NVIDIA Isaac™ Lab 多 GPU 多节点训练指南


NVIDIA Isaac™ Lab 是一个适用于机器人学习的开源统一框架,基于 NVIDIA Isaac Sim™ 开发,其模块化高保真仿真适用于各种训练环境,可提供各种物理 AI 功能和由 GPU 驱动的物理仿真,缩小仿真与现实世界之间的差距。
抽奖福利放送:
Isaac Lab 主要通过 NVIDIA GPU 加速高度逼真的物理模拟、实时渲染、深度强化学习(RL)模仿学习(IL)集成等先进技术,然而对于复杂的强化学习环境,可能需要在多个 GPU 上扩大训练规模。Isaac Lab 支持多 GPU 和多节点功能,与在单个 GPU 上进行训练相比,可以更快地加速训练过程并达到更高的性能水平。
在之前的机器人仿真教程里,我们分别介绍了 Isaac Lab 的安装教程以及 Isaac Lab 的可用环境与强化学习脚本使用指南,本篇教程将带大家了解如何通过多 GPU 和多节点进行扩展训练。
核心要点
Isaac Lab 支持多 GPU 和多节点强化学习。但是此功能目前仅可用于 RL-Games、RSL-RL 和 skrl 库。多 GPU 和多节点训练仅支持 Linux 系统,因 NCCL 库限制,暂不支持 Windows 系统。
一、多 GPU
Isaac Lab 支持以下两种多 GPU 训练框架。
1. 通过 PyTorch Torchrun 进行分布式训练
Torchrun 通过以下方式管理分布式训练:
- 进程管理:为每个 GPU 创建一个独立进程,并将每个进程分配至指定的 GPU。
- 脚本执行:在每个进程上运行相同的训练脚本(例如 RL Games)。
- 环境实例:每个进程都会创建独立的 Isaac Lab 环境实例。
- 梯度同步:收集并同步所有进程的梯度,在每个训练步骤结束后将更新后的梯度广播回各进程。
此流程中的关键组件是:
- Torchrun:处理进程生成、通信和梯度同步。
- RL 库:运行实际训练算法的强化学习库。
- Isaac Lab:提供每个进程独立实例化的模拟环境。
Torchrun 在底层使用 DistributedDataParallel 模块来管理分布式训练。当使用多个 GPU 进行训练时,会发生以下情况:
- 每个 GPU 运行一个独立的进程
- 每个进程执行完整的训练脚本
- 每个进程都独立拥有:
① Isaac Lab 环境实例(含 n 个并行环境)
② 策略网络副本
③ 用于收集训练经验的缓冲区 - 所有进程仅针对梯度更新进行同步
2. 通过 JAX 进行分布式训练
在使用 JAX 时,我们借助 skrl.utils.distributed.jax 模块来实现分布式训练。由于 JAX 等机器学习框架通常不会在单个程序调用中自动启动多个进程,因此 skrl 库提供了该模块,用于负责进程的启动与管理。
*注:仅 skrl 库支持 JAX。
二、多节点
除了将训练规模扩展到单台机器上的多个 GPU 之外,还可以跨多个节点进行训练。要跨多个节点/机器进行训练,需要在每个节点上启动单独的进程。
运行训练
接下来,我们来演示下多 GPU 多节点训练操作步骤。本期教程以 NVIDIA RTX™ 5880 Ada GPU 为底层硬件支持。
一、训练环境
1. CUDA 安装:
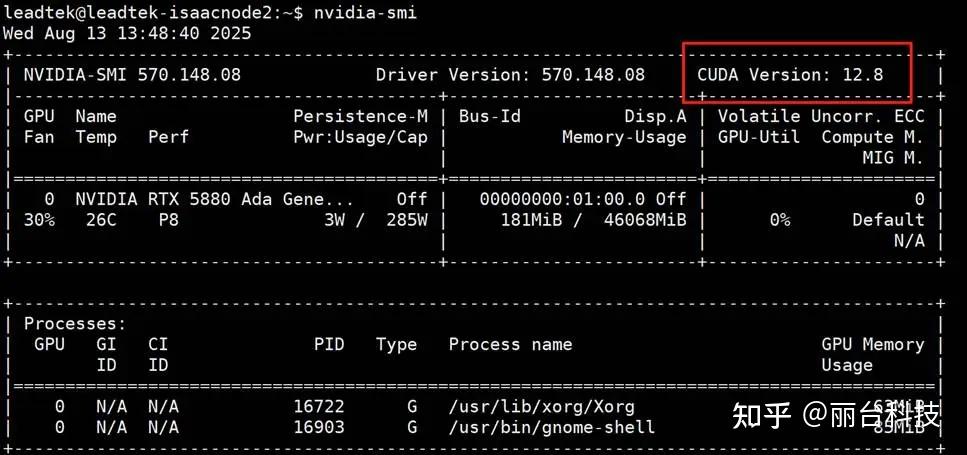
1.1 使用 nvidia-smi 查看当前驱动支持的最高 cuda 版本。如下图所示,可以看到当前显示最高版本为 CUDA Version:12.8。
1.2 访问官网,下载并安装 CUDA 12.8 及以下版本。

