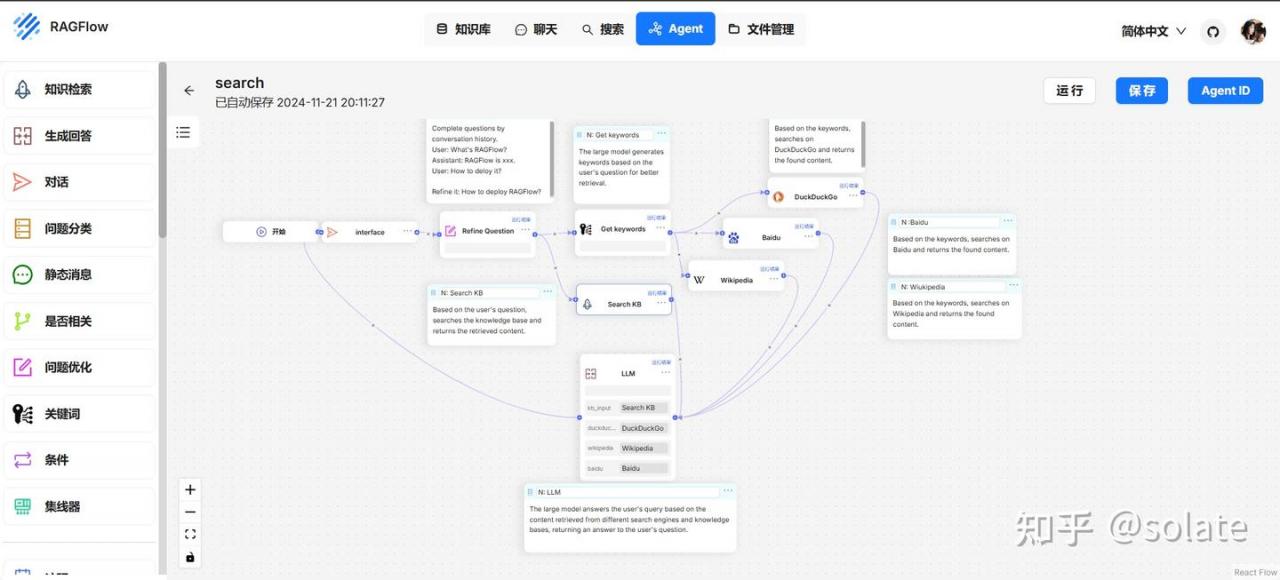
建一个空白的玩一下。
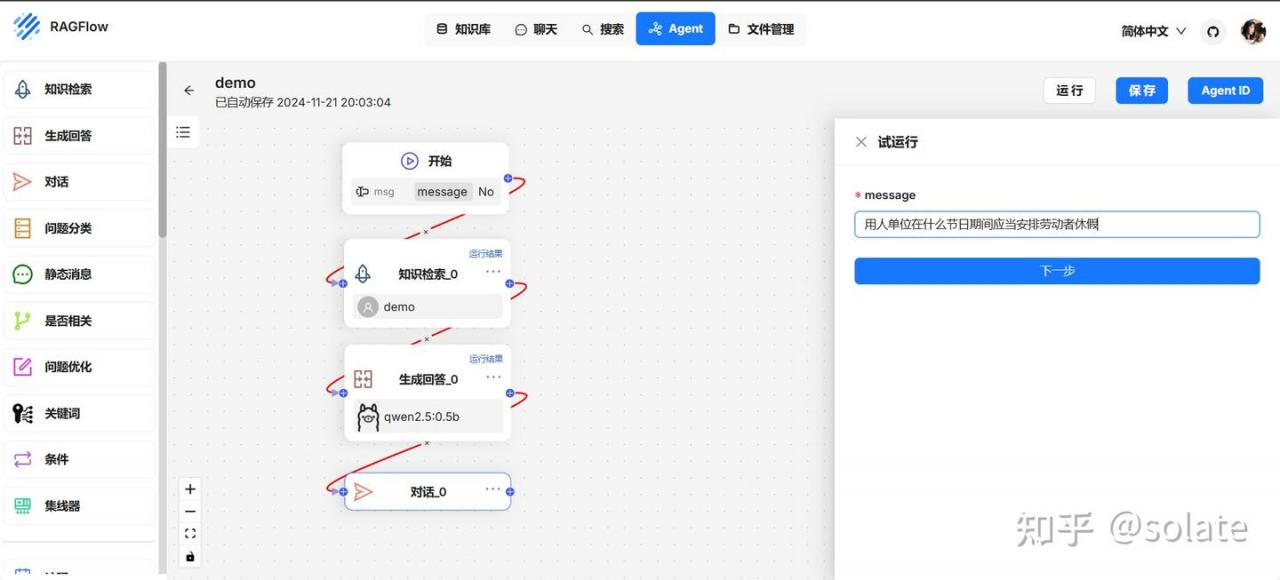
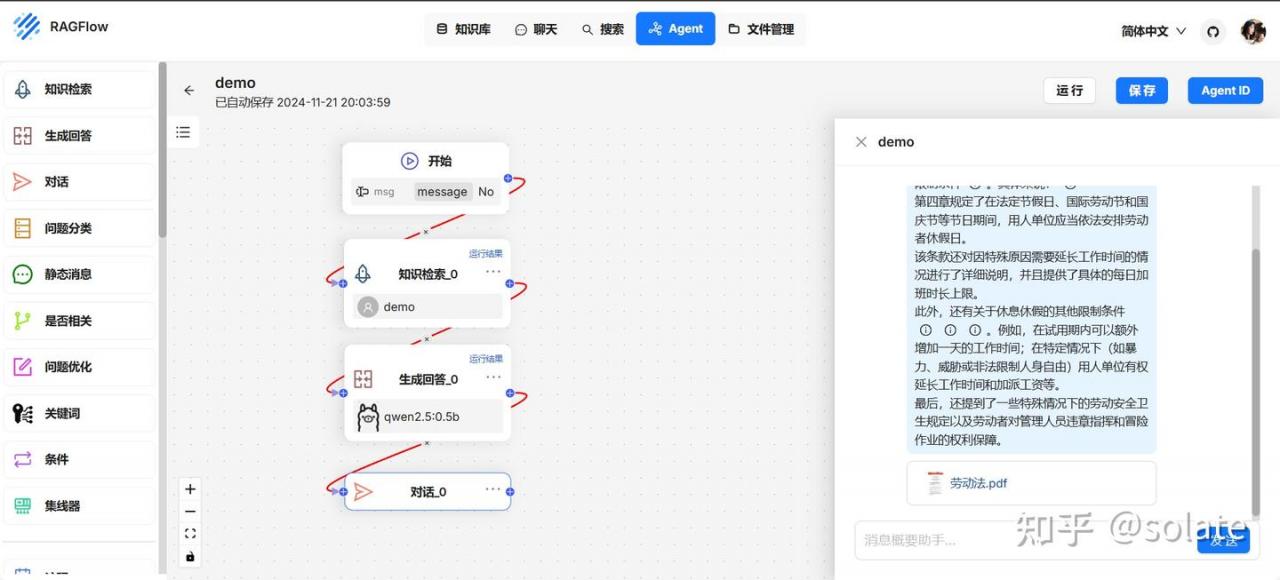
不怎么准确
参考
2024年5款开源本地知识库全面对比解析:到底哪一款最适合你?深入解析助你选择最佳方案!大模型入门,大模型教程_哔哩哔哩_bilibili
【AI大模型】使用Ollama+RAGFlow搭建一个非常好用的知识库!支持多种文件类型,本地部署大模型,效果好到尖叫!新人小白必看教程!_哔哩哔哩_bilibili
【AI大模型】使用Ollama+Dify搭建一个专属于自己的知识库!支持多种文件类型,本地部署大模型,效果出奇的好!_哔哩哔哩_bilibili
吹爆!这可能是唯一能将搭建私有化应用讲清楚的教程了,环境搭建-模型准备-模型部署-api调用-知识库构建一条龙解读!草履虫都能学得会!人工智能|大模型_哔哩哔哩_bilibili
RAGFlow:采用OCR和深度文档理解结合的新一代 RAG 引擎,具备深度文档理解、引用来源等能力,大大提升知识库RAG的召回率降低幻觉_哔哩哔哩_bilibili
PS: 觉得不错的请关注,点赞,收藏吧!! (ง・̀_・́)ง