根据提示,选择对应系统版本,获取 CUDA 工具包安装程序下载链接以及安装方式。

1.3 运行以下命令:
sudo sh cuda_12.8.0_570.86.10_linux.run2. Pytorch 安装
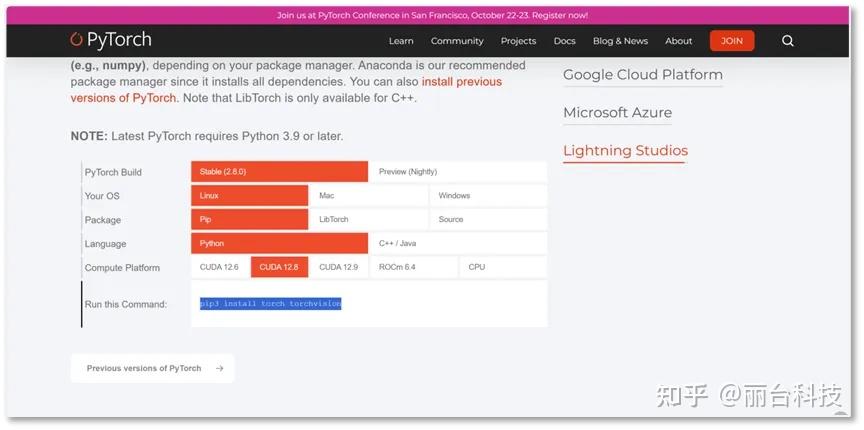
2.1 访问 Pytorch 官网,根据提示选择对应系统、CUDA 版本等下载安装即可。
2.2 如果提示没有 pip,按照要求 apt 安装。

2.3 执行 pip3 install torch torchvision。
2.4 安装完成后,查看 pytorch 版本。

二、运行结果(多节点训练)
1. 在窗口中再次确认环境变量
export ISAACSIM_PATH="${HOME}/isaacsim"
export ISAACSIM_PYTHON_EXE="${ISAACSIM_PATH}/python.sh"2. 节点运行
- 在节点 1 运行:
${ISAACSIM_PYTHON_EXE} -m torch.distributed.run --nproc_per_node=1 --nnodes=2 --node_rank=0 --rdzv_id=123 --rdzv_backend=c10d --rdzv_endpoint=192.168.150.161:5555 scripts/reinforcement_learning/rl_games/train.py --task=Isaac-Cartpole-v0 --headless –distributed- 在节点 2 运行:
${ISAACSIM_PYTHON_EXE} -m torch.distributed.run --nproc_per_node=1 --nnodes=2 --node_rank=1 --rdzv_id=123 --rdzv_backend=c10d --rdzv_endpoint=192.168.150.161:5555 scripts/reinforcement_learning/rl_games/train.py --task=Isaac-Cartpole-v0 --headless –distributed注意,需要调整的参数主要是:
–nproc_per_node
每个节点(机器)上启动的进程数,通常设置为该节点的 GPU 数量。例如,若单机有 8 块 GPU,–nproc_per_node=8。
–nnodes
参与训练的物理节点总数。例如,–nnodes=4 表示使用 4 台机器组成集群进行训练。
–rdzv_endpoint
主节点的 IP 地址和端口号,格式为 host:port。所有节点通过此端点进行通信协调,例如–rdzv_endpoint=192.168.1.100:29500。
*如需了解详细步骤,可参考官方文档:
推荐硬件配置
以下是丽台针对个人开发者/研究人员的机器人仿真及训练环境推荐配置,能流畅运行 Isaac Lab 以及机器人训练和仿真所需的算力,同时可再与企业级多卡集群方案形成互补,能够完全满足中小规模的实验需求。

LEADTEK WS3008 产品特性
- 支持选配 2 张 NVIDIA RTX 5880 Ada GPU
- 支持单 Intel Xeon W-3400、W-2400 系列处理器
- Intel W790 芯片组
- 支持最高至 350W CPU TDP
- 支持最多 DDR5-4800MHz x8 内存
- 支持 4 PCIe 5.0 x16 插槽
- 支持 1 M.2 NVMe PCI-E 4.0 x4
- 支持 2 个 10GbE BaseT、1 个 2.5GbE BaseT 和 1 个 1GbE BaseT 网口
- 支持 1 个 IPMI 管理口
- 支持 2 个 USB-A
- 支持 1 个 VGA 口,1 个 COM 口
- 支持 1 个 1200W/1300W 铂金电源
- 机箱体积:400.0×278.0×167.6 mm
如需获取更多产品信息,欢迎联系
。
*与 NVIDIA 产品相关的图片或视频(完整或部分)的版权均归 NVIDIA Corporation 所有。